使用计算机视觉识别 OpenStreetMap 中的地图要素
[中文正文内容]
使用计算机视觉识别 OpenStreetMap 中的地图要素
Mozilla.ai 开发并发布了 OpenStreetMap AI Helper Blueprint。如果你热爱地图并对训练自己的计算机视觉模型感兴趣,你会喜欢深入研究这个 Blueprint。

David de la Iglesia Castro
Mar 4, 2025 — 5 min read
 Photo by Stefancu Iulian / Unsplash
Photo by Stefancu Iulian / Unsplash
动机
在 Mozilla.ai,我们相信人工智能(AI)在赋能开放协作驱动的社区方面存在大量机会。
然而,这些机会需要仔细设计,因为这些社区的许多成员(以及一般人)越来越担心充斥互联网的 AI slop数量。
考虑到这一点,我们开发并发布了 OpenStreetMap AI Helper Blueprint。如果你热爱地图并对训练自己的计算机视觉模型感兴趣,你会喜欢深入研究这个 Blueprint。
为什么选择 OpenStreetMap?
数据是任何 AI 应用程序最重要的组成部分之一,OpenStreetMap 拥有一个充满活力的社区,他们协同工作以维护和扩展可用的最完整的开放地图数据库。
如果你没听说过,OpenStreetMap 是一张开放的、可编辑的世界地图,由制图者社区创建,他们贡献和维护有关道路、小径、咖啡馆、火车站等的数据。
结合其他来源(如卫星图像),此数据库提供了训练不同 AI 模型的无限可能性。

作为 OpenStreetMap的长期用户和贡献者,我想构建一个端到端的应用程序,该模型首先使用此数据进行训练,然后用于回馈。
这个想法是使用 AI 加速制图过程中较慢的部分(在地图上漫游,绘制多边形),同时让人参与关键部分(验证生成的数据是否正确)。
为什么选择计算机视觉?
大型语言模型 (LLM) 以及最近的视觉语言模型 (VLM) 正在吸走 AI 领域的所有氧气,但是有很多有趣的应用程序不需要使用这种类型的模型。
你可以在 OpenStreetMap 中找到的许多 Map Features 都是用多边形(“区域”)表示的。事实证明,对于一个人来说,查找和绘制这些多边形是一项非常耗时的任务,但是计算机视觉模型可以很容易地针对该任务进行训练(在提供足够数据的情况下)。
我们选择使用最先进的非 LLM 模型将查找和绘制地图要素的工作分为 2 个计算机视觉任务:
- 使用 Ultralytics 的 YOLOv11 进行对象检测,该模型识别图像中存在相关要素的位置。
- 使用 Meta 的 SAM2 进行分割,该模型通过概述其确切形状来细化检测到的要素。
这些模型是轻量级的、快速的且对本地友好的——使用不需要高端 GPU 即可运行的模型令人耳目一新。例如,YOLOv11 和 SAM2 的组合权重比任何可用的最小视觉语言模型(例如 SmolVLM(4.5GB))占用的磁盘空间要小得多(<250MB)。
