无需预训练的 ARC-AGI 方法研究
iliao2345
目录

作者:Isaac Liao 和 Albert Gu
在这篇博文中,我们旨在回答一个简单而根本的问题:
仅仅通过无损信息压缩本身,能否产生智能行为?
认为有效的压缩本身就是智能核心的想法并不新鲜(例如,参见 Hernández-Orallo & Minaya-Collado, 1998; Mahoney, 1999; Hutter, 2005; Legg & Hutter, 2007). 我们不打算重新探讨那些理论讨论,而是进行一次实际演示。
在这项工作中,我们通过开发一种纯粹基于压缩的方法,在 ARC-AGI 挑战 中表现良好,从而证明了推理时期的无损压缩足以产生智能行为。ARC-AGI 挑战是一个类似智商测试的数据集,旨在从有限的演示中推断程序/规则。 关键是,我们的解决方案,我们称之为 CompressARC ,遵守以下三个限制:
- 无预训练;模型随机初始化并在推理时进行训练。
- 无数据集;一个模型仅在目标 ARC-AGI 谜题上进行训练,并输出一个答案。
- 无搜索,在大多数意义上来说——只有梯度下降。
尽管存在这些限制,CompressARC 在训练集上实现了 34.75% 的准确率,在评估集上实现了 20% 的准确率——在 RTX 4070 上处理每个谜题大约需要 20 分钟。 据我们所知,这是第一个用于解决 ARC-AGI 的神经方法,其中训练数据仅限于目标谜题。 CompressARC 的智能并非来自预训练、庞大的数据集、详尽的搜索或海量的计算资源,而是来自压缩。 我们挑战了传统上对大量预训练和数据的依赖,并提出了一个未来,即定制的压缩目标和高效的推理时计算协同工作,以从最少的输入中提取深刻的智能。
什么是 ARC-AGI?
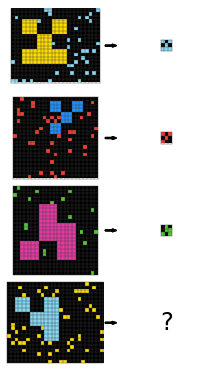
