MySQL 每秒事务数 vs. 每秒 fsyncs 数 (2020)
想知道 MySQL 每秒可以处理多少事务或写入吗? 虽然这取决于许多因素,但从根本上说,这取决于 MySQL 每秒可以提交到磁盘的事务数量。 现代磁盘可以执行大约 ~1000 fsyncs 每秒,但 MySQL 会将多次写入分组到每次 fsync 中。 一个大致的经验法则是每秒 5000-15,000 次写入,具体取决于每次事务的写入次数、索引数量、硬件、写入大小等因素。 阅读本文以更深入地了解这一点!
各位 Napkin 的朋友们,来自四面八方,现在是另一个 Napkin 问题的时间了!
从本 newsletter 开始以来,我一直提出问题供大家尝试回答。 然后在下个月的版本中,您会听到我的答案。 与你们中的一些人交谈后,似乎很多人都将这些文章视为帖子,而不管它们的问题-答案格式如何。
这就是为什么我决定尝试一种更简单的格式:帖子中我一次性提出问题和解决方案。 这一篇会很长,因为它将包括上个月的答案。
希望您喜欢这种格式! 与往常一样,欢迎您提出反馈。
问题 10:MySQL 的最大每秒事务数是否等同于每秒 fsyncs 数?
MySQL 每秒能够处理多少事务(“写入”)?
对于一个像 MySQL 这样的符合 ACID 规范的数据库的写入(SQL insert/update/delete)操作,一个简单的模型可能是这样的(这同样适用于 Postgres 或任何其他关系型/符合 ACID 规范的数据库,但我们将以 MySQL 为例,因为我最了解它):
- 客户端通过现有连接向 MySQL 发送查询:
INSERT INTO products (name, price) VALUES ('Sneaker', 100) - MySQL 将新记录插入到 write-ahead-log (WAL) 中,并调用
fsync(2)来告诉操作系统,告诉文件系统,告诉磁盘_确保_此数据_一定_、绝对可靠地提交到磁盘。 这一步是最复杂的,如下图所示。 - MySQL 将记录插入到后备存储引擎 (InnoDB) 的内存页中,以便后续查询可以看到该记录。 为什么要提交到存储引擎_和_ WAL? 存储引擎针对提供数据查询结果进行了优化,而 WAL 针对以安全的方式写入数据进行了优化 - 我们无法从 WAL 中高效地提供
SELECT! - MySQL 向客户端返回
OK。 - MySQL 最终调用
fsync(2)以确保 InnoDB 将页面提交到磁盘。
