三年后我的 Beancount 账本自动化程度达到 95% (2024)
我的 Beancount 账本自动化程度达到 95%
2024年12月30日 阅读时长约 15 分钟
我坚信应该为自己的需求构建产品,以身作则地使用自己的产品,并找到具有相同需求的客户。因此,我开始构建 BeanHub。三年后,我的 Beancount 账本自动化程度达到 95%,我成为了自己产品的非常满意的用户。 很难描述那种感觉;作为一个痴迷于自动化的计算机爱好者,看到我的会计账簿以开放格式自动更新,而我无需触碰它,这给我带来了纯粹的快乐😍
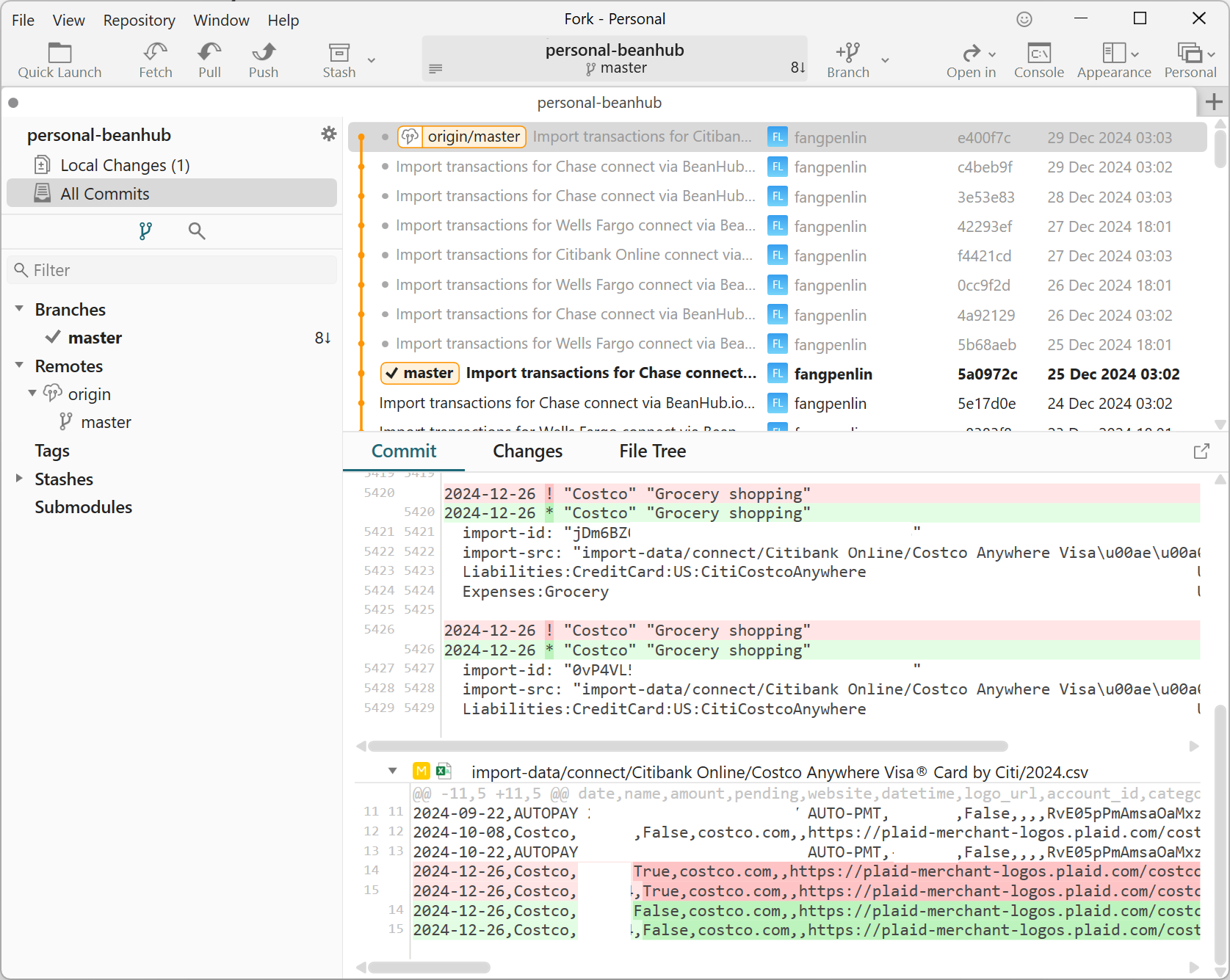 Git 历史记录和差异的屏幕截图,显示 Beancount 和银行交易 CSV 文件的更改
Git 历史记录和差异的屏幕截图,显示 Beancount 和银行交易 CSV 文件的更改
你是否看到了这个 Costco 交易从待定变为已确认的 git 提交?没错!一切都是自动的,但它只是一个可以被任何开源 Beancount 工具读取的 Beancount 文件!更好的是,还有其他人在付费给我,而且数量还在增长。
今天,我看到了关于广受欢迎的会计软件 Bench 在 X 上关闭的不幸消息。
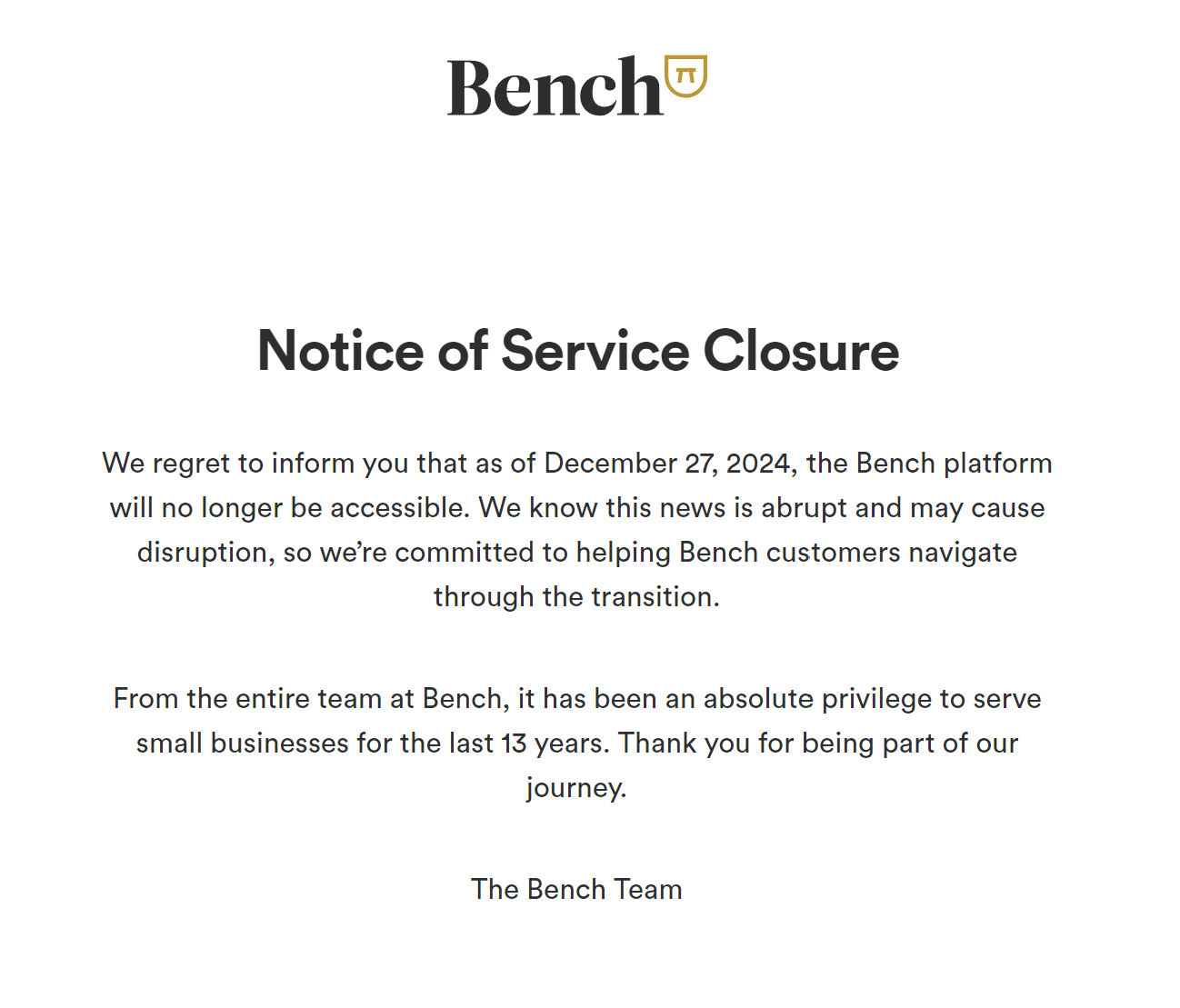 Bench 会计软件的关闭通知
Bench 会计软件的关闭通知
