微调 Google 的 Gemma 3 模型

![]() unsloth
AboutBlogContactDocumentation
Blog
unsloth
AboutBlogContactDocumentation
Blog

微调并运行 Gemma 3
2025年3月10日 • 作者:Daniel & Michael 2025年3月14日 • 作者:Daniel & Michael
Gemma 3 是 Google 最新的多模态(文本+图像)模型,有 1B、4B、12B 和 27B 四种尺寸。现在 Unsloth 已经支持 Gemma 3,它拥有 128K 的上下文窗口,并支持多语言。
2025年3月19日更新: 请阅读我们关于新的 Gemma 3 训练修复的文章
- 使用我们的 Colab notebook 免费微调 Gemma 3。 另请查看我们的 Gemma 3 (1B) GRPO notebook。
- Unsloth 使 Gemma 3 (12B) 的微调速度提高了 1.6 倍,减少了 60% 的 VRAM 使用量,并且在 48GB GPU 上实现了比使用 Flash Attention 2 的环境长 6 倍的上下文长度。
- 我们在 Hugging Face 上上传了所有版本的 Gemma 3,包括 2-8 bit GGUF、动态 4-bit 和 16-bit 版本。 同时修复了之前我们的 GGUF 不支持视觉支持的问题。
- 阅读我们的指南,了解如何正确运行 Gemma 3。
Unsloth 现在还支持所有内容*,包括:完整微调、8-bit 量化、预训练、所有 transformer 风格的模型(Mixtral、MOE、Cohere 等)以及任何训练算法,例如带有 VLMs 的 GRPO。 多 GPU 支持也将在未来几周内推出 - 因此请加入我们的 newsletter 以便在发布时收到通知! 非常感谢 Gemma 团队与我们合作,并在他们的 Gemma 3 Blogpost 中推荐 Unsloth。
通过以下命令获取最新的稳定版 Unsloth:
pip install --upgrade --force-reinstall --no-cache-dir unsloth unsloth_zoo
✨Gemma 3 训练修复
首先,在我们微调或运行 Gemma 3 之前,我们发现当使用 float16 混合精度时,梯度和激活会变成无穷大。这发生在只有 float16 tensor core 的 T4 GPU、RTX 20x 系列和 V100 GPU 中。
Unsloth 中的解决方案有三个方面:
- 将所有中间激活保持为 bfloat16 格式 - 可以是 float32,但这会使用 2 倍的 VRAM 或 RAM(通过 Unsloth 的异步梯度检查点)。
- 在 float16 中使用 tensor core 执行所有矩阵乘法,但手动进行向上/向下转换,而无需 Pytorch 的混合精度 autocast 的帮助。
- 将所有不需要矩阵乘法的其他选项(layernorms)向上转换为 float32。
- 阅读我们的指南,了解如何正确运行 Gemma 3。
这意味着 Unsloth 是唯一可以在 float16 机器上运行 Gemma 3 的框架! 这也意味着带有免费 Tesla T4 GPU 的 Colab Notebook 也可以使用!
Gemma 3 (27B) 的微调在 Unsloth 中可以在 22GB 以下的 VRAM 中进行! 它的速度也提高了 1.6 倍,并且默认使用 Unsloth dynamic 4-bit 量化以获得卓越的准确性! 您还可以直接将 Gemma 3 与 Unsloth 的 GRPO 一起使用来训练您自己的推理模型。
尝试在我们的免费 Google Colab Notebook 中使用 Unsloth 微调 Gemma 3 (4B)。 要查看我们所有的 notebook 和模型上传,请访问我们的 documentation。
我们还与 Hugging Face 合作开设了 R1 Reasoning 课程!
✨Gemma 3 的怪癖 - 无限激活
首先,在我们微调或运行 Gemma 3 之前,我们发现当使用 float16 混合精度时,梯度和激活会变成无穷大。这发生在只有 float16 tensor core 的 T4 GPU、RTX 20x 系列和 V100 GPU 中。
下图:Gemma 3 1B 到 27B 超过了 float16 的最大值 65504

对于较新的 GPU,例如 RTX 30x 或更高版本、A100、H100 等,这些 GPU 具有 bfloat16 tensor core,因此不会发生此问题! 但为什么?!

