LLM 时代改进推荐系统和搜索
Improving Recommendation Systems & Search in the Age of LLMs
[ recsys llm teardown survey ] · 43 分钟阅读
推荐系统和搜索在历史上一直从语言建模中汲取灵感。例如,采用 Word2vec 来学习 item embeddings(用于 embedding-based retrieval),以及使用 GRUs、Transformer 和 BERT 来预测下一个最佳 item(用于 ranking)。当前的大型语言模型范式也不例外。
在这里,我们将讨论工业搜索和推荐系统在过去一年左右的发展历程,并涵盖模型架构、数据生成、训练范式和统一框架:
LLM/multimodality-augmented 模型架构
推荐模型越来越多地采用语言模型和多模态内容,以克服传统的基于 ID 的方法的局限性。这些混合架构包括内容理解以及行为建模的优势,解决了冷启动和长尾 item 推荐的常见挑战。
Semantic IDs (YouTube) 探索了 content-derived features 作为传统基于哈希的 ID 的替代品。 这种方法针对的是预测用户对新 item 和交互次数少的 item 的偏好的难题。他们的解决方案涉及一个两阶段框架。
在第一阶段,一个基于 Transformer 的视频编码器(类似于 Video-BERT)生成 dense content embeddings。然后,通过 Residual Quantization Variational AutoEncoder (RQ-VAE) 将这些 embeddings 压缩为离散的 Semantic IDs。使用这些紧凑的 semantic IDs(几个整数而不是高维 embeddings)来表示用户历史记录,可以显著提高效率。一旦训练完成,RQ-VAE 就会被冻结,并用于生成 Semantic IDs,以便在第二阶段训练 production-scale ranking 模型。
RQ-VAE 本身是一个单层 encoder-decoder 结构,具有 256 维的 latent space。它有八个 quantization levels,每个 level 的 codebook 有 2048 个条目。encoder 将 content embeddings 映射到 latent vector,而 residual quantizer 将这个 vector 离散化,decoder 则重建原始 embedding。初始的 embeddings 来自于一个具有 VideoBERT backbones 的 Transformer,生成详细的 2048 维表示,从而捕获视频中的主题内容。
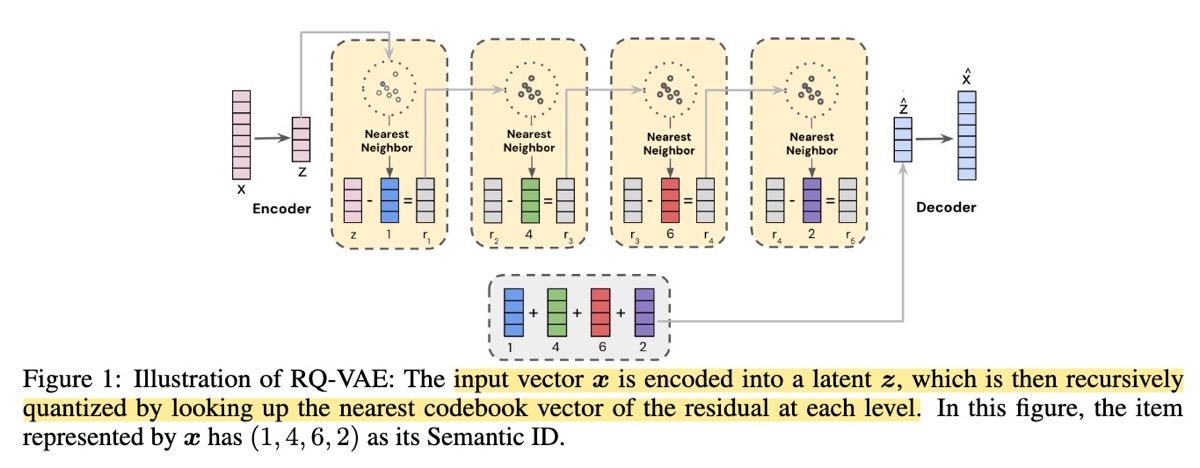
为了将 Semantic IDs 集成到 ranking 模型中,作者提出了两种技术:一种基于 N-gram 的方法,将固定长度的序列分组;以及一种基于 SentencePiece Model (SPM) 的方法,自适应地学习可变长度的 subwords。ranking 模型是一个 multi-task production ranking 模型,它根据当前的视频和用户历史记录,推荐下一个要观看的视频。
