无需归一化的 Transformers (Transformers Without Normalization)
Transformers Without Normalization
Jiachen Zhu1,2 • Xinlei Chen1 • Kaiming He3 • Yann LeCun1,2 • Zhuang Liu1,4,†
† 项目负责人
 1 •
1 •  2 •
2 •  3 •
3 •  4
CVPR 2025
Paper Code Summary
4
CVPR 2025
Paper Code Summary
 左图: 原始的 Transformer 块。 右图: 使用我们提出的 Dynamic Tanh (DyT) 层的模块。DyT 可以直接替换常用的 Layer Norm 或 RMSNorm 层。 带有 DyT 的 Transformers 在性能上可以匹配甚至超过经过归一化的 Transformers。
左图: 原始的 Transformer 块。 右图: 使用我们提出的 Dynamic Tanh (DyT) 层的模块。DyT 可以直接替换常用的 Layer Norm 或 RMSNorm 层。 带有 DyT 的 Transformers 在性能上可以匹配甚至超过经过归一化的 Transformers。
Abstract
归一化层在现代神经网络中无处不在,并且长期以来被认为是必不可少的。 这项工作表明,使用一种非常简单的技术,无需归一化的 Transformers 也能实现相同或更好的性能。 我们引入了 Dynamic Tanh (DyT),这是一种逐元素操作 DyT(x)=tanh(αx),作为 Transformer 中归一化层的直接替代品。 DyT 的灵感来自于 Transformer 中的层归一化通常会产生类似于 tanh 的 S 形输入-输出映射的观察。 通过结合 DyT,无需归一化的 Transformers 可以在性能上匹配甚至超过其归一化的对应物,并且大部分情况下无需超参数调整。 我们验证了带有 DyT 的 Transformers 在各种设置中的有效性,范围从识别到生成,从监督学习到自监督学习,以及从计算机视觉到语言模型。 这些发现挑战了现代神经网络中归一化层必不可少的传统理解,并为它们在深度网络中的作用提供了新的见解。
Implementation
DyT 模块可以用几行 PyTorch 代码实现:
class DyT(nn.Module):
def __init__(self, num_features, alpha_init_value=0.5):
super().__init__()
self.alpha = nn.Parameter(torch.ones(1) * alpha_init_value)
self.weight = nn.Parameter(torch.ones(num_features))
