`zlib-rs` 比 C 语言更快
Trifecta Tech Foundation Home Initiatives
News & blogs Technology Support us About
zlib-rs 比 C 语言更快
2025-02-25 作者:Folkert de Vries zlib-rs data compression
我们发布了 zlib-rs 的 0.4.2 版本,其中包含许多重大的性能改进。据我们所知,我们现在是解压缩方面最快的 API 兼容 zlib 实现,并且在最重要的压缩用例中也击败了竞争对手。
我们构建了一个仪表板,用于展示当前主分支与其它实现相比的性能,并跟踪我们随时间的性能变化,以便发现任何退化并可视化我们的进展。
这篇文章将 zlib-rs 与最新的 zlib-ng 以及(对于解压缩)zlib-chromium 进行了比较。 这些是专注于性能的领先 C 语言 zlib 实现。 我们很快会写一篇包含更多技术细节的博文,这里只简要介绍最具影响力的变更。
解压缩
上次,我们使用 target-cpu=native 标志进行了基准测试。 这为我们的实现提供了最佳结果,但并不完全公平,因为我们的 Rust 实现可以假定某些 SIMD 功能可用,而 zlib-ng 必须在运行时检查它们。
现在我们已经做了一些更改,以便我们也可以在运行时有效地选择最佳实现。
多版本化(Multiversioning)
选择函数的最佳版本被称为多版本化。 我们有一个在所有 CPU 上运行的基线实现,然后是一些使用 SIMD 指令或其它可能在特定 CPU 上可用或不可用的功能的专用版本。 挑战在于始终选择最佳实现,但运行时成本最小。 这意味着我们希望尽可能少地进行运行时检查,然后执行大量工作。
如今,Rust 本身并不原生支持多版本化。 有添加它的提议(我们对此感到非常兴奋!),但目前,我们必须手动实现它,不幸的是这涉及到一些不安全的代码。 我们很快会写更多关于这方面的内容(对于那些迫不及待的人,相关的代码在这里)。
DFA 优化
C 代码能够使用 switch 的隐式 fallthroughs 来生成非常高效的代码。 Rust 没有与此机制等效的机制,当数据以小块传入时,这确实减慢了我们的速度。
Nikita Popov 建议我们尝试 -Cllvm-args=-enable-dfa-jump-thread 选项,该选项可以恢复大部分性能。 它对确定性有限自动机执行一种跳转线程处理,而我们的解压缩逻辑与此模式匹配。
LLVM 目前默认不启用此标志,但最终计划是这样。 我们也在研究在 rustc 本身中支持此优化,并使其比仅仅盲目地将其应用于整个项目并寄希望于最好的情况更加精细。
这些努力是拟议项目目标和 Trifecta Tech Foundation 的代码生成计划的一部分。
基准测试
据我们所知,我们是当今解压缩方面最快的 API 兼容 zlib 实现。 不仅以相当大的优势击败了 zlib-ng,而且比 chromium 中使用的实现还要快。
和以前一样,我们的基准是解压缩压缩版本的 silesia-small.tar,以 2 的幂大小的块将输入提供给状态机。 小块大小模拟了流式传输用例,较大的块大小模拟了完整输入可用的情况。
对比 zlib-ng
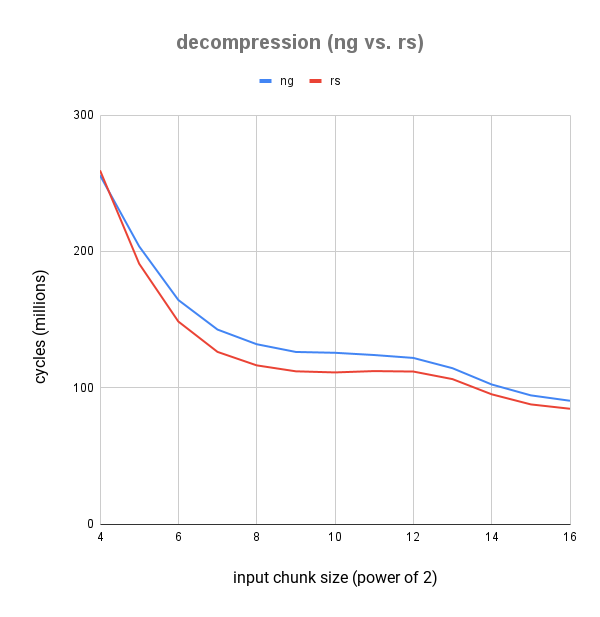
现在,除了最小的块大小之外,我们在所有情况下都比 zlib-ng 快得多。 2^4 = 16 字节的块大小在实践中不太可能与性能相关,因为可以缓冲输入,然后以更大的块解压缩。
但是,对于更相关的块大小,我们明显快于 zlib-ng:对于 1kb 的输入,快超过 10%,对于 65kb 的输入,快超过 6%。
chunk size| zlib-ng| zlib-rs| Δ
---|---|---|---
4| 255.77M ± 179.04K| 259.40M ± 492.87K| 💩 +1.40%
5| 203.64M ± 305.47K| 190.91M ± 343.64K| 🚀 -6.67%
6| 164.30M ± 131.44K| 148.51M ± 193.07K| 🚀 -10.63%
7| 142.62M ± 156.88K| 126.24M ± 113.62K| 🚀 -12.98%
8| 131.87M ± 210.99K| 116.36M ± 116.36K| 🚀 -13.33%
9| 126.19M ± 227.14K| 111.99M ± 100.79K| 🚀 -12.68%
10| 125.58M ± 150.70K| 111.18M ± 111.18K| 🚀 -12.95%
11| 123.94M ± 136.34K| 112.16M ± 201.89K| 🚀 -10.50%
12| 121.81M ± 109.63K| 111.82M ± 89.45K| 🚀 -8.94%
13| 114.27M ± 114.27K| 106.27M ± 138.15K| 🚀 -7.53%
14| 102.34M ± 133.04K| 95.13M ± 95.13K| 🚀 -7.57%
15| 94.35M ± 132.09K| 87.72M ± 96.49K| 🚀 -7.56%
16| 90.40M ± 108.48K| 84.53M ± 84.53K| 🚀 -6.94%
对比 Chromium
对于解压缩,chromium 项目中使用的 zlib 实现(在这里找到,我们通过 libz-sys 的修改版本 使用)通常比 zlib-ng 快。 但是,在这个基准测试中,我们也击败了它,尤其是对于最相关的块大小。
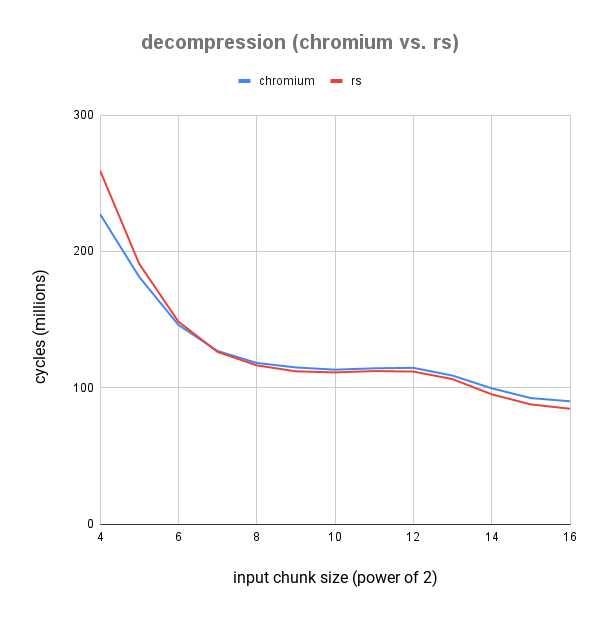
有趣的是,对于较小的块大小,zlib-chromium 大多更快,而对于较大的块大小,性能与 zlib-ng 相当。
chunk size| zlib-chromium| zlib-rs| Δ
---|---|---|---
4| 227.39M ± 363.82K| 259.40M ± 492.87K| 💩 +12.34%
5| 181.29M ± 471.36K| 190.91M ± 343.64K| 💩 +5.04%
6| 146.09M ± 160.70K| 148.51M ± 193.07K| 💩 +1.63%
7| 126.91M ± 164.98K| 126.24M ± 113.62K| 🚀 -0.53%
8| 118.13M ± 94.51K| 116.36M ± 116.36K| 🚀 -1.53%
9| 114.83M ± 91.86K| 111.99M ± 100.79K| 🚀 -2.53%
10| 113.20M ± 90.56K| 111.18M ± 111.18K| 🚀 -1.82%
11| 114.20M ± 102.78K| 112.16M ± 201.89K| 🚀 -1.81%
12| 114.55M ± 103.10K| 111.82M ± 89.45K| 🚀 -2.44%
