Decrypting encrypted files from Akira ransomware using a bunch of GPUs
使用大量 GPU 破解 Akira 勒索软件的加密文件
A hacker does for love what others would not do for money.
使用大量 GPU 解密来自 Akira 勒索软件(Linux/ESXI 2024 变种)的加密文件
最近,我帮助一家公司从 Akira 勒索软件中恢复了数据,而没有支付赎金。我将分享我是如何做到的,以及完整的源代码。
代码在这里:https://github.com/yohanes/akira-bruteforce
需要说明的是,多年来,已经有多个勒索软件变种被命名为 Akira,并且目前有几个版本正在传播。我遇到的这个变种从 2023 年底到现在一直活跃(该公司今年遭到入侵)。

早期的版本(2023 年年中之前)包含一个漏洞,允许 Avast 创建解密器。但是,一旦发布,攻击者就更新了他们的加密方式。我预计在我发布此内容后,他们将再次更改他们的加密方式。
你可以在以下 URL 找到各种 Akira 恶意软件样本哈希值: https://github.com/rivitna/Malware/blob/main/Akira/Akira_samples.txt
与我的客户案例匹配的样本是:
bcae978c17bcddc0bf6419ae978e3471197801c36f73cff2fc88cecbe3d88d1a
它在 Linux V3 版本下被列出。该样本可以在 virus.exchange 上找到(只需粘贴哈希进行搜索)。
请注意,赎金消息和私钥/公钥会有所不同。
我们这样做不是因为它容易,而是因为我们认为它会很容易
我通常会拒绝协助勒索软件案件的请求。但是,当我的朋友给我看这个特殊的案例时,快速检查了一下,我认为它是可以解决的。
从我的初步分析来看,我观察到以下几点:
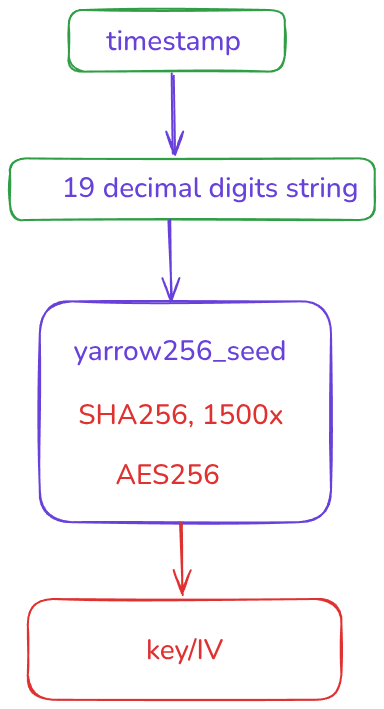
- 勒索软件使用当前时间(以纳秒为单位)作为种子。
- 在我的 Linux 机器上,文件修改时间具有纳秒级分辨率。
- 他们提供了一个部分日志(
shell.log)的屏幕截图,显示了勒索软件的执行时间,精度为毫秒级。
基于此,我的最初想法是:“这应该很容易——只需通过查看文件时间戳进行暴力破解即可。这有多难?”

