PyTorch 内部机制探秘:Ezyang 的博客
ezyang’s blog
软件的弧线朝着理解弯曲。
PyTorch internals
这篇文章是我在2019年5月14日在 PyTorch NYC 聚会上所做的关于 PyTorch 内部机制的演讲的扩展版本。

大家好!今天我想谈谈 PyTorch 的内部机制。

本次演讲是为那些使用过 PyTorch,并且心里想过“如果我能为 PyTorch 做贡献就好了”,但又被 PyTorch 庞大的 C++ 代码库吓到的人准备的。我不会撒谎:PyTorch 的代码库有时确实会让人感到不知所措。本次演讲的目的在于为你提供一张地图:告诉你“支持自动微分的张量库”的基本概念结构,并为你提供一些工具和技巧,以便你在代码库中找到方向。我假设你以前编写过一些 PyTorch 代码,但不一定深入研究过机器学习库是如何编写的。

本次演讲分为两个部分:在第一部分,我将首先向你介绍张量库的概念世界。我将从你所熟知的张量数据类型开始,并更详细地讨论这种数据类型究竟提供了什么,这将使我们更好地理解它在底层是如何实现的。如果你是 PyTorch 的高级用户,你将会熟悉大部分的内容。我们还将讨论“扩展点”的三位一体:layout、device 和 dtype,它们指导我们如何思考对张量类的扩展。在 PyTorch NYC 的现场演讲中,我跳过了关于 autograd 的幻灯片,但我也将在这些笔记中稍微谈一下它们。
第二部分将深入探讨与 PyTorch 实际编码相关的具体细节。我将告诉你如何穿过大量的 autograd 代码,哪些代码是真正重要的,哪些是遗留代码,以及 PyTorch 为你提供的所有用于编写 kernel 的炫酷工具。


张量是 PyTorch 中中心的数据结构。你可能对张量直观地表示什么有一个很好的概念:它是一个包含某种标量类型的 n 维数据结构,例如,float、int 等。我们可以将张量视为由一些数据,以及一些描述张量大小、其中包含的元素类型 (dtype)、张量所在的设备 (CPU 内存?CUDA 内存?) 的元数据组成。
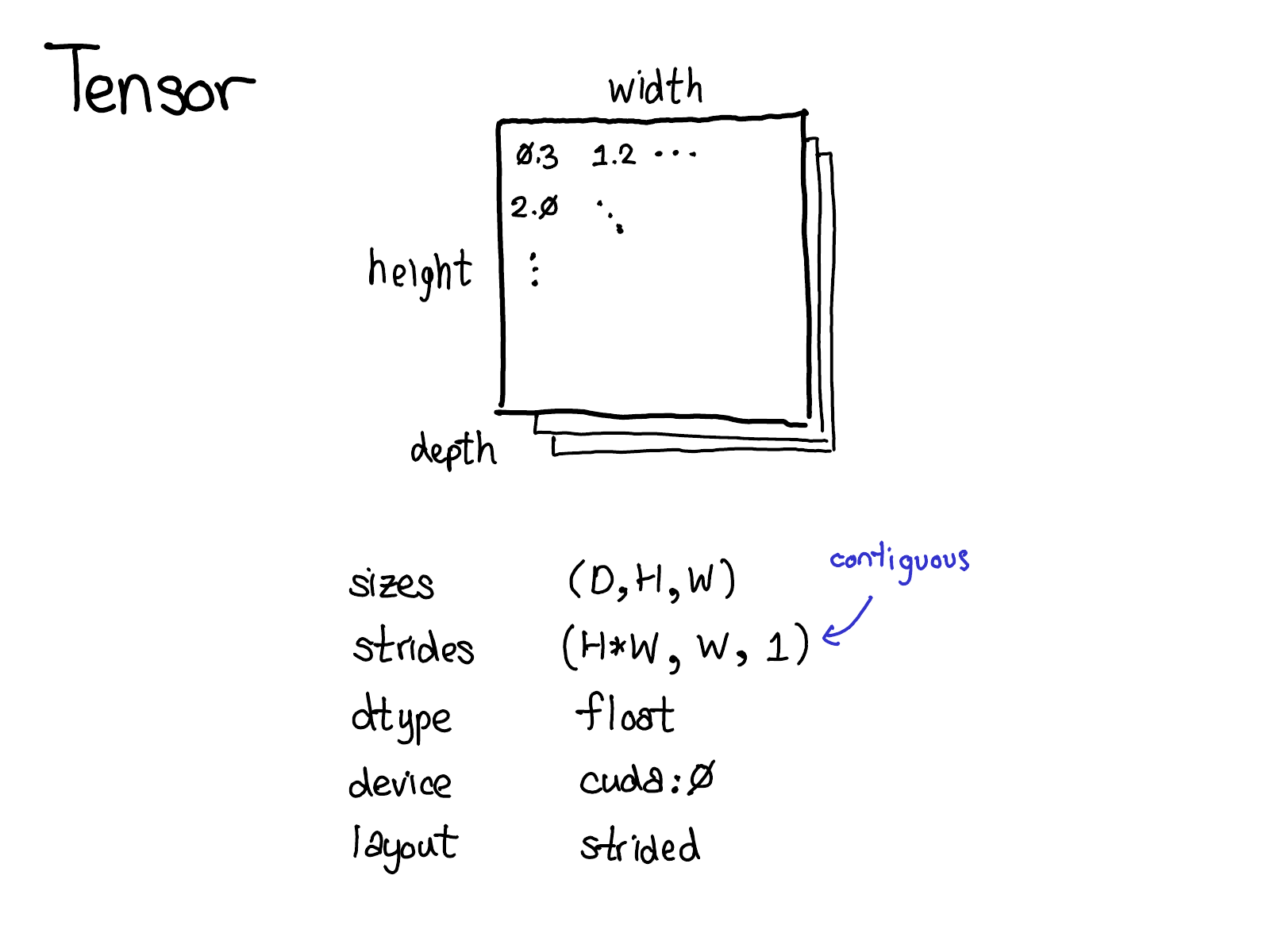
还有一小部分元数据你可能不太熟悉:stride。Stride 实际上是 PyTorch 的一个独特功能,因此值得更深入地讨论它们。
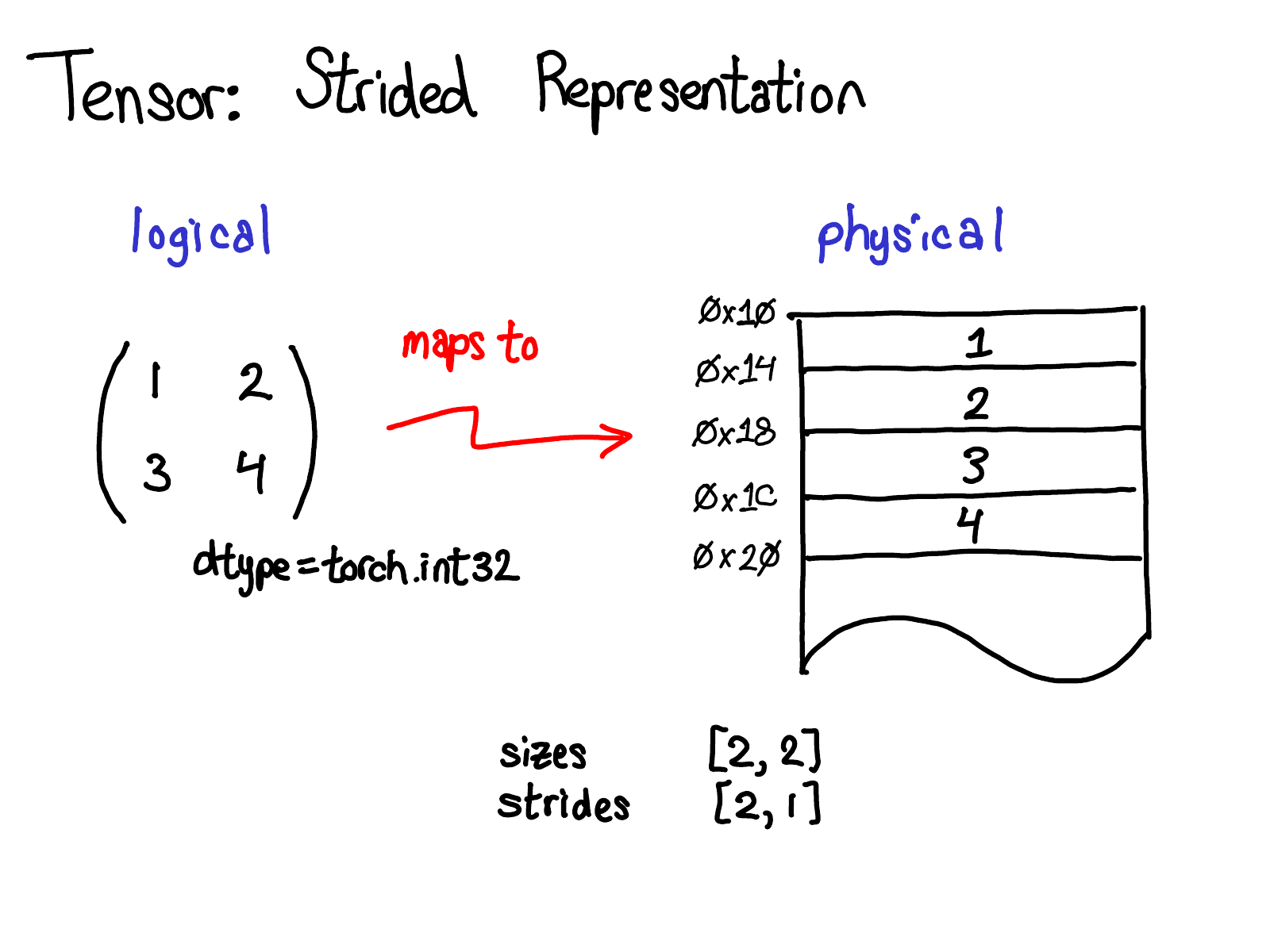
张量是一个数学概念。但是要在我们的计算机上表示它,我们必须为它们定义某种物理表示形式。最常见的表示形式是将张量的每个元素连续地布置在内存中(contiguous 术语由此而来),如你在上面所看到的,将每一行写入内存。在上面的示例中,我指定张量包含 32 位整数,因此你可以看到每个整数都位于一个物理地址中,每个地址彼此偏移四个字节。为了记住张量的实际维度是什么,我们还必须记录大小作为额外的元数据。
那么,stride 与此图有什么关系呢?

