锁竞争 (Lock Contention) 问题分析与解决
Maksim Kita's Blog HomeBlogAbout
锁竞争 (Lock Contention)
2025年3月17日
概述
最近,我回顾了 Resolving a year-long ClickHouse lock contention 这篇文章,并在 C++ Russia 2025 会议上讨论了它。 我想提供更多关于开发过程和一些在原始文章中没有涵盖的技术细节。
动机
2022 年,在 Tinybird 中,我们的一个集群在高负载期间出现了严重的 CPU 利用率不足的问题。
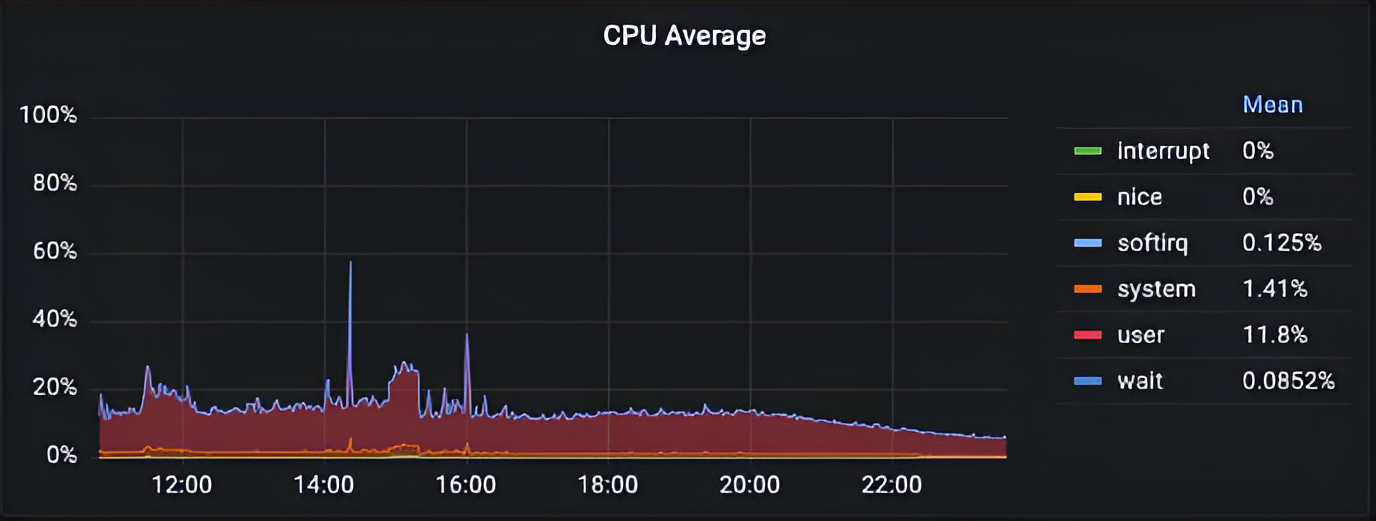 问题原因不明。没有 IO/Network/Memory 瓶颈。在 ClickHouse 中,所有异步指标和查询 profile 事件都是正常的。唯一不寻常的是,随着查询吞吐量的增加,ClickHouse 无法处理负载,并且 CPU 使用率非常低。
问题原因不明。没有 IO/Network/Memory 瓶颈。在 ClickHouse 中,所有异步指标和查询 profile 事件都是正常的。唯一不寻常的是,随着查询吞吐量的增加,ClickHouse 无法处理负载,并且 CPU 使用率非常低。
这个问题持续了一年,在类似的事件中,我们都找不到任何线索。
一年后,在类似事件发生时,我们发现 ContextLockWait 异步指标周期性地增加。Async metrics 会定期计算,包含内存使用情况和一些全局指标。客户端可以使用 system.asynchronous_metrics 表读取它们。其中一个指标是 ContextLockWait,它告诉你有多少线程正在等待 Context 锁。
 在高负载期间,由于
在高负载期间,由于 Context 锁的竞争加剧,该指标可能会增加,这是正常的。但这非常不寻常,因为该指标的正常值在 0 左右,所以我开始从 ClickHouse 内部进行调查。
在事件期间,我定期转储所有线程的堆栈跟踪,以了解有多少线程被 Context 内部的锁阻塞。可以使用 system.stack_trace 表在 ClickHouse 中转储所有线程的堆栈跟踪,使用以下查询:
WITH arrayMap(x -> demangle(addressToSymbol(x)), trace) AS all
SELECT thread_name, thread_id, query_id, arrayStringConcat(all, '\n') AS res
FROM **system.stack_trace** LIMIT 1 FORMAT Vertical;
Row 1:
──────
thread_name: clickhouse-serv
thread_id: 125441
query_id:
res: pthread_cond_wait
std::__1::condition_variable::wait(std::__1::unique_lock<std::__1::mutex>&)
BaseDaemon::waitForTerminationRequest()
DB::Server::main(/*arguments*/)
Poco::Util::Application::run()
DB::Server::run()
Poco::Util::ServerApplication::run(int, char**)
mainEntryClickHouseServer(int, char**)
main
__libc_start_main
_start
我每隔 10-15 秒转储所有线程的堆栈跟踪,以便稍后检查是否有任何线程在 Context 内部锁上花费时间的模式。事件发生后,我能够看到大多数线程被阻塞在需要获取 Context 锁的 Context 类方法上,例如 Context::getSettings()。
在那之后,我几乎可以肯定问题出在 Context 锁竞争上,并开始调查这个特定的锁。
添加 ContextLockWaitMicroseconds
