SepLLM:通过将一个片段压缩为一个分隔符来加速 LLM
SepLLM:通过将一个片段压缩为一个分隔符来加速大型语言模型
Guoxuan Chen1,2, Han Shi1,‡, Jiawei Li1, Yihang Gao2, Xiaozhe Ren1, Yimeng Chen3, Xin Jiang1, Zhenguo Li1, Weiyang Liu4, Chao Huang2 1华为诺亚方舟实验室,2香港大学,3KAUST 生成式人工智能卓越中心,4马克斯·普朗克智能系统研究所,图宾根 ‡通讯作者 guoxchen@connect.hku.hk, shi.han@huawei.com, li.jiawei@huawei.com 代码 arXiv
摘要
大型语言模型(LLM)在一系列自然语言处理任务中表现出卓越的性能。然而,由于其二次复杂度,它们庞大的规模带来了相当大的挑战,尤其是在计算需求和推理速度方面。在这项工作中,我们发现了一个值得注意的模式:与其它语义上有意义的 token 相比,某些无意义的特殊 token (即,分隔符) 对 attention 分数贡献巨大。 这一观察结果使我们假设:这些特殊 token 之间的片段的信息可以被压缩到这些 token 中,而不会造成重大的信息损失。 基于这个假设,我们引入了 SepLLM,这是一个即插即用的框架,通过压缩这些片段并删除冗余 token 来加速推理。 此外,我们还实现了高效的内核来加速训练。 