新型三层架构应用:The New Three-Tier Application

The New Three-Tier Application
Peter Kraft Qian Li 2025 年 3 月 5 日 DBOS 架构
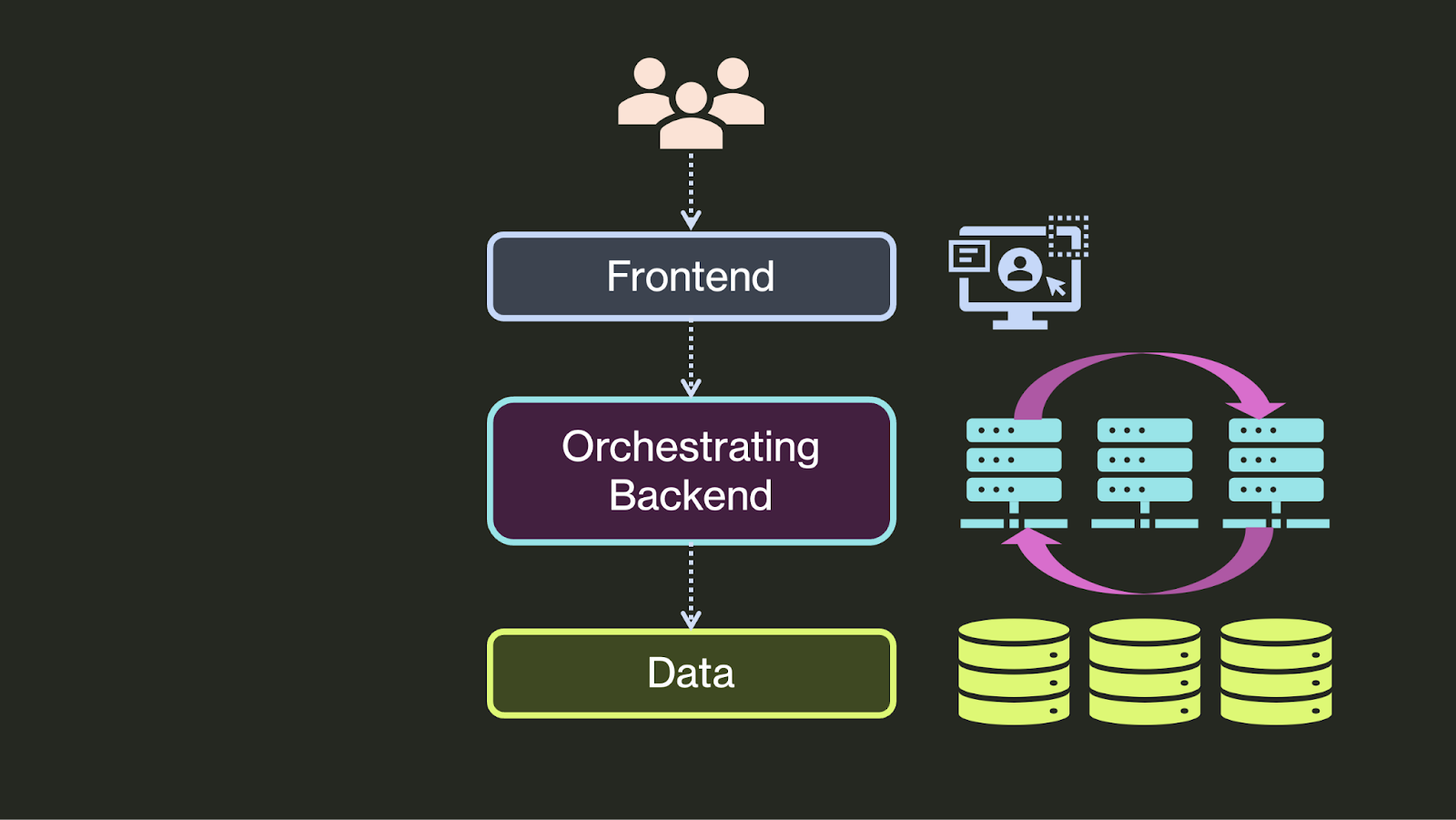
最初(也就是 90 年代),开发者们创建了三层架构应用。正如 Martin Fowler 所说,这三层分别是:数据源层,负责管理持久化数据;领域层,负责实现应用的主要业务逻辑;以及 表示层,负责处理用户与软件之间的交互。