GoStringUngarbler:反混淆 Garble 加密二进制文件中的字符串
跳转到内容 Cloud Blog 联系销售免费开始使用 Cloud Blog 解决方案与技术 安全 生态系统 行业
-
解决方案与技术
-
生态系统
-
安全
-
行业
-
解决方案与技术
-
生态系统
GoStringUngarbler:反混淆 Garble 加密二进制文件中的字符串 2025年3月5日
Mandiant
作者:Chuong Dong
概述
在我们的日常工作中,FLARE 团队经常遇到使用 Go 编写并使用 garble 保护的恶意软件。虽然像 IDA Pro 这样的工具在 Go 分析方面的最新进展简化了分析过程,但 garble 带来了一系列独特的挑战,包括stripped binaries、函数名称 mangling 和加密字符串。
Garble 的字符串加密虽然相对简单,但严重阻碍了静态分析。在这篇博文中,我们将详细介绍 garble 的字符串转换以及自动反混淆它们的过程。
我们还将介绍 GoStringUngarbler,这是一个用 Python 编写的命令行工具,可自动解密在 garble 混淆的 Go 二进制文件中找到的字符串。该工具可以通过生成一个反混淆的二进制文件来简化逆向工程过程,其中所有字符串都已恢复并以纯文本显示,从而简化静态分析、恶意软件检测和分类。
获取 GoStringUngarbler!
GoStringUngarbler 现在可以作为 Mandiant 的 GitHub 存储库中的开源工具使用。该工具仅提取 garble 运行时带有标志“-literals”的二进制文件的字符串。当恶意软件分析师遇到用 garble 的字面转换混淆的样本时,这将有助于显着加快分析过程。 立即下载
Garble 混淆编译器
在详细介绍 GoStringUngarbler 工具之前,我们想简要解释一下 garble 编译器如何修改 Go 二进制文件的构建过程。通过包装官方 Go 编译器,garble 在编译期间通过使用 Go 的 go/ast 库进行抽象语法树 (AST) 操作来对源代码执行转换。在这里,混淆编译器修改程序元素以混淆生成的二进制文件,同时保持程序的语义完整性。一旦被 garble 转换后,程序的 AST 被反馈到 Go 编译管道中,生成一个更难进行逆向工程和静态分析的可执行文件。
虽然 garble 可以对源代码应用各种转换,但本博文将重点关注其“字面量”转换。当使用 -literals 标志执行 garble 时,它会将源代码和导入的 Go 库中的所有字面字符串转换为混淆形式。每个字符串都被编码并包装在一个解密函数后面,从而阻止静态字符串分析。
对于每个字符串,混淆编译器可以随机应用以下字面量转换之一。我们将在后续章节中更详细地探讨每一种。
- 栈转换:此方法实现运行时编码,以直接存储在栈上的字符串。
- 种子转换:此方法采用基于动态种子的加密机制,其中种子值随着每个加密字节而演变,从而创建一系列相互依赖的加密操作。
- 分割转换:此方法将加密字符串分成多个块,每个块在主 switch 语句块中独立解密。
栈转换
garble 中的栈转换实现了直接在栈上运行的运行时加密技术,使用三种不同的转换类型:simple、swap 和 shuffle。这些名称直接取自 garble 的源代码。这三种都使用驻留在栈上的字符串执行加密操作,但每一种在复杂性和数据操作方法上都不同。
- 简单转换: 此转换应用字节对字节编码,使用随机生成的数学运算符和与输入字符串长度相等的随机生成的密钥。
- 交换转换: 此转换应用字节对交换和位置相关编码的组合,其中字节对被打乱并使用动态生成的本地密钥进行加密。
- 混洗转换: 此转换通过使用随机密钥对数据进行编码,将加密数据与其密钥交错,并应用基于 XOR 的索引映射进行置换,以将加密数据和密钥分散到整个最终输出中,从而应用多层加密。
