通过 LLM 表征解读人类大脑中的语言处理
[中文正文内容]
通过 LLM 表征解读人类大脑中的语言处理
2025 年 3 月 21 日
Mariano Schain, Software Engineer, 和 Ariel Goldstein, Visiting Researcher, Google Research
为预测后续话语并使用上下文嵌入适应任务而优化的大型语言模型(LLMs)能够以接近人类熟练程度的水平处理自然语言。这项研究表明,当人类大脑处理日常对话时,人类大脑中的神经活动与大型语言模型(LLMs)中语音和语言的内部上下文嵌入呈线性对齐。
快速链接
人类大脑在日常对话中是如何处理自然语言的?从理论上讲,大型语言模型(LLMs)和人类语言的符号心理语言学模型为自然语言的编码提供了根本不同的计算框架。大型语言模型不依赖于词性的符号部分或句法规则。相反,它们利用简单的自监督目标,例如通过强化学习增强的下一个词预测和生成。这使得它们能够从真实世界的文本语料库中生成特定于上下文的语言输出,有效地将自然语音(声音)和语言(单词)的统计结构编码到多维嵌入空间中。
受到 LLMs 成功的启发,我们在 Google Research 的团队与Princeton University, NYU, 和 HUJI合作,试图探索人类大脑和深度语言模型在处理自然语言以实现其卓越能力方面的异同。在过去五年的系列研究中,我们探索了特定深度学习模型的内部表征(嵌入)与自然自由对话期间人类大脑神经活动之间的相似性,证明了深度语言模型的嵌入作为理解人类大脑如何处理语言的框架的力量。我们证明了深度语言模型生成的词级内部嵌入与人类大脑中与语音理解和产生相关的既定大脑区域的神经活动模式对齐。
语言的类似基于嵌入的表征
我们最近发表在 Nature Human Behaviour上的研究调查了基于 Transformer 的语音转文本模型中的内部表征与真实对话期间人类大脑中的神经处理序列之间的对齐情况。在该研究中,我们分析了在使用颅内电极记录的自发对话期间的神经活动。我们将神经活动模式与 Whisper 语音转文本模型生成的内部表征(嵌入)进行了比较,重点关注模型的语言特征如何与大脑的自然语音处理对齐。
对于听到的(在语音理解期间)或说出的(在语音产生期间)的每个单词,我们从语音转文本模型中提取了两种类型的嵌入 - 来自模型语音编码器的 语音 嵌入和来自模型解码器的基于单词的 语言 嵌入。我们估计了一个线性变换,以根据每个对话中每个单词的语音转文本嵌入来预测大脑的神经信号。该研究揭示了人类大脑语音区域的神经活动与模型的语音嵌入之间以及大脑语言区域的神经活动与模型的语言嵌入之间惊人的对齐情况。以下动画说明了这种对齐,该动画模拟了大脑对受试者语言理解的神经反应序列:
