Strobelight:一个基于开源技术构建的性能分析服务
搜索此站点 ![]()
- Open Source
- Platforms
- Infrastructure Systems
- Physical Infrastructure
- Video Engineering & AR/VR
- Artificial Intelligence
- Watch Videos
发布于 2025 年 1 月 21 日,归类于 Open Source, Production Engineering
Strobelight:一个基于开源技术构建的性能分析服务
 作者:Jordan Rome
作者:Jordan Rome
- 我们将分享关于 Strobelight 的详细信息,它是 Meta 的性能分析编排器。
- Strobelight 将多种技术(许多是开源的)组合成一个单一的服务,帮助 Meta 的工程师提高整个集群的效率和利用率。
- 使用 Strobelight,我们已经看到了显著的效率提升,其中一项每年估计可节省 15,000 台服务器的容量。
Strobelight 是 Meta 的性能分析编排器,实际上并不是单一的技术。它是由多种(许多是开源的)技术组合而成,创造出令人惊叹的效率提升。Strobelight 也不是一个单一的性能分析器,而是多个不同性能分析器(甚至是临时的性能分析器)的编排器,它在 Meta 的所有生产主机上运行,收集关于 CPU 使用率、内存分配以及运行进程的其他性能指标的详细信息。工程师和开发者可以使用这些信息来识别性能和资源瓶颈,优化他们的代码,并提高利用率。
当您将有才华的工程师与丰富的性能数据相结合时,您可以通过创建工具在问题到达生产环境之前识别它们,并发现已运行代码中的机会,从而获得效率上的提升。假设一位工程师修改了代码,从而在服务的关键路径上引入了一个大型对象的意外拷贝。Meta 现有的工具可以识别这个问题,并查询 Strobelight 数据来估计对计算成本的影响。然后,Meta 的代码审查工具可以通知该工程师,他们将要浪费,比如,20,000 台服务器。
当然,静态分析工具可以发现这类问题,但它们不了解全局计算成本,而且通常这些效率低下只有在逐渐为每分钟数百万个请求提供服务时才会成为问题。就像温水煮青蛙。
为什么使用性能分析器?
性能分析器通过采样数据来进行统计分析。例如,一个性能分析器每 N 个事件(或时间分析器中的毫秒)进行一次采样,以了解该事件发生的位置或该事件发生时的状况。例如,对于 CPU 周期事件,分析将显示在 CPU 上执行的函数或函数调用栈中花费的 CPU 时间。这可以让工程师对服务或二进制文件的代码执行有一个高层次的理解。
通过 Strobelight 选择您自己的冒险
Meta 还有其他守护进程收集可观测性指标,但 Strobelight 的专长是软件性能分析。它将资源使用情况与源代码(开发者最容易理解的内容)联系起来。Strobelight 的性能分析器通常(但并非总是)使用 eBPF 构建,这是一种 Linux 内核技术。eBPF 允许将自定义代码安全地注入到内核中,从而能够以非常低的开销收集不同类型的数据,并在可观测性领域释放了如此多的可能性,以至于很难想象没有它 Strobelight 将如何工作。
在撰写本文时,Strobelight 有 42 个不同的性能分析器,包括:
- 由 jemalloc 支持的内存分析器。
- 函数调用计数分析器。
- 基于事件的分析器,用于原生和非原生语言(例如,Python、Java 和 Erlang)。
- AI/GPU 分析器。
- 跟踪 off-CPU 时间的分析器。
- 跟踪服务请求延迟的分析器。
工程师可以利用其中的任何一个,通过 Strobelight 的命令行工具或 Web UI,按需从服务器收集数据。
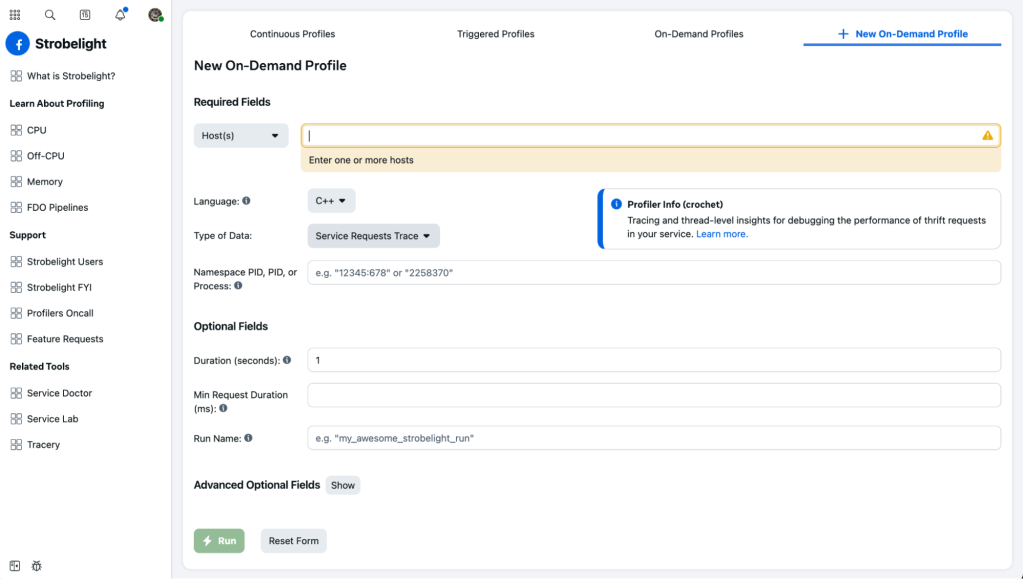 Strobelight Web UI。
Strobelight Web UI。
