深入探索 Git 新的 bundle-URI 特性
GitButler 正在构建一种全新的 Git 使用方式。下载我们的客户端 或查看我们的源代码。
几秒前 由 Scott Chacon 发布 — 8 分钟阅读
深入探索 Git 新的 bundle-URI 特性
Git 新的 bundle-uri 功能可以显著加速克隆速度,但是其中潜藏着什么问题呢?
这是一个关于我尝试研究一个有点冷门的 Git 特性,结果却掉入了一个漫长而曲折的兔子洞,最终只提交了一个非常小的 Git 代码补丁的故事。准备好了吗?
什么是 bundle-uri?
事情的起因是我想弄清楚一个我从 GitLab 的 Gitaly 项目 中听说的特性 bundle-uri 的状态。这个特性理论上可以通过下载一个缓存文件来加速克隆,该文件可以在执行服务器 CPU 密集型的拉取操作之前,为你的项目数据提供种子。
简而言之,当你克隆一个 Git 仓库时,git clone 命令会与你连接的 Git 服务器开始对话,以确定服务器上有什么可用内容以及你想要获取什么。
对于一个仓库的大多数克隆操作,最终的数据传输都是非常相似的,但是每一次,git 客户端和服务器都在进行这种(有时相当复杂且昂贵的)协商过程。
几年前(2022 年末的 v2.38 版本),Git 获得了提供一个 URL 的能力,这个 URL 指向仓库预先计算好的起始点,可以从简单的 HTTP 文件服务器提供。这意味着这个种子数据可以在快速、分布式的 CDN 上。
一旦你拥有了这个种子数据(比如 95% 的项目数据),它就会与服务器进行更加昂贵的协商过程,以确定剩余的部分,从而可能节省大量时间。
更重要的是,你甚至可以提供一个本地文件作为起始点,比如 VM 挂载的文件系统或云缓存中的文件,这会_真正_地加速克隆。
它能让克隆更快吗?
简单的答案是:是的、不是和可能。
是的?
如果你使用本地文件选项,它可以使克隆速度更快。 这可能适用于你启动一个具有挂载点的 VM,并且每次都希望全新克隆仓库的情况。
你可以将它指向挂载点上的某个 bundle 文件作为起始点,然后后续的拉取操作可以变得更小、更快,同时仍然与服务器的当前状态完全同步。
不是?
这就是我掉进兔子洞的地方。理论上,我的理解是,如果我将一个仓库打包成 bundle 文件,并将其放在一个非常靠近我(柏林)的快速 CDN 上,然后使用这个特性,它_肯定_比从 GitHub 或 GitLab 全新克隆要快。
数据量相同,更靠近我,由静态 HTTP 服务器提供服务,而不是由代码托管平台的 Git 服务器进程动态生成的 packfile。这怎么可能_不_更快呢?
但事实并非如此。
我首先选择了一个相当大的仓库,包含许多分支和标签,也就是 GitLab 社区版,并将其克隆作为基准测试。
❯ time git clone https://gitlab.com/gitlab-org/gitlab-foss.git g1
Cloning into 'g1'...
remote: Enumerating objects: 3005985, done.
remote: Counting objects: 100% (314617/314617), done.
remote: Compressing objects: 100% (64278/64278), done.
remote: Total 3005985 (delta 244429), reused 311002 (delta 241404),
pack-reused 2691368 (from 1)
Receiving objects: 100% (3005985/3005985), 1.35 GiB | 23.91 MiB/s
Resolving deltas: 100% (2361484/2361484), done.
Updating files: 100% (59972/59972), done.
(*) 162.93s user 37.94s system 128% cpu 2:36.49 total
好的,它正在下载 300 万个对象,构建一个 1.3G 的 packfile,并以 24 MiB/s 的速度下载它(感谢柏林),总共耗时 2 分 36 秒。
让我们尝试通过将所有这些对象放入一个 packfile 中来加速这个过程,使用较新的 bundle-uri 选项来从 CDN 拉取这些文件,然后执行一个基本上是无操作的拉取操作。
第一步是打包这些对象。
Git Bundle
如果你不熟悉 bundle 文件,它实际上是一个_非常_古老的命令,是在 Git 1.5.1(2007 年 - 18 年前)中引入的,名为 git bundle,其目的正如发行说明中所述,是为了使 “sneakernetting” 更容易——将仓库放在 USB 闪存盘上,并在办公室里传递。
基本上,它在文件中生成一个仓库——有点像一个带有引用列表作为前导头的 packfile。如果你想更深入地了解它们,可以在我的旧版 Pro Git 书中阅读所有相关内容。
因此,让我们在文件中创建一个包含 GitLab 代码库当前状态的仓库,我们可以使用 git bundle create [file] --all 来完成。
❯ time git bundle create gitlab-base.bundle --all
Enumerating objects: 3005710, done.
Counting objects: 100% (3005710/3005710), done.
Delta compression using up to 8 threads
Compressing objects: 100% (582467/582467), done.
Writing objects: 100% (3005710/3005710), 1.35 GiB | 194.33 MiB/s, done.
Total 3005710 (delta 2361291), reused 3005710 (delta 2361291), pack-reused 0 (from 0)
(*) 17.31s user 3.03s system 84% cpu 24.199 total
好的,现在我们有了一个包含所有 1.3G 的 300 万个 git 对象的二进制文件。
我们将它放到 CDN 上(在本例中是 Bunny CDN,在法兰克福有一个_hop_),然后再次使用 git clone --bundle-uri=[file-url] [canonical-repo] 进行克隆。
❯ time git clone --bundle-uri=https://[cdn]/bundle/gitlab-base.bundle https://gitlab.com/gitlab-org/gitlab-foss.git g2
Cloning into 'g2'...
remote: Enumerating objects: 1092703, done.
remote: Counting objects: 100% (973405/973405), done.
remote: Compressing objects: 100% (385827/385827), done.
remote: Total 959773 (delta 710976), reused 766809 (delta 554276),
pack-reused 0 (from 0)
Receiving objects: 100% (959773/959773), 366.94 MiB | 20.87 MiB/s
Resolving deltas: 100% (710976/710976),
completed with 9081 local objects.
Checking objects: 100% (4194304/4194304), done.
Checking connectivity: 959668, done.
Updating files: 100% (59972/59972), done.
(*) 181.98s user 40.23s system 110% cpu 3:20.89 total
你首先会注意到的是,这实际上花费了_更多时间_——3:20,而全新克隆的时间为 2:36。
接下来要注意的是,它_仍然_需要下载 959,773 个对象,占原始克隆的 32%。 所以,那部分的物体少了,但是因为它首先下载了_所有_物体,为什么仍然需要另外一百万个物体呢?🤔
可能?
我花了很多时间进行测试和挖掘,但事实证明,原因是当 Git 解包 bundle 文件时,它只复制本地分支引用。 因此,如果你使用 --all 打包,表明你想要每个可访问的对象,它将创建一个包含所有内容的大型 packfile。
但是,当 bundle 被下载和解包时,它_只会_ 实际_使用由本地分支指向的对象(在克隆之后,可能_只有 master/main)来与服务器协商它仍然需要哪些对象。 其他一切都显得无法访问。
这意味着我们拉取的 1,000,000 个对象都是_重新下载的_——实际上我们几乎已经拥有了所有这些对象,但是 Git 并不知道它们在那里。
因此,我深入研究了代码,找到了发生这种情况的地方。
事实证明,Git 只是将 refs/heads 引用(分支)复制到 refs/bundle 空间中,忽略了 bundle 文件中的所有其他引用。
为什么这很重要? 因为 refs/ 中的内容是 Git 用来与服务器协商它拥有和没有的内容。 如果我们只有用于创建 bundle 文件的 1000 个引用中的 1 个,Git 将告诉服务器这是我们拥有的唯一的东西。
如果我更改此设置以复制 refs/ 中的所有内容(标签和远程引用),重新编译 Git 并再次运行此克隆命令,我将得到:
❯ time ./git clone --bundle-uri=https://[cdn]/bundle/gitlab-base.bundle https://gitlab.com/gitlab-org/gitlab-foss.git g3
Cloning into 'g3'...
remote: Enumerating objects: 65538, done.
remote: Counting objects: 100% (56054/56054), done.
remote: Compressing objects: 100% (28950/28950), done.
remote: Total 43877 (delta 27401), reused 25170 (delta 13546), pack-reused 0 (from 0)
Receiving objects: 100% (43877/43877), 40.42 MiB | 22.27 MiB/s, done.