我将更详细地解释,但事实证明它比预期的更复杂:
- 该恶意软件不依赖于单个时间点,而是使用四个时间点,每个时间点都具有纳秒级分辨率。前两个和后两个相关联,因此我们不能只是逐个暴力破解时间。密钥生成很复杂,每个时间戳都需要1,500 轮 SHA-256。每个文件最终都会有一个唯一的密钥。
- VMware VMFS 文件系统仅以秒级精度记录文件修改时间。
- 并非所有 ESXi host 都在其日志文件中具有毫秒级分辨率,有些仅以秒级精度记录。我仍然不确定是什么配置文件导致了这种不同的行为
- 该恶意软件在执行期间使用多个线程。
- 文件修改时间反映了文件关闭的时间,而不是打开进行写入的时间。
逆向工程
该代码是用 C++ 编写的,众所周知,C++ 很难阅读,但幸运的是,它没有被混淆。该二进制文件是静态链接的(分析起来有点困难),但所有字符串都是明文。错误消息表明使用了 Nettle 库,这使得理解代码变得容易得多。
错误字符串的存在真的很有帮助。
生成随机数的代码如下(实际代码在二进制文件中的 0x455f40 处):
| |
| :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| void generate_random(char *buffer, int size) { uint64_t t = get_current_time_nanosecond(); char seed[32]; //in the real code, it uses C++ code to convert int to string snprintf(seed, sizeof(seed), "%lld", t); struct yarrow256_ctx ctx; yarrow256_init(&ctx, 0, NULL); yarrow256_seed(&ctx, strlen(seed), seed); yarrow256_random(&ctx, size, buffer); } |
随机数生成器在 yarrow256.c 中实现。 这是相关的代码,删除了不必要的部分。 正如评论中指出的:
重新播种时的迭代次数,yarrow 论文中的 P_t。 应该选择使重新播种花费大约 0.1-1 秒。
| |
| :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| void yarrow256_seed( struct yarrow256_ctx *ctx, size_t length, const uint8_t *seed_file) { sha256_update(&ctx->pools[YARROW_FAST], length, seed_file); yarrow256_fast_reseed(ctx); } void yarrow256_fast_reseed( struct yarrow256_ctx *ctx) { uint8_t digest[SHA256_DIGEST_SIZE]; unsigned i; sha256_digest(&ctx->pools[YARROW_FAST], sizeof (digest), digest); /* Iterate */ yarrow_iterate(digest); aes256_set_encrypt_key(&ctx->key, digest); /* Derive new counter value */ memset (ctx->counter, 0, sizeof (ctx->counter)); aes256_encrypt(&ctx->key, sizeof (ctx->counter), ctx->counter, ctx->counter); } /* The number of iterations when reseeding, P_t in the yarrow paper. * Should be chosen so that reseeding takes on the order of 0.1-1 * seconds. */ #define YARROW_RESEED_ITERATIONS 1500 static void yarrow_iterate( uint8_t *digest) { uint8_t v0[SHA256_DIGEST_SIZE]; unsigned i; memcpy (v0, digest, SHA256_DIGEST_SIZE); /* When hashed inside the loop, i should run from 1 to * YARROW_RESEED_ITERATIONS */ for (i = 0; ++i < YARROW_RESEED_ITERATIONS; ) { uint8_t count[4]; struct sha256_ctx hash; sha256_init(&hash); /* Hash v_i | v_0 | i */ WRITE_UINT32(count, i); sha256_update(&hash, SHA256_DIGEST_SIZE, digest); sha256_update(&hash, sizeof (v0), v0); sha256_update(&hash, sizeof (count), count); sha256_digest(&hash, SHA256_DIGEST_SIZE, digest); } } |
种子和加密
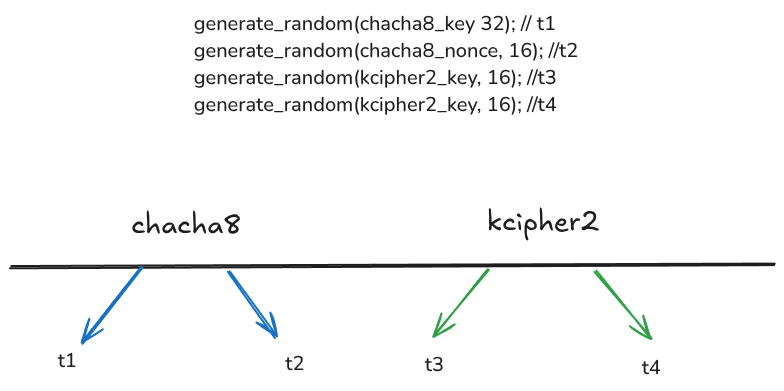
勒索软件调用随机数生成器四次:
| |
| :------------------------------------------------------------------------------------------------------------------------- |
| generate_random(chacha8_key 32); generate_random(chacha8_nonce, 16); generate_random(kcipher2_key, 16); generate_random(kcipher2_key, 16); |
每次 generate_random 调用都使用当前纳秒时间戳作为种子。 因此,有四个唯一的时间戳需要识别。 勒索软件为每个文件生成不同的密钥。
然后,这些密钥被保存在文件末尾作为 trailer,使用 RSA-4096 加密,并使用 PKCS#11 padding 进行填充。
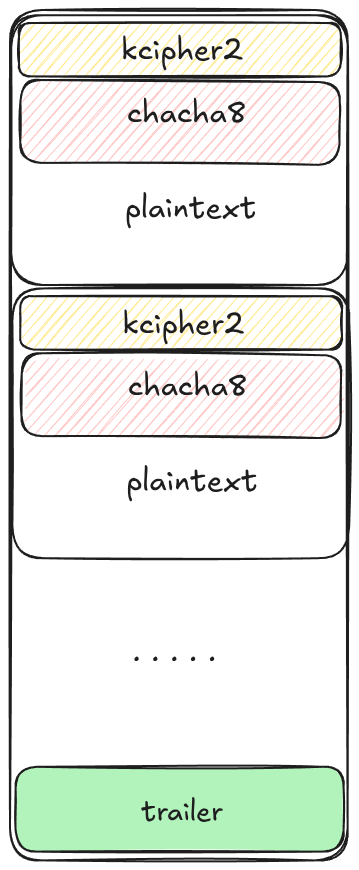
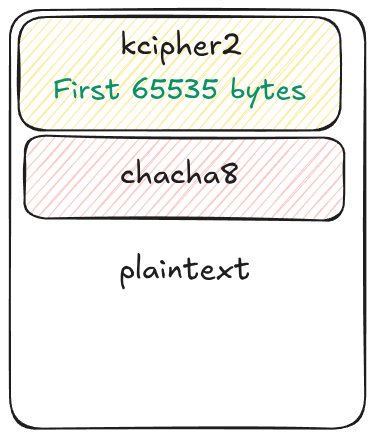
文件被分成 N 个块,并且每个块的一部分被加密。 此百分比由勒索软件的 -n 参数定义。 对于每个块:
- 前 0xFFFF 字节使用 KCipher2 加密。