这种分离的动机在今天仍然和当时一样重要:提高模块化程度,并允许系统中的不同组件相对独立地进行开发。
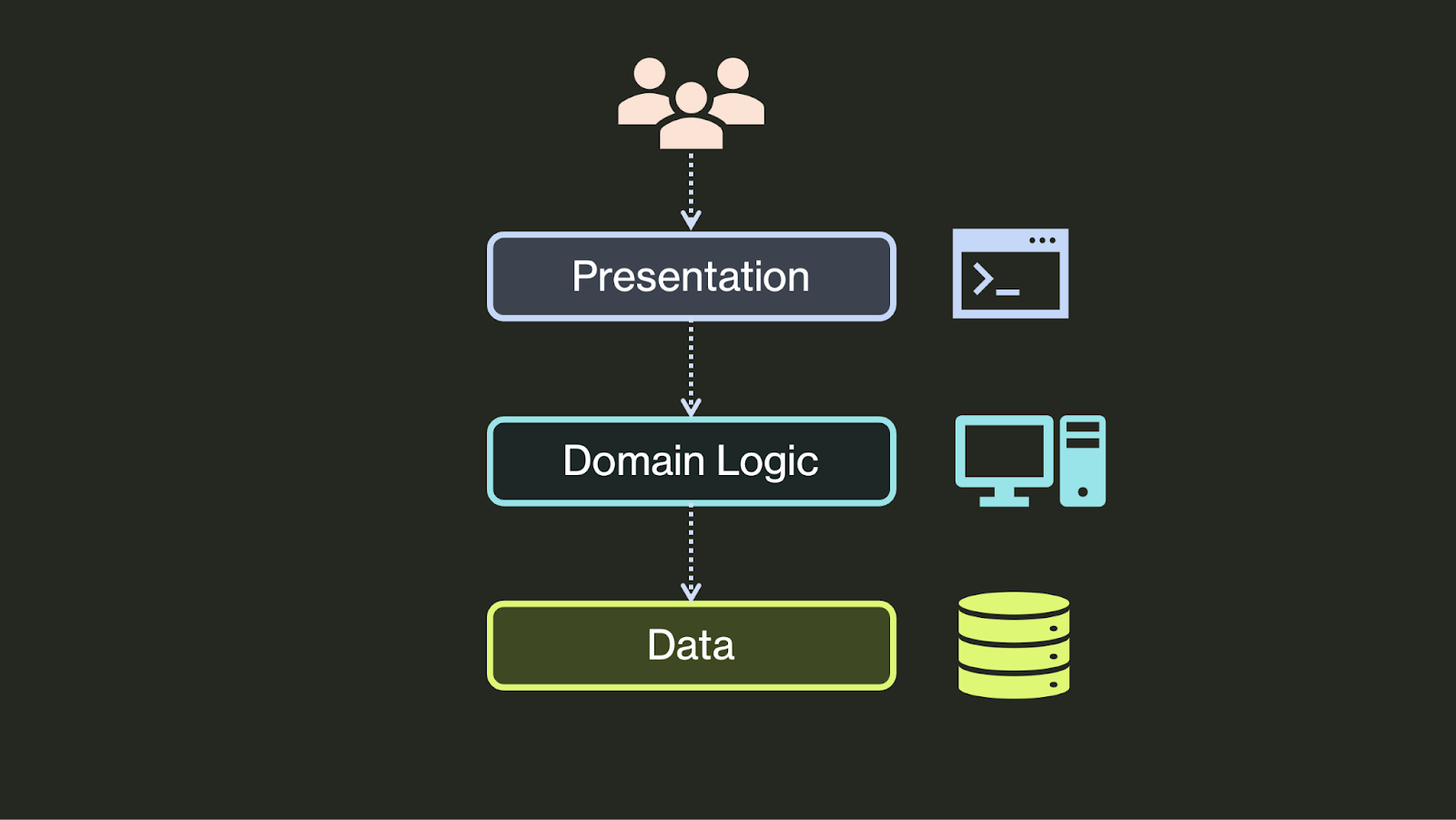
当然,自 90 年代以来,应用架构已经发生了巨大的演变。第一个重大变化发生在表示层。虽然大多数应用曾经使用原生客户端或终端作为其界面,但现在它们大多已转移到 Web 界面。因此,表示层变成了前端,而领域层变成了后端:
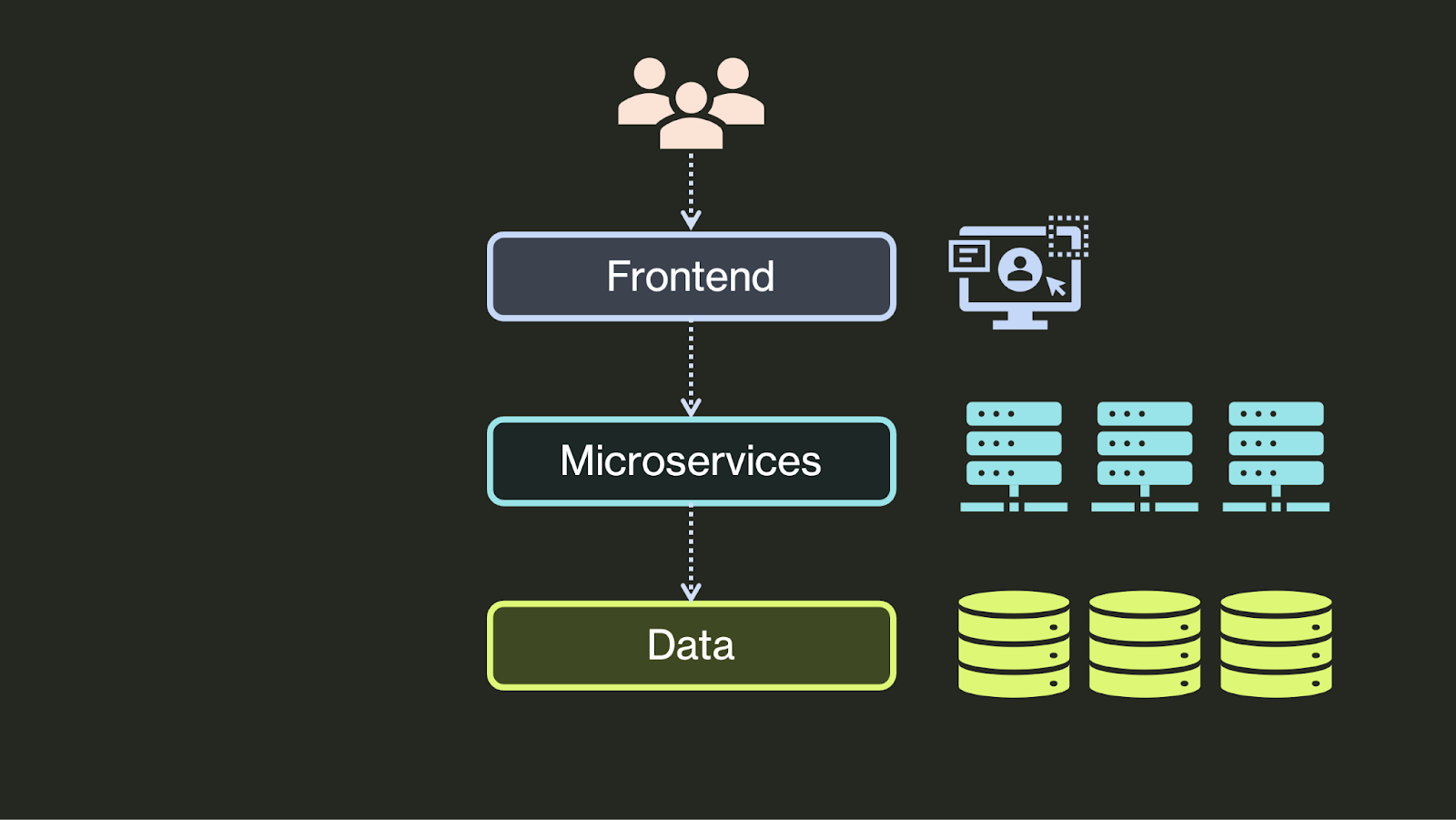
在过去的约 15 年里,领域层/后端发生了更大的转变。这些后端过去主要是单体式的,在单个服务器上的单个软件工件中实现。然而,随着计算复杂性(不断增加的数据量和处理需求)和组织复杂性(更大的工程组织、专业的领域知识、并行开发的需求)的增加,开发人员开始将它们分解为许多松散耦合的微服务,甚至是 serverless 函数。如今,单个应用的后端可以由许多相互协作的服务组成:
这种复杂性为应用开发者带来了新的问题:如何在分布式后端中协调操作?例如:
- 如何原子性地执行多个服务中的一组操作,以便要么全部发生,要么全部不发生?
- 如何请求远程服务仅执行一次任务?
- 如何异步执行任务?