我感到惊讶,但也不是那么惊讶。现在回想起来,我真的很高兴自己选择了为自己构建产品的艰难道路。它并没有给我带来财务自由(尚未),但至少我自己是一个快乐的用户,并且我已经有一些付费客户。不过,这并不容易;我花了三年时间才走到今天,并且我克服了许多有趣的技术挑战,并从中学习了很多。今天,我想分享我构建和销售 BeanHub 作为产品的旅程。
背景
三年前,我创立了我的创业公司 Launch Platform。甚至在我考虑要构建什么产品之前,我就已经面临着每个创业公司创始人都会面临的同样问题——使用什么会计账簿软件?有很多流行的选项,例如 QuickBooks 或 Xero。然而,作为一名拥有超过 20 年经验的软件工程师,我目睹了互联网创业公司的崛起,并且明白没有永远的软件。我知道有一天软件会消失,而我的关键数据将被困在过时的格式中,或者被锁定在他们的数据中心里。
考虑到这一点,虽然注册任何一个都非常容易,但我不想屈服。因此,我四处搜索,找到了 Beancount。它是开源的,因此我无需担心有一天格式会变得过时。但是,我发现现有的工具并不能满足我的所有需求。我痴迷于尽可能地自动化一切。我想要一个基于 Beancount 的智能会计账簿,它可以自动为我完成大多数事情。我还希望拥有一个用户友好的 UI 界面,以便我的妻子可以查看账簿,以确保我没有在未经她允许的情况下购买一些新玩具。她也可以在我的帮助下自己输入条目,而无需学习那些枯燥的东西。
文件而非应用
构建基于数据库的会计软件很容易,因为在数据库中操作数据很容易,并且无数会计账簿软件已经在这样做了。我不想再做一个,因为它违背了最初的目的。
因此,预先设定明确的目标和规则非常重要。对于 BeanHub,我一直告诉自己,所有操作都应该只发生在文件上,而不是数据库中的表上。这使得它困难了 10 倍,因为你需要解析文本文件,相应地更新它,然后将其写回。但我很高兴我这样做了。这保证了我所有的会计账簿都采用相同的开放格式。