self.bias = nn.Parameter(torch.zeros(num_features))
def forward(self, x):
x = torch.tanh(self.alpha * x)
return x * self.weight + self.bias
Key Findings
Layer Normalization Behaves Like Scaled Tanh Function
我们的分析表明,Transformer 中的 layer normalization (LN) 生成的输入-输出映射与缩放的 tanh 函数非常相似。 在较早的层中,这些映射主要呈线性关系。 然而,在更深的层中,它们呈现出 tanh 函数特有的明显的 S 形曲线。
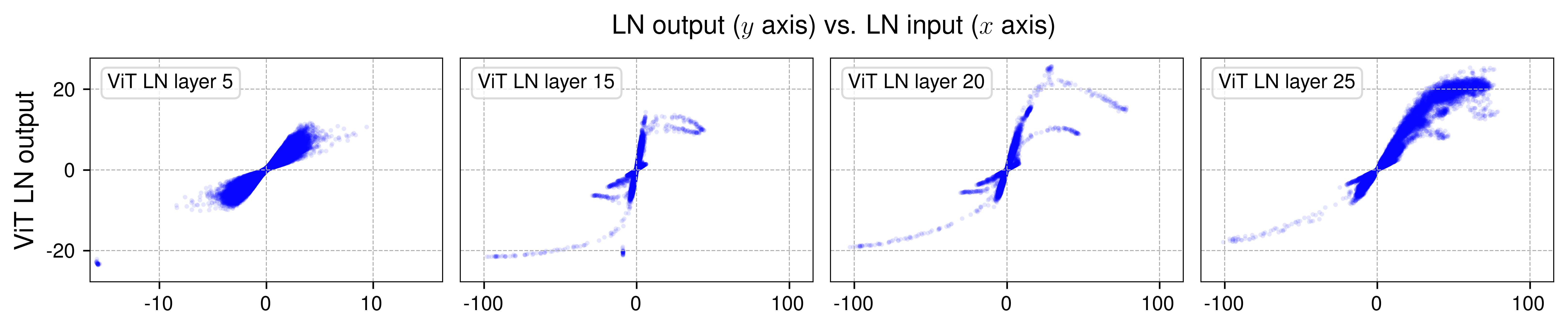

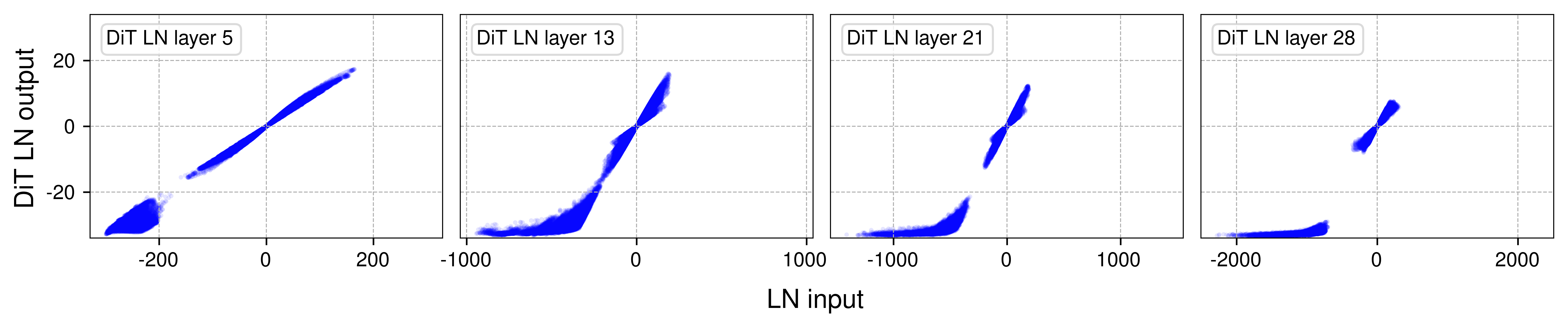
Vision Transformer (ViT)、wav2vec 2.0(用于语音的 Transformer 模型)和 Diffusion Transformer (DiT) 中选定的 LN 层的输出与输入关系。 我们绘制了每个模型中四个 LN 层的输入/输出值。 S 形曲线与 tanh 函数的曲线高度相似。
Evaluation
我们对 DyT 在各种架构和任务中进行了全面的评估,突出了其有效性和通用性。 我们的实验涵盖了视觉方面的监督学习 (ViT 和 ConvNeXt),视觉方面的自监督学习 (MAE 和 DINO),扩散模型 (DiT),大型语言模型 (LLaMA),语音方面的自监督学习 (wav2vec 2.0) 以及 DNA 序列建模 (HyenaDNA 和 Caduceus)。 在每种情况下,使用 DyT 的 Transformers 都实现了与其归一化对应物相似或更好的性能。 有关详细结果和比较,请参阅我们的论文。
Resources
Paper
下载我们的论文,获取有关我们研究的所有详细信息。 Download Paper
Code
查看我们的存储库以获取实现细节。 View on GitHub
Summary
在 X 上阅读我们研究结果的简要总结。 View Summary
BibTeX
@inproceedings{Zhu2025DyT,
title={Transformers without Normalization},
author={Zhu, Jiachen and Chen, Xinlei and He, Kaiming and LeCun, Yann and Liu, Zhuang},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2025}
}
Correspondence
jiachen [dot] zhu [at] nyu [dot] edu zhuangl [at] princeton [dot] edu