在 ClickHouse 中,有按查询划分的 profile 事件,它们的定义如下:
M(**GlobalThreadPoolJobs**,
"Counts the number of jobs that have been pushed to the global thread pool.",
ValueType::Number) \
M(**GlobalThreadPoolLockWaitMicroseconds**,
"Total time threads have spent waiting for locks in the global thread pool.",
ValueType::Microseconds) \
M(**GlobalThreadPoolJobWaitTimeMicroseconds**,
"Measures the elapsed time from when a job is scheduled in the thread pool to when it is picked up
for execution by a worker thread. This metric helps identify delays in job processing, indicating
the responsiveness of the thread pool to new tasks.",
ValueType::Microseconds) \
M(**LocalThreadPoolLockWaitMicroseconds**,
"Total time threads have spent waiting for locks in the local thread pools.",
ValueType::Microseconds) \
如你所见,它们可以有不同的类型,例如 ValueType::Number 或 ValueType::Microseconds。对于可能存在严重竞争的锁,我们已经有很多指标。例如,你可以看到有一个 GlobalThreadPoolLockWaitMicroseconds 事件,它可以让你看到线程在全局线程池中等待锁花费了多少时间。不幸的是,对于 Context 锁,我们没有类似的指标,我们只有 ContextLock 事件,它告诉你 Context 锁被获取或尝试获取了多少次。这不足以了解 Context 锁竞争是否存在问题,因为预期查询在执行期间可能会多次获取此锁以读取查询设置、查询当前数据库等。我们需要一个指标来告诉我们查询中的线程在等待 Context 锁上花费了多少时间,类似于 GlobalThreadPoolLockWaitMicroseconds 事件。
第一步是将 ContextLockWaitMicroseconds 事件添加到 https://github.com/ClickHouse/ClickHouse/pull/55029 中的 profile 事件中:
M(ContextLock,
"Number of times the lock of Context was acquired or tried to acquire. This is global lock.",
ValueType::Number) \
M(**ContextLockWaitMicroseconds**,
"Context lock wait time in microseconds",
ValueType::Microseconds) \
在 pull request 的开发过程中,我已经发现问题出在 Context 锁上,因为我能够使用 ContextLockWaitMicroseconds 指标在本地重现性能问题,以跟踪查询中的线程在等待 Context 锁上花费的时间。
我选取了一个执行时间为 5 毫秒的示例查询:
SELECT UserID, count(*) FROM (SELECT * FROM hits_clickbench LIMIT 10) GROUP BY UserID
0 rows in set. Elapsed: 0.005 sec.