通过结合这些模型,我们可以自动化大部分制图流程,同时保持人类对最终验证的控制。
OpenStreetMap AI Helper Blueprint
Blueprint 可以分为 3 个阶段:
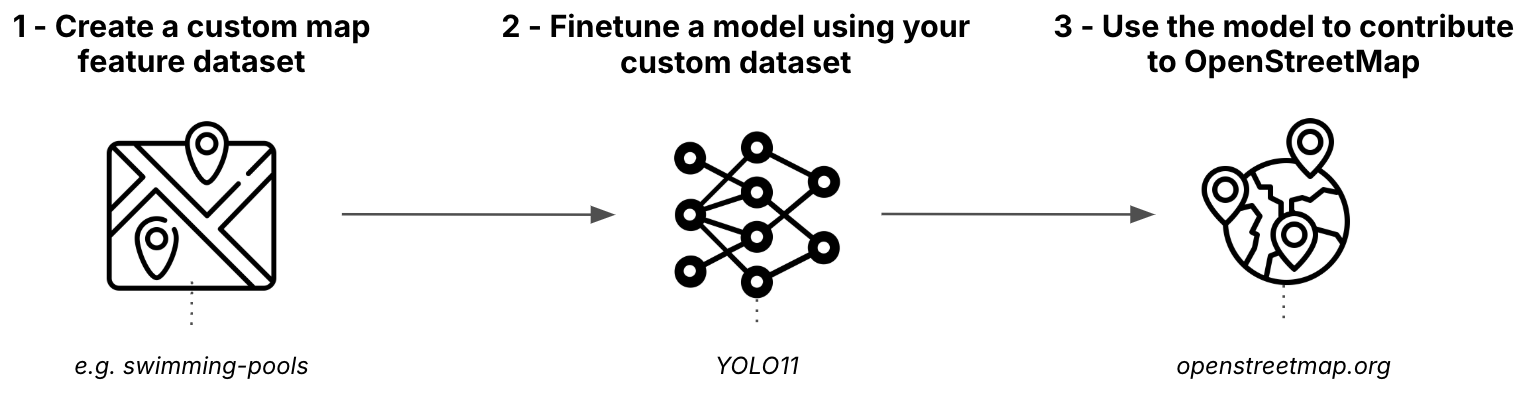
阶段 1:从 OpenStreetMap 创建对象检测数据集
第一阶段包括从 OpenStreetMap 获取数据,将其与卫星图像组合,并将其转换为适合训练的格式。
你可以在 Create Dataset Colab 中自行运行它。
为了获取 OpenStreetMap 数据,我们使用:
- Nominatim API,它为用户提供了一种灵活的方式来选择感兴趣的区域。在我们的游泳池示例中,我们使用 Galicia 进行训练,并使用 Viana do Castelo 进行验证。
- Overpass API,用于使用特定 tags 下载所选区域内的所有相关多边形。在我们的游泳池示例中,我们使用 leisure=swimming_pool,丢弃那些也标记为 location=indoor 的。
下载所有多边形后,你可以选择一个 zoom level。我们使用此缩放级别首先识别包含多边形的所有切片,然后使用 Static Tiles API 从 Mapbox 下载它们。
纬度和经度坐标中的多边形被转换为相对于每个切片的像素坐标中的边界框,然后以 Ultralytics YOLO format 保存。
最后,数据集被上传到 Hugging Face Hub。你可以查看我们的示例 mozilla-ai/osm-swimming-pools。
阶段 2 - 微调对象检测模型
一旦数据集以正确的格式上传,微调 YOLOv11(或 Ultralytics 支持的任何其他模型)非常容易。
你可以在 Finetune Model Colab 中自行运行它,并查看所有 available hyperparameters。
模型经过训练后,也会上传到 Hugging Face Hub。你可以查看我们的示例 mozilla-ai/swimming-pool-detector。
阶段 3 - 贡献给 OpenStreetMap
一旦你有一个微调的对象检测模型,你就可以使用它在多个切片上运行推理。
你可以在 Run Inference Colab 中自行运行推理。
我们还提供了一个托管演示,你可以在其中尝试我们的示例游泳池检测器:HuggingFace Demo。
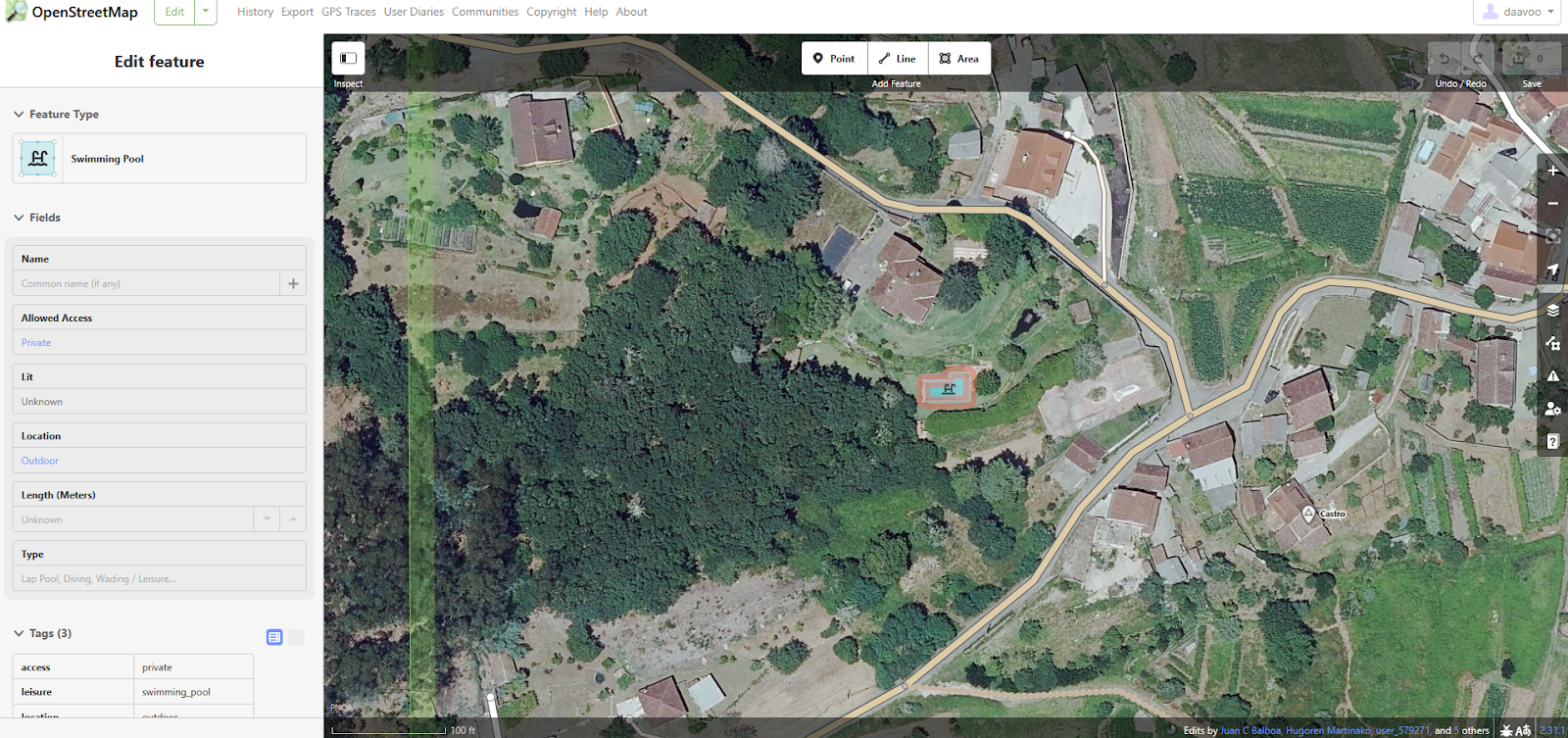
推理需要几个人工交互。首先,你需要首先在地图中选择一个感兴趣的点:
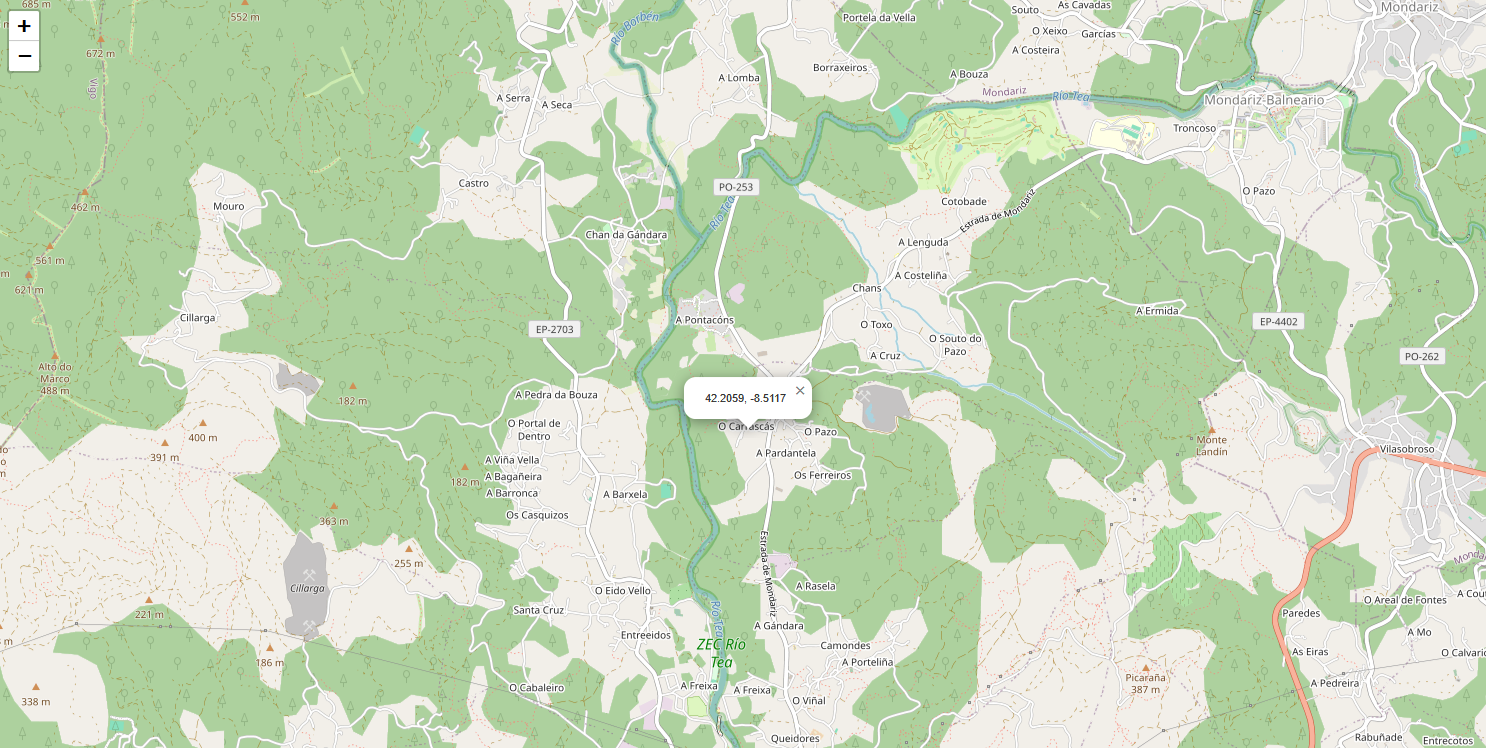
选择一个点后,会基于 margin 参数在其周围计算一个边界框。
所有现有的感兴趣元素都从 OpenStreetMap 下载,并且所有切片都从 Mapbox 下载并连接以创建堆叠图像。