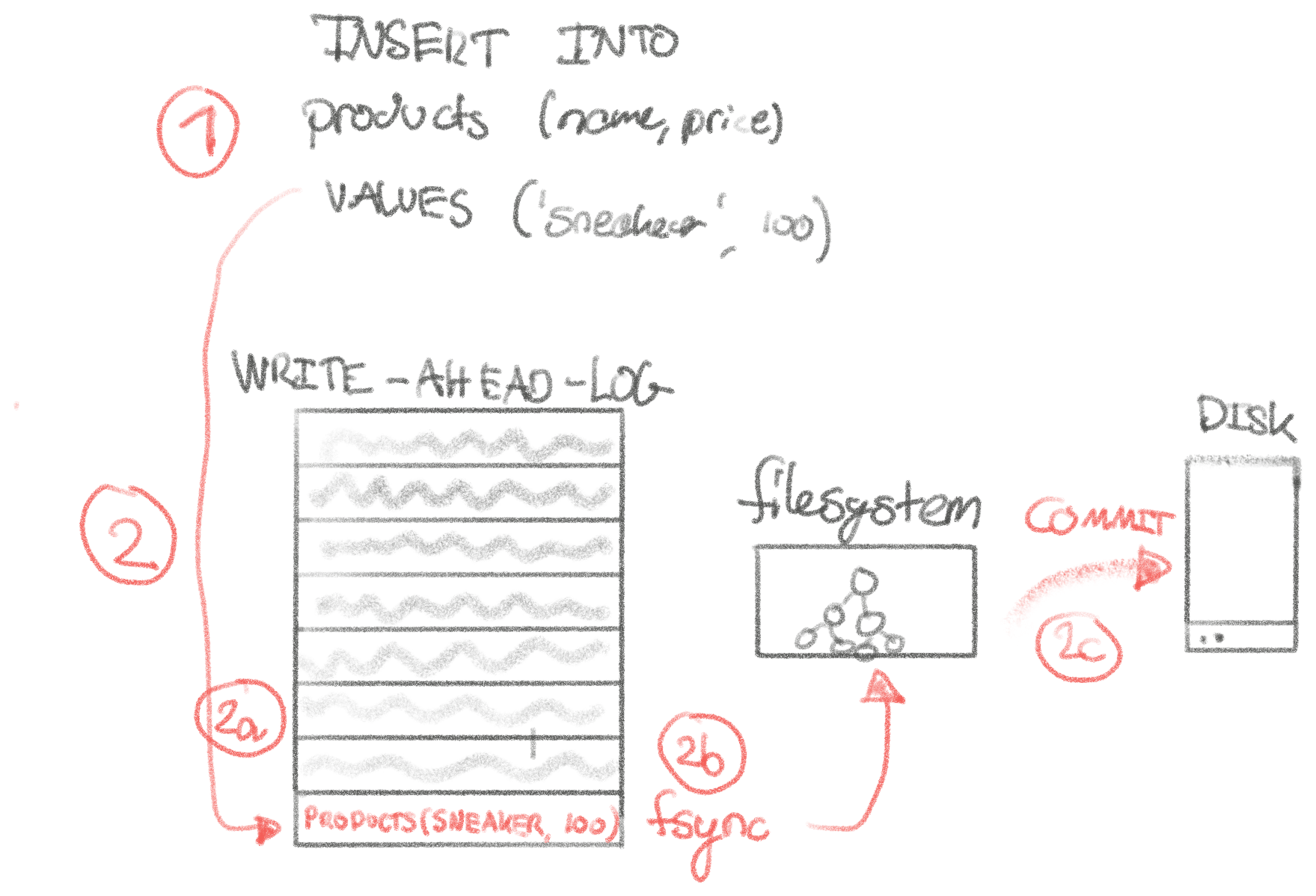
如果在任何这些点发生断电,则可以在没有令人讨厌的意外的情况下定义行为,从而维护我们亲爱的 ACID 兼容性。
太棒了! 现在我们已经构建了一个关系数据库如何安全处理写入的简单模型,我们可以考虑将新记录插入到数据库中的延迟。 当我们查阅 参考 Napkin 数字 时,我们看到步骤 (2) 中的 fsync(2) 是阻塞链中最慢的操作,为 1 毫秒。
例如,步骤 (1) 中的网络处理大约需要 ~10 微秒(TCP Echo Server 是我们可以归类为“TCP 开销”的)。 在 fsync(2) 之前的 write(2) 本身也可以忽略不计,约为 ~10 微秒,因为此系统调用本质上只是写入内核中的内存缓冲区(“页面缓存”)。 这并不能保证实际的位已提交到磁盘,这意味着意外断电会擦除数据,从而使我们的 ACID 兼容性下降。 调用 fsync(2) 可以保证位持久保存在磁盘上,这将在意外的系统关闭中幸免。 缺点是它慢了 100 倍。
有了这些,我们应该能够形成一个关于 MySQL 最大吞吐量的简单假设:
MySQL 的最大理论吞吐量等同于每秒
fsync(2)的最大数量。
我们知道 fsync(2) 需要 1 毫秒,这意味着我们天真地期望 MySQL 能够执行大约:1s / 1ms/fsync = 1000 fsyncs/s = 1000 transactions/s。
很棒。 我们遵循了 Napkin 数学的最初三个步骤:(1) 对系统建模,(2) 确定相关的延迟,(3) 进行 Napkin 数学计算,(4) 根据现实验证 Napkin 计算。
开始第 (4) 步:验证! 我们将用 Rust 编写一个简单的基准测试,该基准测试使用 16 个线程写入 MySQL,每个线程执行 1,000 次插入:
for i in 0..16 {
handles.push(thread::spawn({
let pool = pool.clone();
move || {
let mut conn = pool.get_conn().unwrap();
// TODO: we should ideally be popping these off a queue in case of a stall
// in a thread, but this is likely good enough.