在无训练、从头训练和后训练设置下的实验结果证实了 SepLLM 的有效性。 值得注意的是,在使用 Llama-3-8B 作为 backbone 的 GSM8K-CoT 基准测试中,SepLLM 在性能几乎没有损失的情况下,实现了超过 50% 的 KV cache 显著减少。 此外,在流式设置中,SepLLM 能够跨最多 400 万甚至更多的 token 提供一致且有效的语言建模。
概述
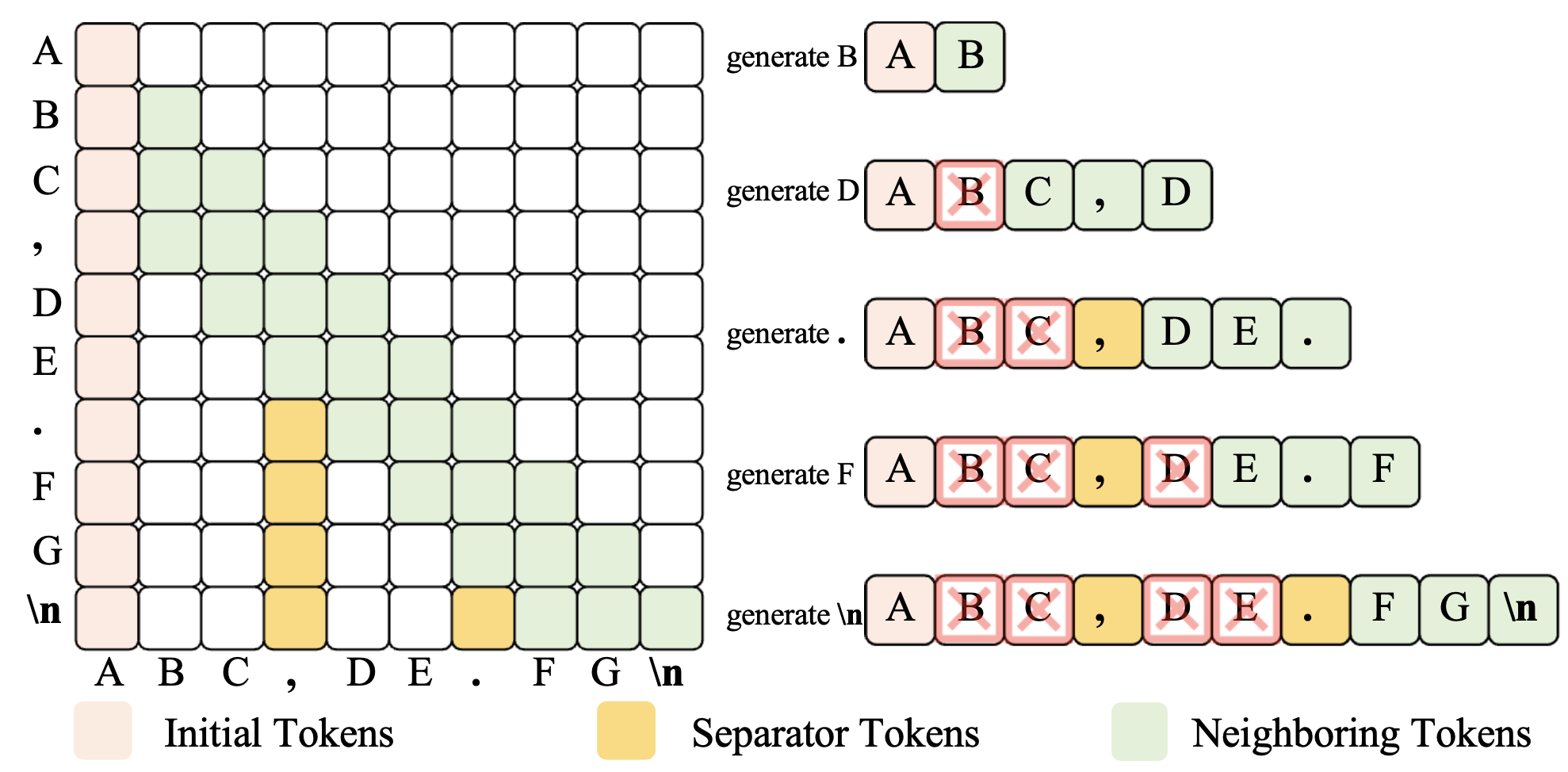
图 1: SepLLM 的训练和推理范式。

图 2: 针对流式应用定制的 SepLLM 的总体框架。
无需训练
GSM8K-CoT | r.KV(%) | MMLU | r.KV(%) ---|---|---|--- Vanilla | 77.3 | 100.0 | 65.7 | 100.0 StrmLLM (n=380) | 71.4 | 47.5 | 63.4 | 52.5 StrmLLM (n=256) | 68.6 | 26.0 | 62.1 | 37.7 SepLLM (n=256) | 77.2 | 47.4 | 64.7 | 44.6
表 1:在 GSM8K-CoT 8-shots 和 MMLU 5-shots 上进行免训练实验的评估结果和平均运行时间 KV cache 使用率。
视频 1:SepLLM 和其他模型之间的 ppl 和运行时间的比较。
从头开始训练