堆叠图像被分成重叠的切片。对于每个切片,我们运行对象检测模型(YOLOv11 以获得分割掩码。
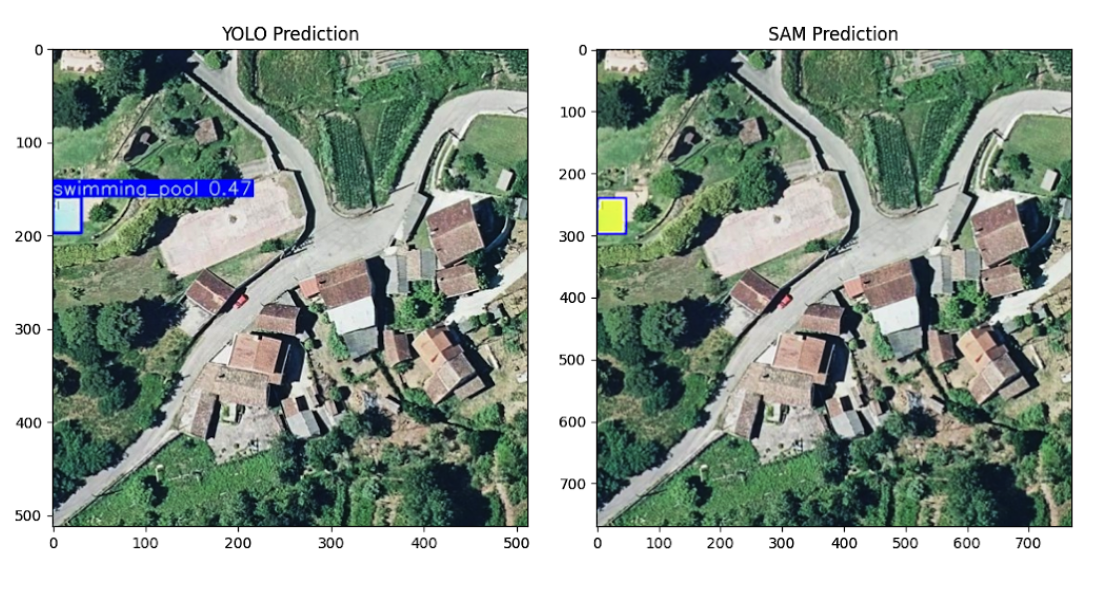
所有预测的多边形都会根据从 OpenStreetMap 下载的现有多边形进行检查,以避免重复。所有被识别为 new 的多边形都会逐个显示以进行手动验证和过滤。
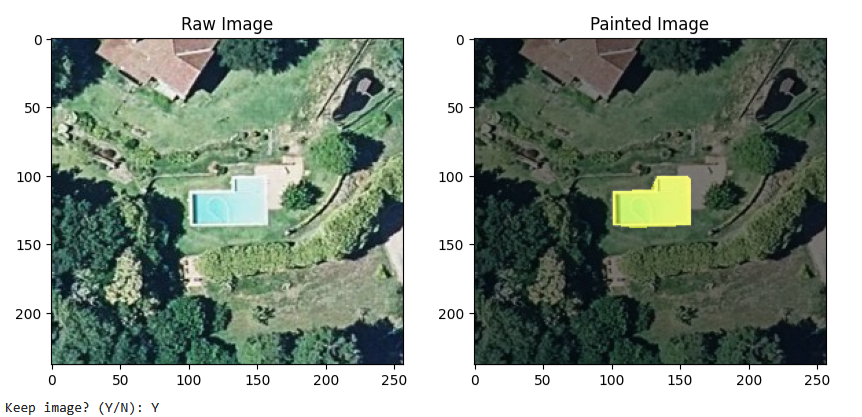
你选择保留的多边形将以单个 changeset 上传到 OpenStreetMap。
结束语
OpenStreetMap 是开放协作的一个强大示例,旨在创建丰富、社区驱动的世界地图。
OpenStreatMap AI Helper Blueprint 表明,通过正确的方法,AI 可以增强人类的贡献,同时将人工验证置于核心地位。在完全手动的过程中,绘制 2-3 个游泳池大约需要 1 分钟,而使用 blueprint,即使没有优化的 UX,我也可以在同一时间内绘制大约 10-15 个(大约多 5 倍)。
它还突出了来自 OpenStreetMap 等项目的高质量数据的价值,这使得可以轻松地训练像 YOLOv11 这样的模型来执行对象检测——证明你不应该总是将 LLM 应用于问题。
我们很乐意你尝试 OpenStreetMap AI Helper Blueprint 并尝试在不同的地图要素上训练模型。如果你有兴趣,请随时为 repo 贡献以帮助改进它,或 fork 它以进一步扩展它!
要查找我们发布的其他 Blueprint,请查看 Blueprints Hub。
阅读更多
 Build Your Own Timeline Algorithm: A Blueprint Timeline algorithms should be useful for people, not for companies. Their quality should not be evaluated in terms of how much time people spend on a platform, but rather in terms of how well they serve their users’ purposes. By Davide Eynard Mar 20, 2025
Build Your Own Timeline Algorithm: A Blueprint Timeline algorithms should be useful for people, not for companies. Their quality should not be evaluated in terms of how much time people spend on a platform, but rather in terms of how well they serve their