Float16 只能表示高达 65504 的数字,而 bfloat16 可以表示高达 10^38 的巨大数字! 但请注意,两种数字格式都只使用 16 位! 这是因为 float16 分配了更多的位,因此它可以更好地表示较小的十进制数,而 bfloat16 不能很好地表示分数。
但为什么要使用 float16? 让我们只使用 float32! 但不幸的是,float32 在 GPU 中对于矩阵乘法来说非常慢 - 有时慢 4 到 10 倍! 所以我们不能这样做。
性能基准
| 模型 | VRAM | 🦥 Unsloth 速度 | 🦥 VRAM 减少 | 🦥 更长的上下文 | 🤗 Hugging Face+FA2 | | -------- | ----- | --------------- | ----------- | ------------- | ------------------ | | Gemma-3-12B | 24GB | 1.7x | >60% | 6x 更长 | 1x |
我们使用 Alpaca 数据集进行了测试,批量大小为 2,梯度累积步数为 4,rank = 32,并在所有线性层(q、k、v、o、gate、up、down)上应用了 QLoRA。
🦥 所有内容支持 + 更新
初步支持完整微调和 8-bit 微调 - 分别设置 full_finetuning = True 和 load_in_8bit = True。 两者将在未来得到进一步优化! 提醒您,您将需要更强大的 GPU!
新的 Unsloth Auto Model 支持 - 现在支持几乎所有模型! Unsloth 现在开箱即用地支持视觉和文本模型,无需自定义实现(并且所有模型都经过优化)。 这允许更快、更少出错、更稳定/简化的微调体验。
我们还支持:Qwen 的 QwQ-32B、Mistral 的 Mixtral、IBM 的 3.2 Granite、Microsoft 的 Phi-4-mini、Cohere 的 c4ai-command-a、AllenAI 的 OLMo-2 以及所有其他 transformer 风格的模型! 我们还为这些模型上传了动态 4-bt 和 GGUF。
Unsloth 中的多项优化使 VRAM 使用量进一步减少 +10%,4-bit 的速度提高了 >10%(在我们最初的 2 倍速度、70% 更少的内存使用量之上)。 8-bit 和完整微调也受益。
现在应该可以通过 pip install unsloth 支持 Windows! 利用 'pip install triton-windows',它为 Triton 提供了一个可通过 pip 安装的路径。
现在 16bit 和 8bit 转换为 llama.cpp GGUF 不需要编译! 这解决了许多问题,这意味着无需安装 GCC、Microsoft Visual Studio 等。
视觉微调: 仅针对支持的视觉模型训练完成/响应! Pixtral 和 Llava 微调现在已修复! 事实上,几乎所有视觉模型都开箱即用! 视觉模型现在自动调整图像大小,这可以防止 OOM 并允许截断序列长度。
Unsloth 中的 GRPO 现在允许非 Unsloth 上传的模型也采用 4bit - 大大减少了 VRAM 使用量! (即使用您自己对 Llama 的微调)
新的训练日志和信息 - 训练参数计数、总批量大小
完全覆盖所有模型的梯度累积错误修复!
🔮 Gemma 3 分析
这是我们对 Gemma 3 架构进行的深入分析:
- 1B 纯文本,4、12、27B 视觉 + 文本。 14T tokens
- 128K 上下文长度,从 32K 进一步训练
- 移除 attn softcapping。 替换为 QK norm
- 5 sliding + 1 global attn
- 1024 sliding window attention