Resolving deltas: 100% (27401/27401), completed with 8564 local objects.
Updating files: 100% (59972/59972), done.
(*) 143.45s user 29.33s system 124% cpu 2:19.27 total
太棒了,现在它不仅比原始克隆更快(2:19 对 2:36),而且还只下载了我打包的数据和在此期间推送到服务器的数据之间的差异。 在这种情况下,我们在拉取中下载了额外的 43,877 个对象,仅占仓库总对象大小的 1%。
这导致了一个有竞争力的世界最小的开源补丁:
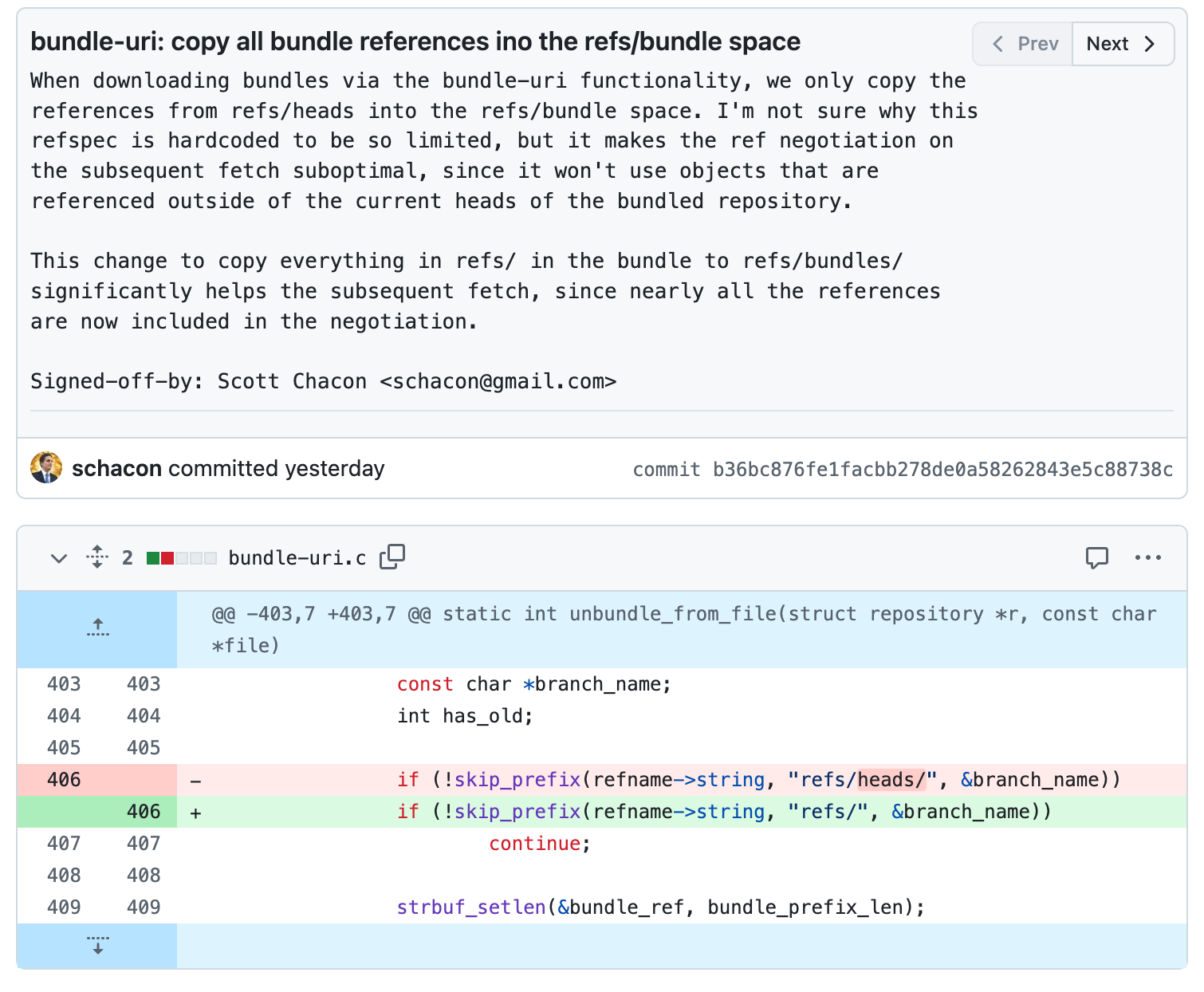 100 字提交消息,6 个字符的差异
100 字提交消息,6 个字符的差异
此补丁正在 Git 邮件列表上进行中,但现在的问题是,这是在 bundler 端还是在克隆端解决。 但是,希望将来版本的 Git 会以某种方式修复此问题。
我应该使用这个功能吗?