for _ in 0..1000 {
conn.exec_drop(
r"INSERT INTO products (shop_id, title) VALUES (:shop_id, :title)",
params! { "shop_id" => 123, "title" => "aerodynamic chair" },
)
.unwrap();
}
}
}));
for handle in handles {
handle.join().unwrap();
}
// 3 seconds, 16,000 insertions
}
这需要大约 3 秒钟才能执行 16,000 次插入,即每秒大约 5,300 次插入。 这比我们的 Napkin 数学告诉我们的理论最大事务吞吐量 1,000 次 fsync 每秒多 5 倍!
通常,使用 Napkin 数学,我们的目标是在一个数量级内,我们确实如此。 但是,当我进行 Napkin 数学计算时,它通常会建立系统的下限,即从第一原理出发,在理想情况下,该系统的速度_可以_达到多快?
系统很少比 Napkin 数学快 5 倍。 当我们发现实际性能和预期性能之间存在显着差距时,我将其称为“第一原理差距”。 这是好奇心开始的地方。 它通常意味着 (1) 有机会改进系统,或 (2) 我们的系统模型存在缺陷。 在这种情况下,只有 (2) 有意义,因为系统比我们预测的更快。
我们的系统工作方式的模型有什么问题? 为什么每秒 fsyncs 不等于每秒事务数?
首先,我检查了基准测试……有什么问题吗? 没有,SELECT COUNT(*) FROM products 显示 16,000。 我使用的 MySQL 是否配置为不在每次写入时 fsync? 没有,它处于 安全默认值。
然后我坐下来思考。 也许 MySQL _不是_在每个_单个_写入时都执行 fsync? 如果它每秒处理 5,300 次插入,也许它会将多个写入批量处理到一起,作为写入 WAL 的一部分,如上面的步骤 (2) 所示? 由于每个事务都很短,因此 MySQL 可以通过等待几微秒来查看其他事务是否想要参与,然后再调用昂贵的 fsync(2)。
我们可以通过编写一个简单的 bpftrace 脚本来观察 ~16,000 次插入的 fsync(1) 的数量来测试这个假设:
tracepoint:syscalls:sys_enter_fsync,tracepoint:syscalls:sys_enter_fdatasync
/comm == "mysqld"/
{
@fsyncs = count();
}
在插入 16,000 条记录所花费的 ~3 秒钟内运行此脚本,我们得到 ~8,000 个 fsync 调用:
$ sudo bpftrace fsync_count.d
Attaching 2 probes...
^C
@fsyncs: 8037
这是一个特殊的数字。 如果 MySQL 正在批量处理 fsync,我们期望看到的数字要低得多。 这个数字意味着我们平均以 ~0.4 毫秒的延迟执行 ~2,500 个 fsync 每秒。 这比我们预期的 fsync 延迟快两倍,即前面提到的 1 毫秒。 为了确保正确性,我再次运行该脚本以对 MySQL 外部的 fsync 进行基准测试,没有,仍然是 1 毫秒。 查看了分布,它始终约为 ~1 毫秒。
因此,我们可以从中得出两件事:(1) 我们可以比我们预期的更快地 fsync 两倍以上,(2) 我们的假设是正确的,即 MySQL 比每个事务执行一次 fsync 更聪明,但是,由于 fsync 也比预期的快,因此这并不能解释一切。
如果您还记得上面的内容,虽然从理论上讲,提交事务可能只需要一个 fsync,但 MySQL 的其他功能也可能会调用 fsync。 也许它们正在增加噪音?