- RL - BOND, WARM, WARP
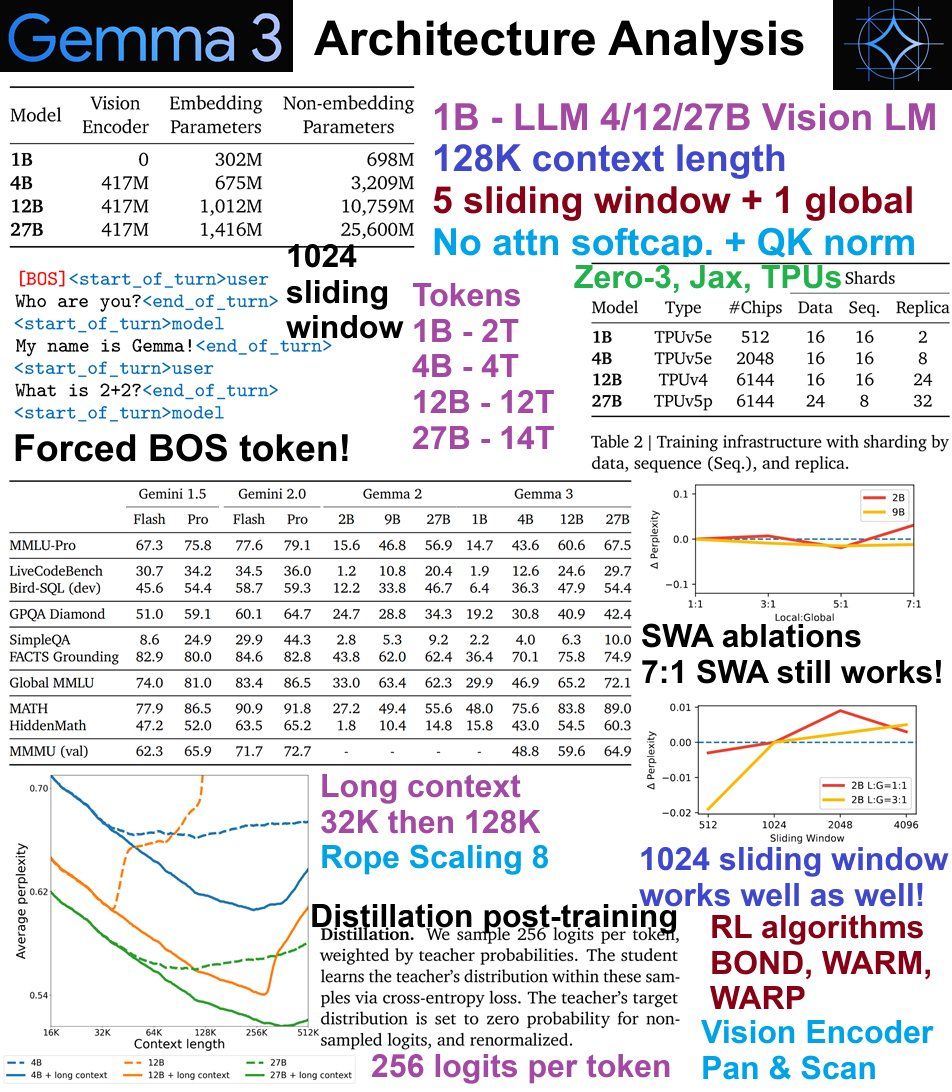
详细分析
- Gemma 2 的架构差异:添加了更多滑动窗口以减少 KV 缓存负载! 发现 5:1 的比例效果很好,并且消融研究表明 7:1 甚至也可以! SWA 是 1024 - 消融研究表明 1024 到 2048 的效果很好。
- 训练,后训练 Gemma-3 使用 TPU,以及带有 JAX 的 Zero-3 like algos。 27B 在 14 万亿个 tokens 上进行训练。 12B = 12T,4B = 4T,1B = 2T tokens。 所有人在 RL/后训练阶段都使用了 distillation。 从更大的 instruct 模型中采样了每个 token 256 个 logits(不确定是哪个 - 也许是闭源的?)。 使用了 RL 算法,如 BOND、WARM 和 WARP。
- Chat template 现在强制使用 BOS token! 使用
<start_of_turn>user和<start_of_turn>model。 262K 词汇大小。 SentencePiece 分词器,带有拆分数字、保留空格和字节回退。 - 长上下文 & 视觉编码器:从 32K 上下文训练,然后扩展到 128K 上下文。 使用了 RoPE Scaling 为 8。 Pan & Scan 算法用于视觉编码器。 视觉编码器以 896 * 896 的固定分辨率运行。 在推理时使用窗口化以允许其他尺寸。
🦥 Dynamic BnB 4-bit 量化
我们上传了适用于 Gemma 3 的 Unsloth Dynamic 4-bit 量化,与标准 4-bit 相比,可显着提高准确性 - 尤其是在视觉模型中,差异最为明显。 正如我们之前的 Qwen2-VL 实验 中所示,我们的动态量化仅增加了 10% 的 VRAM 使用量,就提供了显着的准确性提升。
一个很好的基准示例是我们提交给 Hugging Face OpenLLM Leaderboard 的 Phi-4 的动态 4-bit 量化。 它的得分几乎与我们的 16-bit 版本一样高,并且在 MMLU 上优于标准 BnB 4-bit 和 Microsoft 的官方 16-bit 模型。
另请参见下方 Gemma 3 (27B) 与 Unsloth Dynamic 量化相比的激活和权重误差分析图:


💕 谢谢!
非常感谢 Google 团队的支持,以及感谢大家使用和分享 Unsloth - 我们非常感谢。 🙏
与往常一样,请务必加入我们的 Reddit page 和 Discord 服务器寻求帮助或只是为了表达您的支持! 您也可以在 Twitter 上关注我们并加入我们的 newsletter。
感谢您的阅读!
Daniel & Michael Han 🦥 2025年3月14日
现在免费 Fine-tune Gemma 3!
Company
AboutLinkedInPrivacy PolicyTerms of Service
Product
IntroductionPricingDownloadDocumentation🦥 Models
Community
![]() Twitter (X)
Twitter (X)
![]() Reddit
Reddit
![]() Hugging Face
Hugging Face
![]() Discord
Discord
![]() LinkedIn
LinkedIn
 unsloth
support@unsloth.ai
© 2025 unsloth. All rights reserved.
Join Our Discord
unsloth
support@unsloth.ai
© 2025 unsloth. All rights reserved.
Join Our Discord