结果: 直接使用 dense content embeddings 的效果比使用随机 hash IDs 差。作者推测,ranking 模型严重依赖于基于 ID 的 embedding tables 的记忆——用 fixed dense content embeddings 替换它们会导致 CTR 降低。但是,N-gram 和 SPM 方法都比随机 hashing 更好,尤其是在 cold-start 场景中。Ablation tests 显示,当 embedding table 的大小受到限制时(例如,$8 \times K$ 或 $4 \times K^2$),N-gram 方法具有轻微的优势,而 SPM 方法在较大的 embedding table 中提供了更好的泛化性和效率。
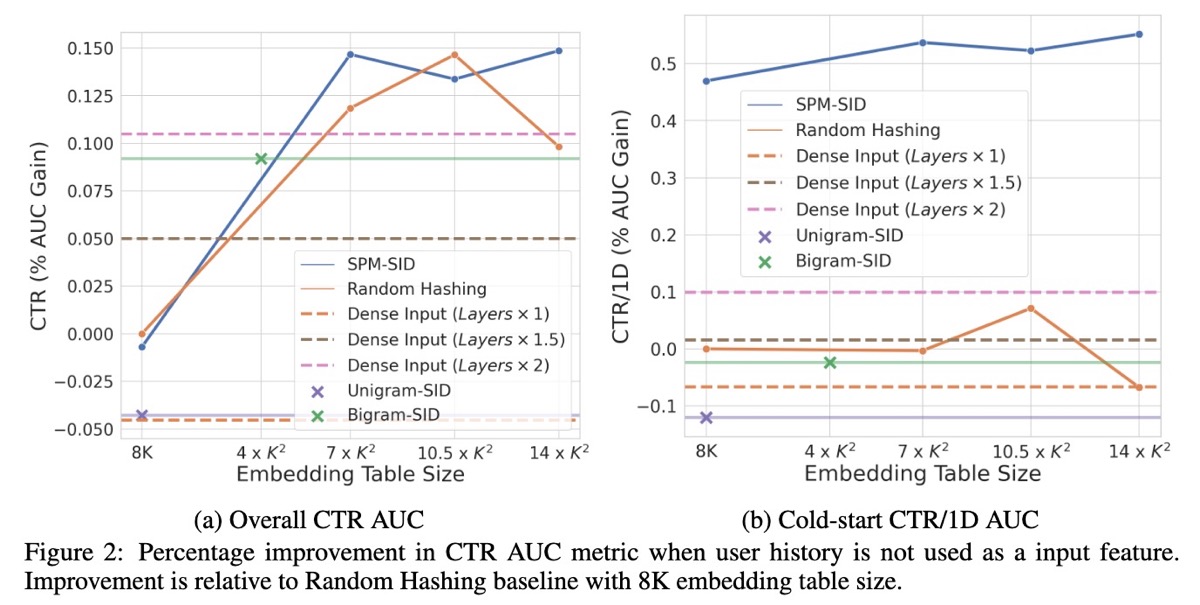
Dense content embeddings(虚线)的表现比随机 hashing(实橙色)差。
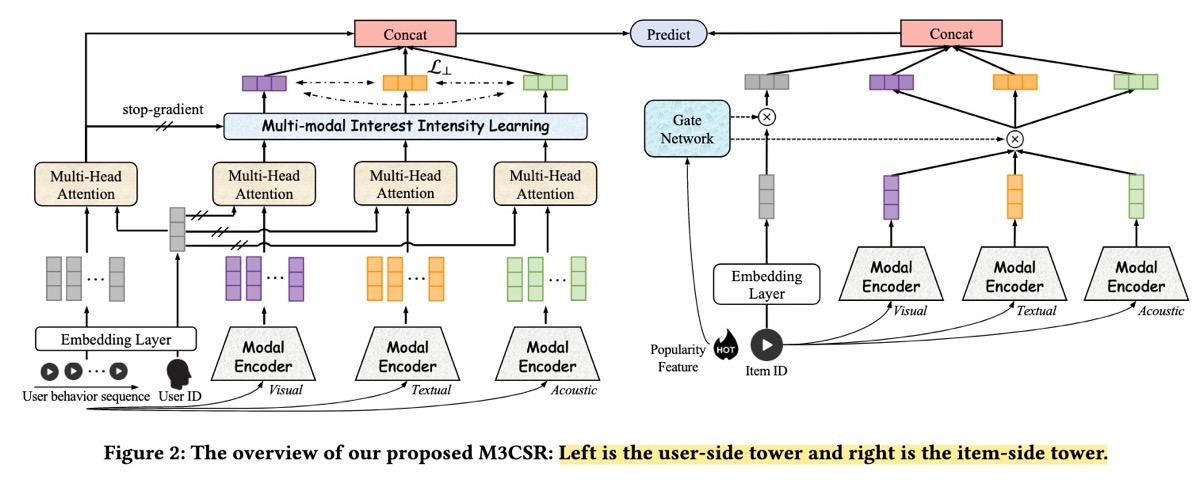
类似地,M3CSR (Kuaishou) 引入了 multimodal content embeddings(视觉、文本、音频),这些 embeddings 通过 K-means 聚类成 trainable category IDs。 这将静态 content embeddings 转换为可适应的、行为对齐的表示。
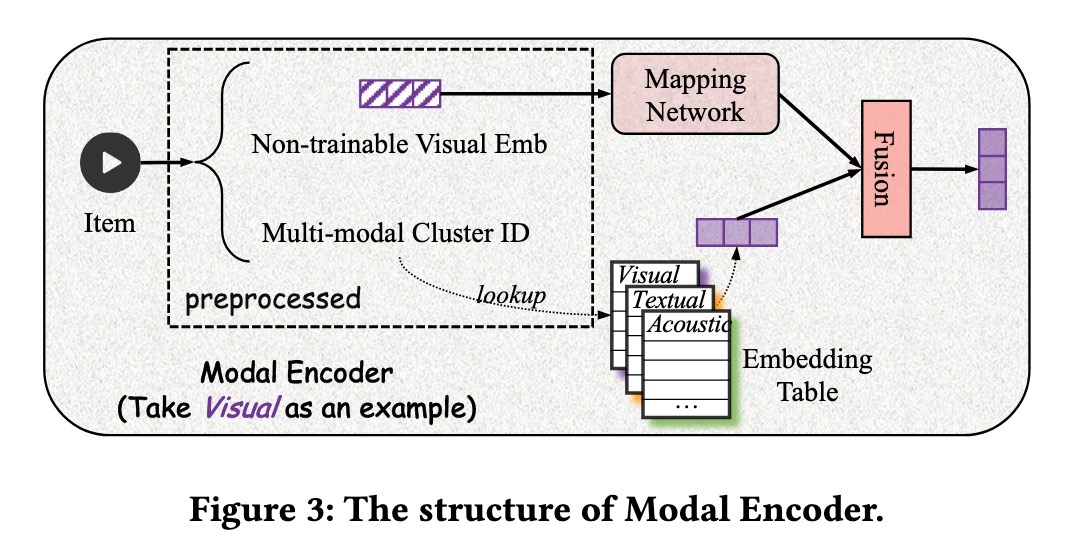
M3CSR 框架具有 dual-tower 架构,将 user-side 和 item-side towers 分开,以优化在线 inference 效率,在这种架构中,user 和 item embeddings 可以预先计算并通过 approximate nearest neighbor indices 进行索引。Item embeddings 来源于 multimodal pretrained models——ResNet 用于视觉,Sentence-BERT 用于文本,VGGish 用于音频——并将它们连接成一个单一的 embedding vector。然后,使用 K-means 将这些 vectors 聚类(从超过 1000 万个视频中提取约 1,000 个 clusters)。
接下来,cluster IDs 通过 Modal Encoder 进行 embedding,Modal Encoder 是一个 dense network,用于将 content features 转换为行为对齐的 spaces,并分配 trainable cluster ID embeddings。Modal Encoder 使用 dense network 来学习从 content-space 到 behavior space 的映射,并使用 cluster ID lookup 来分配 trainable cluster ID embedding。
在 user 端,M3CSR 基于 user behavior sequences 进行学习,以训练 sequential models,从而捕获用户偏好。此外,为了准确地建模用户 modality preferences,该框架将 general behavioral interests 与 modality-specific interests 连接起来。这些 modality-specific interests 是通过使用相同的 Modal Encoder 将 item IDs 转换回 multimodal embeddings 而得出的。
