如何从受 LCP "保护" 的 ePub 中提取内容
@edent! debugging drm ebooks epub · 8 comments · 1,800 words · read ~2,738 times.
正如 Cory Doctorow 曾经说过的那样:“任何时候,当有人在你拥有的东西上加锁,却不给你钥匙时,那把锁就不是为你而设的。”
但关于 LCP DRM 方案,问题在于:他们 确实 给你钥匙!正如我之前写过的,LCP 主要依赖于用户在想要阅读书籍时输入密码(钥匙)。当然,背景中有一些深奥的密码学魔法,但最终,钥匙就放在你的电脑上,等待被找到。当然,密码学非常困难™,这使得检索密钥几乎不可能——所以也许我们可以使用不同的技术来提取未加密的内容?
一个流行的 LCP 应用是 Thorium。它是一个 Electron Web App。这意味着它是一个捆绑的浏览器,运行着 JavaScript。这也意味着它可以很容易地被调试。代码在你自己电脑上运行,没有触及任何人的机器。没有逆向工程,没有破解加密秘密,没有规避任何技术控制,没有泄露任何非法数字,没有破解任何东西。我们只是要求阅读器给我们我们已经付费的内容——而它同意了。
此处有龙
这是一个手动、容易出错且繁琐的过程。这不能用于自动移除 DRM。我只在 Linux 上测试过。它必须仅用于你合法获得的书籍。我使用它进行研究和私人学习。
这使用了 Thorium 3.1.0 AppImage。
首先,解压应用程序:
./Thorium-3.1.0.AppImage --appimage-extract
这会创建一个名为 squashfs-root 的目录,其中包含所有应用程序的代码。
可以通过使用以下命令启用远程调试来运行 Thorium 应用程序:
./squashfs-root/thorium --remote-debugging-port=9223 --remote-allow-origins=*
在 Thorium 应用程序中,打开你想阅读的书籍。
打开 Chrome 并转到 http://localhost:9223/ - 你将看到 Thorium 窗口的列表。点击与你的书籍相关的链接。
在 Thorium 书籍窗口中,浏览你的书籍。在调试窗口中,你应该看到文本和图像弹出。
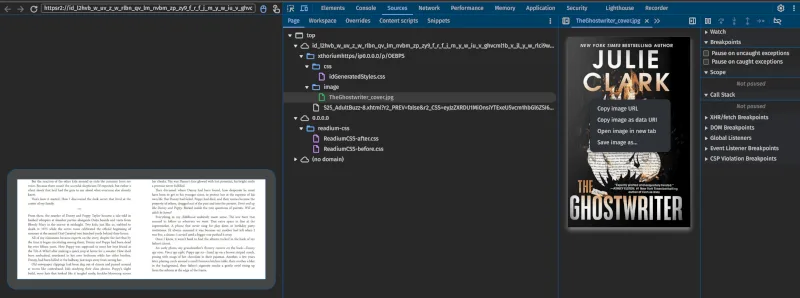
在调试窗口的 "Content" 选项卡中,你将能够看到 eBook 包含的图像和 HTML。
图像
这些图像是从你的 ePub 解密的完整分辨率文件。可以右键单击并从开发者工具中保存它们。
文件
ePub 文件只是一个压缩的文件集合。获取你的 ePub 副本并将其重命名为 whatever.zip 然后解压缩它。现在你将能够看到所有文件的名称 - 图像、css、字体、文本等 - 但它们的内容将被加密,因此你无法打开它们。
但是,你可以将它们的文件名提供给 Electron 应用程序,它会为你读取它们。
图像
要获取图像的 Base64 编码版本,请在调试控制台中运行以下命令:
fetch("httpsr2://...--/xthoriumhttps/ip0.0.0.0/p/OEBPS/image/whatever.jpg")
.then(response => response.arrayBuffer())
.then(buffer => {
let base64 = btoa(
new Uint8Array(buffer).reduce((data, byte) => data + String.fromCharCode(byte), '')
);
console.log(`data:image/jpeg;base64,${base64}`);
});
Thorium 使用 httpsr2 URl 方案 - 你可以通过查看 content 选项卡找到确切的 URl。
CSS
可以直接读取 CSS 并将其打印到控制台:
fetch("httpsr2://....--/xthoriumhttps/ip0.0.0.0/p/OEBPS/css/styles.css").then(response => response.text())
.then(cssText => console.log(cssText));
但是,它比原始 CSS 大得多 - 大概是因为 Thorium 在其中注入了自己的指令。
Metadata
诸如 NCX 和 OPF 之类的元数据也可以毫无问题地解密:
fetch("httpsr2://....--/xthoriumhttps/ip0.0.0.0/p/OEBPS/content.opf").then(response => response.text())
.then(metadata => console.log(metadata));
它们的文件大小与其加密的对应物大致相同 - 所以我不认为它们缺少任何东西。
字体
如果在文档中使用了字体,则应可用。可以使用以下命令将其作为 Base64 编码的文本抓取到控制台:
fetch("httpsr2://....--/xthoriumhttps/ip0.0.0.0/p/OEBPS/font/Whatever.ttf")
.then(response => response.arrayBuffer())
.then(buffer => {
let base64 = btoa(
new Uint8Array(buffer).reduce((data, byte) => data + String.fromCharCode(byte), '')
);
console.log(`${base64}`);
});
从那里可以将其复制到新文件中,然后进行解码。
文本
书籍的 HTML 也显示在 Content 选项卡上。它_不是_来自 ePub 的原始内容。它添加了一堆 CSS 和 JS。但是,一旦你到达正文,你将看到类似以下内容:
<body>
<section epub:type="chapter" role="doc-chapter">
<h2 id="_idParaDest-7" class="ct"><a id="_idTextAnchor007"></a><span id="page75" role="doc-pagebreak" aria-label="75" epub:type="pagebreak"></span>Book Title</h2>
<div class="_idGenObjectLayout-1">
<figure class="Full-Cover-White">
<img class="_idGenObjectAttribute-1" src="image/cover.jpg" alt="" />
</figure>
</div>
<div id="page76" role="doc-pagebreak" aria-label="76" epub:type="pagebreak" />
<section class="summary"><h3 class="summary"><span class="border">SUMMARY</span></h3>
<p class="BT-Sans-left-align---p1">Lorem ipsum etc.</p>
</section>
这看起来像普通的 ePub。你可以像上面一样使用 fetch 命令,但你仍然会得到详细的 xHTML 版本。
组合在一起
如果你解压缩了原始 ePub,你将看到内部目录结构。它应该看起来像这样:
├── META-INF
│ └── container.xml
├── mimetype
└── OEBPS
├── content.opf
├── images
│ ├── cover.jpg
│ ├── image1.jpg
│ └── image2.png
├── styles
│ └── styles.css
├── content
│ ├── 001-cover.xhtml
│ ├── 002-about.xhtml
│ ├── 003-title.xhtml
│ ├── 004-chapter_01.xhtml
│ ├── 005-chapter_02.xhtml
│ └── 006-chapter_03.xhtml
└── toc.ncx
将提取的文件添加到该确切的结构中。然后压缩它们。将 .zip 重命名为 .epub。就这样。你现在拥有了你购买的无 DRM 副本。
奖励!PDF 提取
LCP 2.0 PDF 也可以提取。同样,你需要在启用调试模式的情况下在 Thorium 中打开你购买的 PDF。在调试器中,你应该能够找到已解密 PDF 的 URl。
可以使用以下命令获取它:
fetch("thoriumhttps://0.0.0.0/pub/..../publication.pdf")