简单转换
此转换在 AST 级别实现了一个简单的字节级别编码方案。以下是 来自 garble 存储库的实现。在图 1 和后续从 garble 存储库获取的代码示例中,作者添加了注释以提高可读性。
// 生成与输入字符串长度相同的随机密钥
key := make([]byte, len(data))
// 用随机字节填充密钥
obfRand.Read(key)
// 选择一个随机运算符(XOR、ADD、SUB)用于加密
op := randOperator(obfRand)
// 使用随机运算符和密钥加密数据的每个字节
for i, b := range key {
data[i] = evalOperator(op, data[i], b)
}
图 1:简单转换实现 混淆器首先生成一个与输入字符串长度相等的随机密钥。然后,它随机选择一个可逆的算术运算符(XOR、加法或减法),该运算符将在整个编码过程中使用。
混淆是通过同时迭代数据和密钥字节来执行的,并在每对对应的字节之间应用所选运算符以生成编码的输出。
图 2 显示了 IDA 生成的此转换类型的解密子程序的反编译代码。
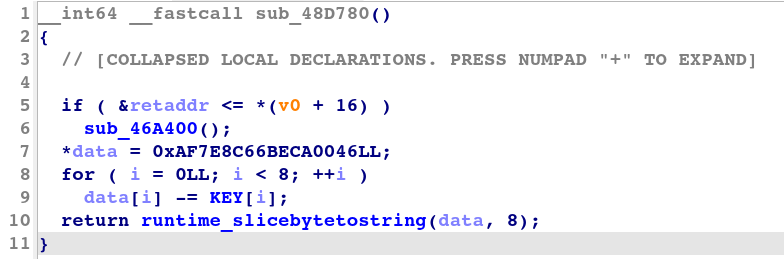 图 2:简单转换解密子程序的反编译代码
图 2:简单转换解密子程序的反编译代码
交换转换
交换转换使用字节混洗和加密算法来加密字符串字面量。图 3 显示了 来自 garble 存储库的实现。
// 根据数据长度确定要执行的交换操作数
func generateSwapCount(obfRand *mathrand.Rand, dataLen int) int {
// 从等于数据长度的交换次数开始
swapCount := dataLen
// 计算最大额外交换(数据长度的一半)
maxExtraPositions := dataLen / 2
// 如果我们可以添加额外的职位,则添加一个随机数
if maxExtraPositions > 1 {
swapCount += obfRand.Intn(maxExtraPositions)
}
// 通过递增来确保交换计数为偶数(如果为奇数)
if swapCount%2 != 0 {
swapCount++
}
return swapCount
}
func (swap) obfuscate(obfRand *mathrand.Rand, data []byte)
*ast.BlockStmt {
// 生成要执行的交换操作数
swapCount := generateSwapCount(obfRand, len(data))
// 生成一个随机移位密钥
shiftKey := byte(obfRand.Uint32())
// 选择一个随机的可逆运算符进行加密
op := randOperator(obfRand)
// 生成用于交换字节的随机位置列表
positions := genRandIntSlice(obfRand, len(data), swapCount)
// 逆序处理位置对
for i := len(positions) - 2; i >= 0; i -= 2 {
// 为每对生成一个位置相关的本地密钥
localKey := byte(i) + byte(positions[i]^positions[i+1]) + shiftKey
// 执行交换和加密:
// - 交换 positions[i] 和 positions[i+1]
// - 使用本地密钥加密每个位置的字节
data[positions[i]], data[positions[i+1]] = evalOperator(op,
data[positions[i+1]], localKey), evalOperator(op, data[positions[i]],
localKey)
}
...