结果: M3CSR 优于几个 multimodal baselines,例如 VBPR、MMGCN 和 LATTICE。Ablation studies 强调了建模 modality-specific user interests 的重要性,并证明了在各个数据集(Amazon、TikTok、Allrecipes)中,multimodal features 始终优于 single-modal features。A/B testing 测量到点击率增加了 3.4%,点赞增加了 3.0%,关注增加了 3.1%。在 cold-start 场景中,M3CSR 也显示出改进的性能,在 cold-start velocity 方面提高了 1.2%,在 cold-start 视频覆盖率方面提高了 3.6%。
FLIP (Huawei) 展示了如何通过从 masked tabular 和 language data 中联合学习,将基于 ID 的推荐模型与 LLMs 对齐。 核心思想是使用来自另一种 modality(文本 tokens)的信息,重建来自一种 modality(user 和 item IDs)的 masked features,从而确保紧密的 cross-modal alignment。
FLIP 分三个阶段运行:modality transformation、modality alignment pretraining 和 adaptive finetuning。首先,使用 structured prompt templates 将 tabular data 转换为文本。然后,进行联合 masked language/tabular modeling,以实现 modalities 之间的 fine-grained alignment。在 pretraining 期间, textual data 会经历 field-level masking(将整个字段替换为 [MASK] tokens),而相应的 tabular features 会被 masking,方法是用 [MASK] 替换 feature IDs。
FLIP 训练两个并行模型,具有三个目标:(i) Masked Language Modeling (MLM) 使用完整的 tabular context 预测 masked text tokens;(ii) Masked Tabular Modeling (MTM) 利用 textual data 预测 masked feature IDs;以及 (iii) Instance-level Contrastive Learning (ICL) 对齐跨 modalities 的 global representations。
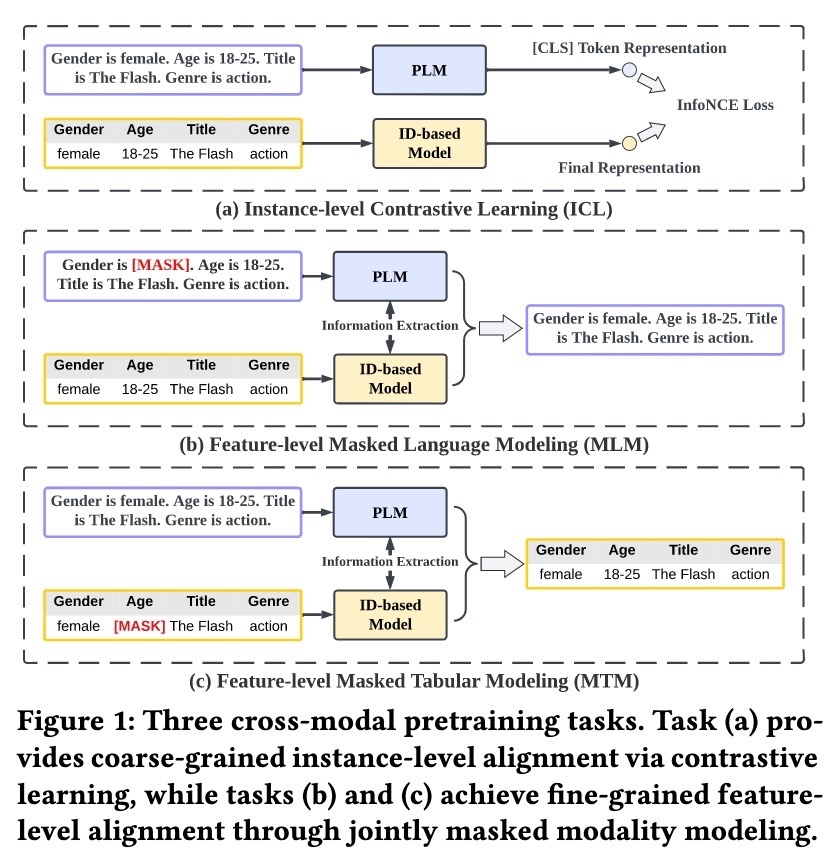
最后,aligned models——TinyBERT 作为 LLM,DCNv2 作为基于 ID 的模型——在 downstream click-through rate (CTR) prediction task 上进行 finetuning。为此,FLIP 在两个模型上添加了随机初始化的 output layers,以估计点击概率。最终的预测是两个模型的 outputs 的加权总和,其中权重在训练期间自适应地学习。
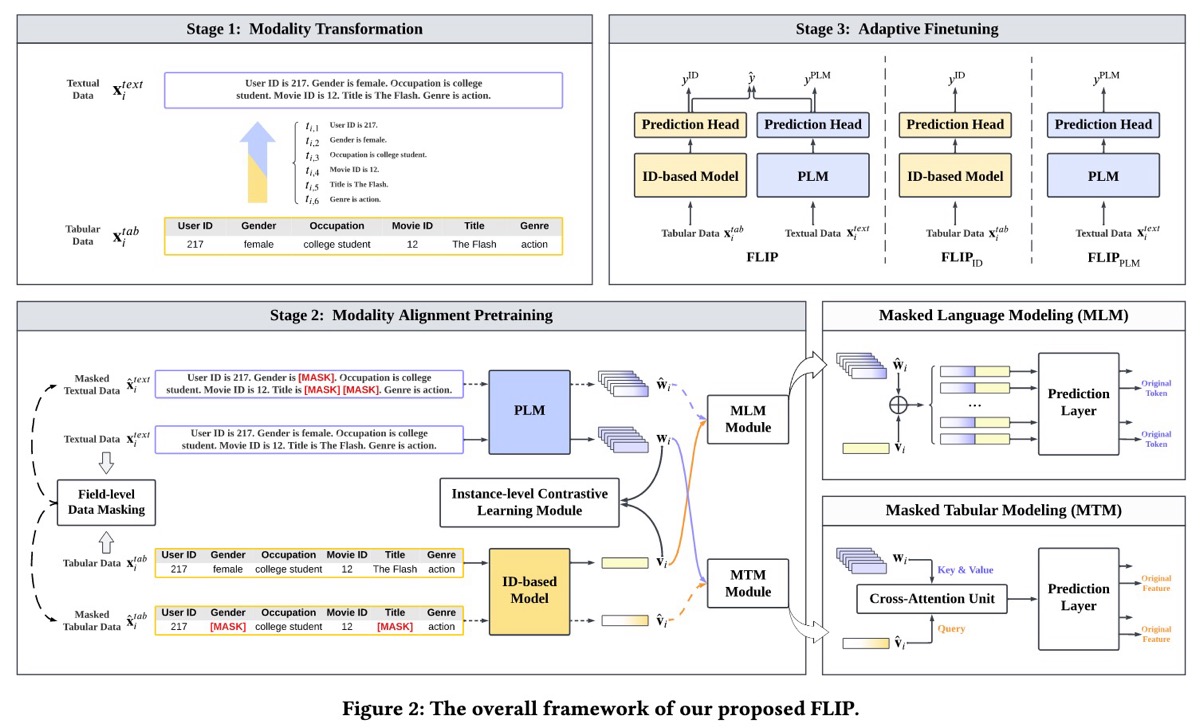
结果: FLIP 优于 ID-only、LLM-only 和 ID+LLM 模型的 baselines。Ablation studies 表明:(i) MLM 和 MTM 目标都可以提高性能,(ii) field-level masking 比 random token masking 更有效,以及 (iii) modalities 之间的联合重建是关键。
类似地,beeFormer 展示了如何在用 textual information 丰富过的 user-item interaction data 上训练 language-only Transformers。 目标是弥合 semantic similarity(来自 textual data)和 interaction-based similarity(来自用户行为)之间的差距。
beeFormer 将用于 item embeddings 的 sentence Transformer encoder 与基于 ELSA (scalablE L inear S hallow A utoencoder)-based decoder 相结合,后者捕获来自 user-item interactions 的 patterns。首先,通过在 textual data 上训练的 Transformer 生成 item embeddings。然后,通过 ELSA 的 item-to-item weight 的 low-rank approximation 使用这些 embeddings 来计算 user recommendations。这里的关键是将 recommendation loss 中的 gradients 反向传播到 Transformer 模型中。因此,weight 更新捕获的是 interaction patterns,而不仅仅是 semantic similarity。
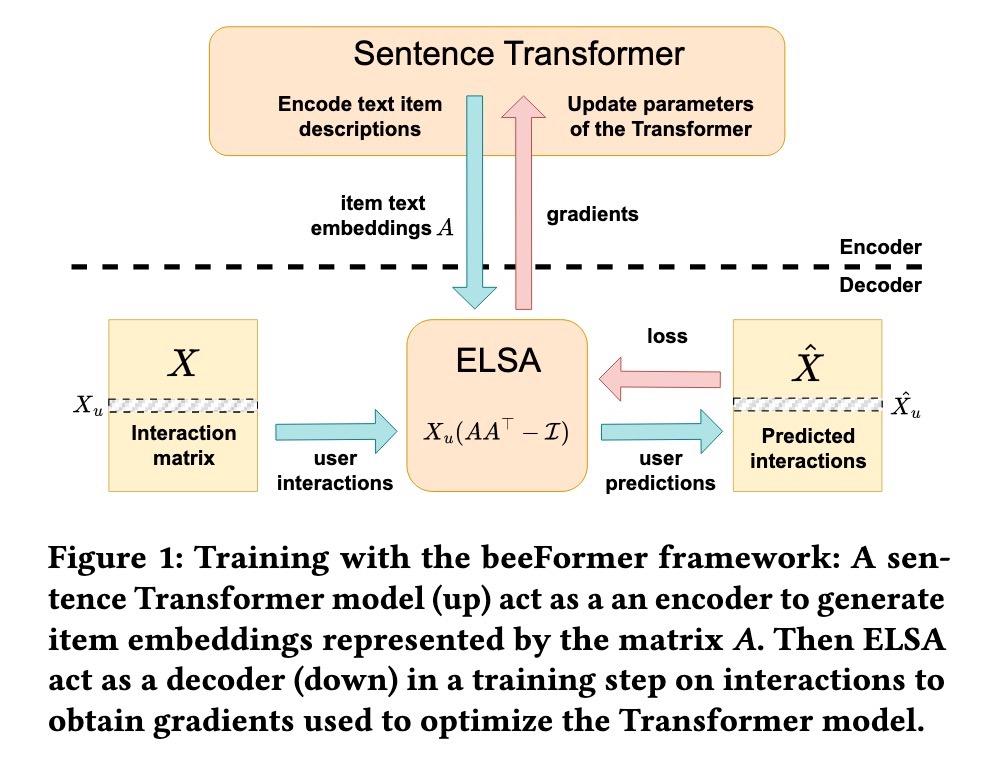
为了使在大型 catalogs 上的训练在计算上可行,beeFormer 应用 gradient checkpointing 来管理 memory usage、gradient accumulation 用于更大的 effective batch sizes,以及 negative sampling 来有效地将训练集中在相关的 items 上。
结果: Offline evaluations 显示 beeFormer 超过了 mpnet-base-v2 和 bge-m3 等 baseline models。但是,比较是有限的(而且恕我直言是不公平的),因为 baselines 没有在训练数据集上进行 finetuning。有趣的是,跨多个领域(电影 + 书籍)训练的模型比 domain-specific 的模型表现更好,这表明存在跨领域的迁移学习。
CALRec (Google) 引入了一个两阶段框架,用于 finetuning 用于 sequential recommendations 的 pretrained LLM (PaLM-2 XXS)。 用户互动和模型预测都完全通过文本表示。