ARC-AGI, 于 2019 年推出,是一个人工智能基准,旨在测试系统从最少的示例中推断和泛化抽象规则的能力。 该数据集由类似智商测试的谜题组成,其中每个谜题提供几个示例图像,这些图像演示了一个基础规则,以及一个需要完成或应用该规则的测试图像。 虽然有些人认为解决 ARC-AGI 可能标志着 通用人工智能 (AGI) 的到来,但其真正的目的是突出当前阻碍 AGI 进展的挑战。 以下是 1000 个谜题中的三个:
隐藏规则:将每个对象向右移动一个像素,除了对象的底部/右侧边缘。| 隐藏规则:缩小大对象并将其颜色设置为分散点的颜色。| 隐藏规则:延长绿线,通过在撞到墙壁时转弯与红线相交。
---|---|---
 |
|  |
| 
对于每个谜题,都存在一个隐藏规则,该规则将每个输入网格映射到每个输出网格。 您将获得一些输入到输出映射的示例,并且您有两次尝试来猜测给定输入网格的输出网格,而不会被告知隐藏规则。 如果任一猜测正确,则该谜题得 1 分,否则得 0 分。 允许您更改输出网格的大小并选择每个像素的颜色。 这些谜题的设计目的是人类可以合理地找到答案,但机器应该更困难。普通人可以解决训练集中的 76.2%,并且人类专家可以解决 98.5%。
400 个训练谜题比其余的更容易,旨在帮助您学习以下模式:
- 对象性: 对象持续存在,不能无缘无故地出现或消失。 对象可以根据情况进行交互或不交互。
- 目标导向: 对象可以是动画的或非动画的。 一些对象是“代理” - 它们有意图并且追求目标。
- 数字和计数: 可以使用加法、减法和比较等基本数学方法,根据形状、外观或运动来计数或排序对象。
- 基本几何和拓扑: 对象可以是矩形、三角形和圆形等形状,可以镜像、旋转、平移、变形、组合、重复等。可以检测到距离的差异。
ARC Prize 团队已经多次发起解决 ARC-AGI 的竞赛,并提供金钱奖励。最近一次比赛涉及可能超过 1,000,000 美元的奖金和奖励,主要奖金保留给能够在受限环境中,使用 12 小时的计算时间在 100 个谜题的私有测试集上实现 85% 的方法。