图 3:交换转换实现 转换首先生成偶数个随机交换位置,该位置基于数据长度加上随机数量的额外位置(限制为数据长度的一半)。然后,编译器使用此长度随机生成一个随机交换位置列表。
核心混淆过程通过逆序迭代位置对来运行,对每对执行交换操作和加密。对于每次迭代,它通过组合迭代索引、当前位置对的 XOR 结果和一个随机移位密钥来生成一个位置相关的本地加密密钥。然后,此本地密钥用于使用随机选择的可逆运算符加密交换的字节。
图 4 显示了 IDA 生成的交换转换解密子程序的反编译代码。
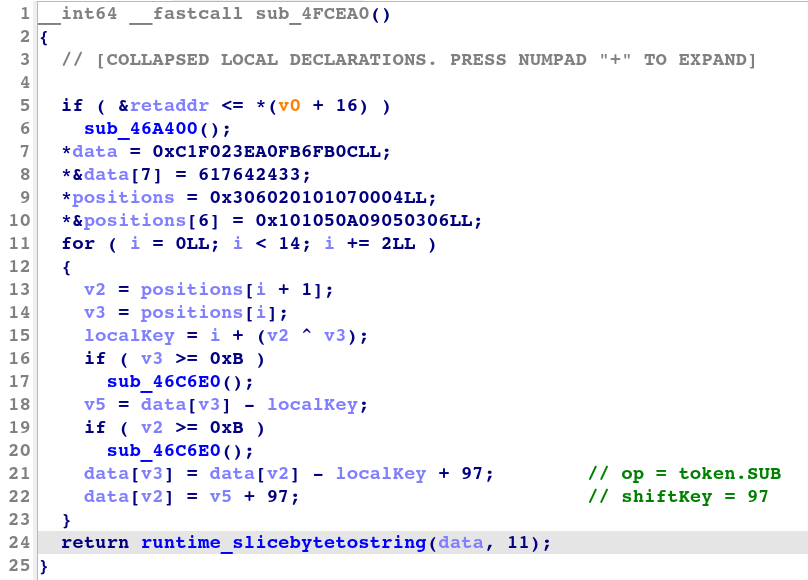 图 4:交换转换解密子程序的反编译代码
图 4:交换转换解密子程序的反编译代码
混洗转换
混洗转换是三种栈转换类型中最复杂的。在这里,garble 通过使用随机密钥加密原始字符串,将加密数据与其密钥交错,并将加密数据和密钥分散到整个最终输出中来应用其混淆。图 5 显示了 来自 garble 存储库的实现。
// 生成与原始字符串长度相同的随机密钥
key := make([]byte, len(data))
obfRand.Read(key)
// 索引密钥大小边界的常量
const (
minIdxKeySize = 2
maxIdxKeySize = 16
)
// 将索引密钥大小初始化为最小值
idxKeySize := minIdxKeySize
// 可能会根据输入数据长度增加索引密钥大小
if tmp := obfRand.Intn(len(data)); tmp > idxKeySize {
idxKeySize = tmp
}
// 将索引密钥大小限制为最大值
if idxKeySize > maxIdxKeySize {
idxKeySize = maxIdxKeySize
}
// 生成一个用于索引加扰的辅助密钥(索引密钥)
idxKey := make([]byte, idxKeySize)
obfRand.Read(idxKey)
// 创建一个将同时保存加密数据和密钥的缓冲区
fullData := make([]byte, len(data)+len(key))
// 为完整数据缓冲区中的每个位置生成随机运算符
operators := make([]token.Token, len(fullData))
for i := range operators {
operators[i] = randOperator(obfRand)
}
// 加密数据并将其与其对应的密钥一起存储
// 前半部分包含加密数据,后半部分包含密钥
for i, b := range key {
fullData[i], fullData[i+len(data)] = evalOperator(operators[i],
data[i], b), b
}
// 生成索引的随机置换
shuffledIdxs := obfRand.Perm(len(fullData))
// 应用置换来分散加密数据和密钥
shuffledFullData := make([]byte, len(fullData))
for i, b := range fullData {
shuffledFullData[shuffledIdxs[i]] = b
}
// 为解密准备 AST 表达式
args := []ast.Expr{ast.NewIdent("data")}
for i := range data {
// 从索引密钥中选择一个随机字节
keyIdx := obfRand.Intn(idxKeySize)