首先,所有输入(例如,user-item interactions)都通过将有意义的 attributes(title、category、brand、price)连接到 structured textual prompts 中,从而转换为 text sequences。Attributes 的格式为“Attribute name: Attribute description”并连接起来。在 user history sequence 的末尾,它们附加 item prefix,从而提示 LLM 将用户的下一次购买预测为 sentence completion task。

CALRec 具有两阶段 finetuning 方法。第一阶段涉及 multi-category training,使模型适应 category-agnostic 的 sequential recommendation patterns。第二阶段在特定的 item categories 中改进模型。训练目标将 next-item generation tasks(预测 items 的 textual descriptions)与 auxiliary contrastive alignment 相结合。前者旨在生成 target item 的 text description,给定用户的历史记录;后者对单独的 user 和 item towers 的输出应用 contrastive loss,以将 user history 与 target item representations 对齐。
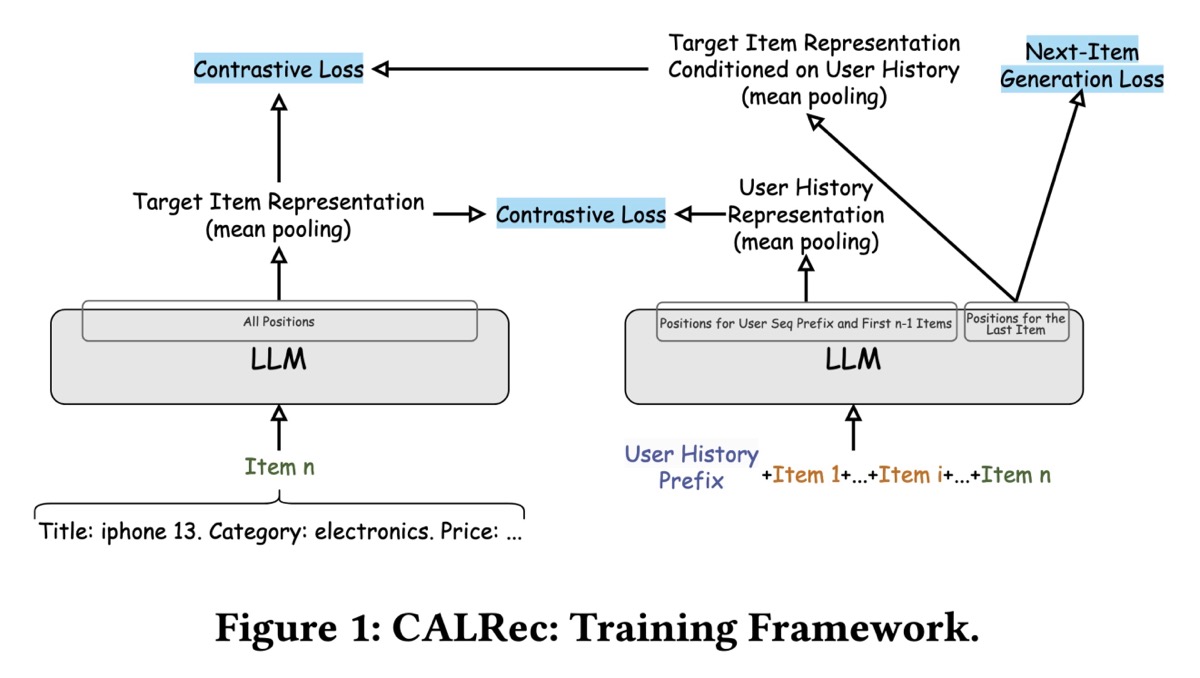
在 inference 期间,提示模型通过 temperature sampling 生成多个候选者。他们删除重复项,按输出的 log probabilities 降序排序,并保留前 k 个候选者。然后,这些 textual predictions 通过 BM25 与 catalog items 匹配,并按匹配分数排序。
结果: 在 Amazon Review Dataset 2018 上,CALRec 优于基于 ID 和基于文本的 baselines(例如,SASRec、BERT4Rec、FDSA、UniSRec)。虽然 evaluation dataset 是有限的,但 CalRec 击败 baselines 很有希望。Ablations 证明了两个训练阶段的必要性,尤其强调了来自 multi-category training 的迁移学习优势和来自 contrastive alignment 的 incremental gains (0.8 - 1.7%)。
EmbSum (Meta) 提出了一种基于内容的推荐方法,该方法使用预先计算的 user interests 和 candidate items 的 textual summaries 来捕获 user engagement history 中的 interactions。
EmbSum 使用 T5-small (61M parameters) 来编码 user interactions 和 candidate content,通过将长的 user histories 分区为 sessions 以进行编码来管理它们。然后,Mixtral-8x22B-Instruct 从 user histories 生成 interpretable user interest summaries。然后,将这些 summaries 馈送到 T5 的 encoder 中以得出最终的 embeddings。
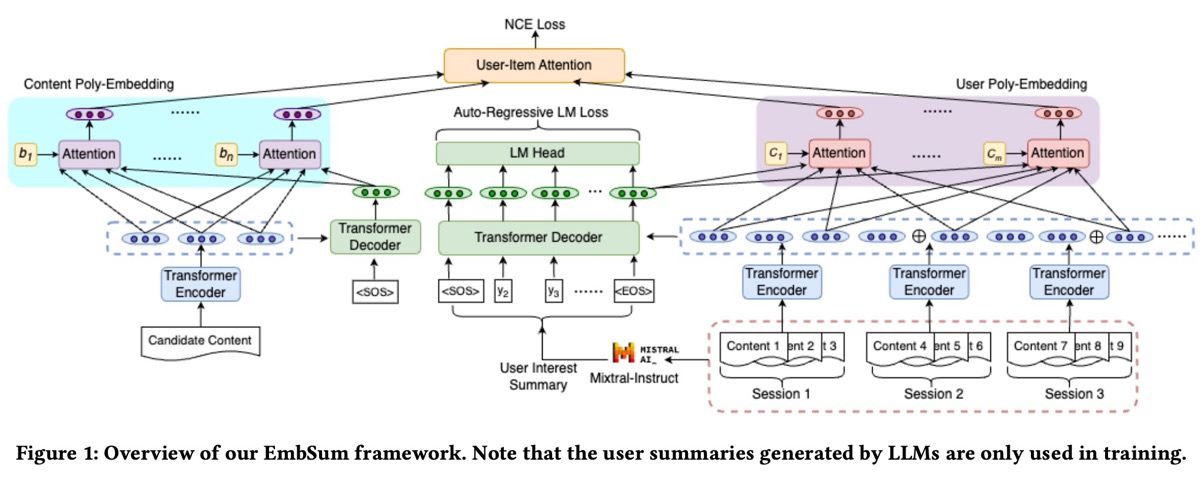
此架构的关键是 User Poly-Embeddings (UPE) 和 Content Poly-Embeddings (CPE)。为了获得 UPE 的 global representation,他们采用 decoder output ([EOS]) 的最后一个 token,并将其与来自 session encoder 的 representation vectors 连接起来。这个组合的 representation 通过一个 poly-attention layer,该 layer 将 nuanced user interests 提炼成多个 embeddings。EmbSum 训练将 noisy contrastive estimation loss 和 summarization loss 相结合,从而确保高质量的 user embeddings。
结果: EmbSum 击败了几个 state-of-the-art 基于内容的 recommenders。 尽管如此,与 behavioral recommenders 的直接比较明显缺失。 Ablation studies 显示,CPE 对性能的贡献最大,其次是基于 session 的分组和编码、user poly-embeddings 和 summarization losses。此外,GPT-4 evaluations 表明生成的 user interest summaries 具有很强的 interpretability 和 quality。
• • •
LLM 辅助的数据生成和分析
另一个常见的 theme 是使用 LLMs 来丰富数据。几篇论文分享了如何使用 LLMs 来解决数据稀缺问题并提高搜索和推荐的质量。例如,在 Bing 生成网页 metadata、在 Indeed 创建 synthetic training data 以识别 poor job matches、在 Yelp 添加 semantic labels 用于 query understanding、在 Spotify 制作 exploratory search queries,以及在 Amazon 丰富音乐 playlist metadata。
Recommendation Quality Improvement (Bing) 分享了 Bing 如何通过使用 LLMs 生成 high-quality metadata 来改进网页 recommendations, 以及如何训练 LLM 来预测点击率和质量。
以前,Bing 的网页表示依赖于 extractive summaries,这通常会导致 query classification 失败。为了解决这个问题,他们使用 GPT-4 从完整的网页内容中为 200 万个页面生成 high-quality 的 titles 和 snippets。然后,为了实现高效的大规模部署,他们使用 GPT-4 生成的数据 finetuned 了 Mistral-7B 模型。
为了提高 webpage-to-webpage recommendation rankings,他们 finetuned 了一个基于 multitask MiniLM 的 cross-encoder,用于 pairwise click predictions 和 quality classification tasks。然后,将生成的 quality scores 与来自现有 LightGBM ranker 的 click predictions 线性组合。