- 剩余的字节使用 Chacha8 加密。
下图显示了如何分割文件。 请注意,对于非常小的文件,不需要知道 Chacha8 密钥和 IV。
在研究了各种 VMware 文件类型(稍后我将对此进行深入研究)之后,我确信最重要的文件(flat VMDK 和 sesparse 文件)具有固定的 header,我可以使用它来攻击加密。
其他细节
此时,我没有进行更深入的分析。 但我确信我稍后可以逆向工程其余的算法,特别是:
- 如何将文件分割成块
- 加密是如何跨块执行的,它会继续流式传输吗?
这些细节稍后将变得重要。 但是,就目前而言,如果我们无法成功地暴力破解时间戳,那么其他步骤都无关紧要。
暴力破解的可行性
方法如下:
- 生成两个时间戳(
t3和t4)。 - 将这些时间戳转换为种子并生成随机字节。
- 使用这些字节作为 KCipher2 密钥和 IV。
- 加密已知的明文,并将结果与加密文件中已知的密文进行比较。
让我们制定一个计划:
- 检查可行性:确定暴力破解是否足够快以至于实用。
- 识别明文:暴力破解需要已知的明文。
- 估计种子初始化时间:我们需要知道加密种子何时初始化,至少具有秒级精度。 此知识可以将暴力破解范围缩小到大约 10 亿个值。
最简单(但效率低下)的方法是尝试所有可能的 T4 > T3 的时间戳对。 可能的对数计算如下:N×(N−1)/2
当 N = 1 billion 时,结果是 500 quadrillion 个可能的对。
我们需要优化它。 首先,我们需要将一秒内的所有纳秒转换为随机值:
- 在我的 mini PC CPU 上,我估计每秒处理 100,000 个时间戳到随机字节的计算速度(利用所有内核)。
- 这意味着将所有时间戳转换为种子值大约需要 10,000 秒(不到 3 小时)。
- 转换后,这些值可以保存以供重用。
- 后来,我使用 GPU 优化了该过程,将转换时间从 3 小时缩短到 6 分钟以内。
如果我们有一台完全确定的机器,没有任何中断,我们可以运行恶意软件,测量它,知道 T3 和 T4 之间的确切时间。 但不幸的是,我们没有这个:
- 恶意软件使用多个线程,
- 它运行在一台非空闲的机器上,T3 和 T4 之间的距离因调度程序以及当时系统繁忙程度而异。
- 该代码还调用了大量的 C++ 库,这些库分配和释放对象,使得执行时间更加不可预测。
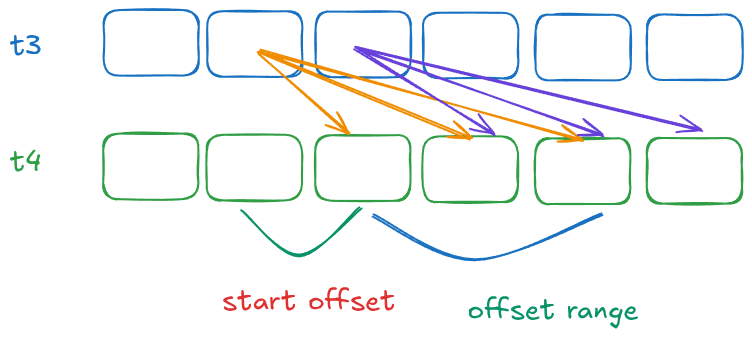
为了清楚起见:
- 我们需要枚举 t3(每秒 10 亿个值)
- 我们不是从 t3 + 1 开始,而是从 t3 + start offset 开始,因为我们知道播种该值需要时间(在我的机器上至少需要一百万纳秒),这就是 "start offset"
- 我们假设直到下一个代码执行只需要几百万纳秒(记住:由于 CPU 调度程序可能会发生中断,并且执行了数百万条指令)。 这是 "offset range" 值。
我们可以做的是尝试运行与恶意软件完全相同的代码,收集计时数据,并尝试找到在统计上合理的范围。 使用与我在之前的文章中使用的相同技术,我只是修改了恶意软件并在我拥有的几台本地机器上进行了测试,而不是重新创建算法并运行它。 运行时在机器之间变化很大。
我的朋友 Deny 前往数据中心,并在受感染的真实硬件上进行了测试。 结果是:时间范围变化,有时变化很大。 正常的 offset 范围约为 2-4 百万纳秒(因此 offset range 为 2 百万),但该值在 1.5 - 5 百万之间变化(总 offset range 为 4.5 百万)。