并尝试并发运行 200 个这样的查询几分钟:
clickhouse-benchmark --query="SELECT UserID, count(*) FROM (SELECT * FROM hits_clickbench LIMIT 10)
GROUP BY UserID" --concurrency=200
并检查结果:
SELECT quantileExact(0.5)(lock_wait_milliseconds), max(lock_wait_milliseconds) FROM
(
SELECT (ProfileEvents['ContextLockWaitMicroseconds'] / 1000.0) AS lock_wait_milliseconds
FROM system.query_log WHERE lock_wait_milliseconds > 0
)
┌─**quantileExact(0.5)(lock_wait_milliseconds)**─┬─**max(lock_wait_milliseconds)**──┐
│ **17.452** │ **382.326** │
└────────────────────────────────────────────┴──────────────────────────────┘
如你所见,有些查询等待 Context 锁长达 382 毫秒,中位数等待时间为 17 毫秒,这是不可接受的。
Context 锁重新设计 (Context Lock Redesign)
实际上,ClickHouse 中有两种类型的 Context:
ContextSharedPart负责存储和提供对所有会话和查询之间共享的全局共享对象的访问,例如:线程池、服务器路径、全局跟踪器、集群信息。Context负责存储和提供对查询或会话特定对象的访问,例如:查询设置、查询缓存、查询当前数据库。
重新设计之前的架构如下所示:

问题在于,即使我们处理 Context 本地的对象时,Context 和 ContextSharedPart 之间的大部分同步都使用单个互斥锁,例如,当线程想要从 Context 读取本地查询设置时,它需要锁定 ContextSharedPart 互斥锁,如果在高数量的低延迟查询的情况下,这会导致巨大的竞争。
在查询执行期间,ClickHouse 可以创建很多 Contexts,因为 ClickHouse 中的每个子查询都可以具有唯一的设置。 例如:
SELECT id, value
FROM (
SELECT id, value
FROM test_table
SETTINGS max_threads = 16
)
WHERE id > 10
SETTINGS max_threads = 32
在这个例子中,我们希望使用 max_threads = 16 执行内部子查询,并使用 max_threads = 32 执行外部子查询。 大量具有许多子查询的低延迟并发查询将为每个查询创建许多 Contexts,并且问题将变得更加严重。
实际上,在项目中拥有全局 Context 或 ApplicationContext 类并将所有内容放入其中是很常见的。 当需要同步时,通常最初使用单个互斥锁实现。 但是,如果锁竞争成为问题,则需要重新设计以使用更复杂的方法。
我们的想法是用两个读写互斥锁 readers–writer lock 替换单个全局互斥锁。 一个全局读写互斥锁用于 ContextSharedPart,一个本地读写互斥锁用于每个 Context。
使用读写互斥锁是因为我们通常进行大量的并发读取(例如,读取设置或某些路径)并且很少进行并发写入。 例如,对于 ContextSharedPart 对象,我们可以在配置热重载期间重写某些字段,但这非常罕见。 对于 Context 对象,在查询执行期间,查询当前数据库,查询设置几乎在查询被解析和分析后永远不会更改。
在许多地方,我完全摆脱了用于初始化某些对象的同步,并使用 call_once 初始化仅初始化一次的对象。
Context 锁重新设计在 pull request https://github.com/ClickHouse/ClickHouse/pull/55121 的范围内实现。
这是重新设计后的架构:

线程安全分析 (Thread Safety Analysis)
Context 锁重新设计在概念上非常简单,但是很难在不引入同步问题的情况下正确实现它。ContextSharedPart 和 Context 都包含许多具有复杂同步逻辑的字段和方法,并且很难手动在它们之间正确拆分同步。不清楚如何确保所有锁都得到正确使用,以及重构后是否没有同步问题。
解决方案是使用 Clang Thread Safety Analysis 并将必要的注解添加到 Context 和 ContextSharedPart 的互斥锁、字段和方法中。现在我想详细解释这是如何完成的以及我遇到了什么问题。
要使用 Clang 线程安全分析,请使用 -Wthread-safety 标志编译你的代码。在生产中,你需要使用 -Werror 或将此特定的 thread-safety 警告标记为错误。
clang -c -Wthread-safety example.cpp
在 Clang 线程安全分析文档中,有一个关于如何使用线程安全注解的示例:
class BankAccount {
private:
**Mutex mu;**
int balance **GUARDED_BY(mu)**;
void depositImpl(int amount) **/* TO FIX: REQUIRES(mu) */** {
balance += amount; // WARNING! Cannot write balance without locking mu.