我们的解决方案
我们认为,无损信息压缩可以作为解决 ARC-AGI 谜题的有效框架。 谜题的更有效(即,更低位)压缩与更准确的解决方案相关联。 为了解决 ARC-AGI 谜题,我们设计了一个系统,该系统通过找到紧凑的表示来将不完整的谜题转换为完整的谜题——填充答案——,该表示在解压缩时可以重现具有任何解决方案的谜题。 关键挑战是在不需要答案作为输入的情况下获得这种紧凑的表示。
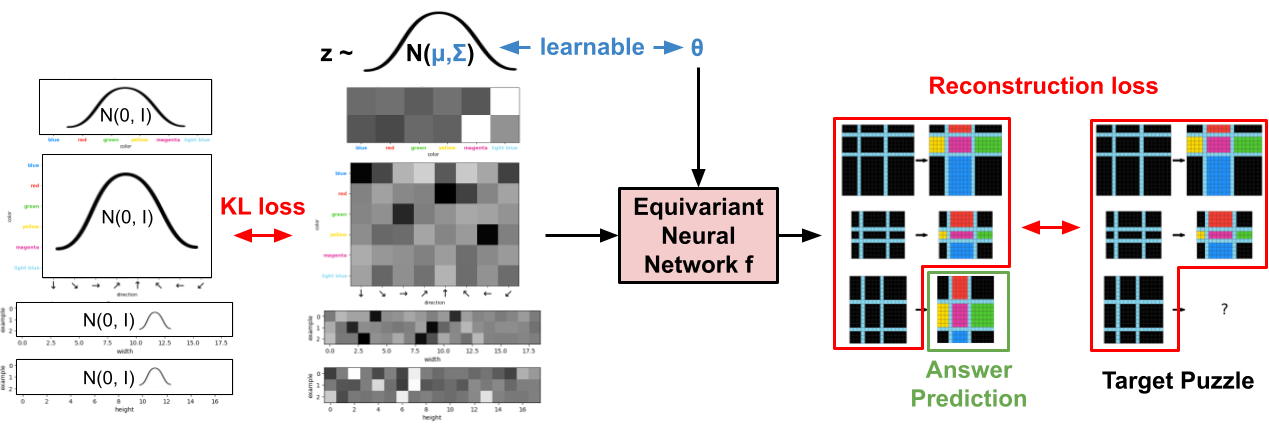
CompressARC 使用神经网络作为解码器。 但是,编码算法不是另一个网络——相反,编码是通过梯度下降算法实现的,该算法在保持正确解码输出的同时对解码器执行推理时训练。 换句话说,运行编码器意味着优化解码器的参数和输入分布,以实现最压缩的谜题表示。 生成的优化参数(例如,权重和输入分布设置)本身充当压缩位表示,该压缩位表示对谜题及其答案进行编码。
用标准的机器学习术语来说:(没有压缩术语,并进行了一些简化)
- 我们从推理时开始,并且给定一个要解决的 ARC-AGI 谜题。(例如,下图中的谜题。)
- 我们构建一个神经网络 $f$(参见架构),该网络专为谜题的细节而设计(例如,示例数量、观察到的颜色)。 该网络采用随机正态输入 $z \sim N(\mu, \Sigma)$,以及跨所有网格的每个像素颜色逻辑预测,包括答案网格(3 个输入输出示例,总共 6 个网格)。 重要的是,$f_\theta$ 对于常见的增强是不变的——例如重新排序输入输出对(包括答案对)、颜色排列和空间旋转/反射。
- 我们初始化网络权重 $\theta$,并为 $z$ 分布设置参数 $\mu$ 和 $\Sigma$。
- 我们共同优化 $\theta$、$\mu$ 和 $\Sigma$,以最大限度地减少已知网格(其中 5 个)上的交叉熵之和,忽略答案网格。 KL 散度惩罚使 $N(\mu, \Sigma)$ 接近 $N(0,1)$,如在 VAE 中一样。
- 由于生成的答案网格由于 $z$ 中的随机性而具有随机性,因此我们在整个训练过程中保存答案网格,并将最常出现的答案网格选择为我们的最终预测。
这种方法为何会执行压缩并不明显。 稍后您将看到我们如何从尝试压缩 ARC-AGI 中推导出它。 首先,让我们看看它如何尝试解决上面的谜题。
观察网络学习过程:着色方块
人工解决方案:
我们首先意识到输入分为多个方块,并且这些方块仍然存在于输出中,但现在它们已着色。 然后,我们尝试弄清楚哪些颜色进入哪些方块。 首先,我们注意到拐角始终是黑色。 然后,我们注意到中间始终是品红色。 之后,我们注意到侧面方块的颜色取决于它们的方向:向上为红色,向下为蓝色,向右为绿色,向左为黄色。 此时,我们将输入复制到答案网格,然后将中间方块涂成品红色,然后根据其方向对其余方块进行着色。
CompressARC 解决方案:
学习 50 步: CompressARC 的网络输出一个答案网格(样本),其中输入具有相同颜色的浅蓝色行/列。 它已经注意到谜题中的所有其他输入输出对都表现出这种对应关系。 它不知道其他输出像素如何分配颜色; 网络输出(样本平均值)的指数移动平均值显示,网络主要将相同的平均颜色分配给非浅蓝色像素。 | 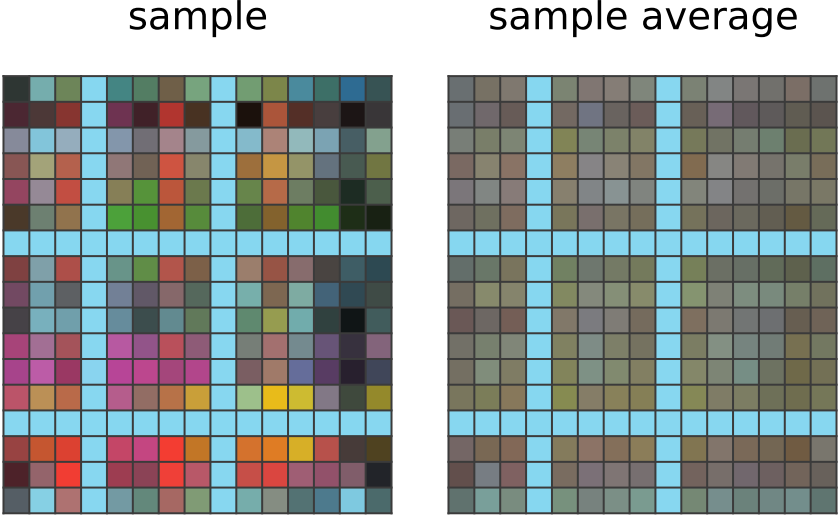 ---|---
学习 150 步: 网络输出一个网格,其中附近的像素具有相似的颜色。 它可能已经注意到这在所有输出中都很常见,并且猜测它也适用于答案。 |
---|---
学习 150 步: 网络输出一个网格,其中附近的像素具有相似的颜色。 它可能已经注意到这在所有输出中都很常见,并且猜测它也适用于答案。 | 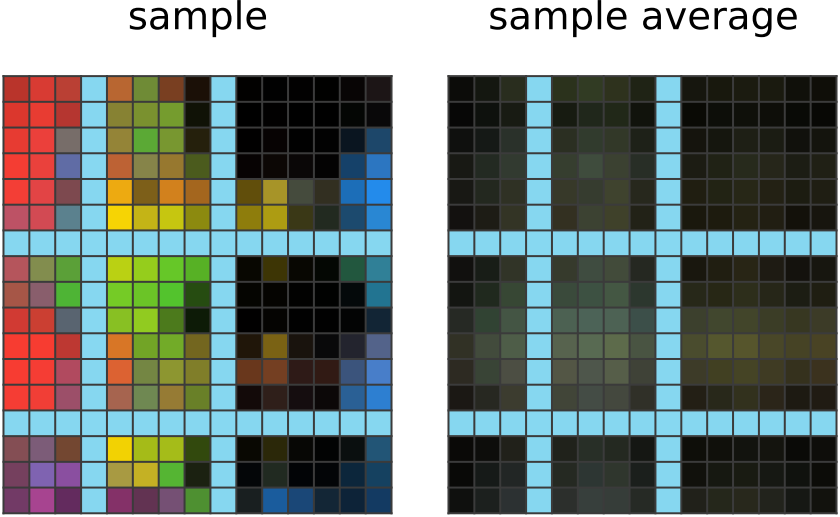 学习 200 步: 现在,网络输出显示更大的颜色斑点,这些颜色斑点被浅蓝色边框切断。 它已经注意到其他给定输出中边框的常见用法来划分颜色斑点,并在此处应用了相同的想法。 它还注意到其他给定输出中的黑色拐角斑点,网络模仿这些斑点。 |