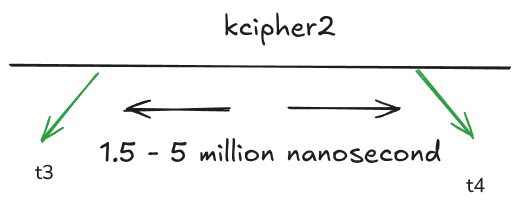
我们仍然需要枚举 4.5 千万亿对,但这似乎是可行的。 如果我们有一个能够每秒运行 5000 万次加密的系统,那么该过程将需要数百天。 但是,如果有 16 个这样的系统,我们可以在 CPU 上几个月内完成它。 通过租用额外的机器,我们可以进一步加快该过程。 后来,我使用 GPU 对此进行了优化,从而显着提高了速度。
我不确定我们能以多快的速度完成 Kicpher2,但与 chacha 的快速比较以及一些快速基准测试表明,仅使用 CPU,我应该能够在我的机器上每秒至少执行数百万次 Kichper 操作。
如前所述,如果 t3 和 t4 是正确的,我们将能够解密文件的前 8 个字节,并且它将解密为已知的明文。
接下来,让我们检查从不同的 VMware 文件中获取明文的可行性
VMWare 文件类型
对于每个文件,我们需要一个明文样本:KCipher2 的文件的前 8 个字节(偏移量 0),以及从偏移量 65,535 开始的另外 8 个字节(仅适用于大文件)。 由于每个 KCipher2 块为 8 个字节,因此我们应该使用 8 字节的明文。 可以使用更少的字节(通过使用位掩码),但这可能会增加误报的风险。
Flat-VMDK
这是一个原始磁盘文件。 如果你幸运的话,这可能是你需要恢复的唯一文件。 但是,如果进行了快照(如本客户的案例),则新数据将被写入 sesparse 文件。
要获取 flat VMDK 的前 8 个字节,你需要安装与原始 VM 上使用的操作系统相同的操作系统。 不同的操作系统版本使用几种不同的引导加载程序。
要确定使用了哪个操作系统,请检查相应的 VMX 文件。 它应该包含部分可读的明文,允许你检查 “guestOS” 的配置。 你可能会发现类似的内容:guestOS =“ubuntu”。 但是,理想情况下,你已经拥有关于每个 VM 使用哪个操作系统的文档,因此你不必依赖此方法。
对于位置 65,535 处的字节(Chacha8 的明文),几乎总是保证为零,因为分区通常从后面的扇区开始。
Sesparse
如果为 VM 创建快照,则每个快照都会有一个 SESPARSE 文件。 我们可以从 QEMU 源代码中看到文件格式。 https://github.com/qemu/qemu/blob/master/block/vmdk.c
文件头是 0x00000000cafebabe,并且在位置 65,535 处,它应该是 0x0(至少,这是我在分析中观察到的)。

其他文件
其他文件对于恢复正常工作的 VM 来说并不重要,但是对于初始测试,了解时间分布可能很有用。 如果有许多具有相同时间戳的小文件,那么了解它们是否聚集在特定的时间戳范围内很有用。
以下是一些常见的用于识别明文的文件签名:
- NVRAM 文件以以下内容开头:4d 52 56 4e 01 00 00 00
- VMDK 文件(磁盘描述符)以字符串开头:
# Disk Descriptor - .VMX 文件以以下内容开头:
.encoding - VMware 日志文件具有以以下格式开头的行:
YYYY-MM-DD
由于这些文件是部分可读的,因此我们通常可以根据文件的开头猜测初始时间戳(例如,日志的 YYYY-MM- 部分)。
通过识别这些文件中的明文,下一步是缩小时间戳范围以进行准确的暴力破解。
加密时间戳