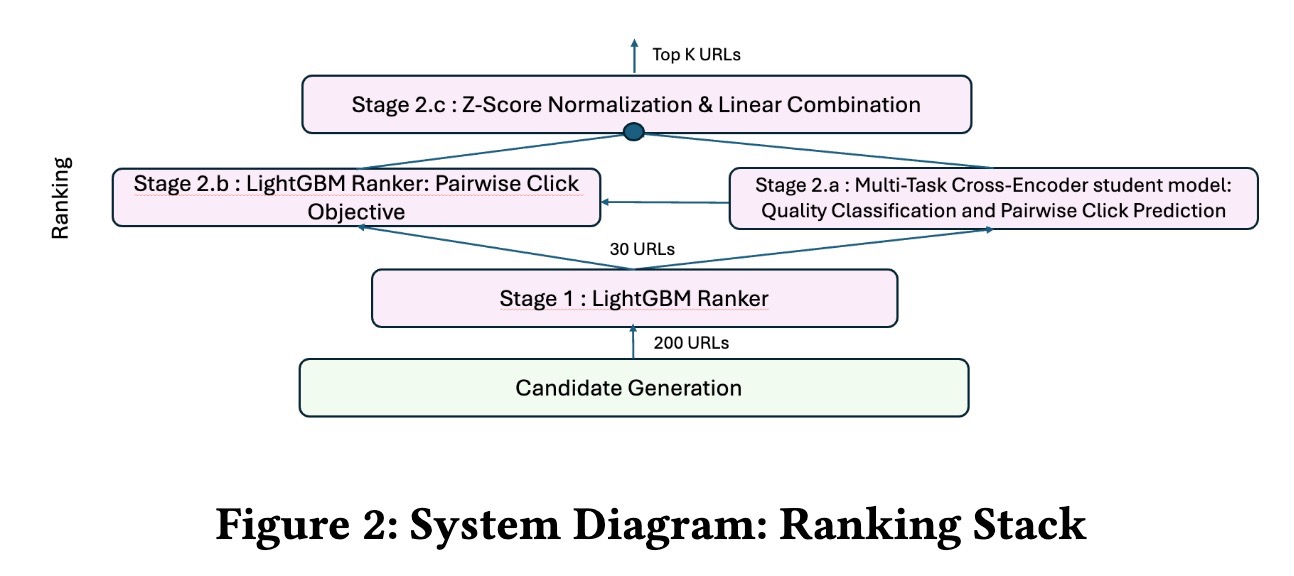
MiniLM(右)与 LightGBM ranker(左)集成在一起。
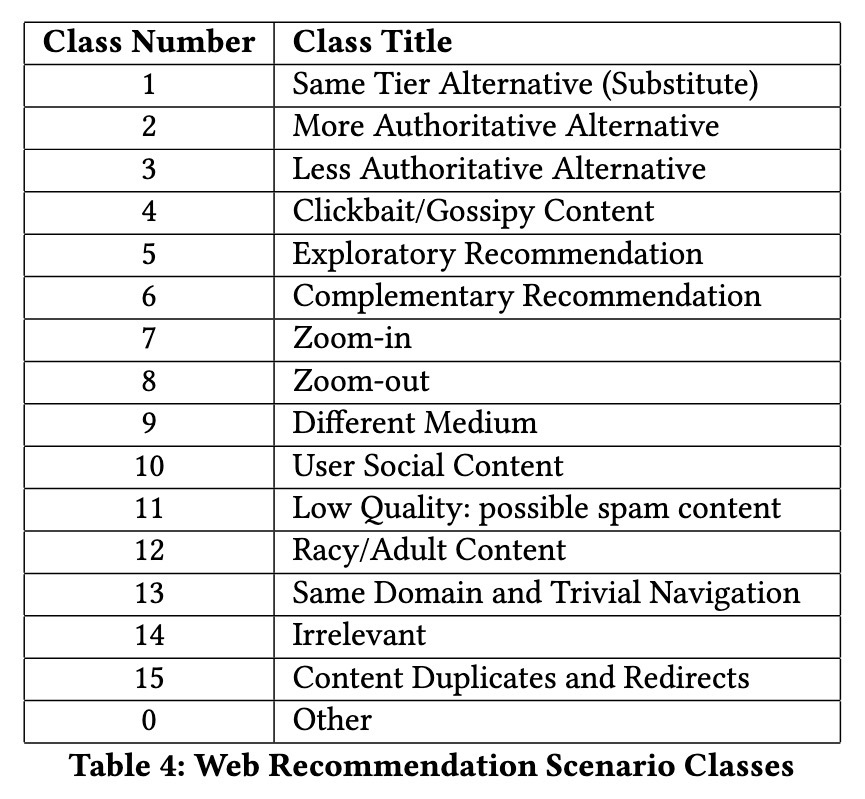
为了更好地理解用户偏好,他们定义了 16 种不同的 recommendation 场景,反映了常见的用户 patterns。使用 high-precision prompts,他们将每个 webpage-to-webpage recommendation(结合了来自 Mistral-7B 的 enhanced title 和 snippets)分类到这些场景中。然后,通过监控每个场景的分布变化,他们量化了网页 recommendation 质量的改进。
结果: 增强后的系统减少了 31% 的 clickbait、35% 的 low-authority content 和 76% 的 duplicate content。与此同时,higher authority content 增加了 18%,cross-medium recommendations 上升了 48%,更具 specificity 的 recommendations 提高了 20%。尽管 lower-quality content(例如,clickbait)在历史上显示出更高的 CTR,但这证明了以质量为重点的 cross-encoder 的有效性。
(👉 推荐阅读) Expected Bad Match (Indeed) 分享了他们如何使用 LLM 生成的 labels 来过滤 poor job matches。 具体来说,他们 finetuned LLMs 来评估 recommendation 质量,并为 post-processing classifier 生成 labels。
他们首先通过 cross-reviewing 250 个 matches 来构建一个 evaluation set,将其缩小到 147 个 high confidence labeled examples。然后,他们使用 expert recruitment guidelines 提示各种 LLMs,例如 Llama2 和 Mistral-7B,以评估 job descriptions、resumes 和 user interactions 等多个维度上的 match quality。但是,这些模型在处理详细 prompts 时遇到了困难,产生了没有考虑详细 job 和 job seeker 信息的 generalized assessments。另一方面,GPT-4 的表现更好,但 prohibitively expensive。
为了平衡成本和有效性,该团队在 200 多个 human-reviewed GPT-4 responses 的 curated dataset 上 finetuned 了 GPT-3.5。这个 finetuned GPT-3.5 在仅仅四分之一的成本和延迟下,与 GPT-4 的性能相匹配。但是,尽管有所改进,但其 6.7 秒的 inference latency 对于在线使用来说仍然太高。因此,他们训练了一个 lightweight classifier,eBadMatch,使用 LLM 生成的 labels 和来自 job descriptions、resumes 和 user activity 的 categorical features。在 production 中,每日 pipeline 对 job matches 进行采样、设计 features、匿名化数据、生成 LLM labels 并 retrains 模型。这个 classifier 充当 post-processing filter,以删除 low-quality matches。