学习 200 步: 现在,网络输出显示更大的颜色斑点,这些颜色斑点被浅蓝色边框切断。 它已经注意到其他给定输出中边框的常见用法来划分颜色斑点,并在此处应用了相同的想法。 它还注意到其他给定输出中的黑色拐角斑点,网络模仿这些斑点。 | 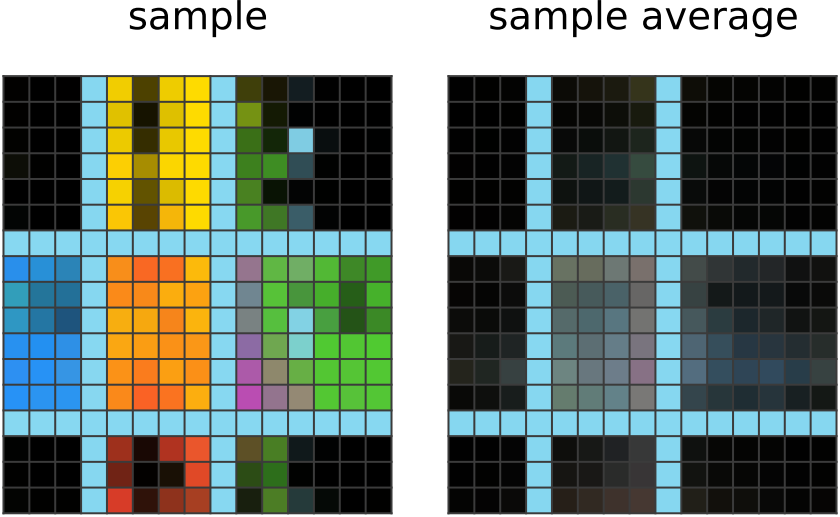 学习 350 步: 现在,网络输出显示分配给距中心正确方向的方块的正确颜色。 它已经意识到使用单个颜色到方向的映射来选择其他给定输出中的斑点颜色,因此它模仿了此映射。 它仍然不是在行内着色的最佳选择,并且它对中心斑点也感到困惑,可能是因为中间不对应于方向。 尽管如此,平均网络输出确实显示出中间正确的品红色色调,这意味着网络正在赶上。 |
学习 350 步: 现在,网络输出显示分配给距中心正确方向的方块的正确颜色。 它已经意识到使用单个颜色到方向的映射来选择其他给定输出中的斑点颜色,因此它模仿了此映射。 它仍然不是在行内着色的最佳选择,并且它对中心斑点也感到困惑,可能是因为中间不对应于方向。 尽管如此,平均网络输出确实显示出中间正确的品红色色调,这意味着网络正在赶上。 | 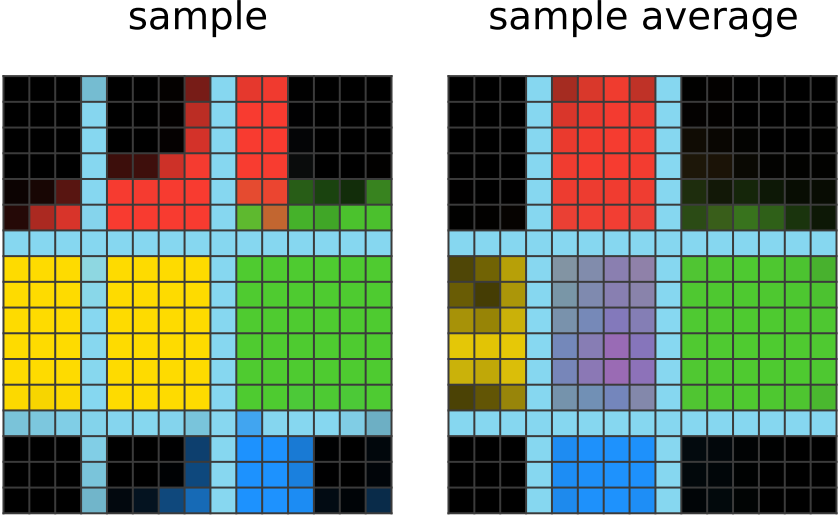 学习 1500 步: 该网络已尽可能优化。 有时它仍然会在其输出的样本中犯一个错误,但是这并不常见并且已被过滤掉。 |
学习 1500 步: 该网络已尽可能优化。 有时它仍然会在其输出的样本中犯一个错误,但是这并不常见并且已被过滤掉。 | 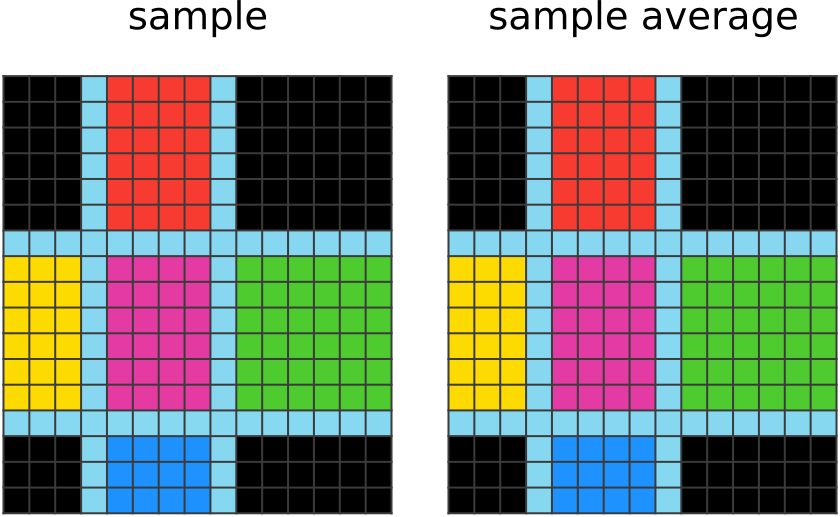
训练后,我们可以解构学习到的 z 分布,以发现它对颜色方向对应表和行/列分隔符位置进行编码!