我们需要按文件描述符对 fsync 进行分组,以更好地了解 MySQL 如何使用 fsync。 但是,原始文件描述符编号并没有告诉我们太多信息。 我们可以使用 readlink 和 proc 文件系统来获取文件描述符指向的文件名。 让我们编写一个 bpftrace 脚本,看看正在 fsync 'ed 什么:
tracepoint:syscalls:sys_enter_fsync,tracepoint:syscalls:sys_enter_fdatasync
/comm == str($1)/
{
@fsyncs[args->fd] = count();
if (@fd_to_filename[args->fd]) {
} else {
@fd_to_filename[args->fd] = 1;
system("echo -n 'fd %d -> ' &1>&2 | readlink /proc/%d/fd/%d",
args->fd, pid, args->fd);
}
}
END {
clear(@fd_to_filename);
}
在将 16,000 个事务插入到 MySQL 中时运行此脚本会得到:
personal@napkin:~$ sudo bpftrace --unsafe fsync_count_by_fd.d mysqld
Attaching 5 probes...
fd 5 -> /var/lib/mysql/ib_logfile0 # redo log, or write-ahead-log
fd 9 -> /var/lib/mysql/ibdata1 # shared mysql tablespace
fd 11 -> /var/lib/mysql/#ib_16384_0.dblwr # innodb doublewrite-buffer
fd 13 -> /var/lib/mysql/undo_001 # undo log, to rollback transactions
fd 15 -> /var/lib/mysql/undo_002 # undo log, to rollback transactions
fd 27 -> /var/lib/mysql/mysql.ibd # tablespace
fd 34 -> /var/lib/mysql/napkin/products.ibd # innodb storage for our products table
fd 99 -> /var/lib/mysql/binlog.000019 # binlog for replication
^C
@fsyncs[9]: 2
@fsyncs[12]: 2
@fsyncs[27]: 12
@fsyncs[34]: 47
@fsyncs[13]: 86
@fsyncs[15]: 93
@fsyncs[11]: 103
@fsyncs[99]: 2962
@fsyncs[5]: 4887
我们可以在这里观察到的是,大多数写入都写入到“redo log”,我们将其称为“write-ahead-log” (WAL)。 有一些 fsync 调用来提交 InnoDB 表空间,但不如 WAL 那么频繁,因为如果我们在它们之间崩溃,我们始终可以从 WAL 中恢复它。 在 fsync 之前,读取工作正常,因为查询可以直接从 InnoDB 的内存中提供服务。
这里唯一令人惊讶的是大量写入 binlog,我们之前没有提到过它。 您可以将 binlog 视为“复制流”。 它是诸如 行 a 从 x 更改为 y、行 b 已删除 和 表 u 添加了列 c 之类的事件流。 主副本将此流式传输到读取副本,后者使用它来更新自己的数据。
当您考虑它时,binlog 和 WAL 需要完全同步。 我们不能在主副本上提交一些东西,但没有提交到副本。 如果它们不同步,这可能会由于读取副本中的漂移而导致数据丢失。 主副本可能会将更改提交到 WAL,断电,恢复,但永远不会将其写入 binlog。
由于 fsync(1) 一次只能同步一个文件描述符,因此您如何才能确保 binlog 和 WAL 包含事务?
一种解决方案是将 binlog 和 WAL 合并为一个日志。 我不太确定为什么不是这种情况,但原因可能是历史性的。 如果您知道,请告诉我!
MySQL 采用的解决方案是使用双因素提交。 这需要三个 fsync 才能提交事务。 此 和 此参考 更详细地解释了这个过程。 因为 WAL 作为双因素提交的一部分被触摸两次,所以它解释了为什么我们看到对它的 fsync 数量大约是上面 bpftrace 输出中 bin-log 的两倍。 在 MySQL 中将多个事务分组为一个双因素提交的过程称为“组提交”。
我们可以从这些数字中收集到的是,由于组提交,似乎 ~16,000 个事务已减少为 ~2885 个提交,或者平均每个提交 ~5.5 个事务。
但还有一件事仍然存在……为什么每个 fsync 的平均延迟比我们的基准测试快两倍? 再次,我们编写一个简单的 bpftrace 脚本:
tracepoint:syscalls:sys_enter_fsync,tracepoint:syscalls:sys_enter_fdatasync
/comm == "mysqld"/
{
@start[tid] = nsecs;
}
tracepoint:syscalls:sys_exit_fsync,tracepoint:syscalls:sys_exit_fdatasync
/comm == "mysqld"/
{
@bytes = lhist((nsecs - @start[tid]) / 1000, 0, 1500, 100);
delete(@start[tid]);
}
它向我们抛出了这个直方图,确认我们看到了一些_非常_快的 fsync:
personal@napkin:~$ sudo bpftrace fsync_latency.d
Attaching 4 probes...