用户还可以通过更新 Meta 的 Configerator 中的配置文件,为任何这些性能分析器设置连续或“触发”的性能分析,从而允许他们定位整个服务,或者,例如,仅定位在特定区域中运行的主机。用户可以指定这些性能分析器应该运行的频率、运行持续时间、符号化策略、他们想要定位的进程等等。
这是一个简单的性能分析器配置示例:
add_continuous_override_for_offcpu_data(
"my_awesome_team", // 拥有此服务的团队
Type.SERVICE_ID,
"my_awesome_service",
30_000, // 每小时所需的样本数
)
为什么 Strobelight 有这么多性能分析器?因为在这些由如此多不同技术驱动的系统中,发生着如此多不同的事情。
这也是 Strobelight 提供 ad-hoc 性能分析器的原因。由于可以从二进制文件中收集的数据类型非常多样,工程师通常需要 Strobelight 没有现成提供的功能。从头开始向 Strobelight 添加新的性能分析器需要进行多次代码更改,并且可能需要几周的时间才能完成审查和推出。
但是,工程师可以编写一个 bpftrace 脚本(一种简单的语言/工具,允许您轻松编写 eBPF 程序),并告诉 Strobelight 像运行其他性能分析器一样运行它。例如,如果一个工程师非常关心特定 C++ 函数的延迟,则可以编写一个小 bpftrace 脚本,提交它,并让 Strobelight 在 Meta 集群中的任意数量的主机上运行它——如果需要,所有这些都可以在几个小时内完成。
如果所有这些听起来都非常强大且危险,那是因为它确实如此。但是,Strobelight 采取了多项安全措施,以防止用户导致目标工作负载的性能下降,以及 Strobelight 写入的数据库的保留问题。Strobelight 还具有足够的感知能力,以确保不同的性能分析器不会相互冲突。例如,如果一个性能分析器正在跟踪 CPU 周期,Strobelight 会确保另一个性能分析器不能同时使用另一个 PMU 计数器(因为还有其他服务也在使用它们)。
Strobelight 还有并发规则和性能分析器排队系统。当然,如果服务所有者想要提取大量数据进行调试,他们仍然可以灵活地真正地压榨他们的机器。
每个人的默认数据
自成立以来,Strobelight 的核心原则之一是为 Meta 的所有服务提供自动、定期收集的性能分析数据。它就像一个飞行记录器——在需要之前不必考虑的事情。还有什么比醒来时收到服务不健康的警报,但没有任何数据说明原因更糟糕的呢?
因此,Strobelight 有一些精心挑选的性能分析器,这些分析器配置为在每个 Meta 主机上自动运行。它们不会一直运行;那样会“很糟糕”,也不太算是“性能分析”。相反,它们具有针对主机上运行的工作负载的自定义运行间隔和采样率。这提供了适量的数据,而不会影响分析的服务或使存储 Strobelight 数据的系统负担过重。
这是一个例子:
一项名为 Soft Server 的服务在 1,000 台主机上运行,假设我们希望性能分析器 A 为该服务每小时收集 40,000 个 CPU 周期样本(记住上面的配置)。Strobelight 知道 Soft Server 在多少台主机上运行,但不知道它的 CPU 密集程度,因此将从保守的运行概率开始,这是一种防止偏差的采样机制(例如,每天中午分析这些主机将隐藏流量模式)。
第二天,Strobelight 将查看它能够为该服务收集多少样本,然后自动调整运行概率(通过一些非常简单的数学运算),以尝试达到每小时 40,000 个样本。我们称之为动态采样,Strobelight 每天都会为 Meta 的每个服务进行此重新调整。
如果主机上运行多个服务(不包括 systemd 或 Strobelight 等守护程序),则 Strobelight 将默认使用配置,该配置将为两者产生更多样本。
等等,等等。如果服务的运行概率或采样率因主机而异,那么如何跨主机聚合或比较数据呢?以及如何比较多个服务的性能分析数据?