假设我想访问逻辑表示中位置 tensor[1, 0] 处的元素。我如何将这个逻辑位置转换为物理内存中的位置?Stride 告诉我如何做到这一点:要找出张量的任何元素所在的位置,我将每个索引乘以该维度对应的 stride,然后将它们全部加在一起。在上图中,我用蓝色对第一个维度进行颜色编码,用红色对第二个维度进行颜色编码,这样你就可以在 stride 计算中跟踪索引和 stride。进行此求和,我得到二(从零开始索引),实际上,数字三位于连续数组的开头下方两个位置。
(在本次演讲的后面部分,我将讨论 TensorAccessor,这是一个处理索引计算的便捷类。当你使用 TensorAccessor 而不是原始指针时,此计算会在底层为你处理。)
Stride 是我们为 PyTorch 用户提供视图的基础。例如,假设我想提取一个表示上面张量的第二行的张量:
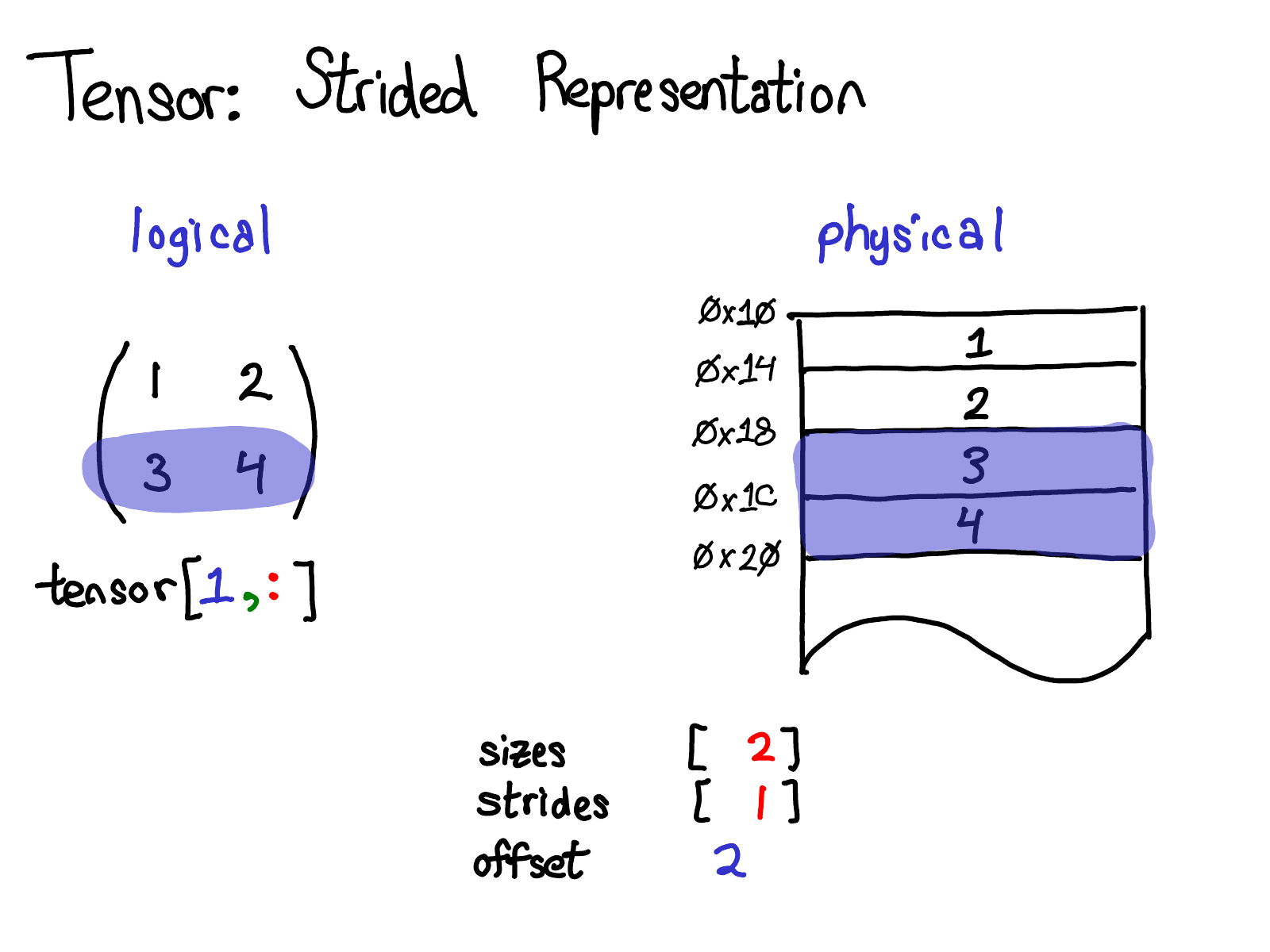
使用高级索引支持,我可以只编写 tensor[1, :] 来获取此行。这是重要的事情:当我这样做时,我不会创建一个新张量;相反,我只是返回一个张量,它是底层数据的不同视图。这意味着,如果我例如编辑该视图中的数据,它将反映在原始张量中。在这种情况下,不难看出如何做到这一点:三和四位于连续内存中,我们需要做的就是记录一个偏移量,说明此(逻辑)张量的数据位于顶部下方两个位置。(每个张量都会记录一个偏移量,但大多数时候它是零,并且在这种情况下我将从我的图中省略它。)
演讲中的问题:如果我对一个张量进行视图操作,我如何释放底层张量的内存?
答案:你必须制作该视图的副本,从而将其与原始物理内存断开连接。你真的不能做太多其他事情。顺便说一句,如果你过去用 Java 编写过代码,那么获取字符串的子字符串也有类似的问题,因为默认情况下不会进行复制,因此子字符串会保留(可能非常大的字符串)。显然,他们 在 Java 7u6 中修复了这个问题。
一个更有趣的例子是,如果我想获取第一列:
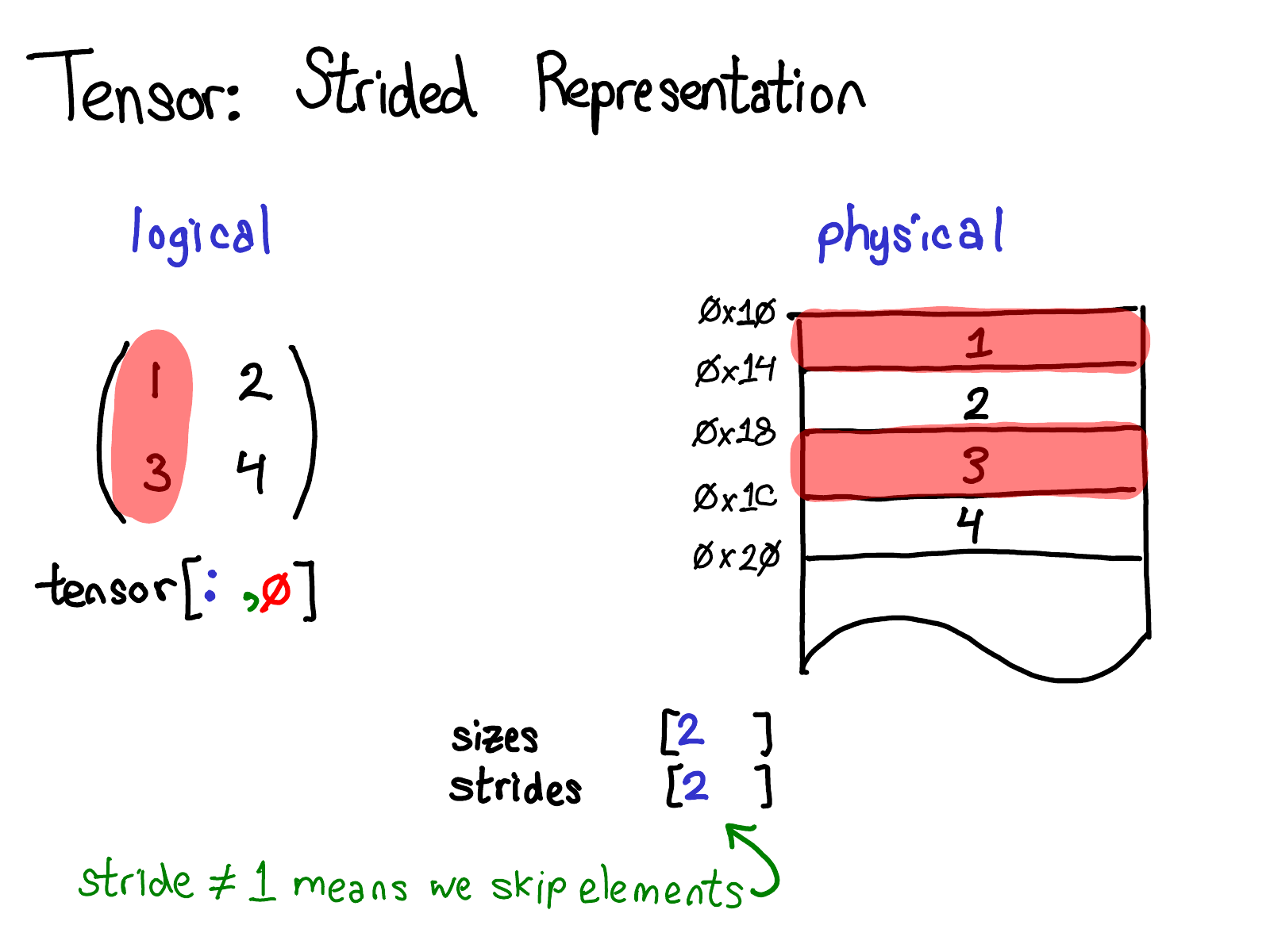
当我们查看物理内存时,我们看到列的元素是不连续的:每个元素之间有一个元素的间隙。在这里,stride 可以提供帮助:我们不是指定 stride 为 1,而是指定 stride 为 2,表示在一个元素和下一个元素之间,你需要跳过两个槽。(顺便说一句,这就是它被称为“stride”的原因:如果我们认为索引是在布局上行走,则 stride 表示每次我们迈出一步时向前走多少个位置。)
Stride 表示实际上可以让你表示张量上各种有趣的视图;如果你想尝试一下可能性,请查看 Stride Visualizer。
让我们退后一步,思考一下我们实际上将如何实现此功能(毕竟,这是一次内部机制演讲)。如果我们可以对张量进行视图操作,这意味着我们必须将张量的概念(你所熟知和喜爱的用户可见的概念)与存储张量数据的实际物理数据(称为 storage)解耦:
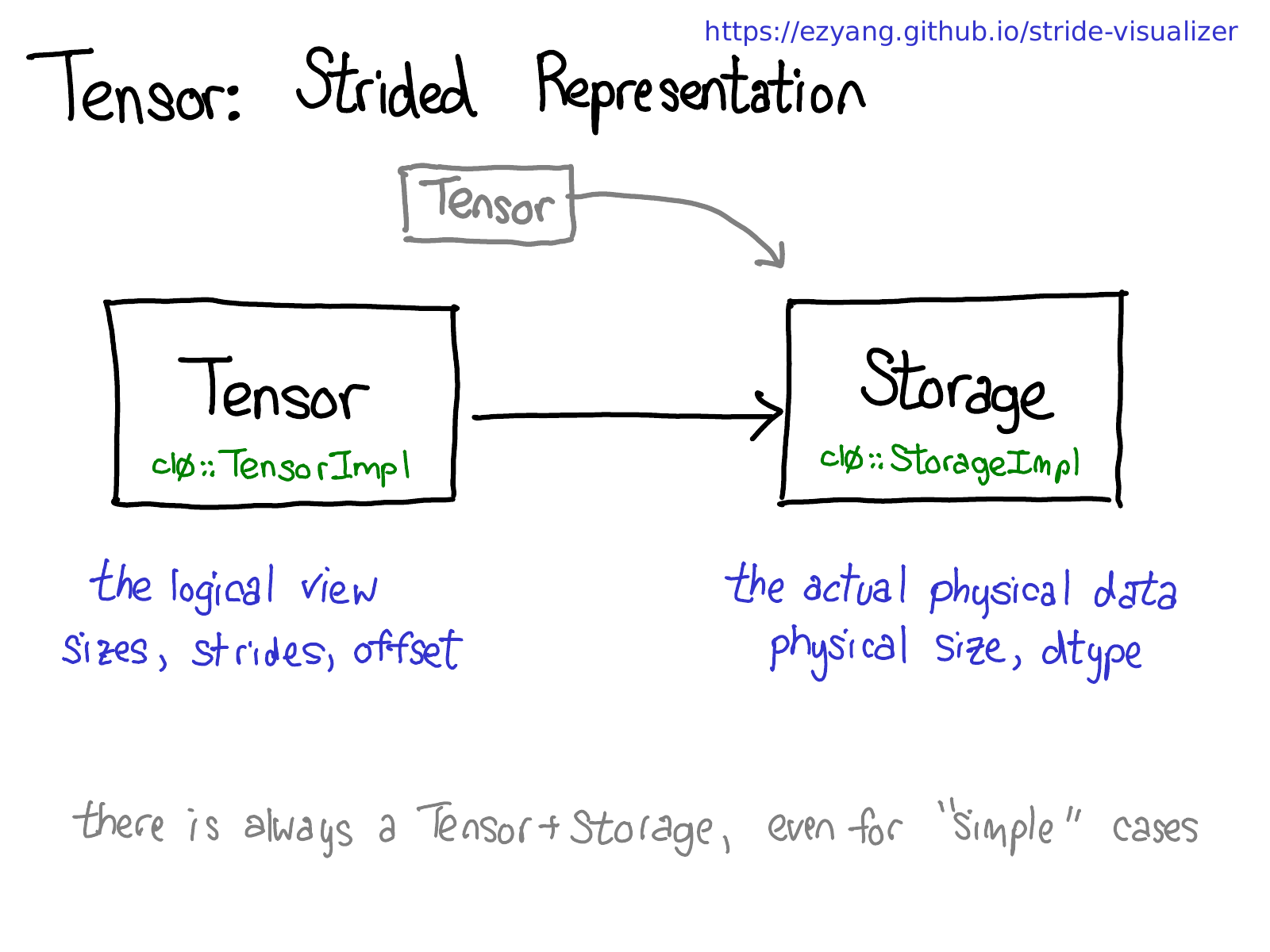
可能有多个张量共享相同的 storage。Storage 定义张量的 dtype 和物理大小,而每个张量记录大小、stride 和偏移量,定义物理内存的逻辑解释。
要意识到的一件事是,始终存在一个 Tensor-Storage 对,即使对于你并不真正需要 storage 的“简单”情况(例如,你只是使用 torch.zeros(2, 2) 分配了一个连续的张量)。
顺便说一句,我们有兴趣使这张图不再正确;与其拥有单独的 storage 概念,不如只将视图定义为由基本张量支持的张量。这有点复杂,但它的好处是,连续张量获得了更直接的表示形式,而无需 Storage 间接寻址。像这样的更改会使 PyTorch 的内部表示形式更像 Numpy 的。
我们已经谈了很多关于张量的数据布局(有些人可能会说,如果你正确地表示数据,其他一切都会到位)。但同样值得简要地谈谈如何实现张量的操作。在最抽象的层面上,当你调用 torch.mm 时,会发生两个 dispatch:
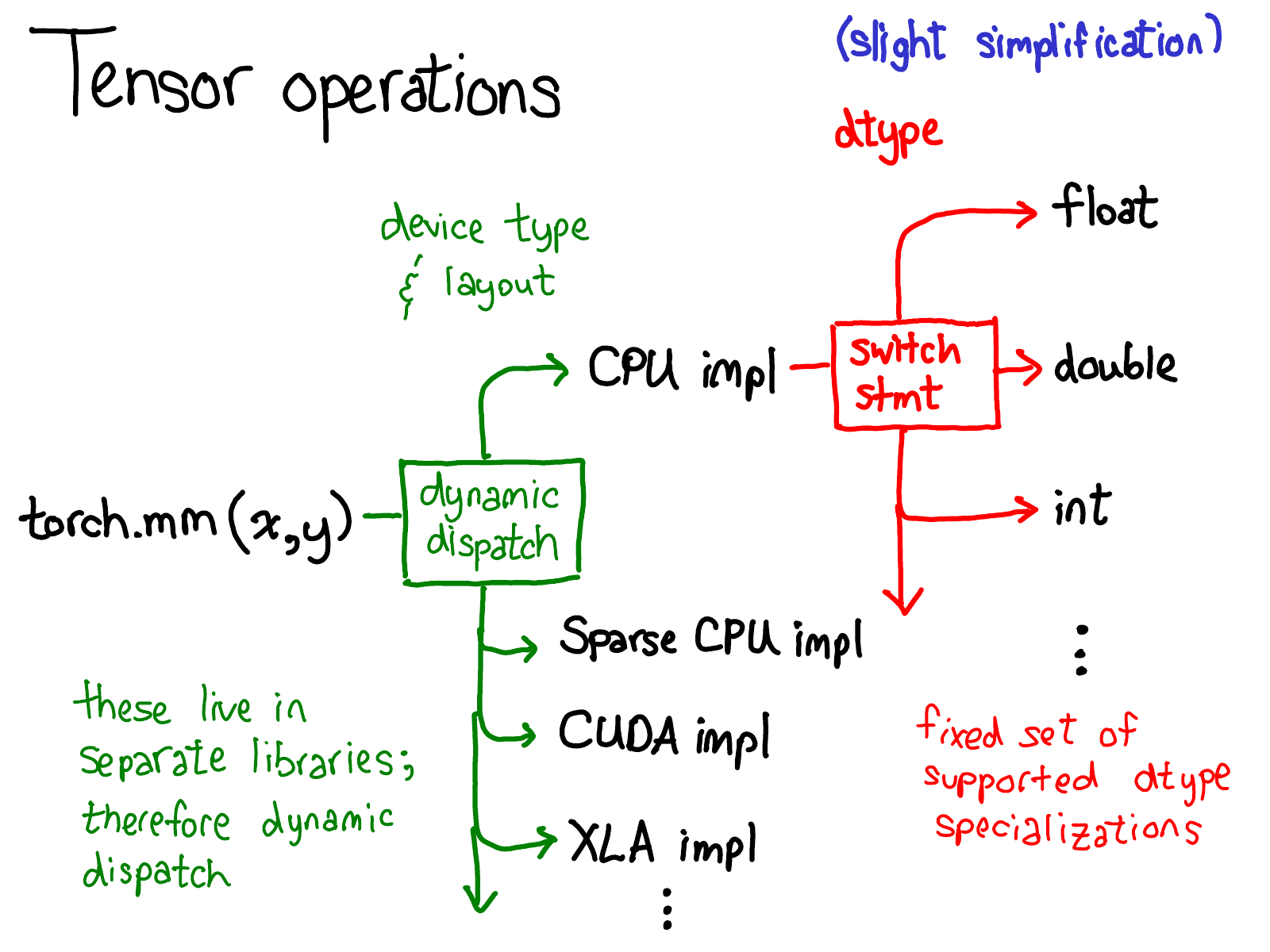
第一个 dispatch 基于张量的设备类型和布局:例如,它是 CPU 张量还是 CUDA 张量(以及,例如,它是 stride 张量还是稀疏张量)。这是一个动态 dispatch:它是一个虚函数调用(虚函数调用发生的确切位置将是本次演讲的后半部分的主题)。你需要在这里进行 dispatch 应该是有意义的:CPU 矩阵乘法的实现与 CUDA 实现完全不同。它是一个_动态_ dispatch,因为这些 kernel 可能位于单独的库中(例如,libcaffe2.so 与 libcaffe2_gpu.so),因此你别无选择:如果你想进入你没有直接依赖的库,你必须动态 dispatch 到那里。
第二个 dispatch 是关于所讨论的 dtype 的 dispatch。此 dispatch 只是 kernel 选择支持的任何 dtype 的简单 switch 语句。经过反思,我们还需要在这里进行 dispatch 应该也是有意义的:在 float 上实现乘法的 CPU 代码(或 CUDA 代码,也可能是)与 int 的代码不同。有理由需要为每个 dtype 提供单独的 kernel。
如果你试图理解 PyTorch 中的运算符是如何调用的,这可能是你脑海中最重要的心理图景。当我们要更多地查看代码时,我们将回到这张图。