^C
@bytes:
[0, 100) 439 |@@@@@@@@@@@@@@@ |
[100, 200) 8 | |
[200, 300) 2 | |
[300, 400) 242 |@@@@@@@@ |
[400, 500) 1495 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[500, 600) 768 |@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[600, 700) 376 |@@@@@@@@@@@@@ |
[700, 800) 375 |@@@@@@@@@@@@@ |
[800, 900) 379 |@@@@@@@@@@@@@ |
[900, 1000) 322 |@@@@@@@@@@@ |
[1000, 1100) 256 |@@@@@@@@ |
[1100, 1200) 406 |@@@@@@@@@@@@@@ |
[1200, 1300) 690 |@@@@@@@@@@@@@@@@@@@@@@@@ |
[1300, 1400) 803 |@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[1400, 1500) 582 |@@@@@@@@@@@@@@@@@@@@ |
[1500, ...) 1402 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
要准确了解这里发生了什么,我们必须深入研究我们正在使用的文件系统。 这将超出范围(否则我永远不会发送任何东西)。 但是,为了不让您完全悬而未决,大概 ext4 正在使用类似于 MySQL 的组提交的技术来批量处理日记帐中的写入(相当于 MySQL 的 write-ahead-log)。 在 ext4 的词汇表中,这似乎被称为 max_batch_time ,但是关于此的文档充其量是稀疏的。 磁盘也可能在文件系统之外/代替文件系统执行此操作。 如果您对此有更多了解,请启发我!
最重要的是,在实际工作负载中,fsync 的执行速度可能比我在这台机器上通过重复写入和 fsync 文件所获得的 1 毫秒快。 很可能是由于 ext4 等效的组提交,这在我们从未并行执行多个 fsync 的基准测试中看不到。
这使我们回到了解释现实生活与 MySQL 理论最大吞吐量的 Napkin 数学之间的差异。 由于以下原因,我们可以从原始 fsync 调用中获得至少 5 倍的吞吐量增长:
- MySQL 通过“组提交”将多个事务合并为更少的
fsync。 - 文件系统和/或磁盘通过其自身的“组提交”合并并行执行的多个
fsync,从而产生更快的性能。
本质上,批量处理的相同技术用于每一层以提高性能。
虽然我们没有设法解释这里发生的一切,但我肯定从这次调查中学到了很多东西。 根据这一点,调整 组提交设置 以优化 MySQL 的吞吐量而不是延迟可能会很有趣。 这也可以在文件系统级别进行调整。
问题 9:倒排索引
上个月,我们研究了倒排索引。 这种数据结构是全文搜索的基础,并且文档的打包方式非常适合集合交集。
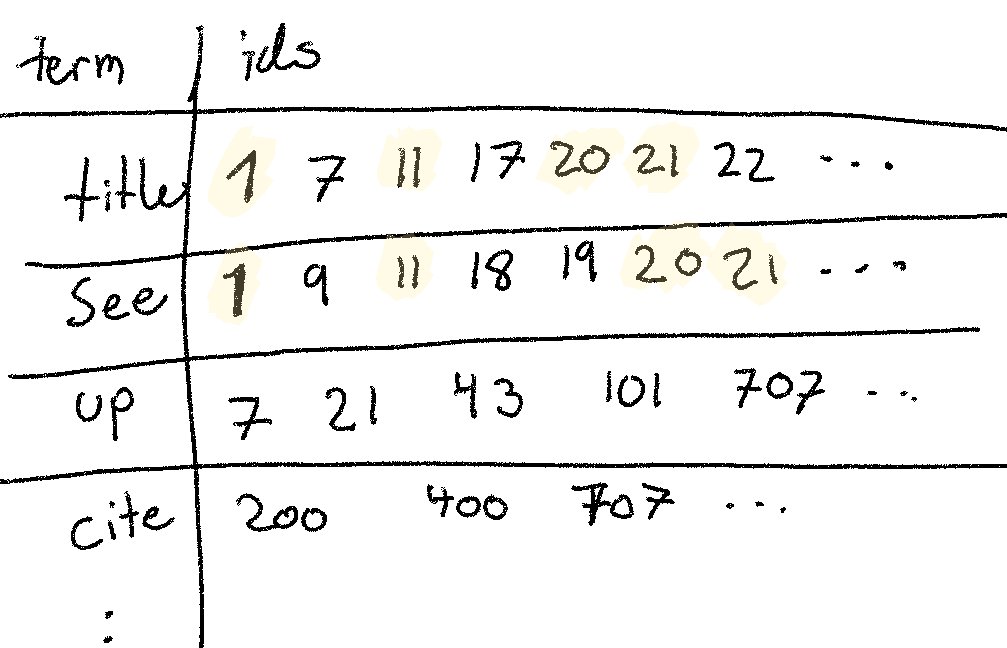
(A) 您估计使用 200 万个 title 的 id 和 100 万个 see 的 id 获取 title AND see 的 id 需要多长时间?