播放静音循环视频暂停静音循环视频
当受试者听到“How are you doing?”这句话时,大脑对受试者语言理解的神经反应序列。
当听者处理传入的口语单词时,我们观察到一系列神经反应:最初,当每个单词被清楚地表达时,语音嵌入使我们能够预测沿颞上回(STG)的语音区域的皮层活动。几百毫秒后,当听者开始解码单词的含义时,语言嵌入会预测Broca 区(位于额下回;IFG)的皮层活动。
转向参与者的产生,我们观察到不同的(反向的!)神经反应序列:
播放静音循环视频暂停静音循环视频
受试者回答“feeling fantastic"时,对受试者语言产生的神经反应序列。
更仔细地观察这种对齐,在大约在说出单词前 500 毫秒(当受试者准备表达下一个单词时),语言嵌入(蓝色描绘)预测Broca 区的皮质活动。几百毫秒后(仍然在单词出现之前),语音嵌入(红色描绘)预测运动皮层(MC)的神经活动,因为说话者计划发音语音序列。最后,在说话者清楚地表达单词之后,当听者听到自己的声音时,语音嵌入预测 STG 听觉区域的神经活动。这种动态反映了神经处理的序列,从计划在语言区域说什么开始,然后计划如何在运动区域中表达它,最后监测在感知语音区域中说了什么。
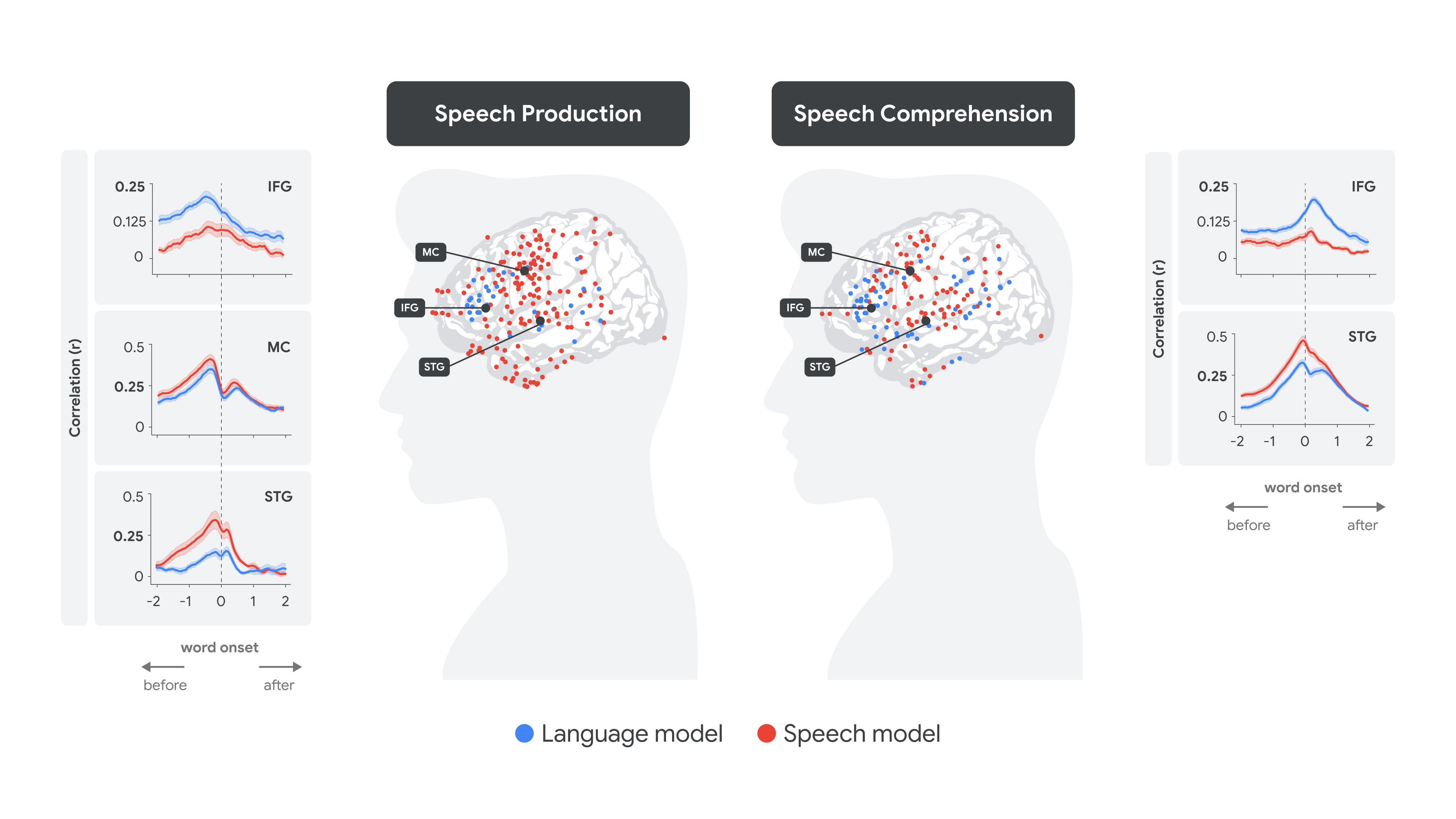
下图说明了全脑分析的定量结果:对于每个单词,给定其语音嵌入(红色)和语言嵌入(蓝色),我们预测了在单词开始前 -2 秒到 +2 秒的时间滞后内(图中的 x 轴值为 0)每个电极的神经反应。这是在语音产生(左图)和语音理解(右图)期间完成的。相关图表说明了作为各个大脑区域电极滞后的函数的,我们对所有单词神经活动预测的准确性(相关性)。
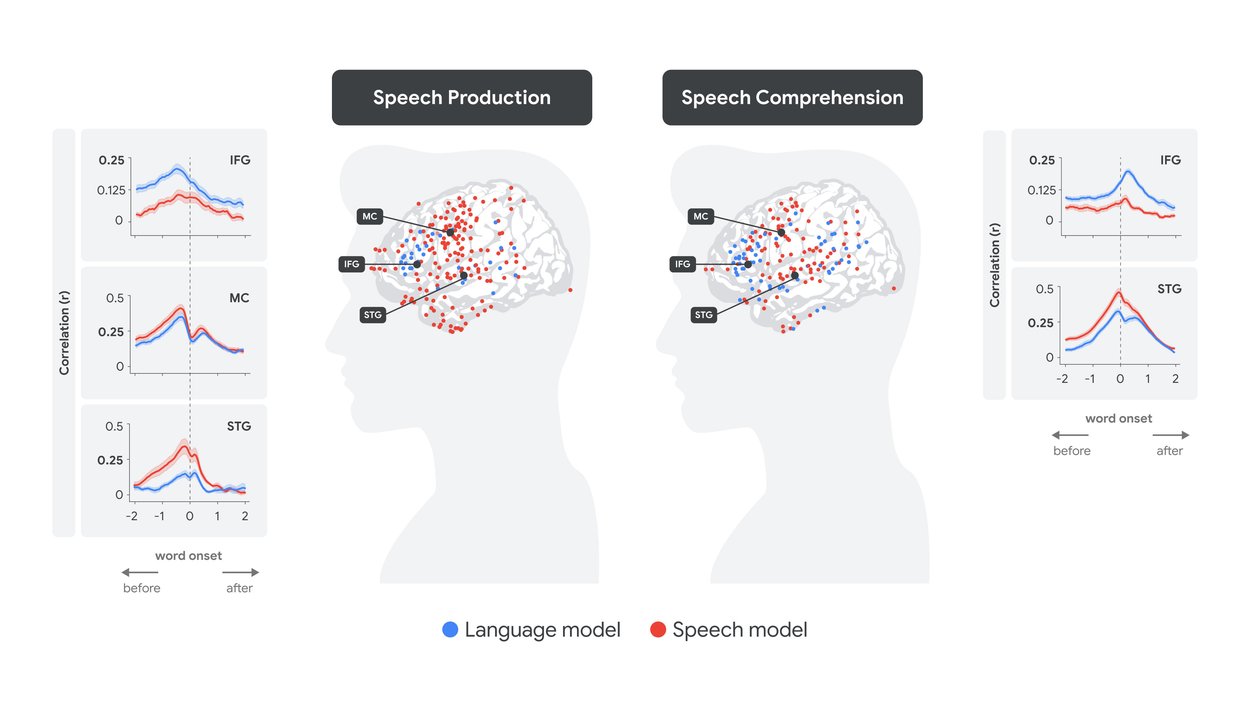
将语音和语言嵌入拟合到人类大脑在产生和理解时的信号。
在语音产生过程中,很明显,IFG 中的语言嵌入(蓝色)在感觉运动区域中语音嵌入(红色)达到峰值之前达到峰值,然后是在 STG 中语音编码达到峰值。相反,在语音理解过程中,峰值编码转移到单词出现之后,STG 中的语音嵌入(红色)在 IFG 中的语言编码(蓝色)之前达到峰值。
总而言之,我们的研究结果表明,语音转文本模型嵌入提供了一个有凝聚力的框架,用于理解自然对话过程中处理语言的神经基础。令人惊讶的是,虽然 Whisper 仅为语音识别而开发,而没有考虑大脑如何处理语言,但我们发现其内部表征与自然对话期间的神经活动对齐。这种对齐并非得到保证 - 阴性结果本应表明嵌入和神经信号之间几乎没有对应关系,表明模型的表征没有捕获大脑的语言处理机制。