如何推导出我们的解决方案
同样,我们如何从尝试执行压缩到最终使用的方法并不明显。 我们的算法的推导使我们绕道而行 信息论, 算法信息论, 和 编码理论, 机器学习仅在接近尾声时才出现。
无损信息压缩入门
在 信息论 中,无损信息压缩是关于尝试用尽可能少的位来表示某些信息,同时仍然能够从位表示中重建该信息。 此类问题被抽象如下:
- 源从某个过程中生成一些符号 $x$,该过程从概率分布 $p(x)$ 生成符号。
- 压缩器/编码器 $E$ 必须将符号 $x$ 映射到字符串位 $s$。
- 解压缩器/解码器 $D$ 必须将 $s$ 准确地映射回原始符号 $x$。
目标是使用 $p$ 来构造位有效的函数 $(E, D)$(即,最大限度地减少 $s$ 的预期长度),而不会出现任何错误符号。 在我们的案例中,符号 $x$ 是 ARC-AGI 数据集(许多谜题 + 答案对),并且我们想弄清楚最佳压缩系统可能解压缩为哪些答案。 除了,我们没有答案(只有谜题)作为输入提供给 $E$,并且我们不知道 $p$,因为很难对人类的谜题构思的智能过程进行建模。
通用的压缩方法
要构建我们的压缩方案,您可能认为我们需要知道 $p$ 是什么,但我们认为这并不重要,因为我们可以制作通用的压缩器。 这完全取决于以下假设:
对于从 $p$ 采样的 ARC-AGI 数据集 $x$,存在一些可实际实现的、位高效的压缩系统 $(E, D)$。
如果这是错误的,那么即使我们知道 $p$,我们使用压缩来解决 ARC-AGI 的整个想法也注定要失败,因此我们不妨做出此假设。
我们的通用压缩器 $(E’, D’)$ 是在不知道 $p$ 的情况下构建的,并且它几乎与原始的 $(E, D)$ 一样位高效:
- $E’$ 观察符号 $x$,选择一个程序 $f$ 和输入 $s$ 以最大限度地减少 $\text{len}(f)+\text{len}(s)$,约束条件是运行该程序会使 $f(s)=x$,然后发送对 $(f, s)$。
- $D’$ 只是一个程序执行器,用于在 $s$ 上执行 $f$,正确生成 $x$。
可以使用 算法信息论 证明 $(E’, D’)$ 实现的位效率最多比 $(E, D)$ 的位效率差 $\text{len}(f)$ 位,其中 $f$ 是 用于实现 D 的代码。 但是由于压缩是可实际实现的,因此 $D$ 的代码应该足够简单,以供人类工程师编写,因此 $\text{len}(f)$ 必须很短,这意味着我们的通用压缩器将接近可能的最佳位效率。
具有讽刺意味的是,使用此方法解决 ARC-AGI 的唯一问题是实现 $E’$ 并不实际,因为 $E’$ 需要在部分固定输出约束 $f(s){answers}=x{answers}$ 下最大限度地减少程序输入对 $(f, s)$ 的长度。
神经网络的助力