现在我们知道暴力破解是可行的,并且我们同时拥有明文和密文,下一步是确定每个文件的加密发生时间(因为每个文件都将具有不同的密钥)。
ESXI 日志
用于运行恶意软件的命令记录在 shell.log 文件中(包括 n 的设置,该设置定义了应加密多少文件)。
某些 ESXi host 在其日志中提供毫秒级分辨率,而另一些则仅提供秒级精度。 此日志为我们提供了恶意软件开始时间的初始时间戳。
例如,如果日志显示恶意软件在 10:00:01.500 启动,我们可以安全地忽略暴力破解时的前 5 亿纳秒,这有助于缩小搜索范围。
文件系统时间戳和修改时间
不幸的是,ESXi 文件系统不支持纳秒精度。
另一个挑战是,文件修改时间仅在文件关闭时才记录。 这意味着记录的时间戳可能无法准确反映加密过程开始的时间,而是反映了加密过程结束的时间。
在 Linux(使用大多数文件系统)中,时间戳精度是纳秒级的。
对于小文件,加密通常仅需几毫秒,因此时间戳很可能反映了加密的确切秒数。 下一步是确定较大文件的加密时间,其中该过程需要更长的时间并且时间戳可能不太精确。
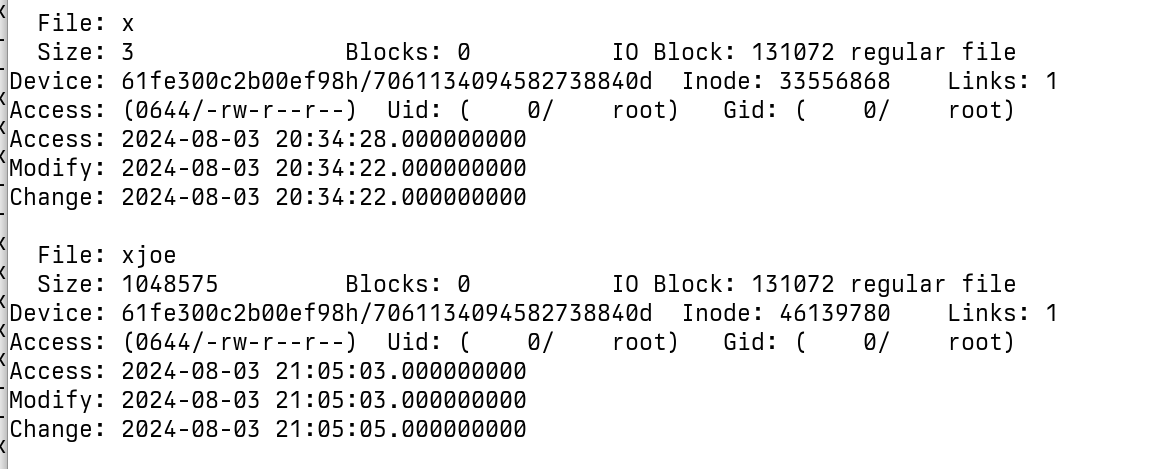
在 VMFS 中,精度是秒级的。
多线程加密
该恶意软件使用多线程,其中每个文件都在一个新线程中处理,工作线程池受到 CPU 核心数量的限制。 这既有优点也有缺点。
如果恶意软件以单个目录为目标,并且文件数少于 CPU 核心数,则该过程很简单——每个文件都将具有一个非常接近其他文件的时间戳。 在 ESXi 机器上,通常有具有大量核心的 CPU(在这种情况下,服务器具有 64 个核心)。
当使用以下命令检查时间戳时:
| |
| :------------------------------------------------- |
| find /vmfs/volumes -exec stat {} \; |
我们应该能够识别首先加密的小文件。 在暴力破解期间,我们可以同时检查该特定时间点的多个文件。
首先处理的文件将具有相似的时间戳,但是对于以后处理的文件,情况会变得更加复杂。 对于较大的文件,加密可能需要几秒钟到几分钟的时间,并且修改时间将反映文件关闭的时间,这明显晚于实际生成加密密钥的时间。
该恶意软件使用 boost::filesystem 来遍历目录和文件。 boost::filesystem 中的迭代器遵循 readdir 返回的顺序,该顺序与使用 ls -f 或 find . 等命令时观察到的顺序相同。
让我们考虑一个示例,其中我们有 4 个 CPU 核心和 8 个文件。 如果文件很小(小于 1 KB,例如 VMDK 描述符文件),则它们的处理几乎是瞬时的(在几毫秒内)。 处理方式如下所示:
- 线程 A、B 和 C 各自找到并处理 小文件(
file_a、file_b、file_c),而 线程 D 找到一个 大文件(file_d)。 所有四个文件都已立即处理。 - 一旦 线程 A、B 和 C 完成,它们便开始处理 下一组文件(
file_e、file_f、file_g)。 但是,这些文件更大,需要更多处理时间。 - 当其他三个线程仍在工作时,线程 D 完成处理大
file_d,并开始处理 最后一个文件(file_h)。 结果,file_h的起始时间戳将与file_d的完成时间对齐。
现在,想象一下有数百个文件——很难确定确切的处理顺序。 但是,一个一致的观察结果是,文件的加密开始时间可能与另一个文件的修改时间相同或非常接近。
这是因为,一旦线程完成处理并关闭文件(从而记录其修改时间),它将立即开始处理下一个可用文件。 这将创建一个序列,其中一个文件的加密开始时间与先前文件的修改时间紧密相关。