}
void withdrawImpl(int amount) **REQUIRES(mu)** {
balance -= amount; // OK. Caller must have locked mu.
}
public:
void withdraw(int amount) {
mu.Lock();
withdrawImpl(amount); // OK. We've locked mu.
**/* TO FIX: mu.unlock() or use std::lock_guard */**
} // WARNING! Failed to unlock mu.
void transferFrom(BankAccount& b, int amount) {
mu.Lock();
**/* TO FIX: lock() and unlock() b.mu potentially use std::lock_guard*/**
b.withdrawImpl(amount); // WARNING! Calling withdrawImpl() requires locking b.mu.
depositImpl(amount); // OK. depositImpl() has no requirements.
mu.Unlock();
}
};
我添加了 TO FIX 注释以修复运行线程安全分析后将看到警告的地方。以下是 Clang 线程安全分析文档中最重要的概念:
线程安全分析提供了一种使用功能保护资源的方法。资源可以是数据成员,也可以是提供对某些底层资源访问的函数/方法。该分析确保调用线程无法访问资源(即调用函数或读取/写入数据),除非它具有这样做的能力。 线程可以独占或共享地拥有一个功能。独占功能一次只能由一个线程拥有,而共享功能可以由多个线程同时拥有。此机制强制执行多读者,单写者模式。对受保护数据的写入操作需要独占访问,而读取操作仅需要共享访问。 功能与命名的 C++ 对象相关联,这些对象声明了获取和释放功能的特定方法。对象的名称用于标识该功能。最常见的示例是互斥锁。例如,如果
mu是一个互斥锁,那么调用mu.Lock()会导致调用线程获得访问受mu保护的数据的能力。类似地,调用mu.Unlock()会释放该功能。
Clang 线程安全注解可以分为三个不同的类别。以下是最常用的注解:
- 对于功能类和函数的实现:
CAPABILITY(...)、SCOPED_CAPABILITY、ACQUIRE(…)、ACQUIRE_SHARED(…)、RELEASE(…)、RELEASE_SHARED(…)、RELEASE_GENERIC(…) - 对于保护字段和方法:
GUARDED_BY(...)、PT_GUARDED_BY(...)、REQUIRES(…)、REQUIRES_SHARED(…) - 实用程序:
NO_THREAD_SAFETY_ANALYSIS
这些注解非常灵活,允许你以不同的方式组合它们。例如,你可以使用带有多个互斥锁的 REQUIRES 注解:
Mutex mutex_1, mutex_2;
int a GUARDED_BY(mutex_1);
int b GUARDED_BY(mutex_2);
void test() REQUIRES(mutex_1, mutex_2) {
a = 0;
b = 0;
}
在 LLVM 标准库中,所有互斥锁实现都使用线程安全注解进行注释。示例 std::mutex:
class _LIBCPP_TYPE_VIS **_LIBCPP_THREAD_SAFETY_ANNOTATION(capability("mutex"))** mutex
{
__libcpp_mutex_t __m_ = _LIBCPP_MUTEX_INITIALIZER;
public:
_LIBCPP_INLINE_VISIBILITY
_LIBCPP_CONSTEXPR mutex() = default;
mutex(const mutex&) = delete;
mutex& operator=(const mutex&) = delete;
#if defined(_LIBCPP_HAS_TRIVIAL_MUTEX_DESTRUCTION)
~mutex() = default;
#else
~mutex() _NOEXCEPT;
#endif
**void lock() _LIBCPP_THREAD_SAFETY_ANNOTATION(acquire_capability())**;
**bool try_lock() _NOEXCEPT _LIBCPP_THREAD_SAFETY_ANNOTATION(try_acquire_capability(true))**;
**void unlock() _NOEXCEPT _LIBCPP_THREAD_SAFETY_ANNOTATION(release_capability())**;
typedef __libcpp_mutex_t* native_handle_type;
_LIBCPP_INLINE_VISIBILITY native_handle_type native_handle() {return &__m_;}
};
Clang 线程安全分析是一个用于捕获代码中的同步错误的好工具。但是,它可能有一些开箱即用的生产使用问题。
ClickHouse 有它自己的一些同步原语实现,例如 std::shared_mutex 的实现,因为标准库实现很慢。我们还希望在 lock/unlock 期间具有带有额外逻辑的互斥锁,例如更新指标或 profile 事件。在这两种情况下,我们都不希望在所有互斥锁中都有大量重复的线程安全注解。我们希望隐藏它们并拥有一个通用的解决方案。
为了解决这些问题,我使用 CRTP pattern 设计了 SharedMutexHelper 模板类,该模板类实现了 SharedMutex 标准库要求 https://en.cppreference.com/w/cpp/named_req/SharedMutex 并添加了线程安全注解。
template <typename Derived, typename MutexType = SharedMutex>
class **TSA_CAPABILITY("SharedMutexHelper")** SharedMutexHelper
{
auto & getDerived() { return static_cast<Derived &>(*this); }
public:
// Exclusive ownership
void **lock() TSA_ACQUIRE()** { getDerived().lockImpl(); }
bool **try_lock() TSA_TRY_ACQUIRE(true)** { getDerived().tryLockImpl(); }
void **unlock() TSA_RELEASE()** { getDerived().unlockImpl(); }
// Shared ownership
void **lock_shared() TSA_ACQUIRE_SHARED()** { getDerived().lockSharedImpl(); }
bool **try_lock_shared() TSA_TRY_ACQUIRE_SHARED(true)** { getDerived().tryLockSharedImpl(); }
void **unlock_shared() TSA_RELEASE_SHARED()** { getDerived().unlockSharedImpl(); }
protected:
/// Default implementations for all *Impl methods.
void lockImpl() TSA_NO_THREAD_SAFETY_ANALYSIS { mutex.lock(); }
...
void unlockSharedImpl() TSA_NO_THREAD_SAFETY_ANALYSIS { mutex.unlock_shared(); }
MutexType mutex;
};
SharedMutexHelper 实现了 SharedMutex 要求的所有必要方法,并且默认情况下,将所有方法委托给 MutexType 实现。 派生类必须继承 SharedMutexHelper 并且仅覆盖必要的 lockImpl,tryLockImpl,unlockImpl,lockSharedImpl,tryLockSharedImpl 和 unlockSharedImpl 方法。
这是一个 ContextSharedMutex 的具体实现:
class ContextSharedMutex : public SharedMutexHelper<ContextSharedMutex>
{
private:
using Base = SharedMutexHelper<ContextSharedMutex, SharedMutex>;
friend class SharedMutexHelper<ContextSharedMutex, SharedMutex>;
void **lockImpl**()
{
ProfileEvents::increment(ProfileEvents::ContextLock);
CurrentMetrics::Increment increment{CurrentMetrics::ContextLockWait};
Stopwatch watch;
Base::lockImpl();
ProfileEvents::increment(ProfileEvents::ContextLockWaitMicroseconds,
watch.elapsedMicroseconds());
}
void **lockSharedImpl**()
{
ProfileEvents::increment(ProfileEvents::ContextLock);
CurrentMetrics::Increment increment{CurrentMetrics::ContextLockWait};
Stopwatch watch;
Base::lockSharedImpl();
ProfileEvents::increment(ProfileEvents::ContextLockWaitMicroseconds,
watch.elapsedMicroseconds());
}
};
如你所见,ContextSharedMutex 仅覆盖 lockImpl 和 lockSharedImpl 方法,并在这些方法中更新指标。
另一个问题是,在 LLVM 标准库中,std::shared_lock 不支持线程安全分析。 这可能是因为此类是可移动的,并且线程安全注解不支持可移动锁。 例如,std::unique_lock 也不支持线程安全分析。
为了解决这个问题,我实现了 SharedLockGuard,它是 std::lock_guard 的类似物,但是用于共享互斥锁:
template <typename Mutex>
class **TSA_SCOPED_LOCKABLE** SharedLockGuard
{
public:
explicit SharedLockGuard(Mutex & mutex_) **TSA_ACQUIRE_SHARED(mutex_)**
: mutex(mutex_) { mutex_.lock_shared(); }
~SharedLockGuard() **TSA_RELEASE()** { mutex.unlock_shared(); }
private:
Mutex & mutex;
};
让我们看一个在 ContextSharedPart 中使用线程安全分析的例子。 我们声明哪些字段受 ContextSharedMutex 互斥锁保护。
struct ContextSharedPart : boost::noncopyable
{
/// For access of most of shared objects.