这些都是在任何环境中都难以解决的挑战,但对于分布式后端来说尤其困难,因为任何服务随时都可能发生瞬时故障。即使是单体式后端现在也面临着类似的挑战,因为它们越来越依赖于众多的第三方服务(例如,用于 AI 功能的 OpenAI、用于账单的 Stripe、用于消息传递的 Twilio、用于身份验证的 Auth0),并且必须仔细协调与它们的交互。
为了解决这些问题,开发者引入了一个新的应用层:一个 编排层,它协调分布式微服务之间的操作,并为前端提供一个简单的 API。
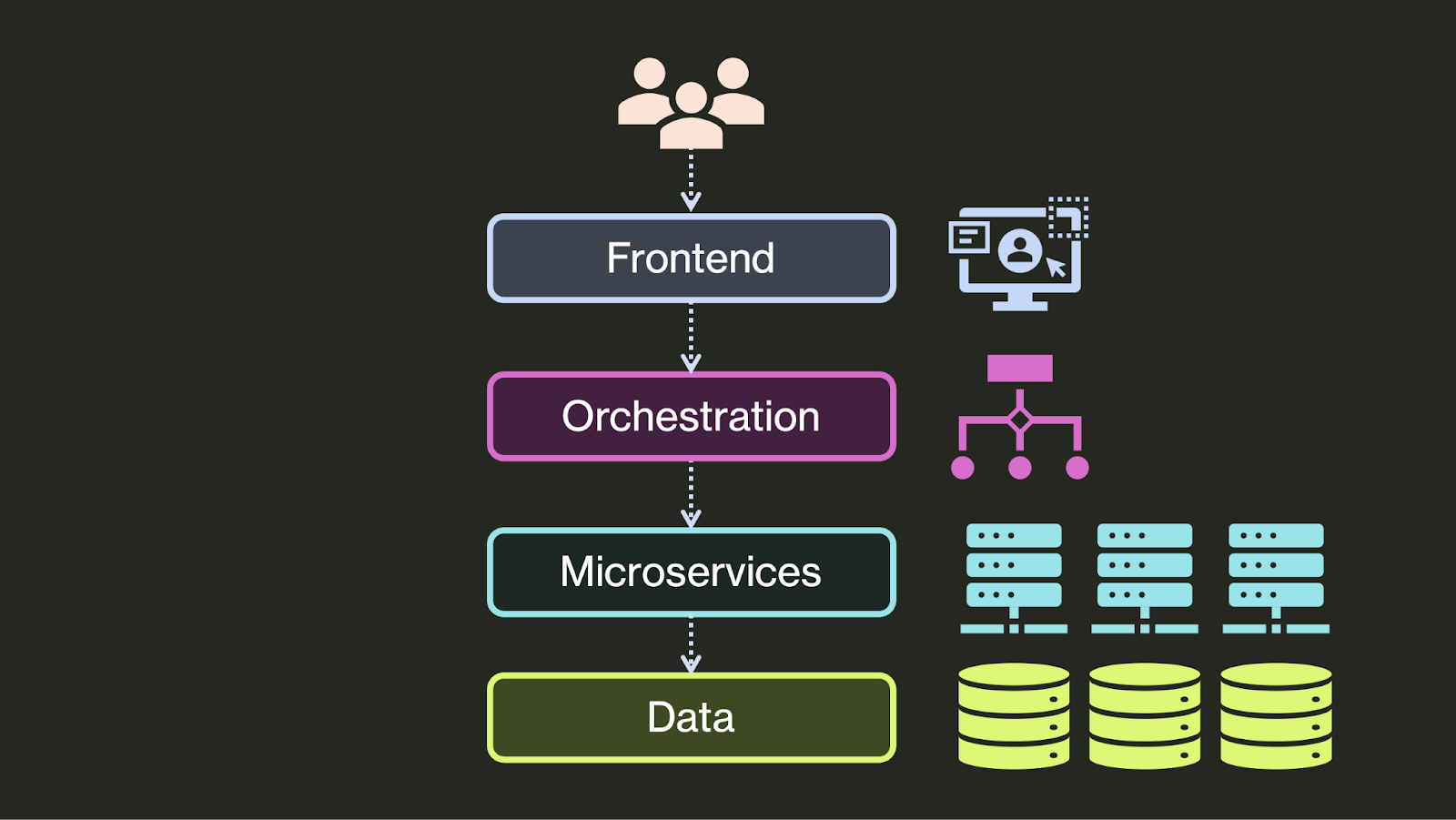
这个编排层主要负责保证代码在发生故障时能够正确执行。例如,编排层可能:
- 通过遵循 saga 模式来保证一组操作以原子方式执行,重试瞬时故障,并在后续操作无法恢复地失败时通过撤销先前的操作来“回滚”。
- 通过使用幂等性键提交任务并在发生瞬时故障时重试来精确地执行一次任务。