由于我们一直在谈论 Tensor,所以我也想花一点时间介绍一下张量扩展的世界。毕竟,生活不仅仅是密集的 CPU float 张量。这里正在发生各种有趣的扩展,例如 XLA 张量、量化张量或 MKL-DNN 张量,作为张量库,我们需要考虑的一件事是如何适应这些扩展。
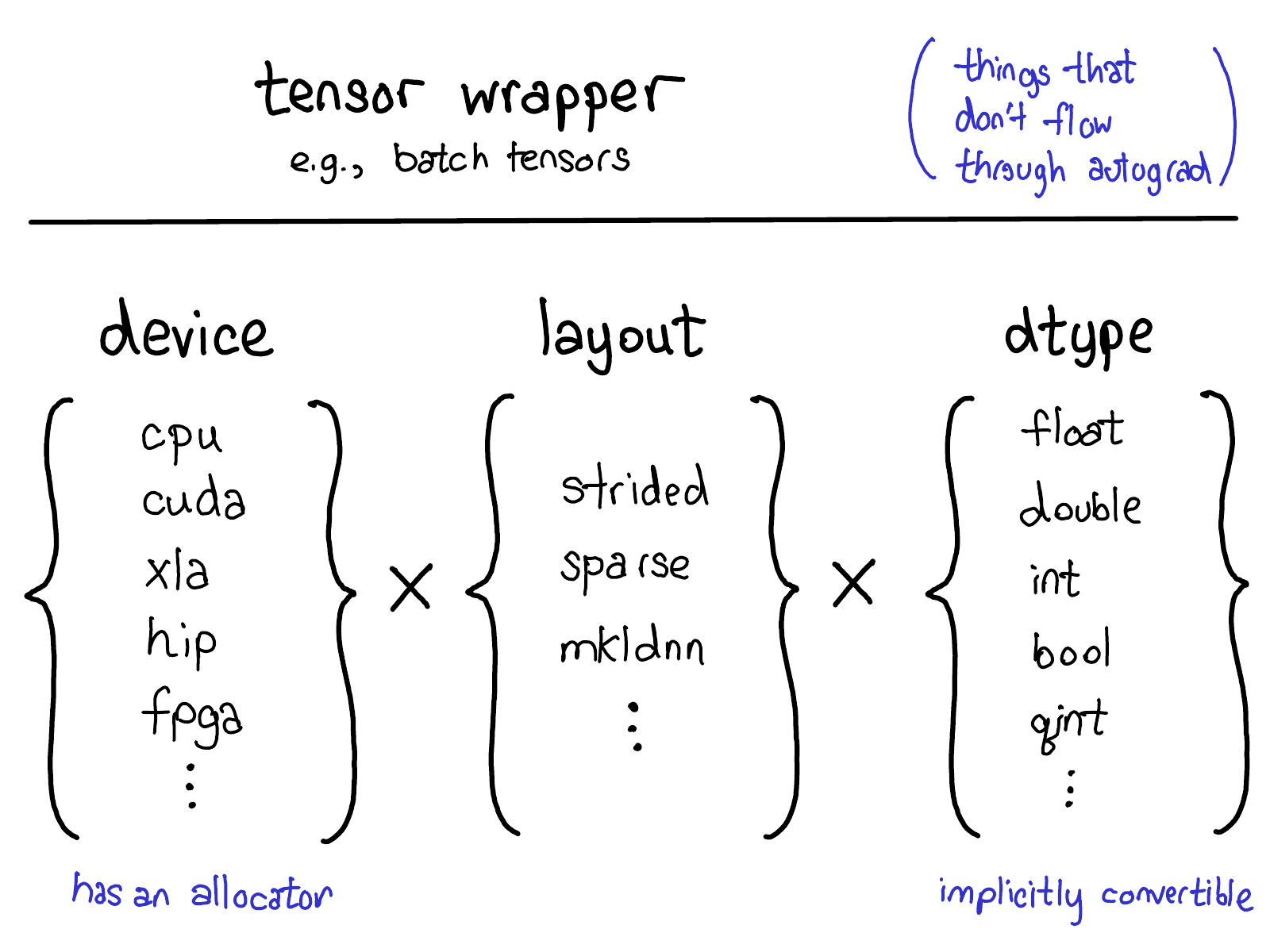
我们当前的扩展模型在张量上提供了四个扩展点。首先,有三个参数唯一地确定了张量是什么:
- device,对张量的物理内存实际存储位置的描述,例如,在 CPU 上,在 NVIDIA GPU (cuda) 上,或者可能在 AMD GPU (hip) 或 TPU (xla) 上。device 的区别特征是它有自己的分配器,不能与其他任何 device 一起使用。
- layout,描述了我们如何逻辑地解释此物理内存。最常见的 layout 是 stride 张量,但稀疏张量具有不同的 layout,涉及一对张量,一个用于索引,一个用于数据;MKL-DNN 张量可能具有更奇特的 layout,例如块布局,不能仅仅使用 stride 表示。
- dtype,描述了实际存储在张量的每个元素中的内容。它可以是 float 或整数,也可以是例如量化整数。
如果你想向 PyTorch 张量添加扩展(顺便说一句,如果这就是你想要做的,请与我们联系!目前,这些事情都无法在树外完成),你应该考虑你要扩展这些参数中的哪一个。这些参数的笛卡尔积定义了你可以制作的所有可能的张量。现在,并非所有这些组合都可能实际具有 kernel(谁在 FPGA 上获得了稀疏、量化张量的 kernel?),但在_原则上_,该组合可能有意义,因此我们至少支持表达它。
最后,你可以通过编写一个围绕 PyTorch 张量的包装类来实现“扩展”张量功能,该类实现了你的对象类型。这听起来可能很明显,但有时人们会想扩展三个参数之一,而他们应该只创建一个包装类。包装类的一个显着优点是它们可以完全在树外开发。
你应该何时编写张量包装器,而不是扩展 PyTorch 本身?关键测试是,你是否需要在 autograd 反向传播期间传递此张量。例如,此测试告诉我们,稀疏张量应该是一个真正的张量扩展,而不仅仅是一个包含索引和值张量的 Python 对象:在对涉及嵌入的网络进行优化时,我们希望由嵌入生成的梯度是稀疏的。
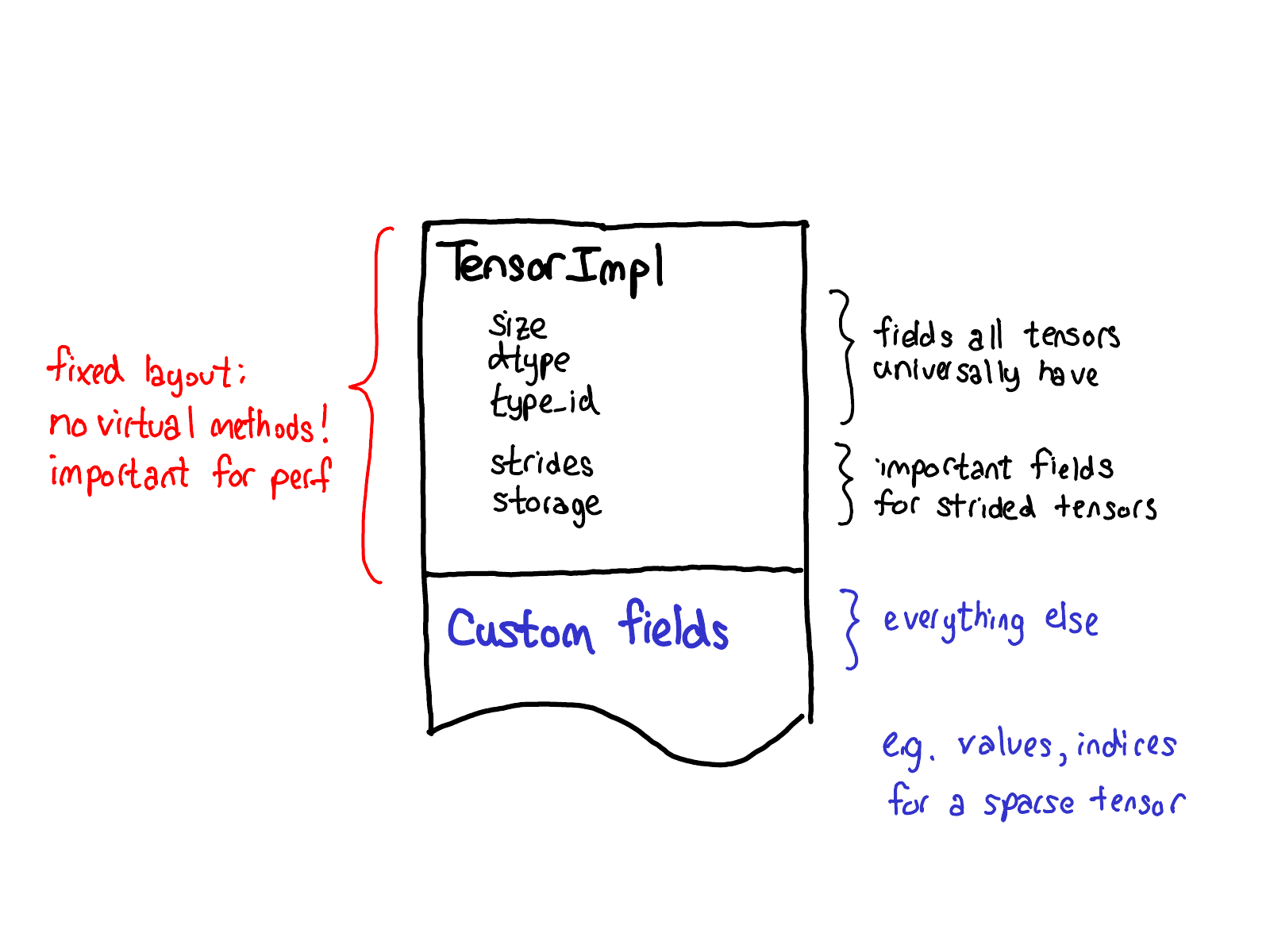
我们关于扩展的理念也对张量自身的数据布局产生影响。我们真正希望从我们的张量结构中得到的一件事是,它具有固定的布局:我们不希望像“张量的大小是多少?”这样的基本(并且经常被调用)操作需要虚拟 dispatch。因此,当你查看 Tensor 的实际布局时(在 TensorImpl 结构 中定义),我们看到的是所有我们认为所有“类似张量”的事物普遍具有的通用前缀字段,加上一些仅真正适用于 stride 张量的字段,但它们_非常_重要,以至于我们将其保留在主结构中,然后是一个可以在每个 Tensor 基础上完成的自定义字段后缀。例如,稀疏张量将它们的索引和值存储在此后缀中。