13| 108.87M ± 87.09K| 106.27M ± 138.15K| 🚀 -2.44%
14| 99.55M ± 129.41K| 95.13M ± 95.13K| 🚀 -4.64%
15| 92.35M ± 157.00K| 87.72M ± 96.49K| 🚀 -5.28%
16| 90.01M ± 180.02K| 84.53M ± 84.53K| 🚀 -6.48%
压缩
我们也一直在努力改进压缩(感谢 Brian Pane,他在此领域贡献了许多 PR),但结果更加复杂。
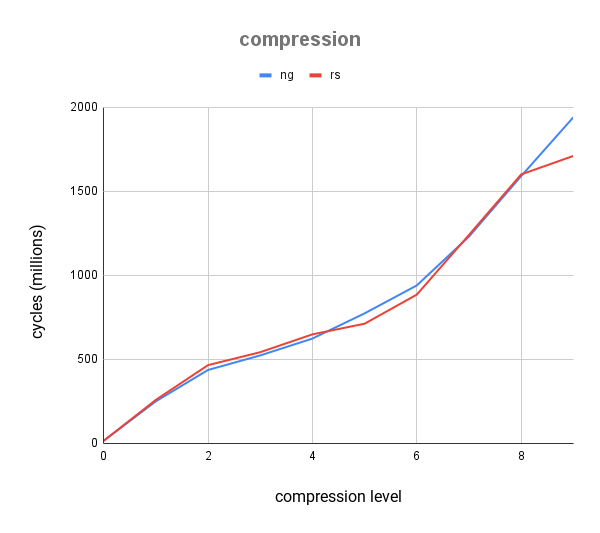
在 x86_64 linux 上,对于一些最重要的压缩级别,我们速度更快,在默认级别 6 上快约 6%,在“最佳压缩”级别 9 上快超过 10%。 但与 zlib-ng 相比,对于大多数其它级别,我们仍然略慢。
compression level| ng| rs| Δ
---|---|---|---
0| 15.07M ± 272.75K| 14.83M ± 260.97K| 🚀 -1.63%
1| 250.09M ± 300.11K| 258.71M ± 388.06K| 💩 +3.33%
2| 436.59M ± 698.54K| 465.33M ± 418.80K| 💩 +6.18%
3| 523.10M ± 156.93K| 542.28M ± 325.37K| 💩 +3.54%
4| 623.40M ± 436.38K| 648.43M ± 324.22K| 💩 +3.86%
5| 773.30M ± 463.98K| 711.81M ± 427.09K| 🚀 -8.64%
6| 939.52M ± 469.76K| 884.79M ± 442.39K| 🚀 -6.19%
7| 1.23G ± 1.48M| 1.24G ± 617.75K| 💩 +0.38%
8| 1.59G ± 159.22K| 1.60G ± 1.92M| 💩 +0.48%
9| 1.94G ± 970.95K| 1.71G ± 512.66K| 🚀 -13.64%
对于大多数用户来说,解压缩是最相关的操作,即使对于压缩,我们也比库存 zlib 快得多。 尽管如此,我们将继续努力提高压缩性能。
结论
zlib-rs 既可以在 C 项目中使用,也可以作为 Rust crate 在 Rust 项目中使用。 对于 Rust 项目,我们建议使用带有 zlib-rs feature flag 的 flate2 crate 的 1.1.0 版本。 为了在 C 项目中使用,zlib-rs 可以构建为 C 动态库(参见说明),并在今天使用 zlib 的任何项目中使用。
我们的实现大部分已经完成,并且性能非常出色。 但是,我们缺少一些与 gzip 文件相关的不太常用的 API 函数,这将使我们在所有情况下都能完全替代。
为了完成这项工作并提高性能和例如打包,我们正在寻求 95,000 欧元的资金。 有关详细信息,请参见工作计划。
如果您有兴趣为 zlib-rs 提供财务支持,请联系我们。
All news and blogs Trifecta Tech Foundation Trifecta Tech Foundation Castellastraat 26 6512 EX Nijmegen The Netherlands +31 24 30 10 484 contact@trifectatech.org Follow us GitHub LinkedIn Mastodon Bluesky RSS Atom