由于 Strobelight 知道所有这些不同的性能分析器调整旋钮,因此它会在记录时调整配置文件样本的“权重”。样本的权重用于标准化数据,并在汇总分析或查看此数据时防止偏差。因此,即使 Strobelight 在一台主机上分析 Soft Server 的频率低于在另一台主机上分析的频率,也可以准确地比较和分组样本。这也适用于比较两个不同的服务,因为服务所有者使用 Strobelight 来查看其特定服务,而效率专家则在共享库中寻找跨集群的“横向”优势。
Strobelight 如何节省容量
有两个默认的持续性能分析器应该被提及,因为它们最终节省了大量的容量。
last branch record (LBR) 分析器
LBR 分析器,名副其实,用于采样 last branch records(一种始于 Intel 的硬件功能)。来自此分析器的数据不会被可视化,而是被馈送到 Meta 的反馈定向优化 (FDO) 管道中。这些数据用于创建 FDO 配置文件,这些配置文件在编译时 (CSSPGO) 和编译后 (BOLT) 使用,通过增加运行时行为的知识来加速二进制文件。Meta 最大的 200 个服务都有来自 LBR 数据的 FDO 配置文件,这些数据是在整个集群中持续收集的。其中一些服务的 CPU 周期减少了 20%,相当于 Meta 运行这些服务所需的服务器数量减少了 10-20%。
事件分析器
第二个分析器是 Strobelight 的事件分析器。这是 Strobelight 版本的 Linux perf 工具。它的主要工作是从多个性能 (perf) 事件(例如,CPU 周期、L3 缓存未命中、指令等)收集用户和内核堆栈跟踪。不仅个人工程师会查看这些数据来了解最热门的函数和调用路径是什么,而且这些数据还会被馈送到监控和测试工具中以识别回归;理想情况下是在它们到达生产环境_之前_。
有人提到 Meta…数据吗?
使用 火焰图 查看函数调用堆栈是很棒的,我并不反对它。但是,查看来自其服务的调用堆栈的服务所有者(该服务导入了许多库并使用了 Meta 的软件框架)将会看到很多“外部”函数。此外,如何仅查找 p99 延迟请求的堆栈?或者服务在哪些地方进行了非预期的字符串复制?
堆栈模式
Strobelight 具有多种机制,可以根据用户的需求增强其生成的数据。其中一种机制称为堆栈模式(灵感来自 Microsoft 的堆栈标签),这是一种小型 DSL,可在调用堆栈上运行,并可用于将标签(字符串)添加到整个调用堆栈或单个帧/函数。然后可以在我们的可视化工具中使用这些标签。堆栈模式还可以通过正则表达式匹配删除用户不关心的函数。可以按服务甚至按配置文件应用任意数量的模式来自定义数据。
甚至有人从这些元数据创建仪表板,以帮助其他工程师识别昂贵的复制、使用效率低或不合适的 C++ 容器、过度使用智能指针等等。可以执行此操作的静态分析工具已经存在很长时间了,但它们无法精确定位这些问题在大量机器中的真正痛苦或计算成本高昂的实例。
Strobemeta