有趣的是,今天,我发现了 Steph Ango 撰写的文章 File over app,他是 Obsidian 的创始人,他在 X 上提到了 Bench 关闭的消息。作者也相信软件应该以开放格式运行。我非常同意。将来我们会看到更多像 Bench 关闭这样的案例。人们在使用依赖于封闭格式的软件时,会更加意识到数据锁定的风险。因此,虽然以“文件而非应用”为理念的软件在短期内可能看起来不那么性感,因为它更难构建,但从长远来看它会胜出。
尽可能开源
在构建 BeanHub 时,缺少大量关键组件来实现目标。例如,我需要一个解析器来操作文本文件。为了在不搞砸文件的情况下不断更新它,我需要一个格式化程序。为了从 CSV 文件导入交易,我需要一个基于规则的导入引擎。虽然 Beancount 及其许多工具都是开源的,但并非所有工具都满足我的需求。因此,我构建了 beancount-parser 来解析具有注释意识的 Beancount 语法,并构建了 beancount-black 来格式化该语法。我还构建了 beanhub-import 作为基于规则的导入引擎。
 BeanHub 开源列表的屏幕截图
BeanHub 开源列表的屏幕截图
这些只是冰山一角。回想起来,令我自己惊讶的是,在过去三年中,我仅仅为了构建 BeanHub 就已经开源了 15 个项目。你可以在我们的 BeanHub 开源项目列表中找到完整列表。你可能会问,我为什么要开源这么多项目?