LLMs 和人类大脑之间的对齐所揭示的一个特别有趣的概念是神经处理中的“软层次结构”的概念。虽然大脑中涉及语言的区域(如 IFG)倾向于优先处理词级的语义和句法信息 - 正如与语言嵌入(蓝色)更强的对齐所表明的那样 - 但它们也捕获较低级别的听觉特征,这从与语音嵌入(红色)较低但显着对齐中可以看出。相反,较低阶语音区域(如 STG)倾向于优先处理声音和音位 - 正如与语音嵌入(红色)更强的对齐所表明的那样 - 它们也捕获词级信息,这从与语言嵌入(蓝色)较低但显着对齐中可以看出。
LLMs 和人类大脑之间的共享目标和几何结构
LLMs 通过使用一个简单的目标来训练处理自然语言:预测序列中的下一个单词。在发表在 Nature Neuroscience上的一篇论文中,我们发现,与 LLMs 类似,听者大脑的语言区域试图在说出下一个单词之前预测它。此外,与 LLMs 类似,听众对单词出现之前的预测的信心会改变单词表达后他们的惊讶程度(预测误差)。这些发现为自回归 LLMs 和人类大脑共享的基于嵌入的上下文表征的,预先出现的预测,事后出现的惊讶和基本计算原理提供了令人信服的新证据。在发表在 Nature Communications上的另一篇论文中,该团队还发现,自然语言中单词之间的关系(如 LLM 嵌入空间的几何结构所捕获的那样)与语言区域大脑诱导的表征(即大脑嵌入)的几何结构对齐。
LLMs 和人类大脑处理自然语言方式之间的差异
虽然人类大脑和基于 Transformer 的 LLMs 在处理自然语言方面共享基本计算原理,但它们的基础神经回路架构却截然不同。例如,在后续研究中,我们调查了基于 Transformer 的 LLMs 和人类大脑中如何在各层之间处理信息。该团队发现,虽然 LLMs 和人类大脑语言区域的各层之间的非线性变换相似,但实现方式却大相径庭。与 Transformer 架构同时处理数百到数千个单词不同,语言区域似乎按顺序,逐个单词,递归和暂时地分析语言。
总结和未来方向
该团队的工作积累的证据揭示了人类大脑和深度学习模型处理自然语言方式之间的几个共享计算原理。这些发现表明,深度学习模型可以为理解大脑基于统计学习,盲优化和直接适应自然处理自然语言的神经代码提供一个新的计算框架。同时,基于 Transformer 的语言模型的神经架构,语言数据类型和规模,训练协议与人类大脑在社会环境中自然获取语言的生物结构和发育阶段之间存在显着差异。展望未来,我们的目标是创建创新的,受生物学启发的具有改进的信息处理和真实世界功能的 神经网络。我们计划通过调整更符合人类经验的神经架构,学习协议和训练数据来实现这一目标。
致谢