我已经告诉过你所有关于张量的信息,但如果这是 PyTorch 提供的唯一功能,那么我们基本上只是一个 Numpy 克隆。PyTorch 最初发布时与众不同的特征是它提供了张量的自动微分(现在,我们还有其他很酷的功能,例如 TorchScript;但那时,就是这样!)
自动微分有什么作用?它是负责获取神经网络的机制:
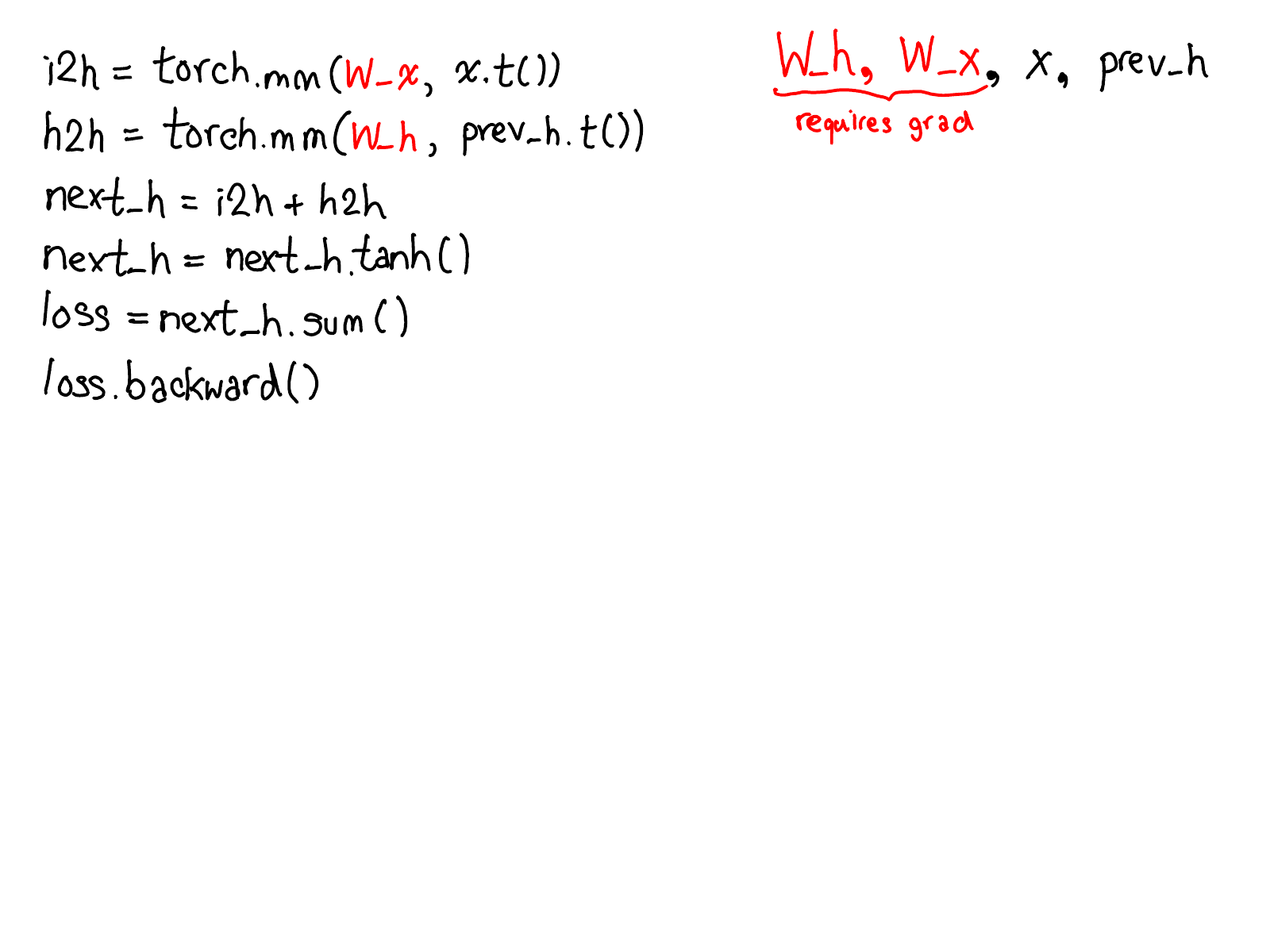
...并填充实际计算网络梯度的缺失代码:

花点时间研究一下这张图。有很多东西需要解释;以下是要看的内容:
- 首先,将你的目光放在红色和蓝色的变量上。PyTorch 实现了 反向模式自动微分,这意味着我们有效地“向后”遍历前向计算以计算梯度。如果你查看变量名,你可以看到这一点:在红色的底部,我们计算
loss;然后,我们在程序的蓝色部分中所做的第一件事是计算grad_loss。loss是从next_h2计算出来的,所以我们计算grad_next_h2。从技术上讲,我们称之为grad_的这些变量实际上不是梯度;它们实际上是 Jacobian 左乘向量,但在 PyTorch 中,我们只称它们为grad,而且大多数人都知道我们的意思。 - 如果代码的结构保持不变,则行为不会:前向的每一行都将替换为不同的计算,该计算表示前向操作的导数。例如,
tanh操作转换为tanh_backward操作(这两行通过图左侧的灰色线连接)。前向和后向操作的输入和输出被交换:如果前向操作产生next_h2,则后向操作将grad_next_h2作为输入。
autograd 的全部意义在于执行此图描述的计算,但实际上永远不会生成此源代码。PyTorch autograd 不会执行源到源的转换(尽管 PyTorch JIT 知道如何执行符号微分)。
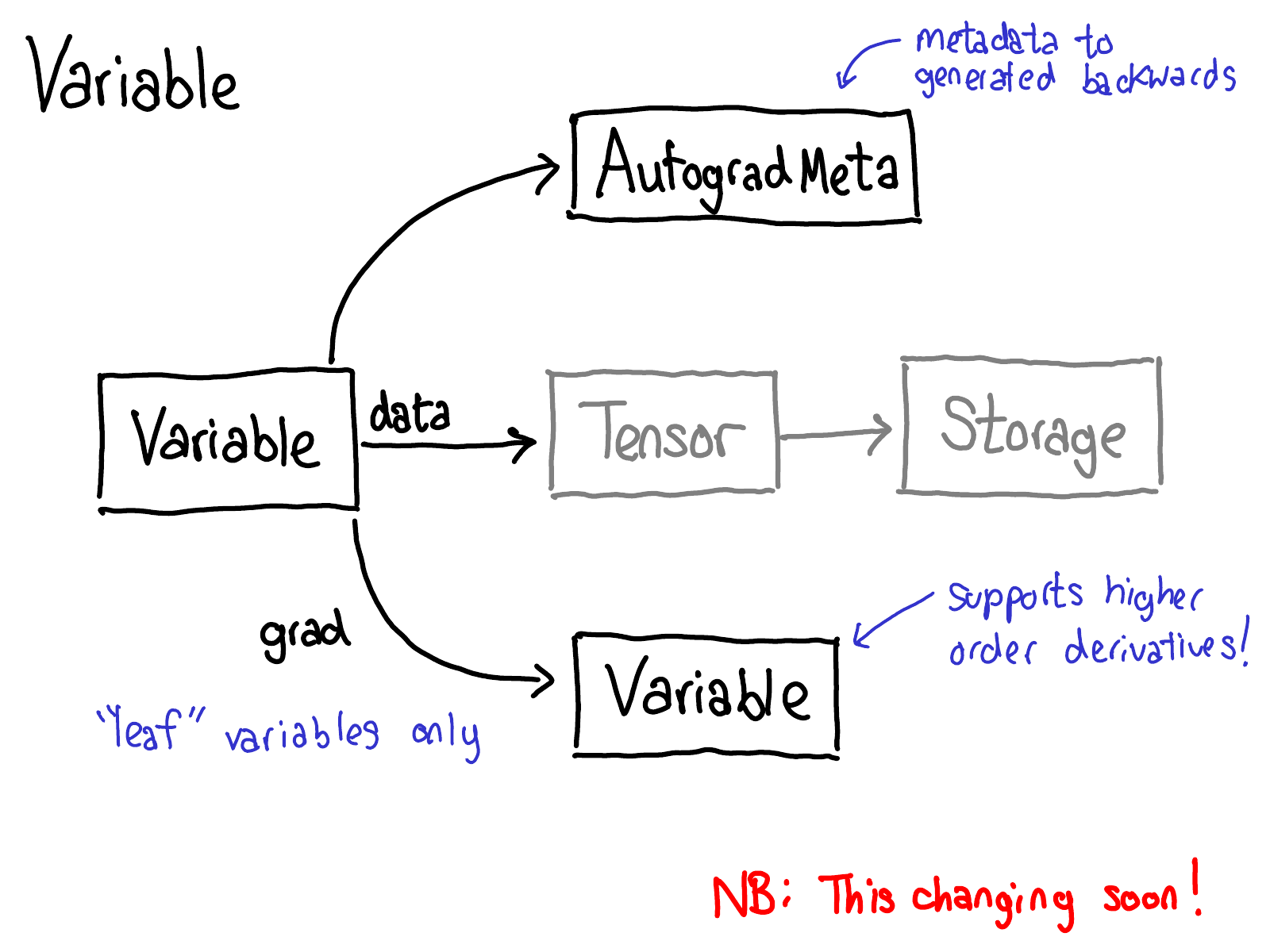
为此,我们需要在对张量执行操作时存储更多元数据。让我们调整一下张量数据结构的图片:现在,我们不再只是一个指向 storage 的张量,而是一个包装此张量的变量,并且还存储执行 autograd 所需的更多信息 (AutogradMeta),当用户在其 PyTorch 脚本中调用 loss.backward() 时。
这是另一张希望在不久的将来过时的幻灯片。Will Feng 正在 C++ 中进行 Variable-Tensor 合并,此前 PyTorch 的前端界面发生了一个简单的合并。
我们还必须更新我们的 dispatch 图片:
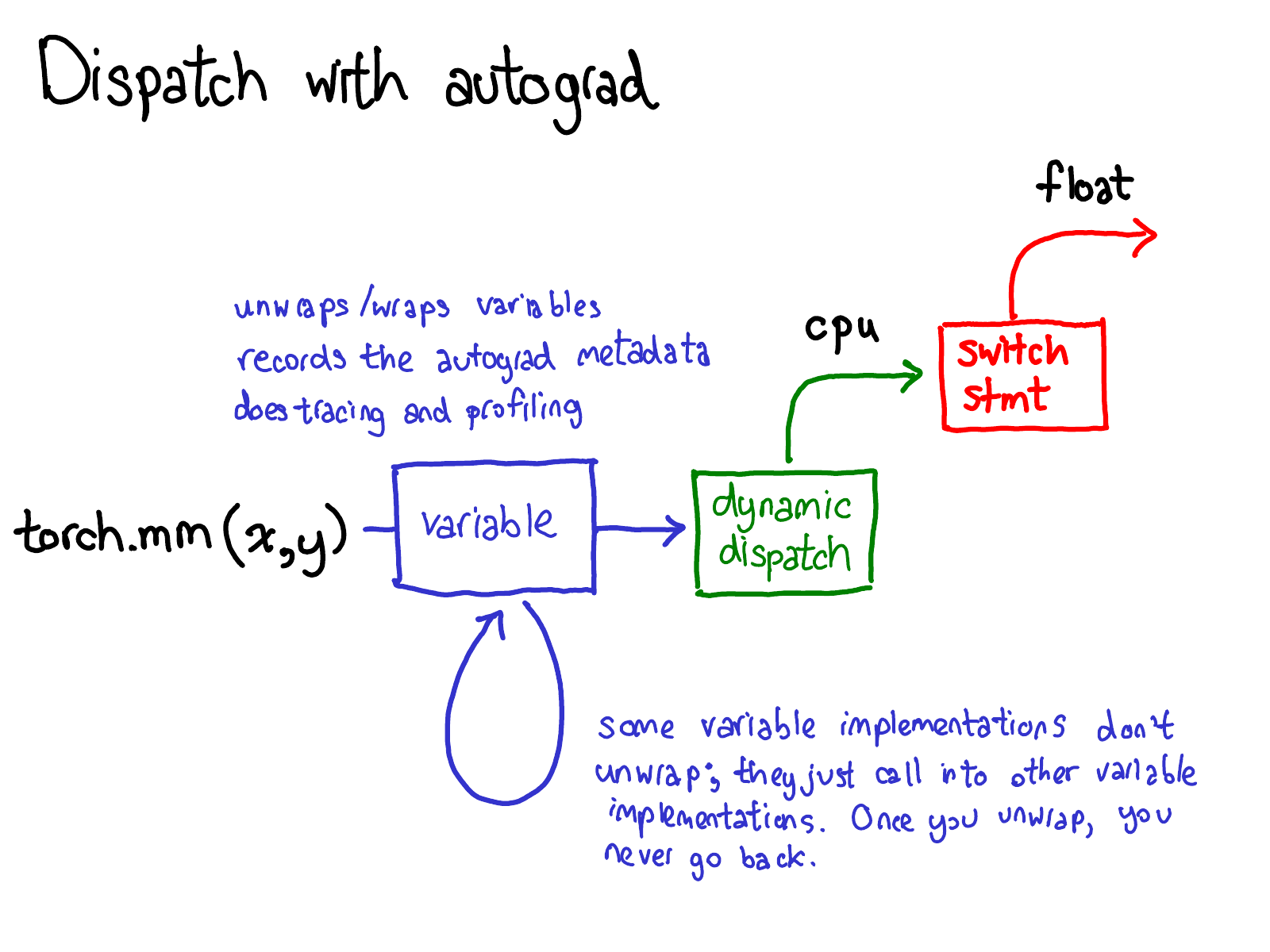
在我们 dispatch 到 CPU 或 CUDA 实现之前,还有另一个关于变量的 dispatch,它负责解包变量,调用底层实现(绿色),然后将结果重新包装到变量中,并记录向后传播所需的 autograd 元数据。
某些实现不会解包;它们只是调用其他变量实现。因此,你可能会在 Variable 世界中花费一段时间。但是,一旦你解包并进入非 Variable Tensor 世界,就结束了;你永远不会回到 Variable(除非从你的函数返回。)
在我的纽约聚会演讲中,我跳过了以下七张幻灯片。我也将推迟它们的编写;你必须等待续集才能获得一些文本。