Strobemeta 是另一种机制,它利用线程局部存储,在运行时将动态元数据的位附加到我们在事件分析器(以及其他分析器)中收集的调用堆栈。这是使用 eBPF 构建分析器的最大优势之一:在采样时采取复杂且自定义的操作。收集的 Strobemeta 用于将调用堆栈归因于特定的服务端点、请求延迟指标或请求标识符。同样,这允许工程师和工具进行更复杂的过滤,以集中 Strobelight 分析器生成的大量数据。
符号化
现在是讨论符号化的好时机:获取指令的虚拟地址,将其转换为实际的符号(函数)名称,并根据符号化策略,还可以获取函数的源文件、行号和类型信息。
大多数时候,获得整个 enchilada 意味着使用二进制文件的 DWARF 调试信息。但这可能有很多兆字节(甚至千兆字节)的大小,因为 DWARF 调试数据包含的不仅仅是符号信息。
需要下载然后解析此数据。但是在进行性能分析时,甚至之后在收集配置文件的同一主机上尝试这样做,其计算成本都太高了。即使使用最佳缓存策略,也可能导致主机工作负载的内存问题。
Strobelight 通过一个符号化服务来解决这个问题,该服务利用多种开源技术,包括 DWARF、ELF、gsym 和 blazesym。在配置文件结束时,Strobelight 将二进制地址堆栈发送到服务,该服务发送回带有文件、行、类型信息甚至内联信息的符号化堆栈。
它可以做到这一点,因为它已经完成了下载和解析 Meta 每个二进制文件(特别是生产二进制文件)的 DWARF 数据的繁重工作,并将它需要的内容存储在数据库中。然后,它可以为来自在整个集群中运行的不同 Strobelight 实例的多个符号化请求提供服务。
为了增加 enchilada(饿了吗?),Strobelight 还会延迟符号化,直到性能分析完成后,并将原始数据存储到磁盘,以防止主机上的内存抖动。这还有一个额外的好处,即不允许使用者影响生产者——这意味着如果 Strobelight 的用户空间代码无法处理 eBPF 内核代码生成样本的速度(因为它花费时间进行符号化或进行其他处理),则会导致样本丢失。
所有这些都得益于 Meta 所有用户空间二进制文件中包含的 帧指针,否则我们将无法遍历堆栈来获取所有这些地址(或者我们必须做一些其他复杂/昂贵的事情,那将效率不高)。
 简化的 Strobelight 服务图。
简化的 Strobelight 服务图。
展示数据(并使其美观)!
Strobelight 客户使用的主要工具是 Scuba——一种查询语言(如 SQL)、数据库和 UI。Scuba UI 为人们构建的查询提供了一套大型可视化工具(例如,火焰图、饼图、时间序列图、分布图等)。
在大多数情况下,Strobelight 生成 Scuba 数据,通常,这是一个快乐的结合。如果有人运行按需配置文件,只需几秒钟即可在 Scuba UI 中可视化这些数据(并向人们发送链接)。甚至像 Perfetto 这样的工具也公开了查询底层数据的能力,因为他们知道不可能尝试设计出足够的下拉菜单和按钮,来表达您想要在查询语言中表达的所有内容——尽管 Scuba UI 已经很接近了。
