使用 Hoarder 构建个人档案
Brainsteam HomePostsNotesLinksSearch
使用 Hoarder 构建个人档案
发布于 2025年2月15日 作者 ![]() James Ravenscroft
James Ravenscroft
在这个时代,由于 各种原因,保存和记录可能从互联网上删除、丢失或遗忘的信息非常重要。 我最近一直在使用 Hoarder 来创建一个自托管的个人网络内容档案,这些内容是我觉得有趣或有用的。 Hoarder 是一个开源项目,它运行在你自己的服务器上,允许你搜索、过滤和标记网络内容。 至关重要的是,它还会获取网络内容的完整副本并将其存储在本地,以便即使原始站点关闭,你也可以访问它。
Hoarder 简评
Hoarder 运行一个无头版本的 Chrome(即,它实际上并没有在你的服务器上打开窗口,它只是模拟它们),并使用它从站点下载内容。 对于需要付费才能访问的内容(也许你想保存一份报纸文章以供日后参考),它可以与 SingleFile 协同工作。SingleFile 是一个 Chrome 和 Firefox(包括移动端)的浏览器插件,它会将你在浏览器中当前查看内容的完整副本发送给 Hoarder。 这意味着,即使你正在查看需要登录才能访问的内容,你也可以将其保存到 Hoarder,而无需与该应用共享任何凭据。
Hoarder 可选地包含一些 AI 功能,你可以根据自己的喜好启用或禁用这些功能。 这些功能允许 Hoarder 自动为你保存的内容生成标签,并可选择生成你保存的任何文章的摘要。 默认情况下,Hoarder 与 OpenAI API 配合使用,他们建议使用 gpt-4o-mini。 但是,我发现 Hoarder 可以很好地与我的 LiteLLM 和 OpenWebUI 设置 协同工作,这意味着我可以使用小型语言模型,以最小的电力和用水量,在我自己的服务器上为书签生成摘要和标签,而且 Sam Altman 不会知道我收藏了什么。
这个 Web 应用相当不错。 它提供了对你已收藏页面的全文搜索,并按标签进行过滤。 它还允许你创建基于你感兴趣的标签集的列表或“feeds”。 一旦你点击进入一篇文章,你可以看到缓存的内容,并可以选择生成该页面的摘要。 你可以手动添加标签,也可以在 Hoarder 内部高亮显示和注释页面。
Hoarder 还有一个 Android 应用,允许你从手机访问你收藏的内容。 该应用仍然有点简陋,似乎还不允许你查看缓存/保存的内容,但我相信它会随着时间的推移而变得更好。
Hoarder 是一个快速发展的项目,在接下来的几周内才满 1 周岁。 它只有一个主要的维护者,考虑到这是他的副业,他做得非常出色。
设置 Hoarder
我主要使用 Docker 和 Docker Compose 来管理我的自托管应用。 我按照 开发者提供的说明 来启动并运行 Hoarder。 然后,在 .env 文件中,我们为 OpenAI API 的基本 URL、密钥和我们要使用的推理模型提供了一些略有不同的值。