- 通过监视异步任务的执行并在其被中断时重新启动它来安全地执行异步任务。
如何构建编排层
到目前为止,开发者构建编排层已经超过十年了。广义上讲,编排层分为两类。每一类都有其优点和缺点,并且大多数大型企业都将两者用于不同的应用程序。
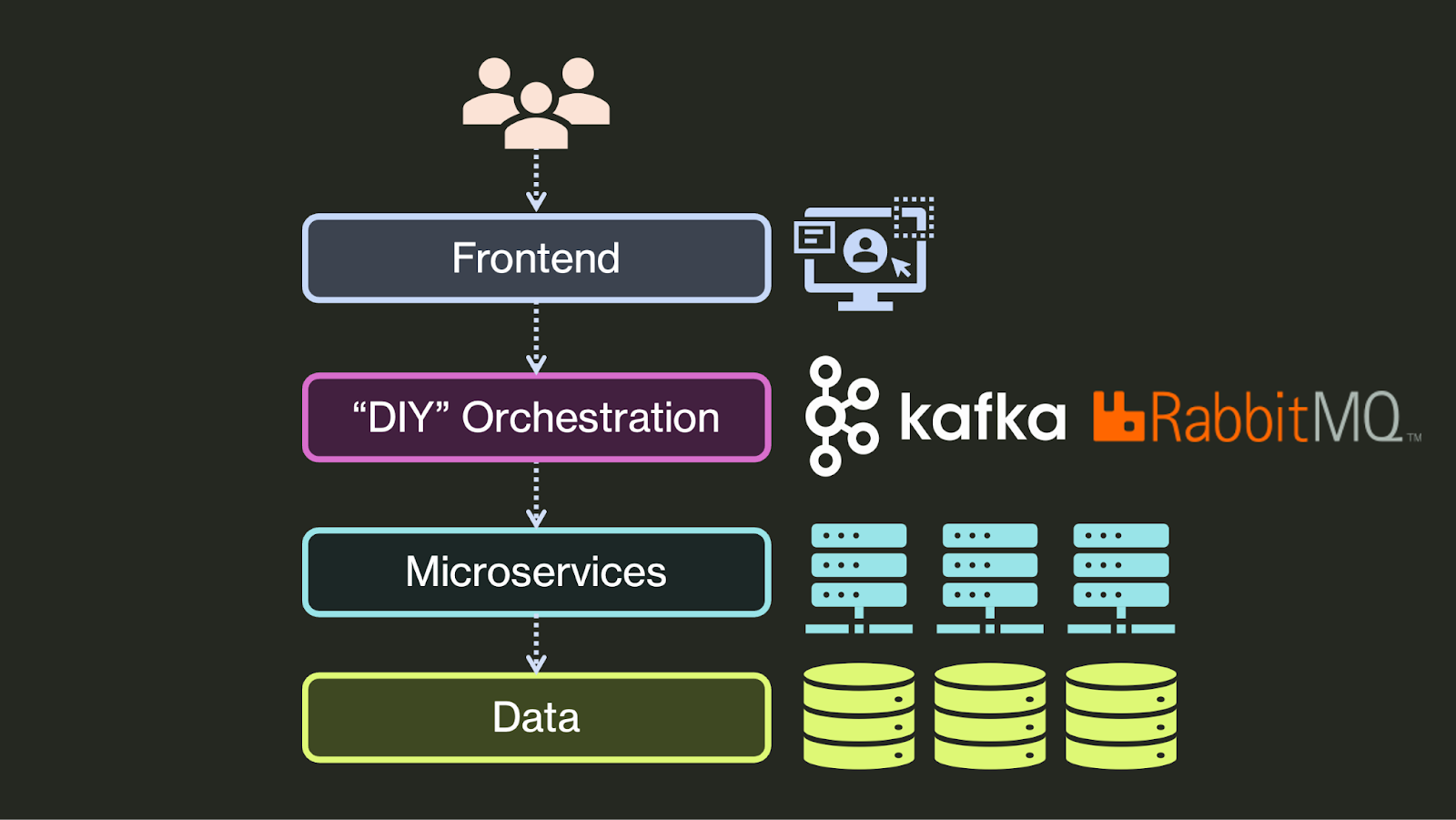
选择 1:自己动手
第一类是“自己动手”编排。在这里,开发者自己实现编排,通常利用诸如 Apache Kafka、AWS SQS 或 RabbitMQ 之类的事件处理系统或消息代理。例如,为了让服务 A 在服务 B 中调度一个任务,服务 A 会将该任务写入 Kafka,然后服务 B 会从 Kafka 读取该消息并执行该任务。正确地执行此操作很困难,并且需要深入了解底层系统的语义。在此示例中,服务 B 必须正确处理重复消息(因为 Kafka 至少传递一次),并且必须在处理其任务时管理超时。
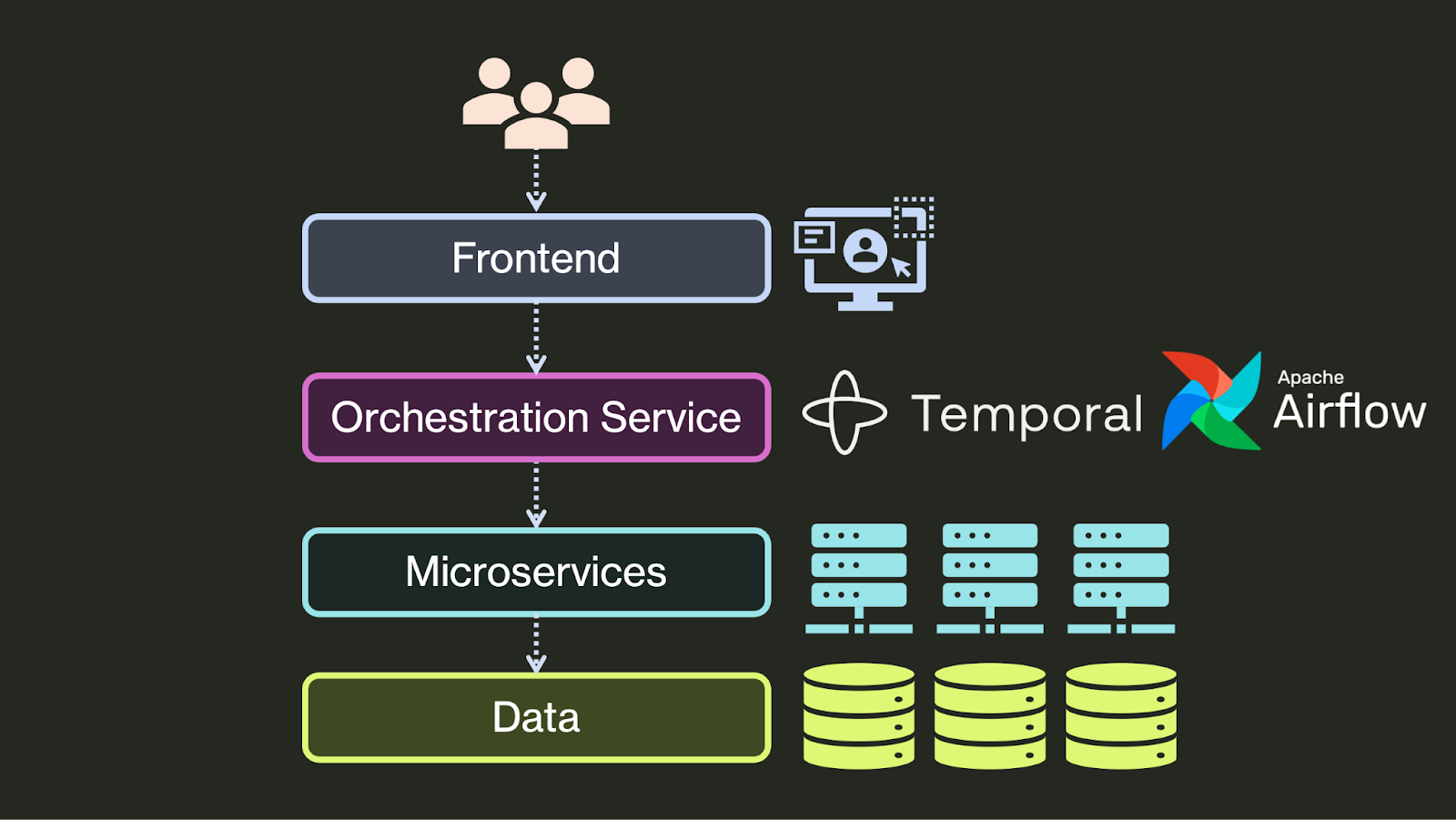
选择 2:专用外部编排器
第二类编排层是专用编排系统,它是在过去几年中为了应对 DIY 解决方案的复杂性而开始出现的。这些系统中的大多数都使用 工作流 抽象,开发者将程序编写为任务工作流。系统持久地执行工作流,重试单个步骤直到它们成功,并在持久性存储中跟踪工作流的进度。一些流行的编排系统包括 AWS Step Functions,用于 AWS 操作(尤其是 AWS Lambda 函数);Apache Airflow,用于数据工程管道;以及 Temporal,用于异步后端。
目前,编排层似乎是管理分布式系统复杂性所必需的。然而,这两类都不完全令人满意。DIY 解决方案复杂且难以维护。编排系统更易于使用,但需要将应用程序的控制流外包给外部系统,从而带来所有架构复杂性。此外,由于编排层和后端层之间需要进行多轮通信,并且大多数编排解决方案都是高度异步的,因此 DIY 解决方案和编排系统通常都带有显著的性能开销。
接下来会发生什么?