.then(response => response.arrayBuffer())
.then(buffer => {
let base64 = btoa(
new Uint8Array(buffer).reduce((data, byte) => data + String.fromCharCode(byte), '')
);
console.log(`${base64}`);
});
复制输出并对其进行 Base64 解码。你将拥有一个未加密的 PDF。
后续步骤
这可能是我有能力做到的最远的一步了。
但是,就目前而言,存在一个解决方案。如果我购买了带有 LCP Profile 2.0 加密的 ePub,我将能够手动从中提取我需要的内容 - 而无需对加密方案进行逆向工程。
伦理
在我发布这篇博文之前,我在 Mastodon 上公开了我的发现。此后不久,我收到了来自 Readium 联盟(创建 LCP DRM 的机构)一位高级人士的 LinkedIn 消息。
他们说:
Hi Terence, You've found a way to hack LCP using Thorium. Bravo! We certainly didn't sufficiently protect the system, we are already working on that. From your Mastodon messages, you want to post your solution on your blog. This is what triggers my message. From a manual solution, others will create a one-click solution. As you say, LCP is a "reasonably inoffensive" protection. We managed to convince publishers (even big US publishers) to adopt a solution that is flexible for readers and appreciated by public libraries and booksellers. Our gains are re-injected in open-source software and open standards (work on EPUB and Web Publications). If the DRM does not succeed, harder DRMs (for users) will be tested. I let you think about that aspect
我确实考虑了那个方面。一天后,我回复说:
Thank you for your message. Because Readium doesn't freely licence its DRM, it has an adverse effect on me and other readers like me.
- My eReader hardware is out of support from the manufacturer - it will never receive an update for LCP support.
- My reading software (KOReader) have publicly stated that they cannot afford the fees you charge and will not be certified by you.
- Kobo hardware cannot read LCP protected books.
- There is no guarantee that LCP compatible software will be released for future platforms.
In short, I want to read my books on my choice of hardware and software; not yours. I believe that everyone deserves the right to read on their platform of choice without having to seek permission from a 3rd party. The technique I have discovered is basic. It is an unsophisticated use of your app's built-in debugging functionality. I have not reverse engineered your code, nor have I decrypted your secret keys. I will not be publishing any of your intellectual property. In the spirit of openness, I intend to publish my research this week, alongside our correspondence.
他们在出版前不久的回复包含了我认为是对情感操纵的粗略尝试。
Obviously, we are on different sides of the channel on the subject of DRMs. I agree there should be many more LCP-compliant apps and devices; one hundred is insufficient. KOReader never contacted us: I don't think they know how low the certification fee would be (pricing is visible on the EDRLab website). FBReader, another open-source reading app, supports LCP on its downloadable version. Kobo support is coming. Also, too few people know that certification is free for specialised devices (e.g. braille and audio devices from Hims or Humanware). We were planning to now focus on new accessibility features on our open-source Thorium Reader, better access to annotations for blind users and an advanced reading mode for dyslexic people. Too bad; disturbances around LCP will force us to focus on a new round of security measures, ensuring the technology stays useful for ebook lending (stop reading after some time) and as a protection against oversharing. You can, for sure, publish information relative to your discoveries to the extent UK laws allow. After study, we'll do our best to make the technology more robust. If your discourse represents a circumvention of this technical protection measure, we'll command a take-down as a standard procedure.
承认他们未能正确优先考虑可访问性,有点自取其辱!
我决定简洁地回复,而不是反驳他们的所有观点。
As you have raised the possibility of legal action, I think it is best that we terminate this conversation.
我真诚地相信,这篇文章是旨在教育人们了解 Readium 的 DRM 方案缺陷的合法尝试。读者和出版商都需要意识到,他们的 Thorium 应用程序很容易访问未受保护的内容。
我当然会发布与此问题相关的任何进一步通信。