为了避免搜索程序空间,我们只需选择一个程序 $f$,以在位效率上做出很小的牺牲。 我们希望程序空间的多样性可以委托给输入 $s$ 空间中的多样性。 具体来说,我们编写一个运行神经网络前向传递的程序 $f$,其中 $s=(\theta, z, \epsilon)$ 是神经网络的权重、输入和输出校正。 然后,我们可以使用梯度下降来“搜索” $s$。
这种受限的压缩方案使用 相对熵编码 (REC)1 将噪声权重 $\theta$ 和神经网络输入 $z$ 编码为位 $s_\theta$ 和 $s_z$,并使用 算术编码 将输出误差校正 $\epsilon$ 编码为位 $s_\epsilon$,以生成一个由三个块 $(s_\theta, s_z, s_\epsilon)$ 组成的位串 $s$。 压缩方案的运行方式如下:
- 解码器运行 $\theta = \text{REC-decode}(s_\theta)$, $z = \text{REC-decode}(s_z)$, $\text{logits} = \text{Neural-Net}(\theta, z)$ 和 $x=\text{Arithmetic-decode}(s_\epsilon, \text{logits})$。
- 编码器训练 $\theta$ 和 $z$ 以最大限度地减少总代码长度 $\mathbb{E}[\text{len}(s)]$。 $s_\epsilon$ 通过算术编码固定,以保证正确的解码。 为了以可微分的方式计算损失 $\mathbb{E}[\text{len}(s)]$ 的三个组成部分,我们参考 REC 和算术编码的属性:
- 事实证明,$\epsilon$ 代码长度 $\mathbb{E}[\text{len}(s_\epsilon)]$ 等于谜题中所有给定网格上的总交叉熵误差。
- REC 要求我们固定一些参考分布 $q_\theta$,并且还要向 $\theta$ 添加噪声,将其转换为分布 $p_\theta$。 然后,REC 允许您使用代码长度 $\mathbb{E}[\text{len}(s_\theta)] = KL(p_\theta|| q_\theta) = \mathbb{E}{\theta \sim p\theta} [\log (p_\theta(\theta) / q_\theta(\theta))]$ 位来存储噪声 $\theta$。 我们将选择将 $q_\theta = N(0, I/2\lambda)$ 固定为较大的 $\lambda$,这样损失分量 $\mathbb{E}[\text{len}(s_\theta)] \approx \lambda | \theta|^2 + \text{const}$ 等效于正则化解码器。