users’ purposes. By Davide Eynard Mar 20, 2025  Benchmarking DeepSeek R1 Models using Lumigator: A Practical Evaluation for Zero-Shot Clinical Summarization New state-of-the-art models emerge every few weeks, making it hard to keep up, especially when testing and integrating them. In reality, many available models may already meet our needs. The key question isn’t “Which model is the best?” but rather, “What’s the smallest model that gets the job done?” By Nathan Brake, Davide Eynard, Dimitris Poulopoulos, Irina Vidal Migallón Mar 13, 2025
Benchmarking DeepSeek R1 Models using Lumigator: A Practical Evaluation for Zero-Shot Clinical Summarization New state-of-the-art models emerge every few weeks, making it hard to keep up, especially when testing and integrating them. In reality, many available models may already meet our needs. The key question isn’t “Which model is the best?” but rather, “What’s the smallest model that gets the job done?” By Nathan Brake, Davide Eynard, Dimitris Poulopoulos, Irina Vidal Migallón Mar 13, 2025  Evaluating DeepSeek V3 with Lumigator A typical user may be building a summarization application for their domain and wondering: “Do I need to go for a model as big as DeepSeek, or can I get away with a smaller model?”. This takes us to the key elements: Metrics, Models, and Datasets. By Dimitris Poulopoulos, Irina Vidal Migallón, Nathan Brake, Davide Eynard Mar 6, 2025
Evaluating DeepSeek V3 with Lumigator A typical user may be building a summarization application for their domain and wondering: “Do I need to go for a model as big as DeepSeek, or can I get away with a smaller model?”. This takes us to the key elements: Metrics, Models, and Datasets. By Dimitris Poulopoulos, Irina Vidal Migallón, Nathan Brake, Davide Eynard Mar 6, 2025  Deploying DeepSeek V3 on Kubernetes Previously, we explored how LLMs like Meta’s Llama reshaped AI, offering transparency and control. We discussed open-weight models like DeepSeek and deployment options. Now, we show how to deploy DeepSeek V3, a powerful open-weight model, on a Kubernetes cluster using vLLM. By Dimitris Poulopoulos, Kyle White Feb 20, 2025
Deploying DeepSeek V3 on Kubernetes Previously, we explored how LLMs like Meta’s Llama reshaped AI, offering transparency and control. We discussed open-weight models like DeepSeek and deployment options. Now, we show how to deploy DeepSeek V3, a powerful open-weight model, on a Kubernetes cluster using vLLM. By Dimitris Poulopoulos, Kyle White Feb 20, 2025
Powered by Ghost
Mozilla.ai
Subscribe to receive updates Subscribe