首先,由于我在开源工具的基础上构建了该产品,因此我想尽可能地回馈。其次,作为一家企业,我希望即使在我的网站将来关闭后,也能保持“文件而非应用”概念的有效性。导入规则引擎 beanhub-import 就是一个很好的例子。人们会编写自己的导入规则,然后他们的工作流程将依赖于它。因此,它们必须是开源的。否则,用户将在软件生命周期结束后失去导入交易的能力。开源的另一个原因是它可以免费曝光。即使有些人一开始对像 BeanHub 这样的托管 Beancount 服务不感兴趣,他们也通过我构建的 beancount-black 格式化程序了解了 BeanHub 的存在。
示例 beanhub-import 规则 YAML 文件展示了如何定义用于导入交易的规则:
inputs:
- match: "import-data/mercury/*.csv"
config:
# use `mercury` extractor for extracting transactions from the input file
extractor: mercury
# the default output file to use
default_file: "books/{{date.year}}.bean"
# postings to prepend for all transactions generated from this input file
prepend_postings:
- account: Assets:Bank:US:Mercury
amount:
number: "{{amount}}"
currency: "{{currency|default('USD',true)}}"
- name: Routine Wells Fargo expenses
common_cond:
extractor:
equals: "plaid"
file:
suffix: "(.+)/WellsFargo/(.+).csv"
match:
- cond:
desc: "Comcast"
vars:
account: Expenses:Internet:Comcast
narration: "Comcastinternetfee"
- cond:
desc: "PG&E"
vars:
account: Expenses:Gas:PGE
narration: "PG&EGas"
actions:
# generate a transaction into the beancount file
- file: "books/{{date.year}}.bean"
txn:
payee: "{{payee|default(omit,true)}}"
narration: "{{narration|default(desc,true)|default(bank_desc,true)}}"
postings:
- account: "{{account}}"
amount:
number: "{{-amount}}"
currency: "{{currency|default('USD',true)}}"
虽然听起来像是让我们开源一切,但这个决定并非没有顾虑。假设你密切关注了开源社区新闻。在这种情况下,你会看到像 Amazon 这样的大型科技公司采用 MongoDB, Elastic Search, 或 Redis 这样的开源项目,然后提供竞争性服务的故事。作为企业主,我不能忽视竞争对手使用我的代码提供相同服务的风险。开源还是不开源确实是一个问题。根据我的经验,以下是我经常问自己的关于是否开源一个项目的问题:
- 这个项目对其他人有用吗?
- 谁将从中受益?
- 这个项目会提供曝光吗?
- 它是否有助于服务于“文件而非应用”的概念?
- 我的竞争对手会拿走它并与我竞争吗?