- 我们还必须对 $z$ 执行对 $\theta$ 执行的操作,因为它也使用 REC 表示。 我们将选择将 $q_z = N(0,I)$ 固定,因此 $z$ 的代码长度为 $\mathbb{E}[\text{len}(s_z)] = KL(p_z|| q_z) = \mathbb{E}_{z \sim p_z} [\log (p_z(z) / q_z(z))]$。
我们可以通过 重参数化技巧 计算这些代码长度的梯度。
此时,我们观察到我们描述的 $s$ 的总代码长度实际上是具有解码器正则化 (= $z$ 的 KL + 重建误差 + 正则化) 的 VAE 损失。 同样,如果我们将我们上面描述的其余部分(加上关于等方差性和谜题间独立性的修改,并忽略正则化)移植到典型的机器学习术语中,我们将获得 上面对 CompressARC 的描述。
架构
我们设计了自己的神经网络架构,用于将潜在变量 $z$ 解码为 ARC-AGI 谜题。 我们架构中最重要的特征是其等方差性,这是规定只要输入 $z$ 经历转换,输出 ARC-AGI 谜题也必须以相同方式转换的对称性规则。 一些例子:
- 重新排序输入/输出对
- 打乱颜色
- 网格的翻转、旋转和反射
我们需要一次考虑的等方差性太多了,因此我们决定创建一个 完全对称的基本架构,并通过 添加非对称层 一次又一次地打破不需要的对称性,以赋予其 特定的非等方差能力。
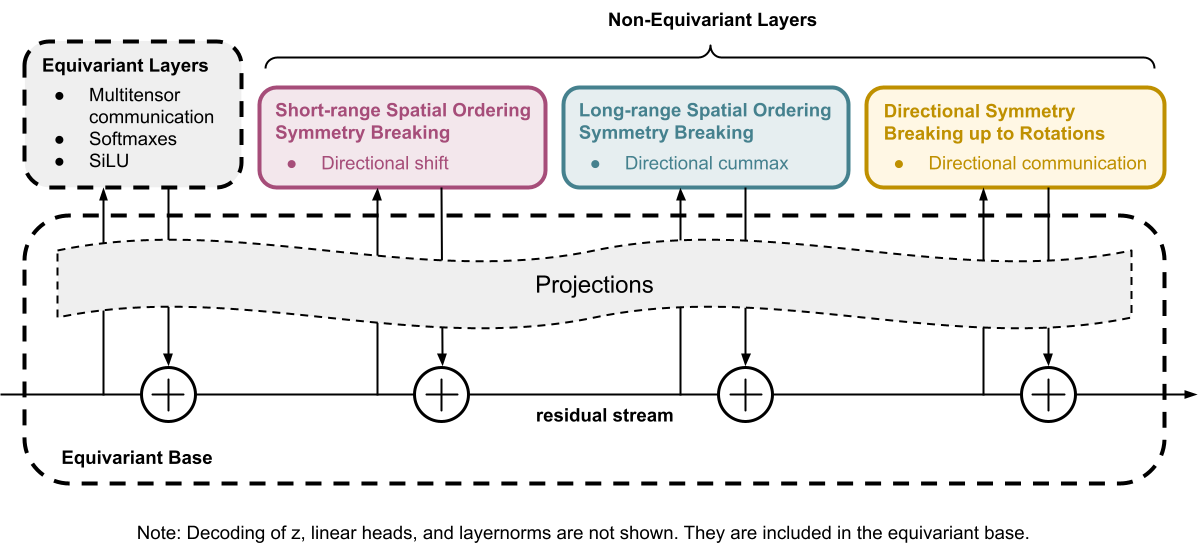
为了说明我们的意思,假设 $z$ 和 ARC-AGI 谜题都采用形状为 $[n\_examples, n\_colors, height, width, 2 \text{ 用于输入/输出}]$ 的张量形式 (这实际上不是数据的格式(参见多重张量),但它可以最好地表达这个想法。) 然后,我们的网络一开始就对 $example$、$color$、$height$ 和 $width$ 维度中索引的排列是不变的。 必须格外小心权重共享,以强制网络也对交换 $width$ 和 $height$ 维度是不变的。 然后,我们可以添加一个涉及在 $width$ 和 $height$ 维度中滚动一个的层,以允许网络区分短距离空间交互,但不区分长距离空间交互。
实际的数据($z$、隐藏激活和谜题)通过我们的层以我们称为“多重张量”的格式传递,这只是各种形状的张量桶。 所有等方差性都可以根据它们如何更改多重张量来描述。 为了理解我们列出的任何层,您必须首先阅读下面关于多重张量的部分。
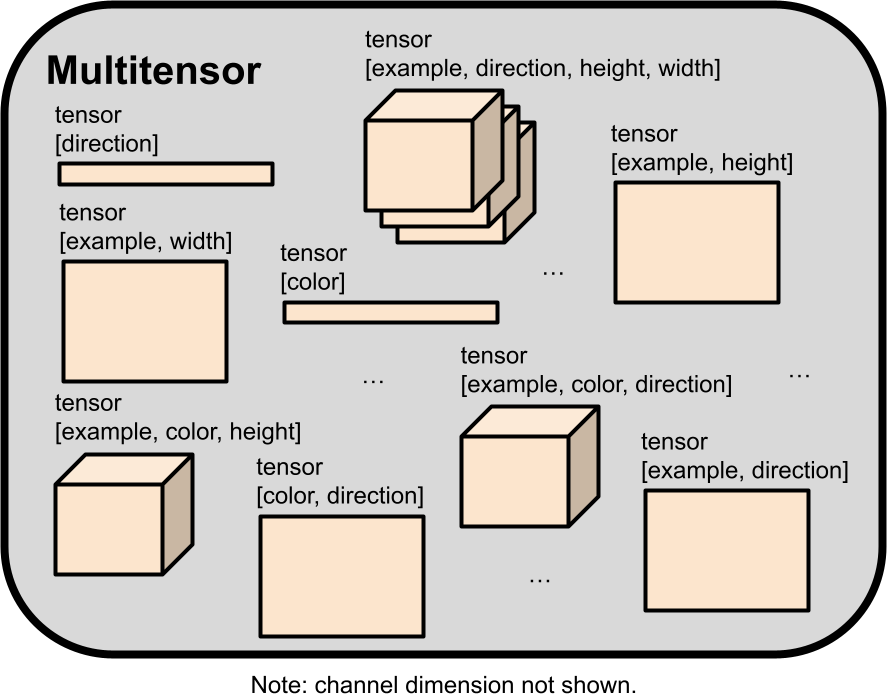
多重张量
大多数常见的机器学习架构类都对具有恒定秩的单一类型张量进行操作。 LLM 对形状为 $[n\_batch, n\_tokens, n\_channels]$ 的秩 3