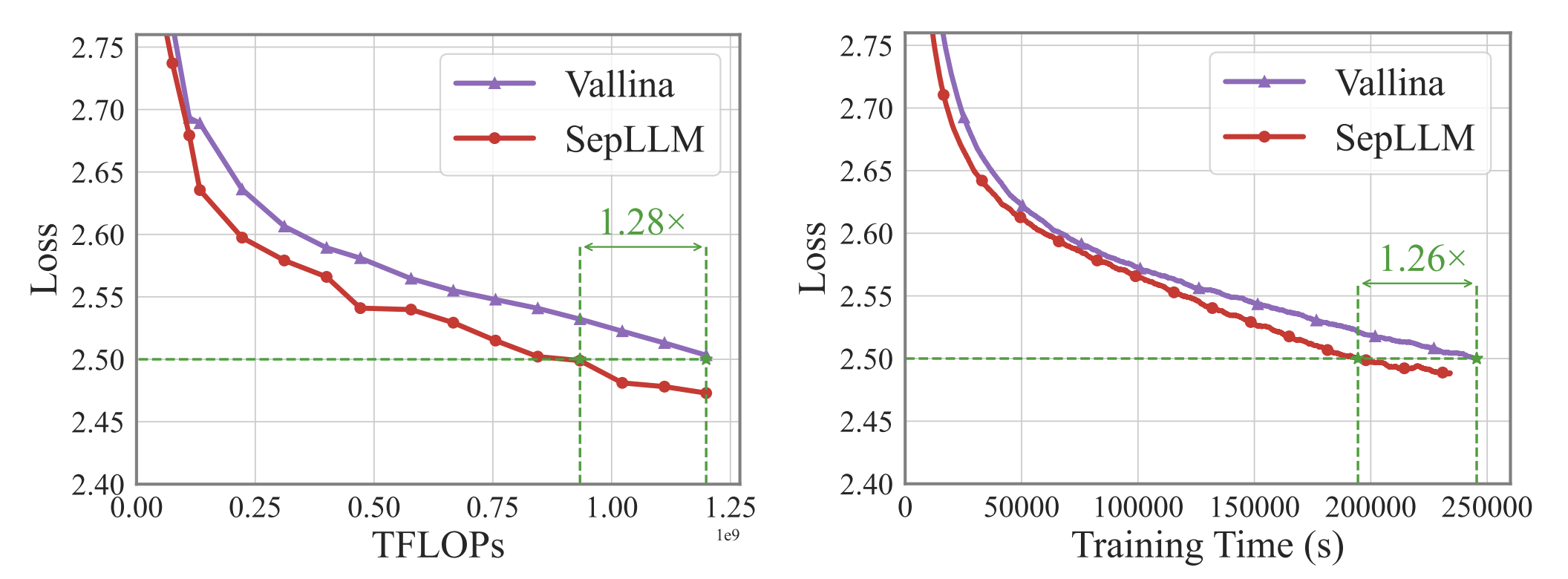
图 3: vanilla Transformer 和 SepLLM 之间的损失比较。
后训练
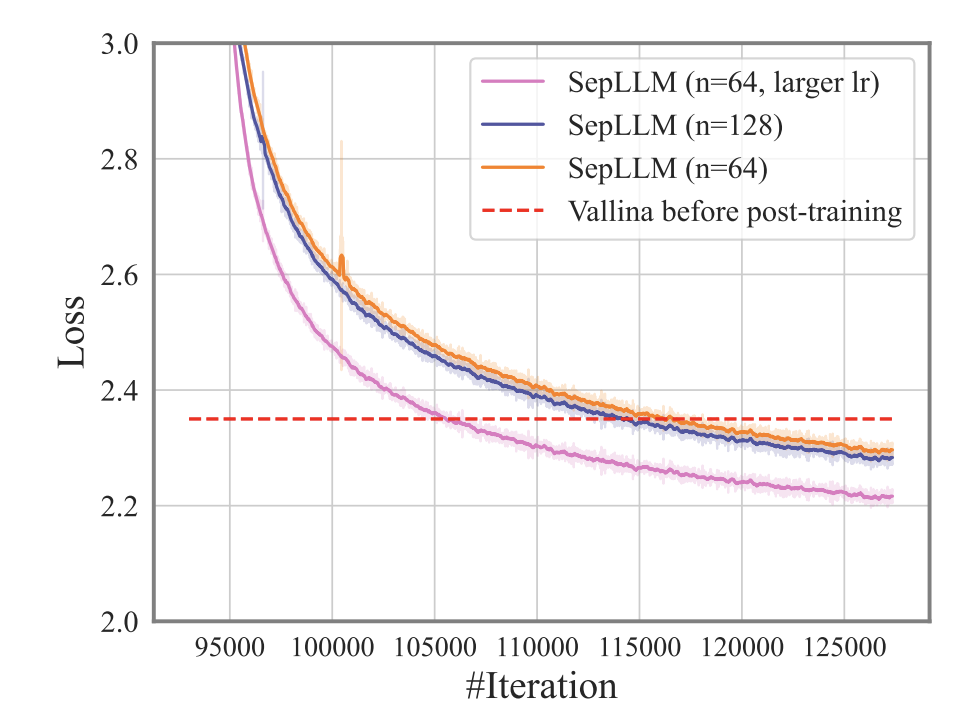
图 4: 后训练的训练损失曲线。
BibTeX
@article{chen2024sepllm,
title={SepLLM: Accelerate Large Language Models by Compressing One Segment into One Separator},
author={Chen, Guoxuan and Shi, Han and Li, Jiawei and Gao, Yihang and Ren, Xiaozhe and Chen, Yimeng and Jiang, Xin and Li, Zhenguo and Liu, Weiyang and Huang, Chao},
journal={arXiv preprint arXiv:2412.12094},
year={2024}
}
本页面使用 Academic Project Page Template 构建,该模板改编自 Nerfies 项目页面。 欢迎免费借用本网站的代码,只需在页脚链接回本页即可。 本网站根据 Creative Commons Attribution-ShareAlike 4.0 International License 获得许可。