默认情况下,Hoarder 将拉取页面,尝试提取和简化内容,然后丢弃原始内容。 如果你希望 Hoarder 保留包含所有功能的原始内容的完整副本,请在 .env 文件中将 CRAWLER_FULL_PAGE_ARCHIVE 设置为 true。 这将占用更多的磁盘空间,但意味着你将拥有更真实的原始数据副本。
你可能需要设置一个 HTTP 反向代理,以将请求转发到 Hoarder 的正确容器。 我使用 Caddy,因为它超级简单并且内置了 lets-encrypt 支持:
hoarder.yourdomain.example {
reverse_proxy localhost:3011
}
完成所有设置后,你可以第一次登录。 导航到用户设置并转到 API 密钥,你需要为浏览器集成生成一个密钥。
配置 SingleFile 和 Hoarder 浏览器扩展
我在 Firefox 中同时安装了 SingleFile 和 Hoarder Official Extension。 这两个扩展在我的工作流程中都有其用武之地,但你可能会发现你的情况有所不同。 默认情况下,我会点击进入 Hoarder 扩展,该扩展与服务器的集成更紧密,并且知道我是否已经收藏了某个页面。 如果我登录到一个需要付费才能访问的页面,或者我必须点击大量的 Cookie 横幅并关闭大量的广告,我将使用 SingleFile。
对于 Hoarder 扩展,点击该扩展,然后只需输入你的新实例的基本 URL,并在提示时粘贴你的 API 密钥。 下次你点击该按钮时,它将尝试收藏你在该选项卡中打开的任何内容。
对于 SingleFile,你可以按照 这里的指南 进行操作。 本质上,你需要右键单击扩展图标并转到“管理扩展”,然后打开首选项,展开“目标”,然后输入 API URL(https://YOUR_SERVER_ADDRESS/api/v1/bookmarks/singlefile),你的 API 密钥(你已在上面生成并用于 Hoarder 扩展),然后将 data field name 设置为 file,并将 URL field name 设置为 url。
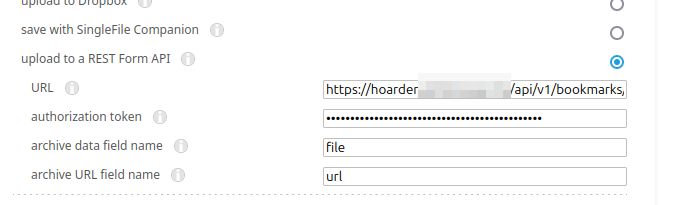 。
。
完成此操作后,下次你点击 SinglePage 扩展图标时,它应该会通过多个步骤来保存当前页面,包括任何支持图像到 Hoarder。
使用 LiteLLM 添加自托管的 AI 标签和摘要
我已经配置了一个 LiteLLM 实例,你可以参考 我之前的帖子 以获取有关如何使其工作的提示和技巧。 请参阅以下示例,并将 litellm.yourdomain.example 和 your-litellm-admin-password 替换为你设置中的相应值。
OPENAI_BASE_URL=https://litellm.yourdomain.example
OPENAI_API_KEY=<your-litellm-admin-password>
INFERENCE_TEXT_MODEL="qwen2.5:14b"
INFERENCE_IMAGE_MODEL=gpt-4o-mini
我还发现 LiteLLM 有一个怪癖,这意味着你必须在你的配置中使用 ollama_chat 作为模型前缀,而不是 ollama,才能启用无错误的 JSON 和模型“工具使用”。 这是我的 LiteLLM 配置 yaml 的摘录:
- model_name: gpt-4o-mini
litellm_params:
model: openai/gpt-4o-mini
api_key: "os.environ/OPENAI_API_KEY"
- model_name: qwen2.5:14b
litellm_params:
drop_params: true
model: ollama_chat/qwen2.5:14b
api_base: http://ollama:11434
我没有任何本地多模态模型既可以与 LiteLLM 一起使用,又可以很好地回答提示,因此我仍然依赖 gpt-4o-mini 来完成 Hoarder 中的基于视觉的任务。
从 Linkding 迁移
直到最近,我一直使用 Linkding 进行书签和个人存档,但我想尝试 Hoarder,因为我很容易被闪亮的东西分散注意力。 据我所知,没有从 Linkding 迁移到 Hoarder 的官方途径,但我能够为此使用 Linkding 的 RSS feed 功能。
首先,我登录到我的 Linkding 实例并导航到设置 > 集成并获取所有书签的 RSS feed 链接
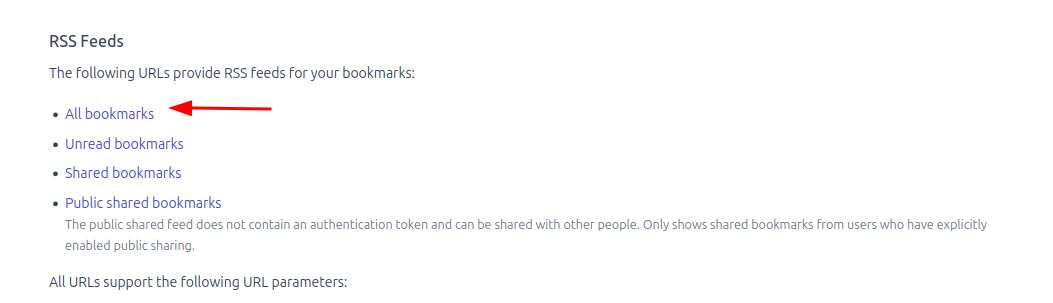 。
。
然后,我打开 Hoarder 的用户设置 > RSS 订阅并将我的 feed 添加为那里的订阅。 我点击“立即获取”以触发初始导入。
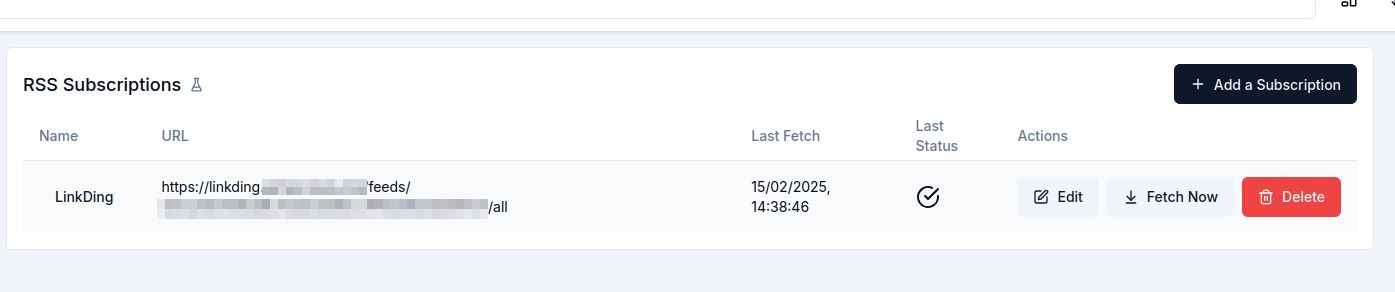
结论
Hoarder 是一个非常酷的工具,而且很容易启动并运行。 尽管它背后的团队规模不大,但它发展迅速,并且已经提供了令人印象深刻且简单的用户体验。 为了让我个人觉得更有用,我希望在应用程序中获得更好的注释支持,无论是通过桌面 Web 体验还是通过移动应用程序。 我也希望看到一个移动应用程序,其中包含用于在应用程序中阅读文章而不是在浏览器中打开的功能。 此外,如果我们能够将缓存的内容导出为电子书,以便我可以在我的 Kindle 或我的 Kobo 上阅读书签内容,那就太好了。
我对 Hoarder 等应用程序的去中心化社交未来也感兴趣。 想象一下,你可以加入一个 Hoarder 服务器联盟,这些服务器都使其书签内容可用于搜索和参考。 甚至可以(可选地)共享注释和笔记。 这将是朝着更开放的替代集中式搜索服务迈出的重要一步。
回复和网络活动
如果你想评论或回复,请 toot me 或 bluesky me 关于此 url,或发送我一个 webmention
3 喜欢



4 转帖




Brainsteam 由 ![]() James Ravenscroft (he/him pronouns, also known as jamesravey) 在英国汉茨郡的朴茨茅斯创建。
由 Hugo 和 plague 主题驱动。
James Ravenscroft (he/him pronouns, also known as jamesravey) 在英国汉茨郡的朴茨茅斯创建。
由 Hugo 和 plague 主题驱动。