k := int(idxKey[keyIdx])
// 构建 AST 表达式进行解密:
// 1. 使用 XOR 和索引密钥来查找数据和密钥的真实位置
// 2. 应用反向运算符以使用对应的密钥解密数据
args = append(args, operatorToReversedBinaryExpr(
operators[i],
// 使用 XOR ed 索引访问加密数据
ah.IndexExpr("fullData", &ast.BinaryExpr{X: ah.IntLit(shuffledIdxs[i]
^ k), Op: token.XOR, Y: ah.CallExprByName("int", ah.IndexExpr("idxKey",
ah.IntLit(keyIdx)))}),
// 使用 XOR ed 索引访问对应的密钥
ah.IndexExpr("fullData", &ast.BinaryExpr{X:
ah.IntLit(shuffledIdxs[len(data)+i] ^ k), Op: token.XOR, Y:
ah.CallExprByName("int", ah.IndexExpr("idxKey", ah.IntLit(keyIdx)))}),
))
}
图 5:混洗转换实现 Garble 首先生成两种类型的密钥:一个与输入字符串长度相同的主密钥用于数据加密,以及一个较小的索引密钥(介于 2 和 16 个字节之间)用于索引加扰。然后,转换过程按以下四个步骤进行:
- 初始加密: 使用随机生成的具有其对应密钥字节的可逆运算符来加密输入数据的每个字节。
- 数据交错: 加密数据和密钥字节被组合成一个缓冲区,加密数据位于前半部分,对应的密钥位于后半部分。
- 索引置换: 密钥数据缓冲区经历随机置换,从而将加密数据和密钥分散到整个缓冲区中。
- 索引加密: 通过使用来自索引密钥的随机选择的字节 XOR ed 置换索引来进一步混淆对置换数据的访问。
图 6 显示了 IDA 生成的混洗转换解密子程序的反编译代码。
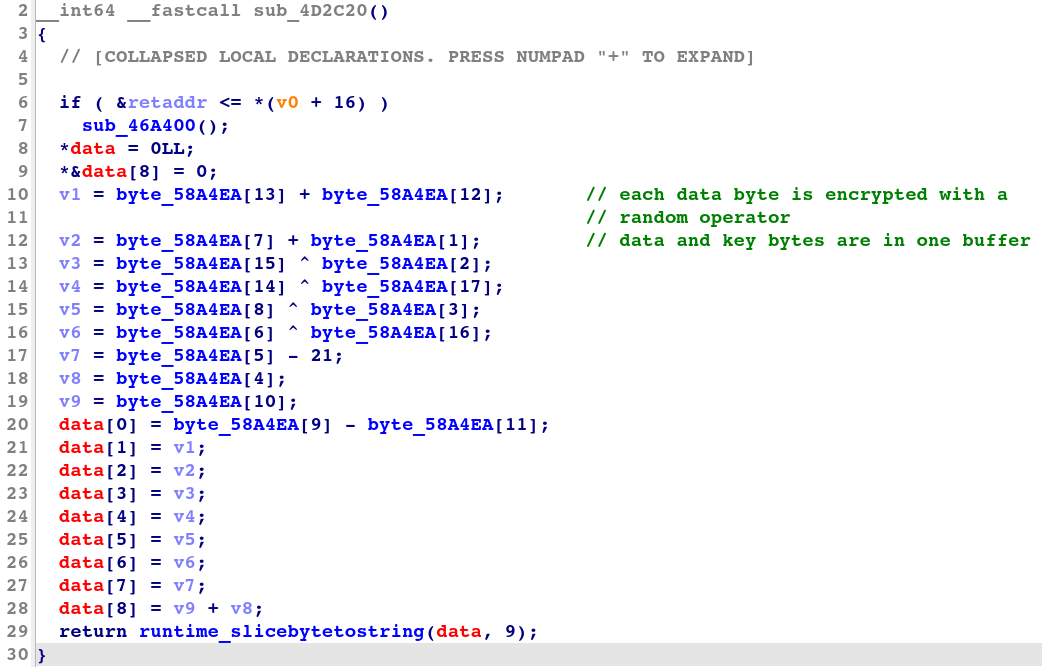 图 6:混洗转换解密子程序的反编译代码
图 6:混洗转换解密子程序的反编译代码
种子转换
种子转换实现了一种链式编码方案,其中每个字节的加密都依赖于通过连续更新的种子值进行的先前加密。图 7 显示了 来自 garble 存储库的实现。
// 生成随机的初始种子值
seed := byte(obfRand.Uint32())
// 存储原始种子以供以后在解密中使用
originalSeed := seed
// 选择一个随机的可逆运算符进行加密
op := randOperator(obfRand)
var callExpr *ast.CallExpr
// 加密每个字节,同时构建函数调用链
for i, b := range data {
// 使用当前种子值加密当前字节
encB := evalOperator(op, b, seed)
// 通过添加加密字节来更新种子
seed += encB
if i == 0 {
// 使用第一个加密字节启动函数调用链
callExpr = ah.CallExpr(ast.NewIdent("fnc"), ah.IntLit(int(encB)))
} else {
// 将后续加密字节添加到函数调用链
callExpr = ah.CallExpr(callExpr, ah.IntLit(int(encB)))
}
}
...
图 7:种子转换实现 Garble 首先随机生成一个种子值用于加密。当编译器迭代输入字符串时,通过使用随机运算符和当前种子来加密每个字节,并通过添加加密字节来更新种子。在此种子转换中,每个字节的加密都依赖于前一个字节的结果,从而通过连续更新的种子创建依赖项链。
在解密设置中,如图 8 中的 IDA 反编译代码所示,混淆器生成一个对解密函数的调用链。对于以第一个开始的每个加密字节,解密函数应用运算符以使用当前种子来解密它,并通过将加密字节添加到其中来更新种子。由于此设置,由于它在解密过程中进行多次函数调用,因此这种转换类型的子程序很容易在反编译器和反汇编视图中识别。
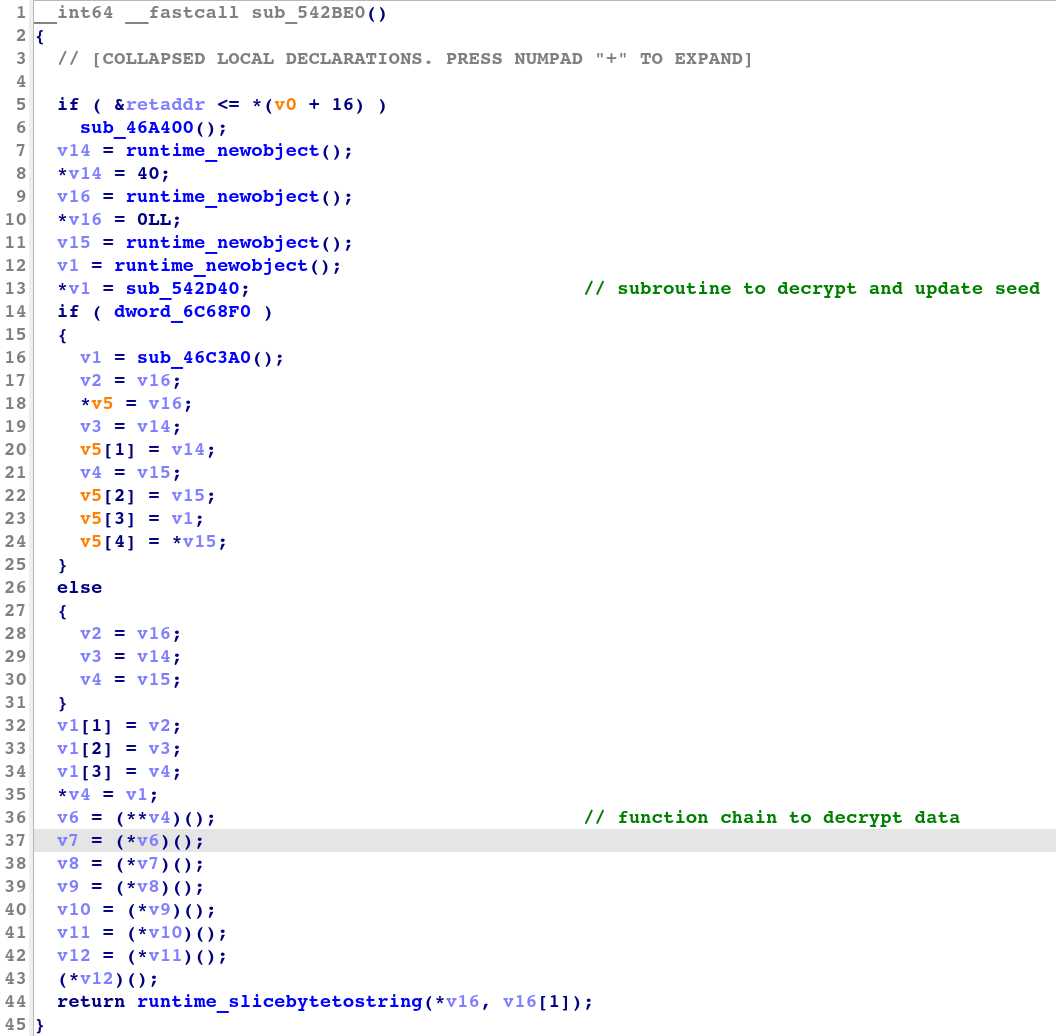 图 8:种子转换解密子程序的反编译代码
图 8:种子转换解密子程序的反编译代码
 图 9:种子转换解密子程序的反汇编代码
图 9:种子转换解密子程序的反汇编代码
分割转换
分割转换是 garble 最复杂的字符串转换技术之一,它实现了一种多层方法,该方法结合了数据碎片、加密和控制流操作。图 10 显示了 [来自 garble 存储库的实现](https://cloud.google.com/blog/topics/threat-intelligence/<https:/github.com/burrowers