所描述的工作是 Google Research 与 the Hasson Lab 在 Princeton University 的 Neuroscience Institute 和 Psychology Department,the DeepCognitionLab 在 Hebrew University Business School 和 Cognitive Department,以及来自 NYU Langone Comprehensive Epilepsy Center 的研究人员的长期合作结果。
标签:
快速链接
其他感兴趣的帖子
- [
 2025 年 3 月 20 日 Google Pixel Watch 3 上的脉搏消失检测
2025 年 3 月 20 日 Google Pixel Watch 3 上的脉搏消失检测
- Health & Bioscience ·
- Mobile Systems ·
- Product ](https://research.google/blog/deciphering-language-processing-in-the-human-brain-through-llm-representations/</blog/loss-of-pulse-detection-on-the-google-pixel-watch-3/>)
- [
 2025 年 3 月 18 日 使用差分隐私 LLM 推理生成合成数据
2025 年 3 月 18 日 使用差分隐私 LLM 推理生成合成数据
- Machine Intelligence ·
- Natural Language Processing ·
- Security, Privacy and Abuse Prevention ](https://research.google/blog/deciphering-language-processing-in-the-human-brain-through-llm-representations/</blog/generating-synthetic-data-with-differentially-private-llm-inference/>)
- [
 2025 年 3 月 6 日 从诊断到治疗:推进 AMIE 进行纵向疾病管理
2025 年 3 月 6 日 从诊断到治疗:推进 AMIE 进行纵向疾病管理
- Generative AI ·
- Health & Bioscience ](https://research.google/blog/deciphering-language-processing-in-the-human-brain-through-llm-representations/</blog/from-diagnosis-to-treatment-advancing-amie-for-longitudinal-disease-management/>)
关注我们