覆水难收。在现代企业的技术和组织规模上,编排分布式系统的复杂性是不可避免的。但是,我们需要更好的方法来管理这种复杂性。
复杂性的最大来源来自编排层和应用层的分离。在与业务逻辑分离的单独系统上运行应用程序的控制流会增加开发、测试和调试应用程序的每个步骤的摩擦。它实际上将单个应用程序变成了分布式微服务,从而带来了所有复杂性。
为了管理这种复杂性,我们认为解决编排问题的任何好的解决方案都应该结合编排层和应用层。在 DBOS,我们正在通过构建 DBOS Transact (Python, TypeScript) 来参与竞争:一个轻量级的编排库,您可以将其添加到任何程序中。与现有的编排系统一样,您可以将程序编写为步骤工作流。例如,这是一个简化的程序,用于在电子商务服务中执行结账:
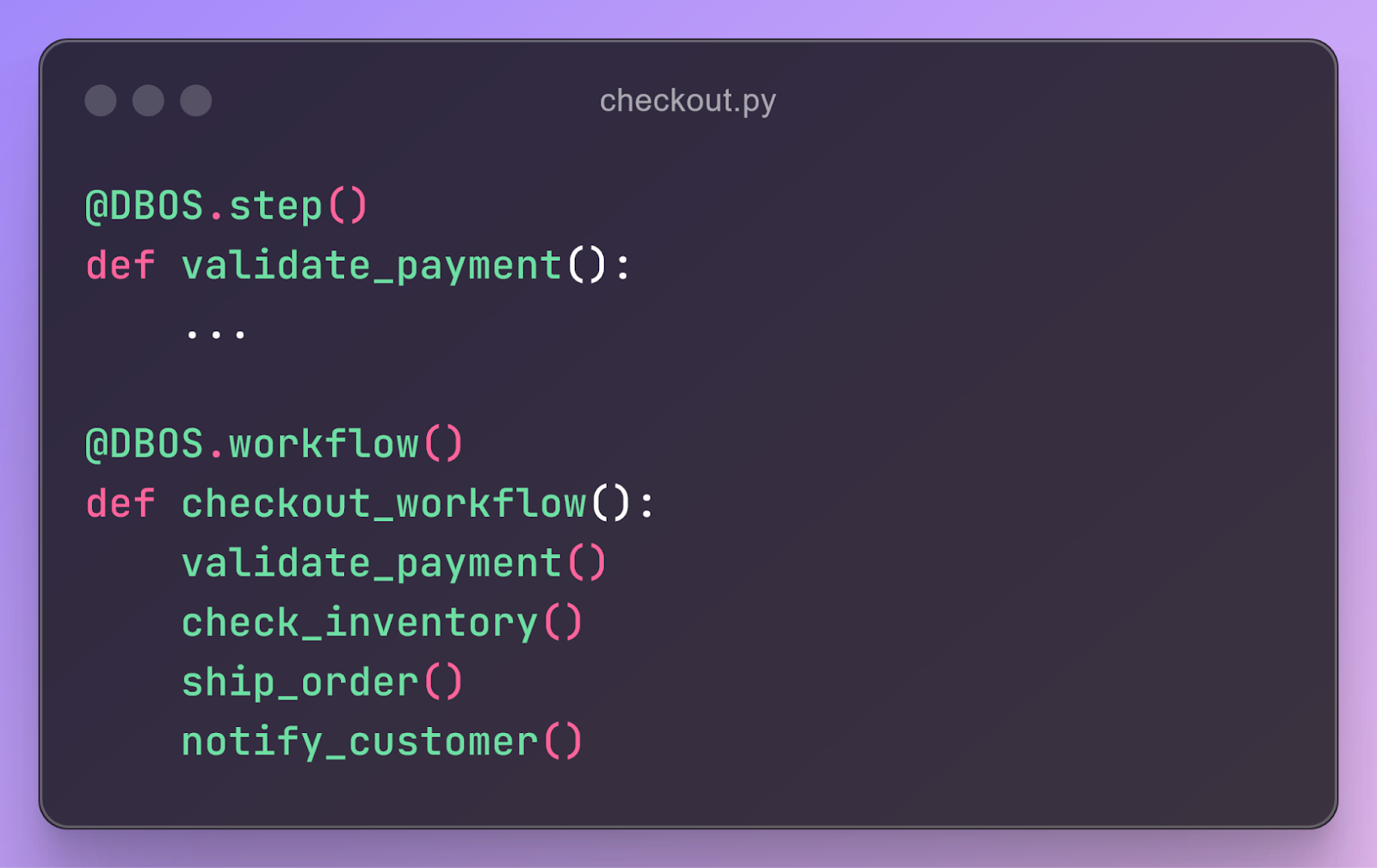
该库(特别是 DBOS.workflow() 和 DBOS.step() 装饰器)使用编排它们的代码包装您的函数。它将您的程序的执行状态(当前正在执行哪些工作流以及它们已完成哪些步骤)保存在 Postgres 数据库中。