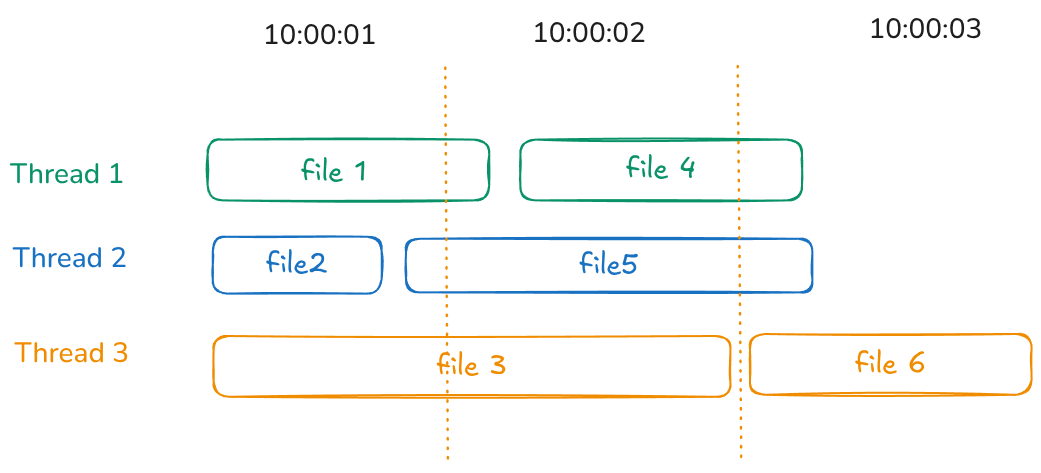
因此,给定几百个文件和大量的 CPU 核心,我们可能只有几秒钟的列表,恶意软件将开始生成随机密钥。
因此,现在我们有了难题的最后一部分:我们知道何时执行了加密。
网络文件系统
在查看客户的日志时,我注意到一些条目提到了 NFS 的使用。 但是,在澄清之后,确认 NFS 仅用于备份,并且未受到影响。 所有相关文件都存储在服务器上的本地磁盘上。
如果使用了网络文件系统,则会使该过程复杂化。 如果系统之间的网络时间没有完全同步,则时间戳可能不准确或不可靠,从而进一步使暴力破解过程复杂化。
创建暴力破解器
该计划似乎很可靠,因此下一步是实现该代码。 我需要确认加密过程的工作方式是否与恶意软件完全相同。
为了测试这一点,我修补了恶意软件代码,使 gettime 函数返回一个常量值 0,从而确保在测试期间获得可预测且一致的结果。
KCipher2
我专注于 KCipher2,因为并非所有文件都使用 Chacha8 密钥,尤其是小文件。 尽管 KCipher2 是一种标准加密算法,但它并不广为人知,我找不到它的优化实现。
在实验期间,我注意到我的结果与在线提供的标准 KCipher2 实现不符。 事实证明,恶意软件对初始化向量和加密过程进行了一些修改,特别是涉及 endian 交换。
CUDA
我不是 CUDA 编程专家。 大约 10 年前,我曾对此进行过简短的试验,但找不到当时我所工作的公司的实用用例。
为了加快开发速度,我要求 ChatGPT (o1) 将代码移植到 CUDA。 该代码已成功编译,但产生了不正确的结果。 事实证明,ChatGPT 略微修改了常量表中的数字。 手动更正这些值后,代码开始工作。
尽管该实现已运行,但我怀疑它不是最佳的,但我无法从 ChatGPT (o1) 获得进一步的优化建议。 在这一点上,我有两个选择:花费更多时间优化代码,或者继续使用预测的 offset range 并在此过程中改进代码。 我选择立即开始测试并根据需要进行优化。 不幸的是,事实证明这种方法浪费了金钱,因为它没有产生任何成功的结果。
在项目开始时,我只有两个 RTX 3060 GPU。 一个专用于我的 Windows 机器,因此我只能在我的 Mini PC 上使用一个 GPU(通过 Oculink 从外部连接)。 为了提高性能,我决定购买 RTX 3090。 与 4090 或更高型号相比,泰国价格仍然合理。
我通过从内存中读取密钥和 IV、加密零块并将结果写回内存来测试该实现。 性能令人失望,仅实现了每秒约 6000 万次加密。 按照这个速度,整个过程将需要大约 10 年,这显然太慢了,无法进行实际恢复。
手动优化
我通过删除不必要的代码来执行一些手动优化以提高性能:
- 暴力破解只需要第一个块,因此无需处理其他块。
- 该代码已简化为仅加密零块,从而减少了不必要的处理。
- 由于只需要结果的前 8 个字节,因此忽略了其余输出以最大程度地减少计算。
共享内存
在研究用于 AES 的 CUDA 优化之后,我发现使用共享内存可以显着提高性能,这与 ChatGPT 的建议相反。 令人惊讶的是,将常量内存数据复制到共享内存所涉及的额外步骤在开销方面可以忽略不计,但导致代码运行速度提高了数倍。
避免内存写入
最初,我在 GPU 上执行加密,在主机 (CPU) 上执行匹配。 但是,即使并行执行,这种方法也很慢:
- 在 GPU 上生成加密