你必须考虑这些因素并在它们之间找到平衡。最后,虽然它们还不是超级明星开源项目(尚未),但根据 GitHub stars,有些人发现这些项目很有用,我为做这件事感到非常自豪:
 Launch Platform 公司的开源 GitHub 存储库的屏幕截图
Launch Platform 公司的开源 GitHub 存储库的屏幕截图
我希望有一天我可以开源更多,但是因为一旦它是开源的,你就无法收回它,所以我宁愿小心谨慎也不愿后悔。此外,能够开源更多通常需要一个适当的企业来保持你的收入增长,而其他人无法利用它。因此,我需要花时间思考一下。
但即使它还不是 100% 开源的,你也可以使用我们提供的开源工具在本地运行你的所有 BeanHub 工作流程。唯一缺少的是 Plaid API 集成,用于将银行交易提取并转储到本地 CSV 文件中,以供 beanhub-import 使用。没有什么能阻止你注册 Plaid API 并在本地执行相同的操作。唯一的问题是,某些银行(例如 Chase)需要安全审查流程才能访问交易数据,而你可能不想作为单个用户经历此过程。
从头开始构建一个 GitHub
基于纯文本开放格式运行的最大好处之一是,你可以使用 Git 轻松跟踪它们,并免费获得完整的更改历史记录。因此,对我来说,在 Git 之上构建 BeanHub 是不费吹灰之力的。我喜欢 Heroku 的部署体验。一个人可以编写部署配置(例如代码)并推送。该平台会处理它。我想为 BeanHub 提供类似的体验,允许用户将更改推送到他们的 Git 存储库,并且它会自动检查你的账簿。当服务器端有更新时,例如银行交易更新,我们会提交更改,以便你可以在本地拉取。
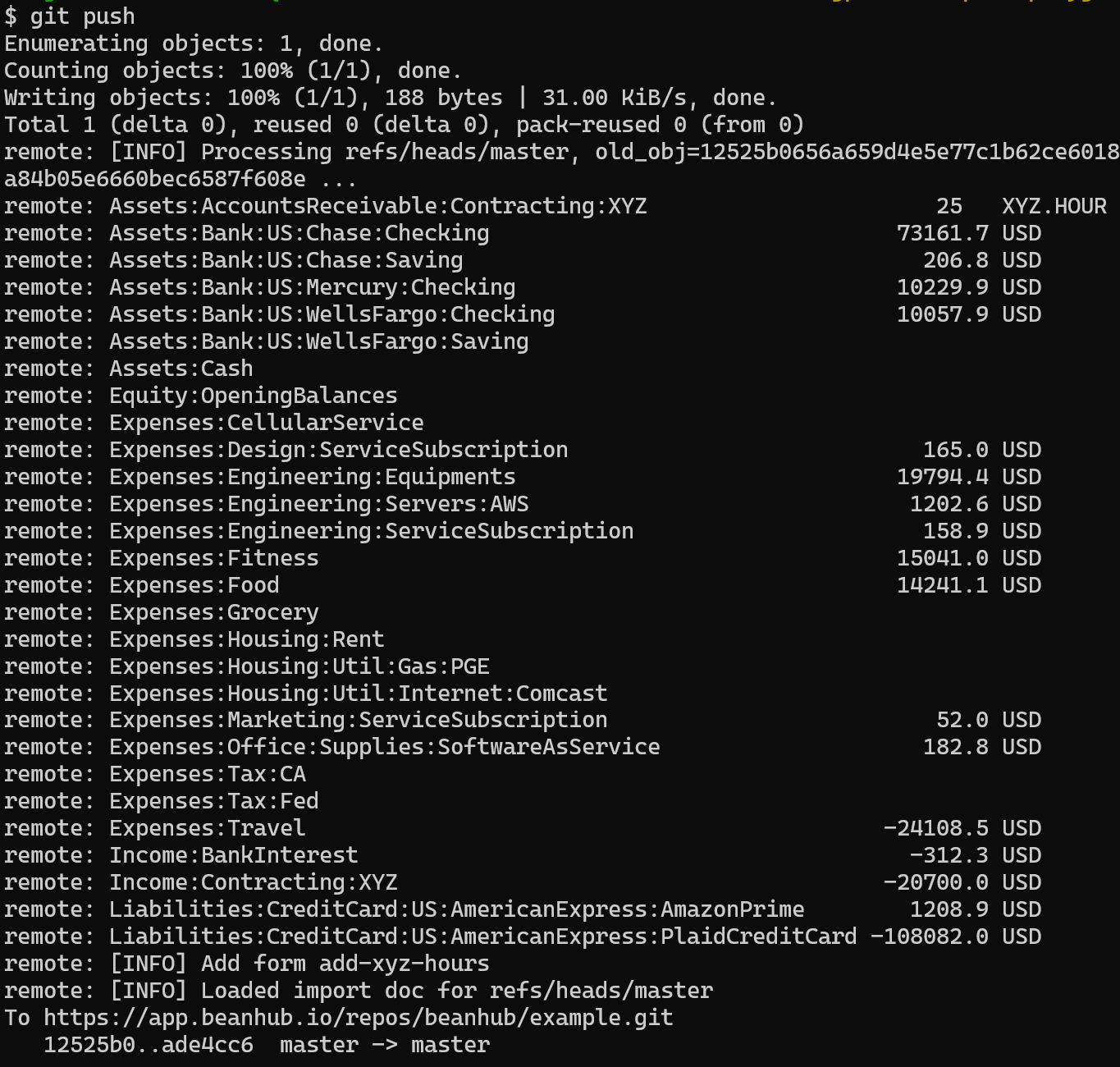 BeanHub 存储库 git push 控制台输出的屏幕截图,显示 Beancount 余额
BeanHub 存储库 git push 控制台输出的屏幕截图,显示 Beancount 余额
它只是一个带有某些 hooks 的托管 Git 存储库,所以应该不难,对吧?不,不幸的是,它非常困难。如果你不需要考虑以下因素,那么托管 Git 存储库并不难:
- 可扩展性
- 持久性
- 数据完整性
- 分叉
- 成本效益
- 安全性
如果你需要考虑所有这些因素,那么你基本上是从头开始构建一个 GitHub。是的,我为 BeanHub 自己做了这件事。它的工作方式值得另一篇完整的博客文章。事实上,我已经在这里写了它,如果你有兴趣:BeanHub 的工作原理,第 2 部分,基于容器层的大规模可审计 Git 存储库系统。 tl;dr,我使用带有 overlayfs 的容器来捕获在每个 git 操作中所做的更改。
 查看器看到上面的文件夹下面有较低的文件夹的图表,查看器通过将上层中引入的更改与下层结合起来,看到一个合并的文件夹
查看器看到上面的文件夹下面有较低的文件夹的图表,查看器通过将上层中引入的更改与下层结合起来,看到一个合并的文件夹
我在这里构建的技术使得托管具有自定义自动 hook 操作的许多 Git 存储库成为可能,我已经可以想到许多有趣的用例。我正在考虑将其剥离为独立的产品,从而支持基于 git 的“文件而非应用”软件。如果你对此感兴趣,请通过 fangpen@launchplatform.com 与我联系。如果足够多的人表达他们的兴趣,我可以实现它。请告诉我。
安全问题
安全是构建此类软件时需要考虑的另一个有趣的话题,尤其是在处理用户提供的文件时。即使 Beancount 文件看起来无辜且无害,但你可能会惊讶地发现,人们可以使用精心创建的文件轻松执行代码。这是一个例子:
main.bean:
option "insert_pythonpath" "true"
plugin "my_plugins"
2024-04-21 open Assets:Cash