让我们假设每个文档 id 都存储为 64 位整数。 然后我们处理的是 1 * 10^6 * 64bit = 8 Mb 和 2 * 10^6 * 64 bit = 16 Mb。 如果我们使用一个非常简单的集合交集算法,本质上是两个嵌套的 for 循环,我们需要扫描 ~24Mb 的顺序内存。 根据 参考,我们可以在 1Mb/100us * 24Mb = 2.4ms 中完成此操作。
奇怪的是,Lucene 每晚基准测试 以大约 22 QPS 的速度执行这些查询,或者每个查询 1000ms/22 = 45ms。 这比我们的预测差很多。 我准备解释为什么 Lucene 可能_更快_(例如,通过将 postings 压缩到小于 64 位),而不是解释为什么它可能慢 20 倍! 我们又有了一个第一原理差距。
一些缓慢可能是由于从磁盘读取造成的,但是由于访问模式是顺序的,因此它应该只慢 2-3 倍。 硬件可能与参考不同,但很难解释 20 倍的差异。 将数据发送到客户端可能会导致很大的损失,但是同样,20 倍看起来很大。 这种类型的差距指向缺少一些基本的东西(正如我们在 MySQL 中看到的那样)。 不幸的是,这个月我没有时间深入研究,因为我优先考虑了 MySQL 的帖子。
(B) 那么 title OR see 呢?
在这种情况下,我们必须扫描大致相同数量的内存,但是处理更多的文档,并可能将更多的文档传输回客户端。 我们预计性能大约在同一数量级 ~2.4ms。
在这种情况下,Lucene 吞吐量大约减半,这与我们的相对期望相符。 但是同样,就绝对值而言,Lucene 处理这些查询的时间约为 ~100ms,这比我们预期的要高得多。
(C) Lucene 每晚的基准测试对于 (A) 和 (B) 相比如何? 此文件显示了一些实际使用的术语。 如果它们不一致,您将如何解释这种差异?
与 (A) 和 (B) 一起回答。
(D) 让我们想象一下,我们想要 title AND see 并按每个文档的最后修改日期对结果进行排序。 您预计这需要多长时间?
如果 postings 未按该顺序存储,我们天真地期望在最坏的情况下,我们需要对大约 ~24Mb 的内存进行排序,以 5 毫秒/Mb 的速度。 这会将我们置于 5mb/mb * 24mb ~= 120ms 的查询时间范围内。
实际上,这似乎是一个无意的技巧问题。 如果按最后修改日期排序,则它们已经大致按该顺序排序,因为新文档插入到列表的末尾。 这意味着它们已经按_大致_正确的顺序存储,这意味着我们的排序必须移动的位数要少得多。 即使情况并非如此,我们也可以仅为此列存储排序列表,例如 Lucene 允许使用 doc values。
通过电子邮件、RSS 或 Twitter 订阅新文章! 3,637 位订阅者
您可能也喜欢...