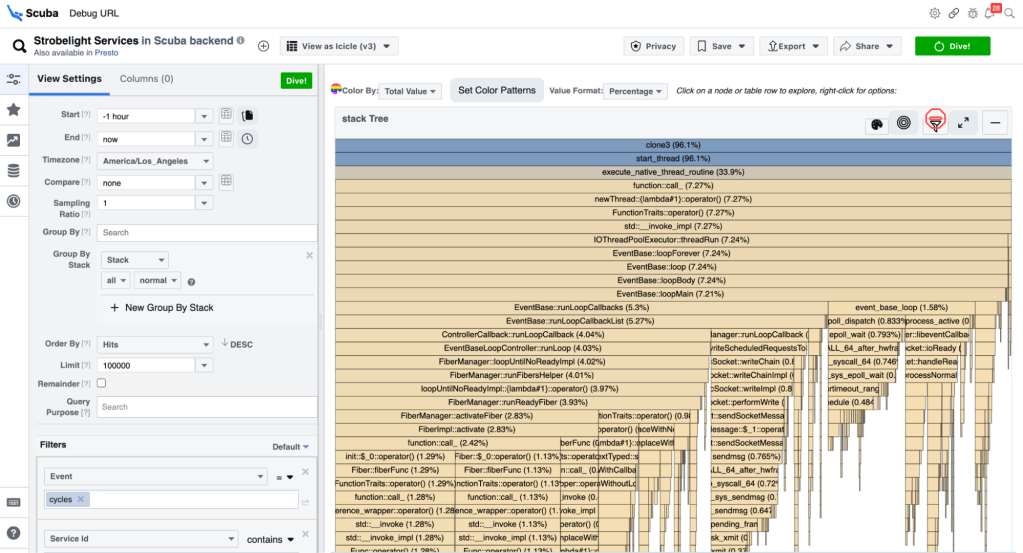 mononoke 服务一小时的 CPU 周期事件的函数调用堆栈的火焰图/冰柱图示例。
mononoke 服务一小时的 CPU 周期事件的函数调用堆栈的火焰图/冰柱图示例。
另一个工具是在 Meta 使用的跟踪可视化工具,名为 Tracery。当我们想要在一个屏幕上组合相关但不同的配置文件数据流时,我们会使用此工具。这些数据也很适合在时间线上查看。Tracery 允许用户创建自定义可视化工具和精心挑选的工作区,与其他工程师分享,以精确定位该数据的重要部分。它还由客户端柱状数据库(用 JavaScript 编写!)提供支持,这使得它在缩放和过滤时非常快。Strobelight 的 Crochet 分析器结合了服务请求跨度、CPU 周期堆栈和 off-CPU 数据,为用户提供了其服务的详细快照。
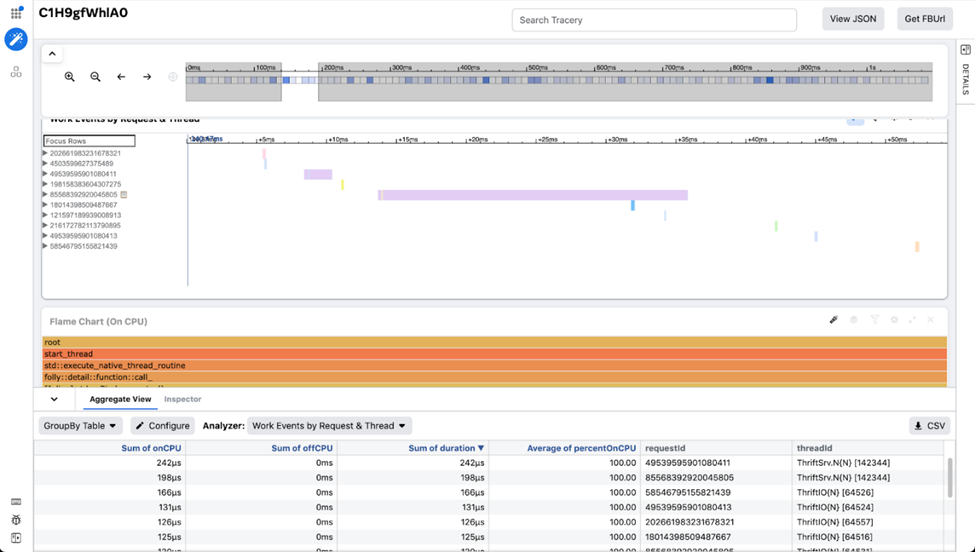 Tracery 中的跟踪示例。
Tracery 中的跟踪示例。
最大的“&”
Strobelight 帮助 Meta 的工程师实现了无数的效率和延迟提升,从增加所服务的请求数量,到大大减少堆分配,再到在预生产分析工具中捕获回归。
但最显着的胜利之一是我们称之为“最大的 &”。
一位经验丰富的性能工程师正在浏览 Strobelight 数据,并发现通过过滤特定的 std::vector 函数调用(使用符号化的文件和行号),他可以识别 C++ 中使用“auto”关键字时无意中发生的计算成本高昂的数组复制。
工程师转动了一些旋钮,调整了他的 Scuba 查询,并且碰巧在 Meta 最大的广告服务之一的热门调用路径中注意到其中一个副本。然后,他打开代码编辑器以调查此特定向量副本是否是有意的……事实并非如此。
这是任何在 C++ 中工作的工程师都犯过一百次的简单错误。
因此,工程师在 auto 关键字后输入了一个“&”,以表明我们想要一个引用而不是副本。这是一个单字符提交,在发布到生产环境后,相当于每年节省约 15,000 台服务器的容量!
回去重新阅读该句子。一个 & 符号!
一个开放的结局
这只是 Strobelight 可以做的所有事情的冰山一角。Strobelight 团队与 Meta 的性能工程师密切合作,开发新功能,可以更好地分析代码,以帮助精确定位速度慢、计算成本高昂以及原因。
我们目前正在 开源 Strobelight 的性能分析器和库,这无疑会使它们更强大和更有用。Strobelight 使用的大多数技术已经是公共或开源的,因此请使用它们并为它们做出贡献!
致谢
特别感谢 Wenlei He、Andrii Nakryiko、Giuseppe Ottaviano、Mark Santaniello、Nathan Slingerland、Anita Zhang 和 Meta 的性能分析器团队。