2024-04-21 open Expenses:Food
2024-04-22 * "Dinner"
Assets:Cash -20.00 USD
Expenses:Food 20.00 USD
my_plugins.py:
__plugins__ = ["evil"]
def evil(entries, options):
print('!!ALL YOUR ACCOUNTING BOOKS ARE BELONG TO US!!')
return entries, []
幸运的是,我为我以前的雇主构建了一个大规模的数据管道,用于处理用户上传的具有潜在零日漏洞的数据。为了安全地处理它们,我学会了采用带有容器的沙盒技术。这是另一个值得一篇完整文章的有趣话题。猜猜怎么着?我已经写了一篇。如果你有兴趣,可以在这里找到它:BeanHub 的工作原理第 1 部分包含使用沙盒处理 Beancount 数据的危险。
 攻击者上传带有恶意代码的数据的图表,服务器在沙箱内处理它。攻击者的代码试图访问沙箱外部,但失败了。
攻击者上传带有恶意代码的数据的图表,服务器在沙箱内处理它。攻击者的代码试图访问沙箱外部,但失败了。
感谢基于容器的沙盒技术,BeanHub 在最近的 Jinja2 安全漏洞 中躲过了一劫,该漏洞允许由其 SandboxedEnvironment 提供支持的模板环境在某些情况下逃逸。因为所有操作都是在沙盒容器内完成的,所以除非攻击者可以破坏沙箱,否则它不会影响任何其他内容。我想这就是深度防御的意义所在——你不会依赖于单层防御。
产品构建者的冒名顶替者综合症
我对构建产品有信心。但是作为一名销售人员又是另一回事。我经常将我的产品与大公司的产品进行比较,并且我总是觉得我的产品缺少一些东西,以至于我无法自豪地销售它。我总是想,好吧,在添加 XYZ 功能后,它应该足够好了,到那时我应该更努力地销售它。但是在添加新功能后,我仍然觉得它还不够好,无法全力销售。
事实上,有一部分创业人士会告诉你,让我们先销售产品,然后再构建软件以进行扩展,例如在著名的 Do things don’t scale article 中描述的那样。我认为他们是对的,但是知道它是对的与做它是不同的。我希望我可以在产品甚至存在之前就销售它,但我更多的是一个构建者而不是一个销售者。自信心水平之间的差距使我几乎总是倾向于先构建然后再销售。
我的问题的另一个来源来自作为构建者的自豪感;我想推出一些经过润色的东西。害怕先推出你的想法,而其他人可能会在你之前做这件事也存在。我仍在学习如何克服这些并使自己朝着这种方法前进。即使采用先构建的方法,为了平衡构建者类型的创业公司创始人,我想一个经验法则可能是——如果它对你的内部用例足够好,那么它对其他人也足够好。想想看。构建这些产品需要一个由优秀工程师组成的完整团队;你应该为你自己或一个非常小的团队所构建的东西感到自豪。
你还需要教育用户并发展社区
虽然销售产品本身是一个挑战,但教你的用户如何使用它也是另一个挑战。纯文本复式簿记是一个非常小众的话题,并不是每个人都知道什么是复式簿记。它的一些概念也很难理解,例如为什么收入在 Beancount 中为负。为了帮助用户理解纯文本复式簿记,我还推出了 BeanHub Academy,这是一个关于使用 Beancount 进行纯文本复式簿记的教程。
 BeanHub Academy 网站主页的屏幕截图
BeanHub Academy 网站主页的屏幕截图
该教程仍在开发中。当然,如果他们阅读它,它会吸引一些潜在用户。我还没有足够长的时间来判断它的效果如何,但我相信,如果从长远来看,更多的人理解基于纯文本的复式簿记,那么它将有益于 BeanHub。
虽然我们提到了开源部分中对潜在竞争的恐惧,但现在我担心它还为时过早,因为现在没有竞争。当可寻址市场非常小时,最大的问题是扩大社区规模。因此,我赞助了 plaintextaccounting.org 网站,以换取广告爆炸,尽管其他开源工具可能会与我自己的工具竞争。