**mutable ContextSharedMutex mutex;**
/// Path to the data directory, with a slash at the end.
String path **TSA_GUARDED_BY(mutex)**;
/// Path to the directory with some control flags for server maintenance.
String flags_path **TSA_GUARDED_BY(mutex)**;
/// Path to the directory with user provided files, usable by 'file' table function.
String dictionaries_lib_path **TSA_GUARDED_BY(mutex)**;
/// Path to the directory with user provided scripts.
String user_scripts_path **TSA_GUARDED_BY(mutex)**;
/// Path to the directory with filesystem caches.
String filesystem_caches_path **TSA_GUARDED_BY(mutex)**;
/// Path to the directory with user provided filesystem caches.
String filesystem_cache_user_path **TSA_GUARDED_BY(mutex)**;
/// Global configuration settings.
ConfigurationPtr config **TSA_GUARDED_BY(mutex)**;
};
然后,在需要访问受保护字段的 ContextSharedPart 方法中,我们使用 SharedLockGuard 进行共享访问,或者使用 std::lock_guard 进行独占访问:
String Context::getPath() const
{
SharedLockGuard lock(shared->mutex);
return shared->path;
}
String Context::getFlagsPath() const
{
SharedLockGuard lock(shared->mutex);
return shared->flags_path;
}
String Context::getUserFilesPath() const
{
SharedLockGuard lock(shared->mutex);
return shared->user_files_path;
}
String Context::getDictionariesLibPath() const
{
SharedLockGuard lock(shared->mutex);
return shared->dictionaries_lib_path;
}
void Context::setPath(const String & path)
{
std::lock_guard lock(shared->mutex);
shared->path = path;
if (shared->tmp_path.empty() && !shared->root_temp_data_on_disk)
shared->tmp_path = shared->path + "tmp/";
if (shared->flags_path.empty())
shared->flags_path = shared->path + "flags/";
if (shared->user_files_path.empty())
shared->user_files_path = shared->path + "user_files/";
if (shared->dictionaries_lib_path.empty())
shared->dictionaries_lib_path = shared->path + "dictionaries_lib/";
if (shared->user_scripts_path.empty())
shared->user_scripts_path = shared->path + "user_scripts/";
}
我在此 pull request https://github.com/ClickHouse/ClickHouse/pull/55278 中实现了线程安全分析重构。
性能改进 (Performance Improvements)
在 Tinybird 中,我们有一个包含大量低延迟查询的综合基准。 我们使用新旧 ClickHouse 版本(在 Context 锁重新设计之后)运行了此基准:
clickhouse benchmark -r --ignore-error \
--concurrency=500 \
--timelimit 600 \
--connect_timeout=20 < queries.txt
并具有以下结果:
- 之前 ~200 QPS。之后 ~600 QPS (~3x 更好)。
- 之前 CPU 利用率仅 ~20%。之后 ~60% (~3x 更好)。
- 之前中位数查询时间 1s。之后 ~0.6s (~2x 更好)。
- 之前最慢的查询花费 ~75s。之后 ~6s (~12x 更好)。
如你所见,在这种基准测试中,由于并发性低,我们无法将 ClickHouse 利用到 100% 的 CPU 使用率。 我们可以使用 --concurrency=1000 完全利用 ClickHouse 实例,并具有大约 ~1000 QPS 和 ~95-96% 的 CPU 利用率。
对于更复杂的生产查询,ClickHouse 最有可能遇到另一个瓶颈。 但是,我们绝对消除了 Context 锁竞争作为潜在瓶颈。
结论 (Conclusion)
锁竞争是现代高并发系统中非常常见的性能问题来源。 你可以将其视为与 CPU/Memory/IO/Network 绑定相同的方式,例如 LockContention 绑定。
要检测此类问题,你可以尝试使用 off-cpu analysis 并引入额外的应用程序级指标,这些指标会告诉你线程在不同的锁中花费了多少时间。
尽可能多地使用所有可用的工具也是一个好主意,包括诸如地址/内存/线程/未定义行为清理器之类的运行时工具以及诸如 Clang 线程安全分析之类的编译时工具。 © 2025 Maksim Kit