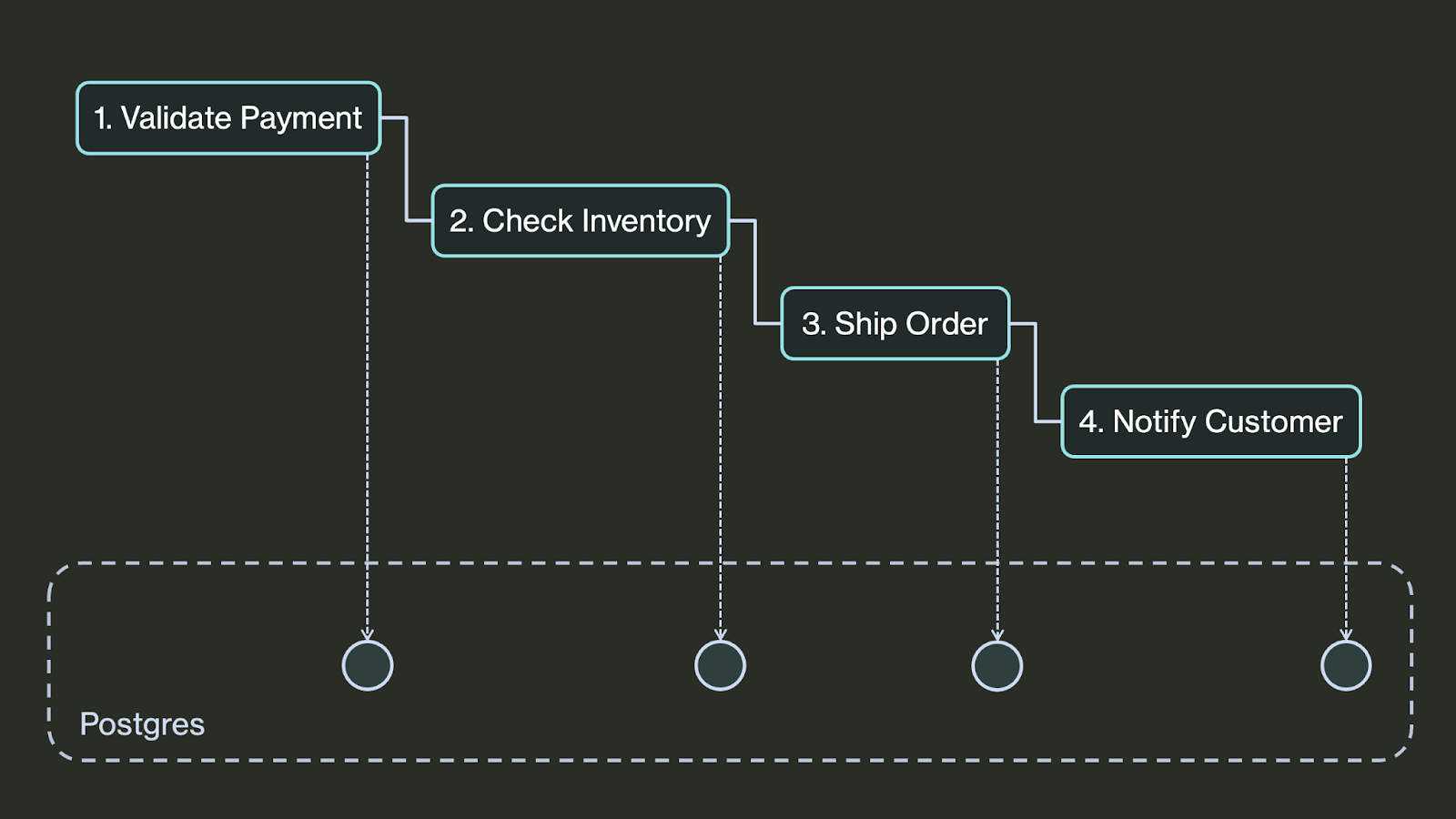
通过将执行状态持久化到数据库,轻量级库可以实现编排系统的主要目标:保证代码在发生故障时能够正确执行。 如果程序失败,该库可以在 Postgres 中查找其状态,以确定下一步要采取的步骤,重试瞬时问题并从其上次完成的步骤恢复中断的执行。
为了使之更具体:想象一下订单发货服务遇到中断。工作流不会取消已付款的订单(这会使客户感到沮丧)。相反,它会以指数退避的方式重试 - 可能需要几个小时 - 直到发货服务恢复。如果结账服务本身在工作流等待时崩溃或重新启动,则不会丢失订单。该服务只需在 Postgres 中查找每个工作流的状态,并从其离开的位置恢复每个工作流,从而确保即使通过多个系统故障也能正确处理客户订单。
在连接到数据库的库中实现编排意味着您可以消除编排层,将其功能推送到应用层(该库检测您的程序)和数据库层(您的工作流状态被持久化到 Postgres)。这管理了分布式世界的复杂性,使微服务 RPC 调用或第三方 API 调用的复杂性更接近于常规函数调用。因此,应用程序将再次具有三层: