Deep Research 大比拼:不同实现的深度解析
Han, Not Solo Blogs Notebooks Projects Talks About
Deep Research 大比拼:不同实现的深度解析
2025年2月26日 • Han Lee | 预计阅读时间 6 分钟 (1134 字)
最近,前沿 AI 实验室掀起了一股 “Deep Research” 发布浪潮。Google 在 2024 年 12 月推出了 Gemini 1.5 Deep Research,OpenAI 紧随其后在 2025 年 2 月发布了 Deep Research,Perplexity 也在不久后推出了自己的 Deep Research。与此同时,DeepSeek、阿里巴巴的 Qwen 和 Elon Musk 的 xAI 为他们的聊天机器人助手推出了 Search 和 Deep Search 功能。除此之外,GitHub 上涌现了数十个 Deep Research 的模仿开源实现。似乎 Deep Research 成了 2025 年的 Retrieval-Augmented Generation (RAG) —— 所有东西都在被重新包装并作为 “Deep Research” 进行营销,但对于它实际包含的内容却没有明确的定义。
这听起来是否很熟悉?它与 2023 年围绕 RAG 的炒作,以及几个月前的 agents 和 agentic RAG 的炒作相呼应。为了理清头绪,这篇博文将从技术实现的角度,审视各种 “Deep Research”。
Deep Research、Deep Search 还是仅仅是 Search
"”Deep Research 使用 AI 来探索您感兴趣的复杂主题,并为您提供一份全面、易于阅读的报告,让您可以初步了解 Gemini 如何在处理复杂任务方面做得更好,从而节省您的时间。“- Google”
"”Deep Research 是 OpenAI 的下一个 agent,它可以独立为您工作 —— 您给它一个提示,ChatGPT 将找到、分析和综合数百个在线来源,以创建一份达到研究分析师水平的综合报告。“ - OpenAI
"”当您提出一个 Deep Research 问题时,Perplexity 会执行数十次搜索,阅读数百个来源,并对这些材料进行推理,从而自主地提供一份全面的报告。“ - Perplexity”
抛开营销术语,以下是 Deep Research 的简明定义:
“Deep Research 是一种报告生成系统,它接收用户查询,使用大型语言模型 (LLMs) 作为 agents 来迭代地搜索和分析信息,并生成一份详细的报告作为输出。”
在自然语言处理 (NLP) 术语中,这被称为 report generation(报告生成)。
实现方式
报告生成——或者说 deep research ——自 ChatGPT 首次亮相以来一直是 AI 工程的焦点。 我个人在 2023 年初的黑客马拉松中尝试过它,那时 AI 工程才刚刚起步。LangChain、AutoGPT、GPT-Researcher 等工具以及 prompt 工程,再加上 Twitter 和 LinkedIn 上的无数演示,已经引起了广泛关注。然而,真正的挑战在于实现细节。下面,我们将探讨构建报告生成系统的常见模式,突出它们的差异,并对不同供应商的产品进行分类。
未经训练:有向无环图 (DAG)
早期,AI 工程师发现要求像 GPT-3.5 这样的 LLM 从头开始生成报告是不切实际的。相反,他们转向 Composite Patterns 将多个 LLM 调用链接在一起。
该过程通常如下所示:
- 分解用户查询 —— 有时使用 step back prompting (Zheng et al, 2023) —— 以创建报告大纲。
- 对于每个部分,从搜索引擎或知识库检索相关信息并进行总结。
- 最后,使用 LLM 将各个部分拼接成一份连贯的报告。
GPT-Researcher 就是一个典型的例子。
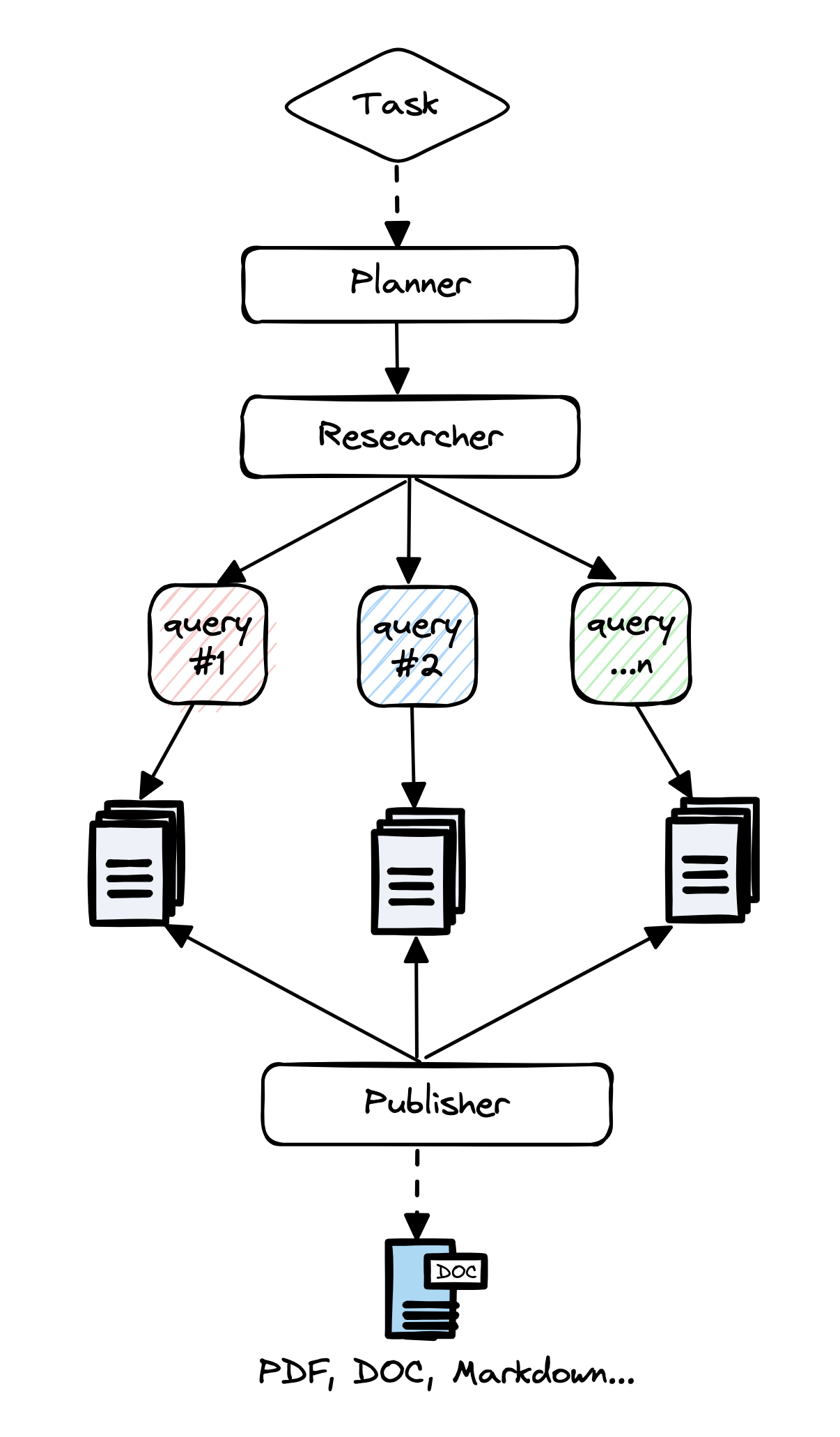
该系统中的每个 prompt 都经过 “prompt engineering” 精心手工调整。 评估依赖于对输出的主观观察,导致报告质量不一致。 成功时,它很棒。
未经训练:有限状态机 (FSM)
为了提高报告质量,工程师们增加了 DAG 方法的复杂性。 他们没有采用单程流程,而是引入了诸如 reflexion (Shinn et al, 2023) 和自我反思之类的结构模式,其中 LLM 审查并改进其自身的输出。 这将简单的 DAG 转换为有限状态机 (FSM),LLM 部分指导状态转换。
来自 Jina.ai 的这张图例说明了这种方法:
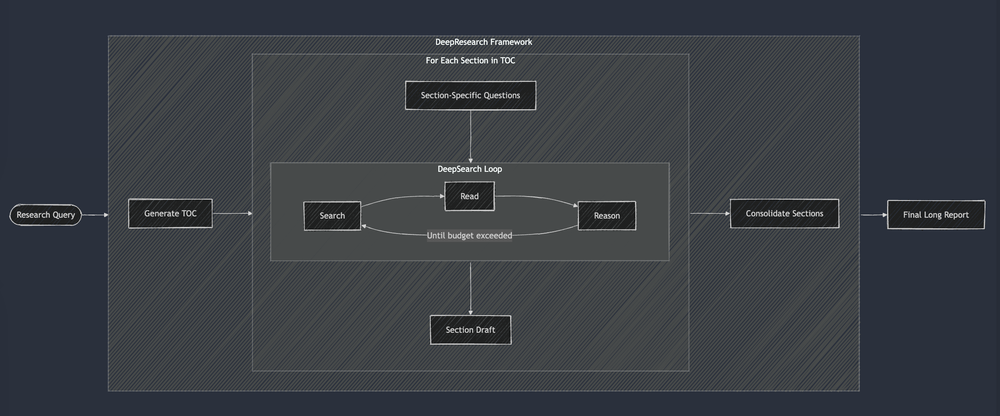
与 DAG 方法一样,每个 prompt 都是手工制作的,并且评估仍然是主观的。 报告质量持续差异很大,因为系统是手动调整的。
已训练:端到端
早期方法的缺点 —— 随意的 prompt 工程和缺乏可衡量的评估指标 —— 促使人们进行了转变。 斯坦福大学的 STORM [Shao et al, 2024] 通过使用 DSPy (Khattab et al, 2023) 端到端优化系统来解决这些问题。
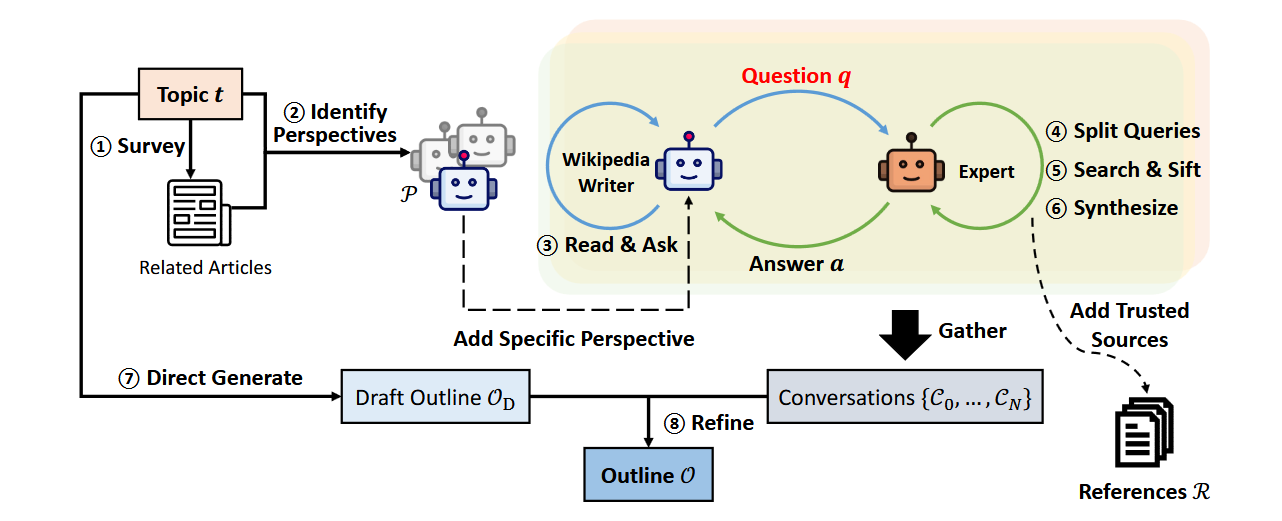
结果呢? STORM 生成的报告质量堪比 Wikipedia 文章。
已训练:大型推理模型
LLM 推理能力的进步使得大型推理模型成为 Deep Research 的一个引人注目的选择。 例如,OpenAI 描述了它如何训练其 Deep Research 模型,如下所示。 请注意,OpenAI 使用 LLM-as-a-judge 和 evaluation rubrics 来评分输出。

Google 的 Gemini 和 Perplexity 的聊天助手也提供了 “Deep Research” 功能,但两者都没有发布任何关于他们如何针对该任务优化其模型或系统,或任何实质性定量评估的文献。 然而,Google 的 Deep Research 的产品经理在 podcast interview 中提到,他们“本身具有特殊的访问权限。它几乎是相同的模型 (Gemini 1.5)。 我们当然有我们自己的后训练工作”。 我们假设所做的微调工作并不重要。 同时,xAI 的 Grok 在报告生成方面表现出色,尽管它似乎不会进行超过两次迭代的搜索 - 大纲部分几次,每个部分几次。
竞争格局
我们开发了一个概念图,以评估各种流行服务的 Deep Research 功能。 纵轴衡量研究的深度,由服务执行的迭代周期数来定义,以便根据先前的发现收集更多信息。 横轴评估训练水平,从手工调整的系统(例如,那些使用手工制作的 prompt 的系统)到另一端利用机器学习技术的完全训练的系统。 训练系统的示例包括:
OpenAI Deep Research:通过强化学习专门针对研究任务进行了优化。
DeepSeek:针对通用推理和工具使用进行了训练,可适应研究需求。
Google Gemini:指令微调的大型语言模型 (LLMs),经过广泛训练,但未专门针对研究进行训练。
Stanford STORM:一个经过训练的系统,可简化整个端到端的研究过程。
该框架突出了不同的服务如何平衡迭代研究深度与其训练方法的复杂性,从而更清楚地了解其 Deep Research 的优势。

结论
Deep Research 的发展速度非常快。 六个月前失败或未广泛使用的技术现在可能成功。 命名约定仍然不明确,增加了混乱。 希望这篇文章能够阐明技术差异并消除炒作。
参考文献
- Yijia Shao, Yucheng Jiang, Theodore A. Kanell, Peter Xu, Omar Khattab, Monica S. Lam (2024) Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models. Retrieved from https://arxiv.org/abs/2402.14207
- OpenAI (2025). Deep Research System Card. Retrieved from https://cdn.openai.com/deep-research-system-card.pdf
- assafelovic. (2024). GPT Researcher (Version [latest version]) [Computer software]. GitHub. Retrieved from https://github.com/assafelovic/gpt-researcher
- Jina AI. (2024). A practical guide to implementing DeepSearch/DeepResearch. Retrieved from https://jina.ai/news/a-practical-guide-to-implementing-deepsearch-deepresearch/
- Latent Space. (2024). The inventors of deep research. Retrieved from https://www.latent.space/p/gdr
@article{
leehanchung,
author = {Lee, Hanchung},
title = {The Differences between Deep Research, Deep Research, and Deep Research},
year = {2025},
month = {02},
howpublished = {\url{https://leehanchung.github.io}},
url = {https://leehanchung.github.io/blogs/2025/02/26/deep-research/}
}
Han, Not Solo
Han Lee's blog on machine learning engineering, compound AI systems, search and information retrieval, and recsys — exploring machine learning, LLM agents, and data science insights from startups to enterprises.