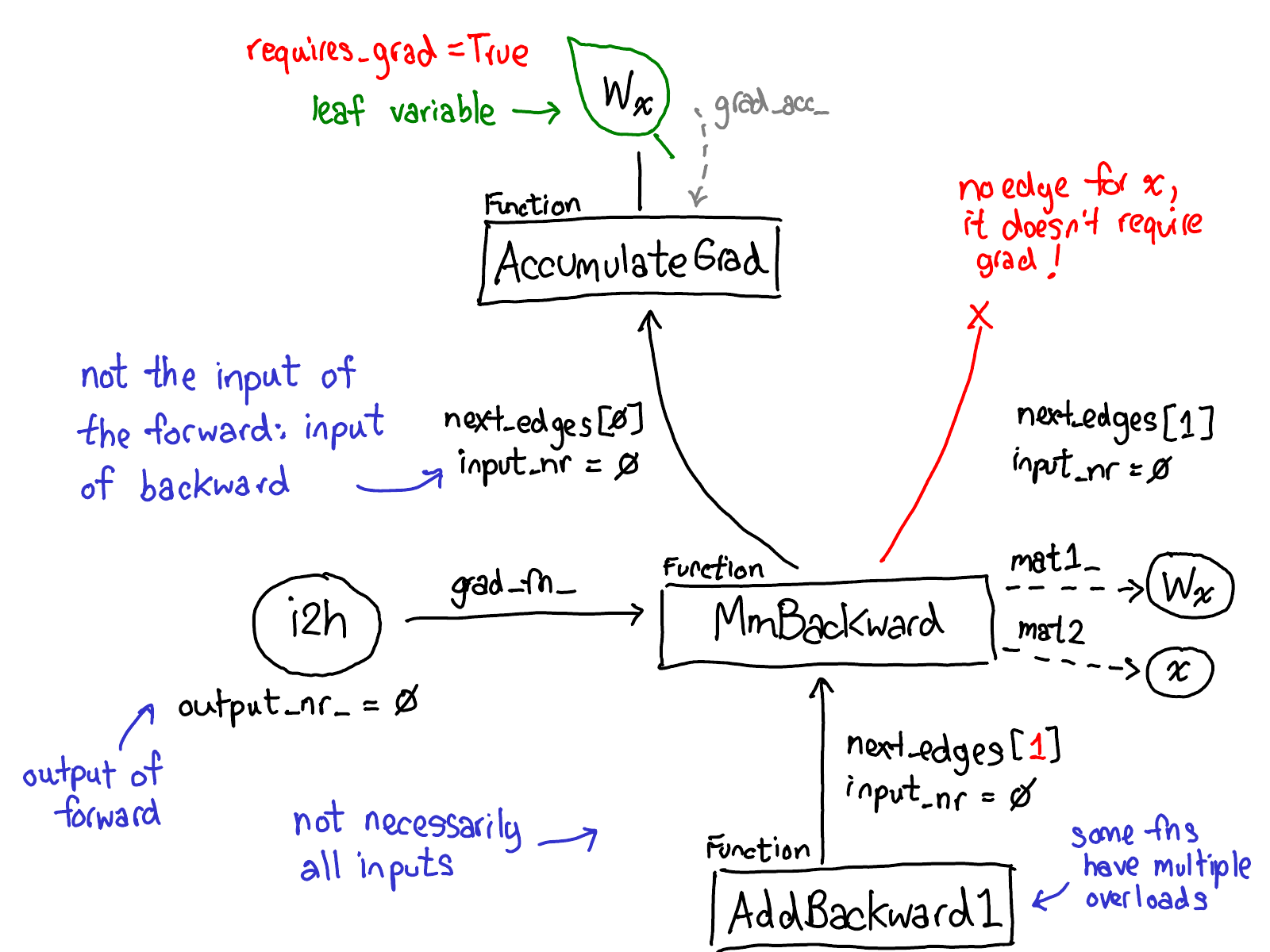
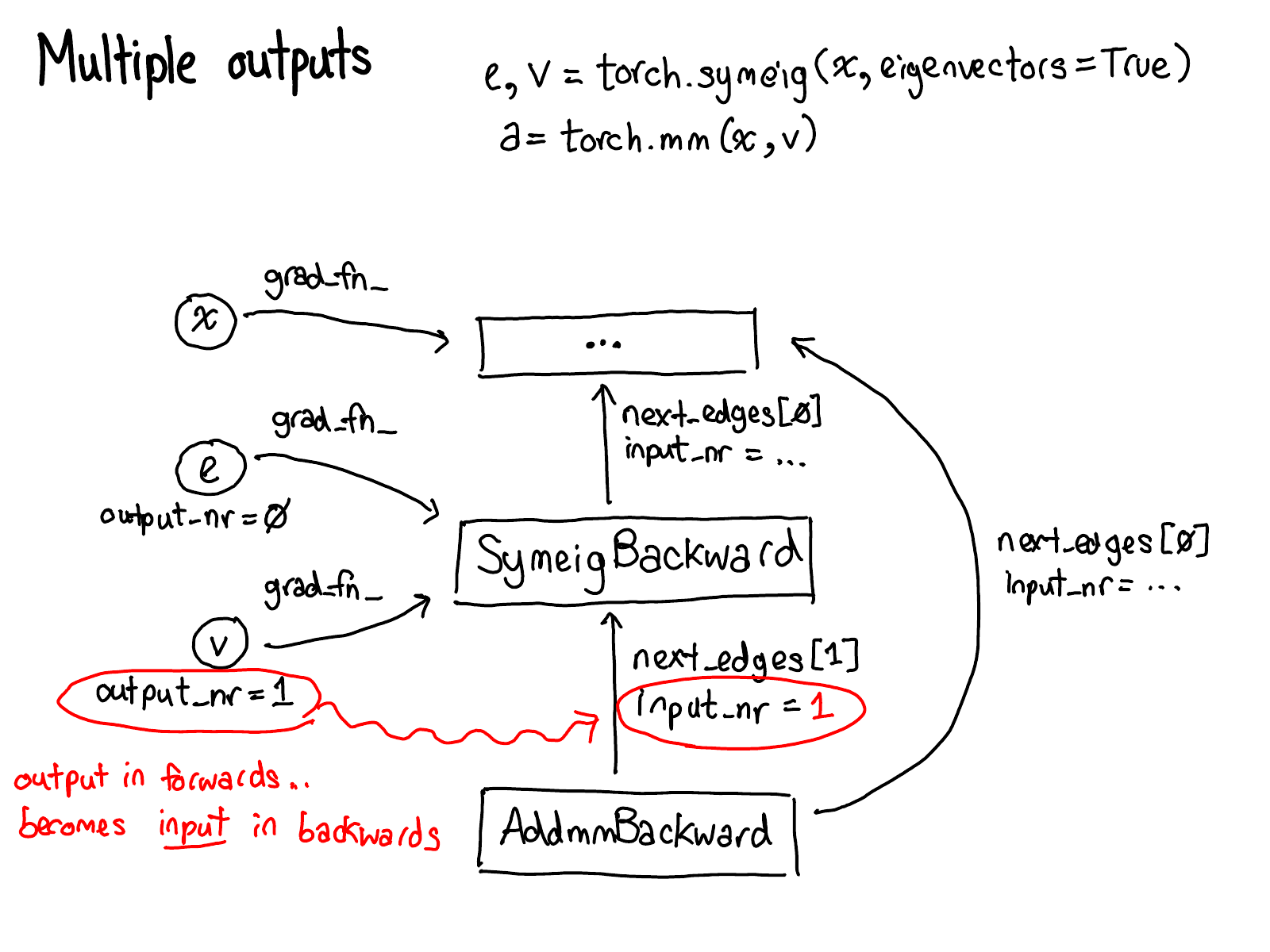
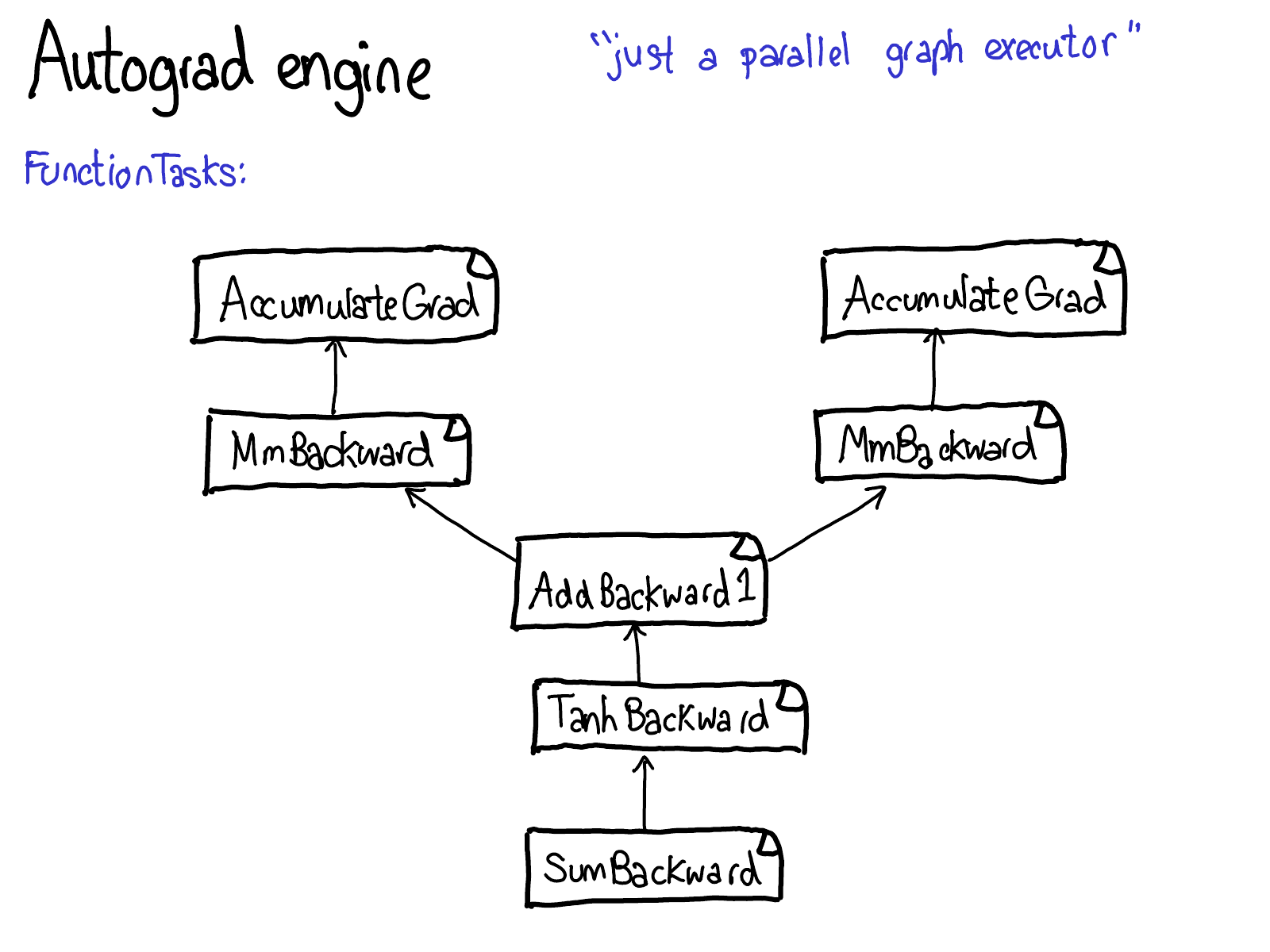
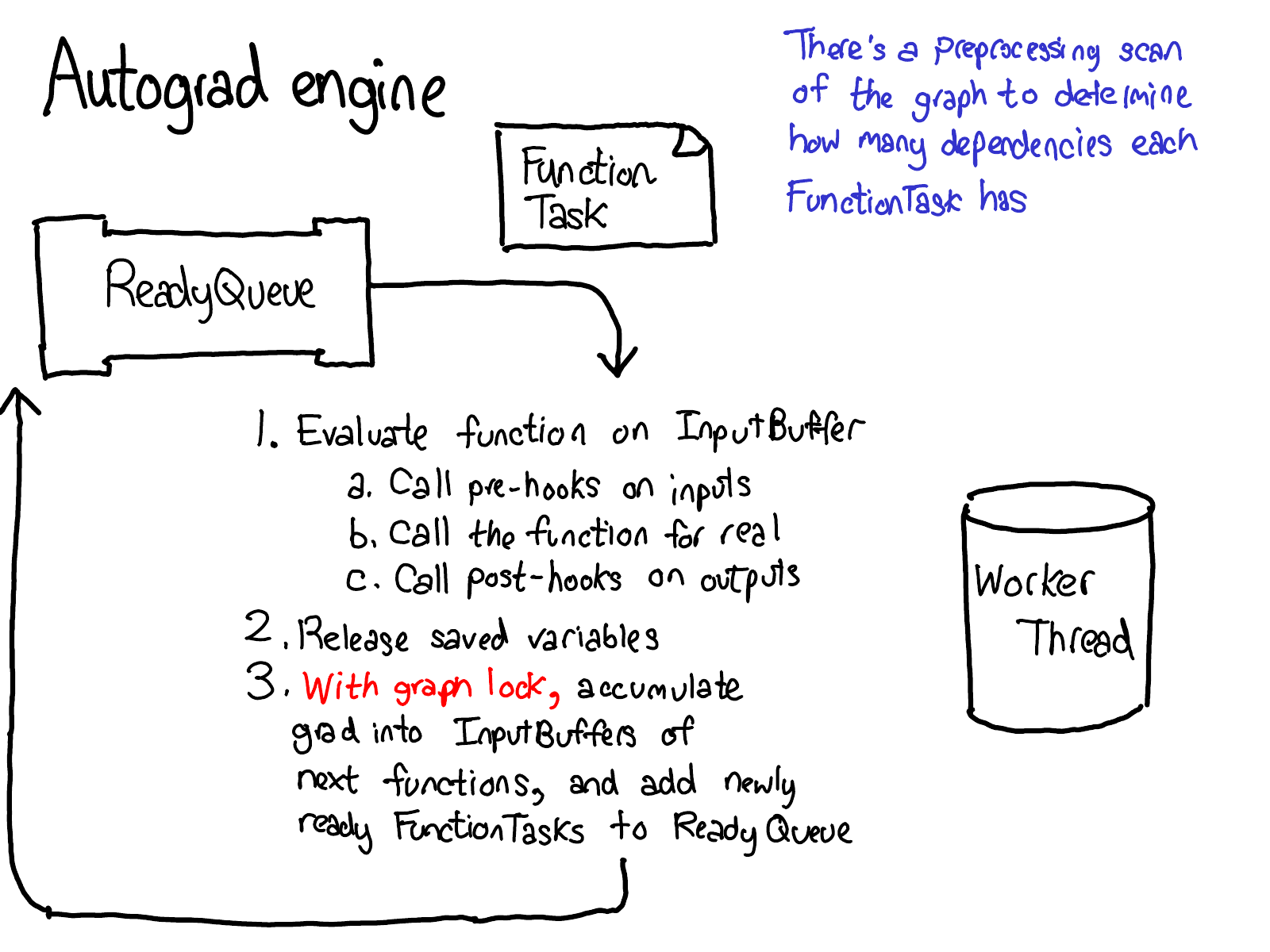
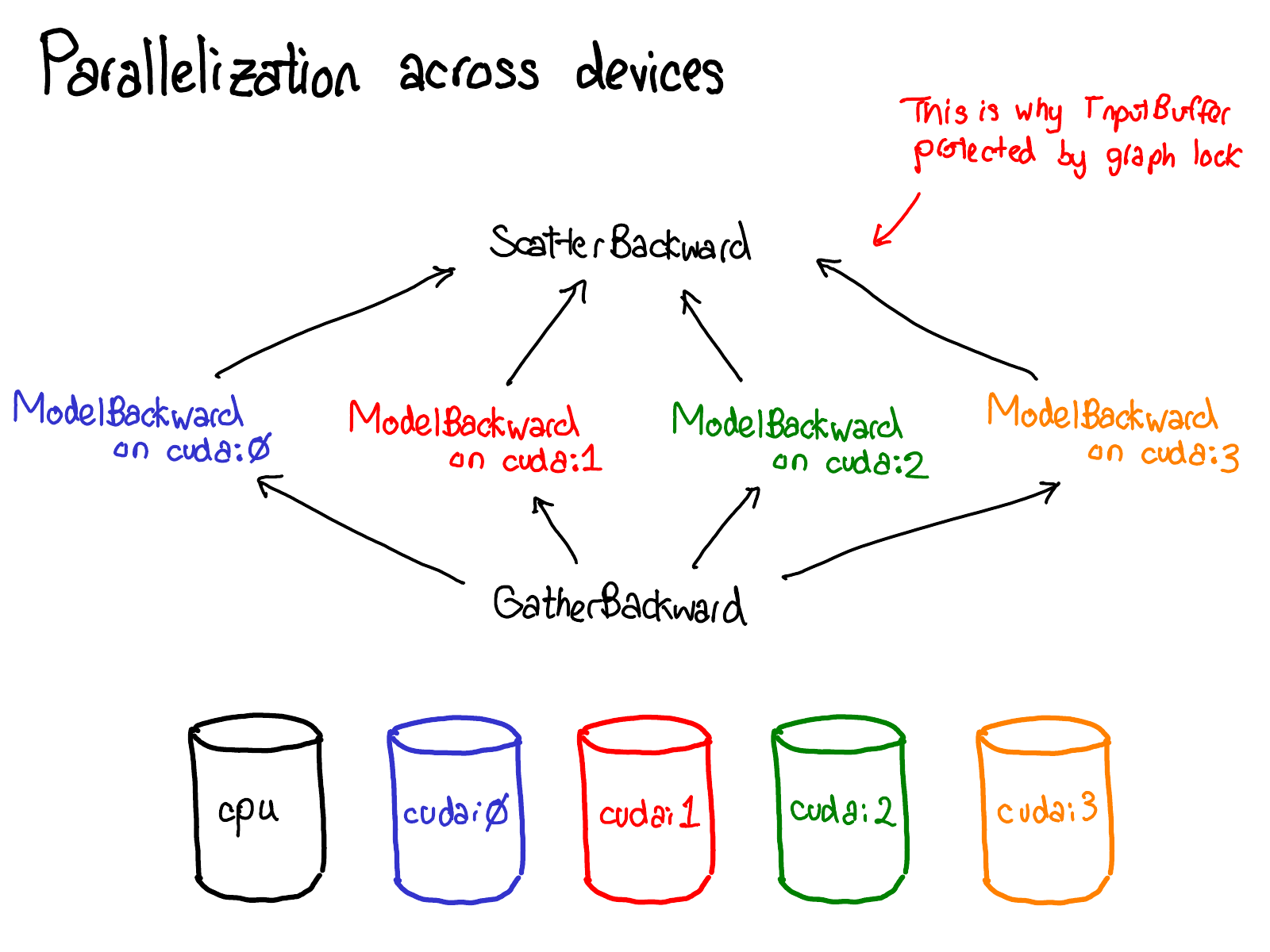

概念就说这么多了,让我们看一些代码。

PyTorch 有很多文件夹,并且在 CONTRIBUTING 文档中对它们进行了非常详细的描述,但实际上,你只需要了解四个目录:
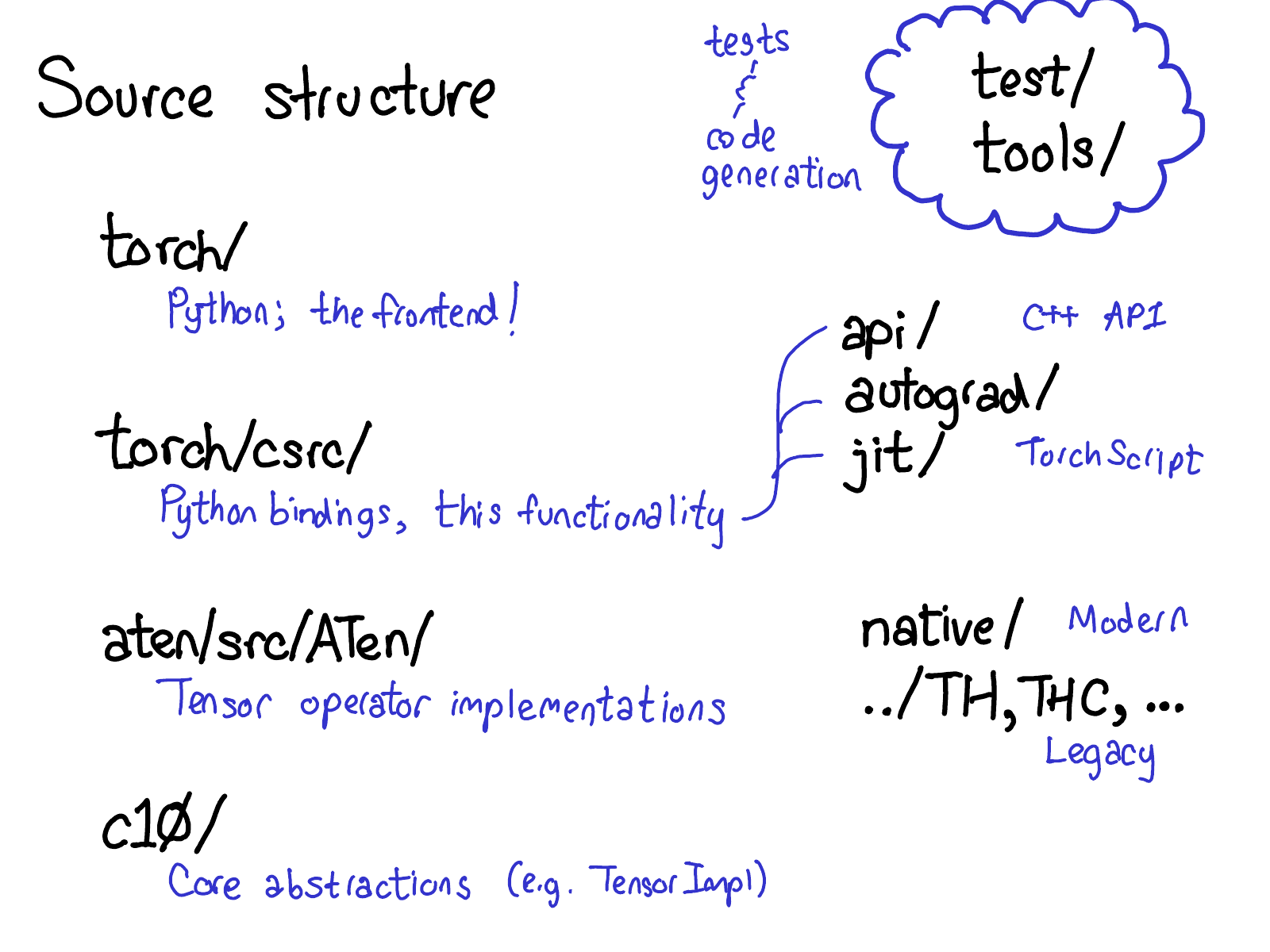
- 首先,
torch/包含你最熟悉的内容:你导入和使用的实际 Python 模块。这些都是 Python 代码,很容易修改(只需进行更改并查看会发生什么)。但是,潜伏在表面之下的是... torch/csrc/,实现 PyTorch 前端的 C++ 代码。更具体地说,它实现了在 Python 和 C++ 世界之间进行转换的绑定代码,以及 PyTorch 的一些非常重要的部分,例如 autograd 引擎和 JIT 编译器。它还包含 C++ 前端代码。aten/,是 "A Tensor Library"(由 Zachary DeVito 创造)的缩写,是一个实现 Tensor 操作的 C++ 库。如果你正在寻找某些 kernel 代码所在的位置,那么它很可能在 ATen 中。ATen 本身分为两个运算符邻域:现代的 C++ 运算符实现的 "native" 运算符,以及遗留的 C 运算符实现的 "legacy" 运算符 (TH, THC, THNN, THCUNN)。遗留运算符是城镇中糟糕的部分;如果可以的话,尽量不要在那里花费太多时间。c10/,是对 Caffe2 和 A"Ten" 的双关语(明白了吗?Caffe 10),包含 PyTorch 的核心抽象,包括 Tensor 和 Storage 数据结构的实际实现。
有很多地方可以查找代码;我们应该简化目录结构,但事实就是这样。如果你正在尝试处理运算符,你将大部分时间花费在 aten 中。
让我们看看这种代码分离在实践中是如何分解的:

当你调用像 torch.add 这样的函数时,实际会发生什么?如果你还记得我们关于 dispatch 的讨论,那么你的脑海中已经有了基本的概念:
- 我们必须从 Python 领域转换为 C++ 领域(Python 参数解析)
- 我们处理 variable dispatch (VariableType--Type,顺便说一句,与编程语言类型没有任何关系,只是一个用于进行 dispatch 的小工具。)
- 我们处理 设备类型/布局 dispatch (Type)
- 我们有实际的 kernel,它可以是现代 native 函数,也可以是遗留的 TH 函数。
这些步骤中的每一个都具体对应于某些代码。让我们穿过丛林。

我们在 C++ 代码中的初始着陆点是 Python 函数的 C 实现,我们将其作为 torch._C.VariableFunctions.add 之类的东西暴露给 Python 端。THPVariable_add 是其中一个实现的实现。
关于此代码,一件重要的事情是它是自动生成的。如果你在 GitHub 存储库中搜索,你将找不到它,因为你实际上必须构建 PyTorch 才能看到它。另一件重要的事情是,你不需要真正深入了解此代码在做什么;我们的想法是略过它并了解它在做什么。在上面,我用蓝色注释了一些最重要的位:你可以看到有一个 PythonArgParser 类,用于实际从 Python args 和 kwargs 中提取 C++ 对象;然后我们调用一个 dispatch_add 函数(我已经用红色内联),它释放全局解释器锁,然后在 C++ Tensor self 上调用一个普通的旧方法。在返回的路上,我们将返回的 Tensor 重新包装到 PyObject 中。
(此时,幻灯片中存在错误:我应该告诉你有关 Variable dispatch 代码的信息。我尚未在此处修复它。发生了一些魔术,然后...)

当我们调用 Tensor 类上的 add 方法时,尚未发生虚拟 dispatch。相反,我们有一个内联方法,该方法在 "Type" 对象上调用一个虚拟方法。此方法是实际的虚拟方法(这就是我说 Type 只是一个“小工具”,让你进行动态 dispatch 的原因)。在此示例的特定情况下,这是因为我们有一个对每个设备类型(CPU 和 CUDA)相同的 add 实现,所以此虚拟调用将 dispatch 到一个名为 TypeDefault 的类上的 add 实现;如果我们恰好有不同的实现,我们可能会降落在 CPUFloatType::add 之类的东西上。正是虚拟方法的这种实现最终使我们获得了实际的 kernel 代码。
希望这张幻灯片很快也会过时;Roy Li 正在使用另一种机制替换
Typedispatch,这将帮助我们更好地在移动设备上支持 PyTorch。
值得再次强调的是,直到我们获得 kernel,所有代码都是自动生成的。
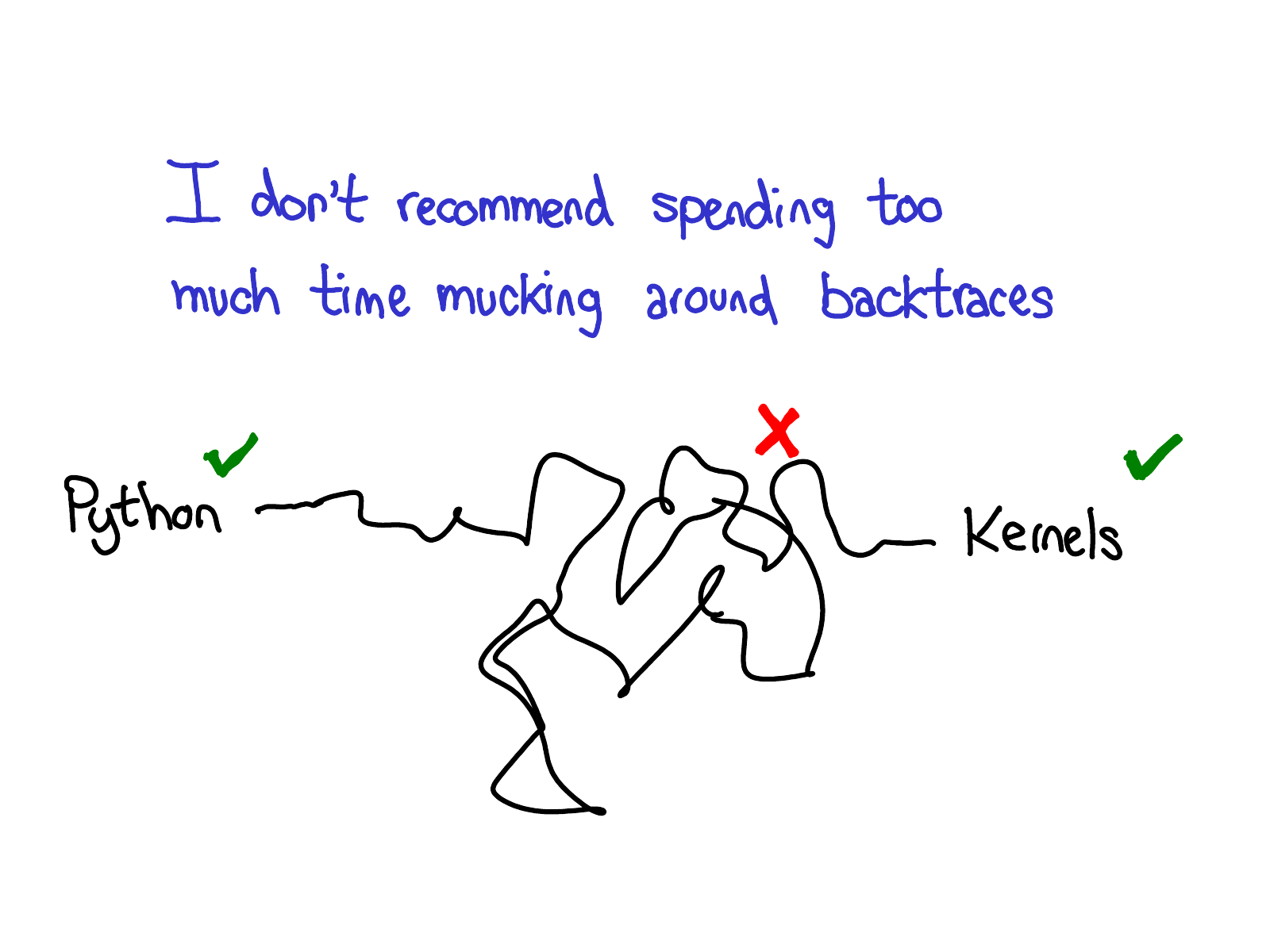
这有点曲折,所以一旦你对正在发生的事情有了一些基本的了解,我建议直接跳转到 kernel。

PyTorch 为未来的 kernel 编写者提供了许多有用的工具。在本节中,我们将介绍其中的一些工具。但首先,你需要什么来编写 kernel?