- 将结果复制到 CPU
- 在一个新线程中执行匹配,并将下一批工作提交给 GPU。
我发现完全避免写入内存的速度更快。 相反,匹配过程直接在 GPU 上处理,并且除非找到匹配项,否则不会将任何数据写入内存。 这种方法显着减少了处理时间并提高了效率。
多个文件匹配
对于每个 t3 和 t4 组合,对于任何共享同一秒级时间戳(但具有不同的纳秒)的文件,都可能发生匹配。
为了提高效率,我们可以尝试同时匹配多个文件。 但是,如果要匹配的文件过多,该过程可能会显着变慢。 当前,并行处理的文件数硬编码为 32,以在性能和效率之间保持平衡。
循环
我考虑并实现了两种进行循环的方法。 对于每个 t3 值,我们可以启动一个 GPU 内核来检查所有 offset range。 但是,这种方法效率低下,因为它需要启动内核 10 亿次,从而导致巨大的开销。

或者,我们可以为每个 offset 启动一个 GPU 内核。 然后,每个内核将执行必要的检查。 这种方法要快得多,因为它将提交次数减少到仅 “offset range”,大约为 2 到 450 万个作业。

批量检查
最初,我的方法是将任务提交给 GPU,使用 cudaDeviceSynchronize() 等待结果,然后提交下一批工作。 但是,事实证明这种方法很慢。
- 将工作提交给 GPU,如果找到匹配项,只需使用 found 标志对其进行标记即可。
- 仅每 100 步调用
cudaDeviceSynchronize()来检查结果。 如果找到匹配项,则在继续操作之前将标志重置为零。
虽然此方法显着提高了性能,但如果两个 offset 非常接近(相隔不到 100 步),则代码可能会错过其中一个 offset。 尽管在我的测试中从未发生过此问题,但我添加了可选的循环模式。 在此模式下,程序读取 offset 列表,并确保手动检查附近的 offset 以避免遗漏任何潜在的匹配项。
最终速度
我认为 GPU 专家仍然可以找到进一步优化我的代码的方法。 目前,我的 RTX 3090 上的 KCipher2 每秒可实现约 15 亿次加密。
- 对于使用单个 offset 测试 10 亿个值,大约需要 0.7 秒,包括检查匹配项的时间(每批最多 32 个匹配项)。
- 使用单个 GPU 测试 200 万个 offset 大约需要 16 天,或者使用 16 个 GPU 仅需要 1 天。
我还使用 Runpod 进行了测试,结果证明 RTX 4090 是理想的选择。 尽管它比 3090 贵约 60%,但速度也快 2.3 倍。
- 使用 4090,相同的过程在单个 GPU 上大约需要 7 天。
- 使用 16 个 GPU,该过程可以在 10 多个小时内完成。
运行暴力破解
从成本的角度来看,RTX 4090 是此任务的绝佳选择,原因如下:
- 不需要大内存。
- 不需要浮点运算。
- RTX 4090 提供大量的 CUDA 核心,从而提高了处理速度。
- 与其他高端 GPU 相比,RTX 4090 的租金相对较低。
如果 4090 不可用,考虑到其性价比,3090 也是一个不错的选择。
最初,我的客户考虑使用 Google Cloud Platform (GCP) 机器,并寻求为期一个月的租金折扣。 但是,事实证明此选项非常昂贵(花费数万美元)。
经过一番研究,我发现了一些更具成本效益的替代方案:Runpod 和 Vast.ai。
Runpod
为了暴力破解 1 秒(10 亿纳秒),offset range 为 2 百万,这将需要 7 天。 在