 纯文本会计网站的屏幕截图
纯文本会计网站的屏幕截图
该广告为 BeanHub 带来了许多用户;这是一项促进我的产品并帮助社区的绝佳投资;这是一个双赢的局面。
最后的想法
我希望你觉得我的文章有趣。正如我多次说过的,我认为构建软件就像一场马拉松。虽然我需要很长时间才能把事情做好,但是一旦它们做对了,积极的影响就可以持续更长时间。我还相信更多软件应该体现“文件而非应用”的理念,并让用户控制他们的数据。我希望看到更多像 BeanHub 和 Obsidian 这样的应用程序采用这种方法。
接下来是什么,你可能会问?
那么基于 LLM 的自动记账功能呢? 听起来是个好主意……嗯……你知道吗?也许不是 😅 除此之外,如果你对 BeanHub 有任何反馈,请随时通过 support@beanhub.io 与我们联系
这篇文章由我自己赞助🤣
 Monoline - Meet Monoline - 你的个人微型日记。
自由快速地写下你的想法,并在不同平台上跨设备实时自动同步。 简单来说,它是一个信使应用程序,但仅用于发送给自己 🤯
立即尝试
此广告由 PolisNetwork 提供支持
Monoline - Meet Monoline - 你的个人微型日记。
自由快速地写下你的想法,并在不同平台上跨设备实时自动同步。 简单来说,它是一个信使应用程序,但仅用于发送给自己 🤯
立即尝试
此广告由 PolisNetwork 提供支持
分享这篇文章! [](https://twitter.com/intent/tweet?text=My Beancount books are 95% automatic after 3 years&url=https://fangpenlin.com/posts/2024/12/30/my-beancount-books-are-95-percent-automatic/> "在 Twitter 上分享") [](https://www.linkedin.com/shareArticle?url=https://fangpenlin.com/posts/2024/12/30/my-beancount-books-are-95-percent-automatic/&title=My Beancount books are 95% automatic after 3 years> "在 LinkedIn 上分享") [](https://reddit.com/submit?url=https://fangpenlin.com/posts/2024/12/30/my-beancount-books-are-95-percent-automatic/&title=My Beancount books are 95% automatic after 3 years> "在 Reddit 上分享") [](https://news.ycombinator.com/submitlink?u=https://fangpenlin.com/posts/2024/12/30/my-beancount-books-are-95-percent-automatic/&t=My Beancount books are 95% automatic after 3 years> "在 Hacker News 上分享")
最近的文章:
Nvidia GPU on bare metal NixOS Kubernetes cluster explained
MAZE - My AI models are finally evolving!
MAZE - How I would build AGI
主题由 <3 创建 John Otander (@4lpine). </> 可在 Github 上找到.