我们通常认为 PyTorch 中的 kernel 由以下部分组成:
- 首先,我们编写关于 kernel 的一些元数据,这些元数据为代码生成提供支持,并让你获得与 Python 的所有绑定,而无需编写任何代码。
- 一旦你获得了 kernel,你就通过了设备类型/布局 dispatch。你需要编写的第一件事是错误检查,以确保输入张量具有正确的维度。(错误检查非常重要!不要吝啬它!)
- 接下来,我们通常必须分配结果张量,我们将把输出写入其中。
- 到了 kernel 正确的时间。此时,你现在应该执行第二个 dtype dispatch,以跳转到专门针对其运行的每个 dtype 的 kernel。(你不希望过早地执行此操作,因为那样你将无用地复制在任何情况下看起来都相同的代码。)
- 大多数性能 kernel 都需要某种并行化,以便你可以利用多 CPU 系统。(CUDA kernel 是“隐式”并行化的,因为它们的编程模型建立在海量并行化的基础上)。
- 最后,你需要访问数据并执行你想要执行的计算!
在后续幻灯片中,我们将介绍 PyTorch 具有的一些工具,以帮助你实现这些步骤。

要利用 PyTorch 带来的所有代码生成优势,你需要为你的运算符编写一个_模式_。该模式提供了你的函数的 mypy 式类型,并控制我们是否为 Tensor 上的方法或函数生成绑定。你还可以告诉模式,对于给定的 device-layout 组合,应该调用你的运算符的哪些实现。查看 native 中的 README 以获取有关此格式的更多信息。
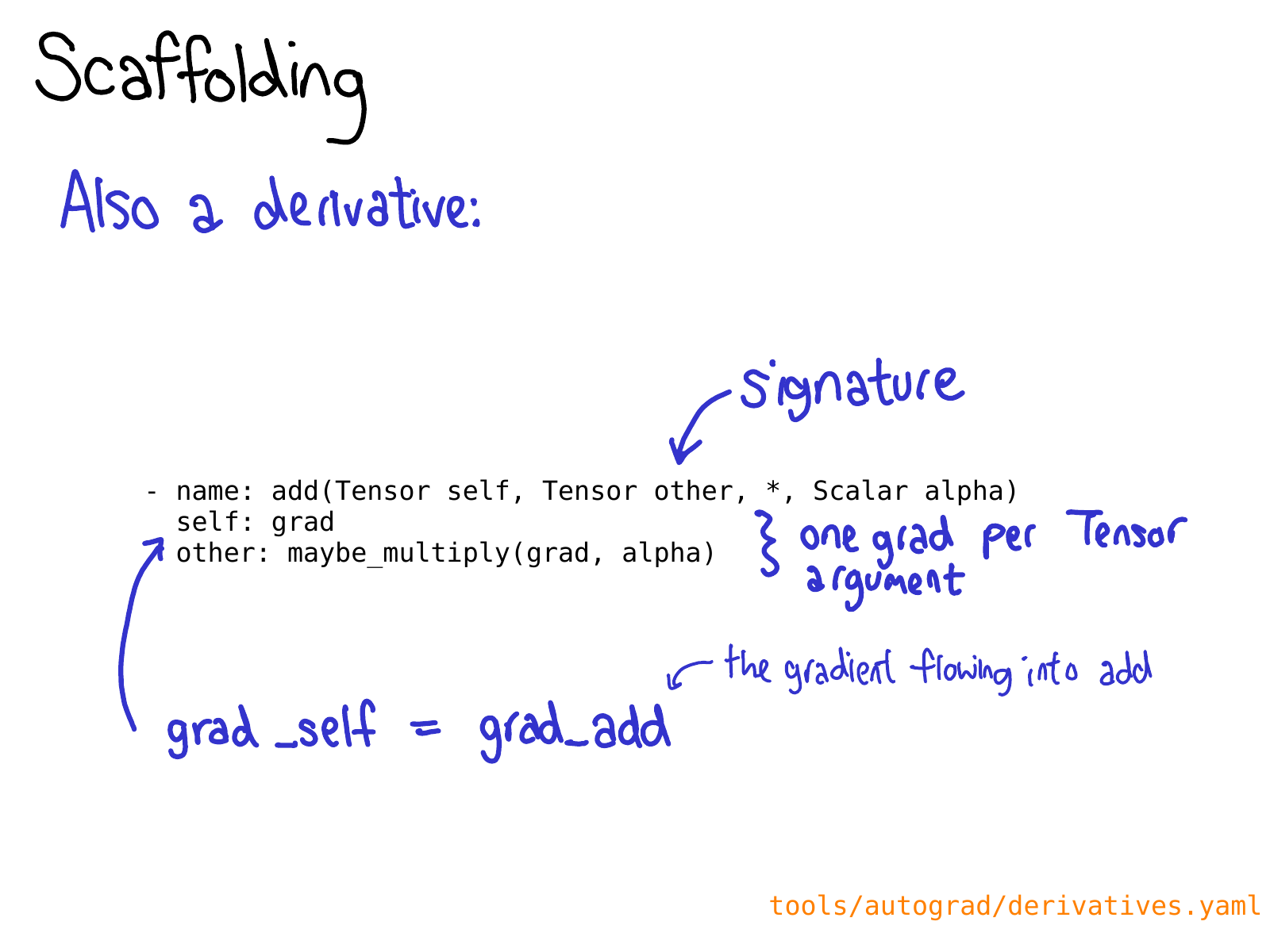
你可能还需要在 derivatives.yaml 中为你的操作定义一个导数。

可以通过低级 API 或高级 API 进行错误检查。低级 API 只是一个宏 TORCH_CHECK,它接受一个布尔值,然后接受任意数量的参数来组成错误字符串,如果布尔值不为真,则呈现该字符串。关于此宏的一个好处是你可以将字符串与非字符串数据混合在一起;所有内容都使用它们的 operator<< 实现进行格式化,并且 PyTorch 中大多数重要的数据类型都有 operator<< 实现。
高级 API 使你免于一遍又一遍地编写重复的错误消息。它的工作方式是,你首先将每个 Tensor 包装到 TensorArg 中,该 TensorArg 包含有关张量来自何处的信息(例如,它的参数名称)。然后,它提供了许多预先准备好的函数,用于检查各种属性;例如,checkDim() 测试张量的维度是否为固定数字。如果不是,该函数会根据 TensorArg 元数据提供用户友好的错误消息。

在 PyTorch 中编写运算符时,需要注意的一件事是,你通常会注册编写_三个_运算符:abs_out,它对预先分配的输出进行操作(这实现了 out= 关键字参数);abs_,它就地操作;以及 abs,它是运算符的普通旧功能版本。
大多数时候,abs_out 是真正的主力,而 abs 和 abs_ 只是 abs_out 周围的薄包装器;但有时有理由为每个案例编写专门的实现。

要进行 dtype dispatch,你应该使用 AT_DISPATCH_ALL_TYPES 宏。它接受你要在上面 dispatch 的张量的 dtype,以及一个 lambda,它将专门用于可从宏 dispatch 的每个 dtype。通常,此 lambda 只是调用一个模板化的辅助函数。
此宏不仅仅是“执行 dispatch”,它还决定你的 kernel 将支持哪些 dtype。因此,实际上有很多版本的此宏,可让你选择不同的 dtype 子集来生成专门化。大多数时候,你只会想要 AT_DISPATCH_ALL_TYPES,但请注意你可能想要 dispatch 到更多类型的情况。在 Dispatch.h 中有关于如何为你的用例选择正确的一个的指导。

在 CPU 上,你经常希望并行化你的代码。过去,这通常是通过直接在你的代码中散布 OpenMP 编译指示来完成的。

在某个时刻,我们必须实际访问数据。PyTorch 提供了很多选项来执行此操作。
- 如果你只想在某个特定位置获取一个值,你应该使用
TensorAccessor。张量访问器就像一个张量,但它将张量的维度和 dtype 硬编码为模板参数。当你检索像x.accessor<float, 3>();这样的访问器时,我们执行运行时测试以确保张量确实是这种格式;但在那之后,每次访问都是未经检查的。张量访问器可以正确处理 stride,因此你应该首选使用它们而不是原始指针访问(不幸的是,某些遗留 kernel 是这样做的。)还有一个PackedTensorAccessor,它特别适合用于在 CUDA 启动上发送访问器,以便你可以从 CUDA kernel 内部获取访问器。(一个值得注意的陷阱:TensorAccessor默认为 64 位索引,这比 CUDA 中的 32 位索引慢得多!) - 如果你要编写某种具有非常规则的元素访问的运算符,例如,一个点态操作,那么你最好使用更高级别的抽象
TensorIterator。此类助手会自动为你处理广播和类型提升,并且非常方便。 - 为了在 CPU 上获得真正的速度,你可能需要使用矢量化的 CPU 指令来编写你的 kernel。我们也有助手!
Vec256类表示标量的向量,并提供许多方法来一次性对它们执行矢量化操作。然后,像binary_kernel_vec这样的助手可以让你轻松地运行矢量化操作,然后使用普通的旧指令完成所有不能很好地舍入为矢量指令的内容。此基础结构还可以管理在不同指令集下多次编译你的 kernel,然后在运行时测试你的 CPU 支持哪些指令,并在这些情况下使用最佳 kernel。

PyTorch 中的许多 kernel 仍以遗留的 TH 样式编写。(顺便说一句,TH 代表 TorcH。这是一个非常好的首字母缩写词,但不幸的是它有点中毒;如果你在名称中看到 TH,请假设它是遗留的。)我所说的遗留的 TH 样式是什么意思?
- 它是以 C 样式编写的,没有(或很少)使用 C++。
- 它是手动引用计数的(通过手动调用
THTensor_free在你完成使用张量时减少引用计数),并且 - 它位于
generic/目录中,这意味着我们实际上将多次编译该文件,但使用不同的#define scalar_t。
此代码非常疯狂,我们讨厌审查它,所以请不要添加到它。如果你喜欢编码但不太了解 kernel 编写,你可以做的一项更有用的任务是将其中一些 TH 函数移植到 ATen。


总而言之,我想简要地谈谈如何高效地在 PyTorch 上工作。如果 PyTorch 庞大的 C++ 代码库是阻止人们为 PyTorch 做出贡献的第一个看门人,那么你的工作流程效率就是第二个看门人。如果你尝试使用 Python 习惯处理 C++,你将会遇到糟糕的体验:重新编译 PyTorch 将花费很长时间,而且你将花费很长时间才能知道你的更改是否有效。
如何高效地工作本身可能就是一个演讲,但是此幻灯片调用了一些最常见的反模式,当有人抱怨时,我看到:"在 PyTorch 上工作很难。"
- 如果你编辑一个标头,特别是被许多源文件包含的标头(特别是如果它被 CUDA 文件包含),请预计会进行非常长的重建。尽量坚持编辑 cpp 文件,并谨慎地编辑标头!
- 我们的 CI 是一种非常棒的零设置方式,可以测试你的更改是否有效。但是预计要等待一两个小时才能收到信号。如果你正在进行需要大量实验的更改,请花时间设置本地开发环境。同样,如果你在特定的 CI 配置中遇到难以调试的问题,请在本地设置它。你可以 在本地下载并运行 Docker 映像。
- CONTRIBUTING 指南解释了如何设置 ccache;强烈建议这样做,因为有时它会帮助你幸运地避免在编辑标头时进行大规模重新编译。它还有助于掩盖我们的构建系统中的错误,当我们不应该重新编译文件时,我们会重新编译文件。
- 归根结底,我们有很多 C++ 代码,如果你在具有 CPU 和 RAM 的强大服务器上构建,你将获得更愉快的体验。特别是,我不建议在笔记本电脑上进行 CUDA 构建;构建 CUDA 非常慢,而且笔记本电脑往往没有足够的动力来快速周转。
这就是 PyTorch 内部机制的旋风之旅的全部内容!许多许多事情都被省略了;但希望这里的描述和解释可以帮助你至少掌握代码库的很大一部分。
你应该从这里去哪里?你可以做出什么样的贡献?一个好的起点是我们的 issue 跟踪器。从今年早些时候开始,我们一直在对 issue 进行分类;标记为 triaged 的 issue 意味着至少有一名 PyTorch 开发人员查看了它并对该 issue 进行了初步评估。你可以使用这些标签来查找我们认为 高优先级 的 issue,或者查找特定于某些模块的 issue,例如 [autograd](https://github.com/pytorch/pytorch/issues?q=is%3Aopen+is%3Aissue+label