对此也有几个答案——“可能”和“你别无选择”。
此功能的真正受益者是 GitHub、GitLab 等代码托管平台,因为它有望大大降低 CPU 服务器负载。 如果他们的动态 Git 服务器进程不必在每次有人克隆时都在 CPU 中计算大量 packfile,而是可以将大量内容转移到便宜、快速、全球分布的 CDN 上,那么它可以节省他们大量的资金和服务器资源。
但是,这对_你_有帮助吗?
可能
我可以看到两种对普通人有帮助的用例。
如果你在内部运行自己的 git 服务器(可能使用 Gitosis 或 GitLab),这可以帮助减少服务器负载,尤其是在你进行大量克隆时。 这就是为什么 GitLab 有一个实验性功能来实现这一点。
如果你运行某种经常需要完整克隆的自动化设置,可能是 CI 或自动化测试系统,并且由于某种原因不想运行浅克隆,那么此功能的本地文件版本(从挂载点或 NFS 点读取种子 bundle)可能会非常有帮助。
例如,如果我从本地 bundle 文件执行相同的克隆:
❯ time ./git clone --bundle-uri=/tmp/gitlab-base.bundle https://gitlab.com/gitlab-org/gitlab-foss.git g4
Cloning into 'g4'...
remote: Enumerating objects: 69832, done.
remote: Counting objects: 100% (52229/52229), done.
remote: Compressing objects: 100% (21467/21467), done.
remote: Total 33625 (delta 23410), reused 17620 (delta 11061), pack-reused 0 (from 0)
Receiving objects: 100% (33625/33625), 28.39 MiB | 20.50 MiB/s, done.
Resolving deltas: 100% (23410/23410), completed with 9321 local objects.
Updating files: 100% (60218/60218), done.
(*) 93.29s user 16.84s system 189% cpu 58.103 total
现在,完整克隆花费不到 1 分钟,并且我与上游服务器完全同步。(我实际上不知道为什么这需要这么长时间——复制 bundle 文件应该非常快,但它需要 30 秒左右——我可能想接下来深入研究这个问题……)
你别无选择
更可能的答案是“你别无选择”,因为你的 Git 客户端会自动执行此操作。
虽然我在这篇文章的大部分时间都在谈论在 git clone 中手动指定 bundle URL,但这实际上并不是此功能的实际使用方式(除了上面描述的 CI 类型用例)。
在较新版本的 Git 服务器协议中,服务器本身可以通告 bundle URL。 这意味着服务器可以告诉 Git 客户端“首先获取此种子文件,然后返回给我”。
除非已专门配置 Git 不使用它们,否则如果服务器告诉它它们的位置,它将尝试下载 bundle 种子。 因此,最有可能的是,如果 GitHub 将来实现了此功能,你的 Git 客户端将开始从 Azure CDN 下载 bundle 文件,然后再占用 GitHub 服务器上的 packfile 创建资源。
希望我们可以使此修复程序的某些版本落地(或由比我更聪明的人编写的某些内容),因此你的客户端不会下载比实际需要更多的数据,也不会浪费 Azure 的带宽。 😉