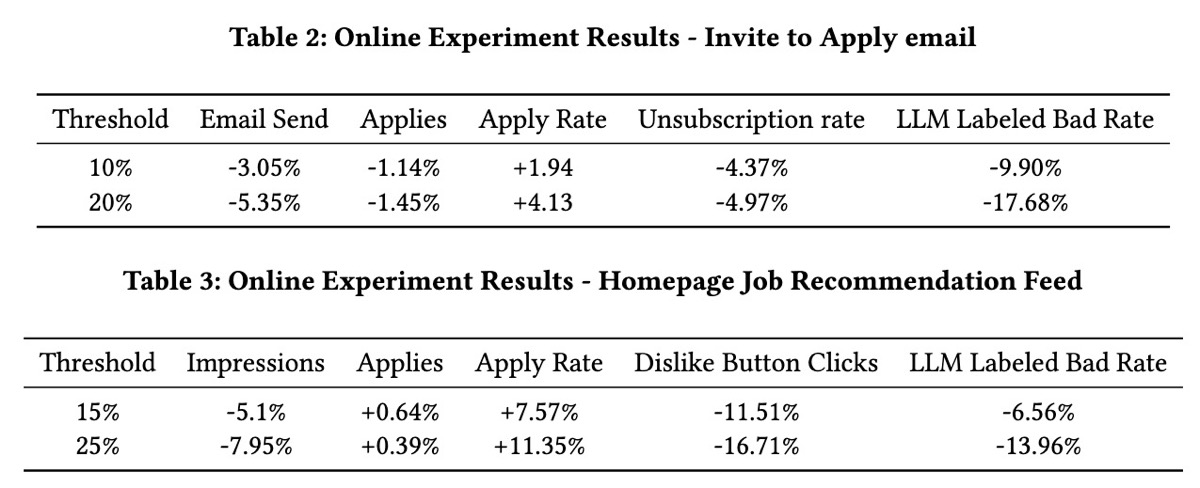
结果: eBadMatch classifier 针对 LLM labels 实现了 0.86 的 AUC-ROC,其 latency 适合实时过滤。Online experiments 表明,在 invitation-to-apply emails 上应用 20% 的 threshold filter 可将 batch matches 减少 17.68%、降低 unsubscribe rates 4.97% 并增加 application rates 4.13%。在 homepage recommendation feeds 中也观察到了类似的改进。
(👉 推荐阅读) Query Understanding (Yelp) 展示了他们如何将 LLMs 集成到其 query understanding pipeline 中, 以改进 query segmentation 和 review highlights。
Query segmentation 识别 user queries 的有意义部分(例如,topic、name、time、location 和 question)并相应地标记它们。在此过程中,他们了解到拼写校正和分割可以一起完成,因此添加了一个 meta tag 来标记拼写校正的部分,并将两个任务合并到一个 prompt 中。Retrieval-augmented generation (RAG) 通过将 business names 和 categories 作为消除 user intent 歧义的 context,进一步提高了 segmentation accuracy。为了进行 evaluation,他们将 LLM 识别的 segments 与 human-labeled 的 name match 和 location intent datasets 进行了比较。
Review highlights 选择 reviews 中的关键 snippets 以在搜索结果中突出显示。他们使用 LLMs 生成适合 highlights 的同义词组。Curated examples 提示 LLMs 在 phrase expansion 中复制 human reasoning。RAG 通过使用相关 business categories 扩充输入以指导 phrase generation,进一步增强了相关性。Offline evaluation 是通过 human annotators 完成的,然后在 online A/B testing 中测试新的 highlight phrases。为了高效地扩展并覆盖 95% 的 traffic,Yelp 使用对 OpenAI 的 batch calls 预先计算了 snippet expansions,并将它们存储在 key-value stores 中以减少 latency。
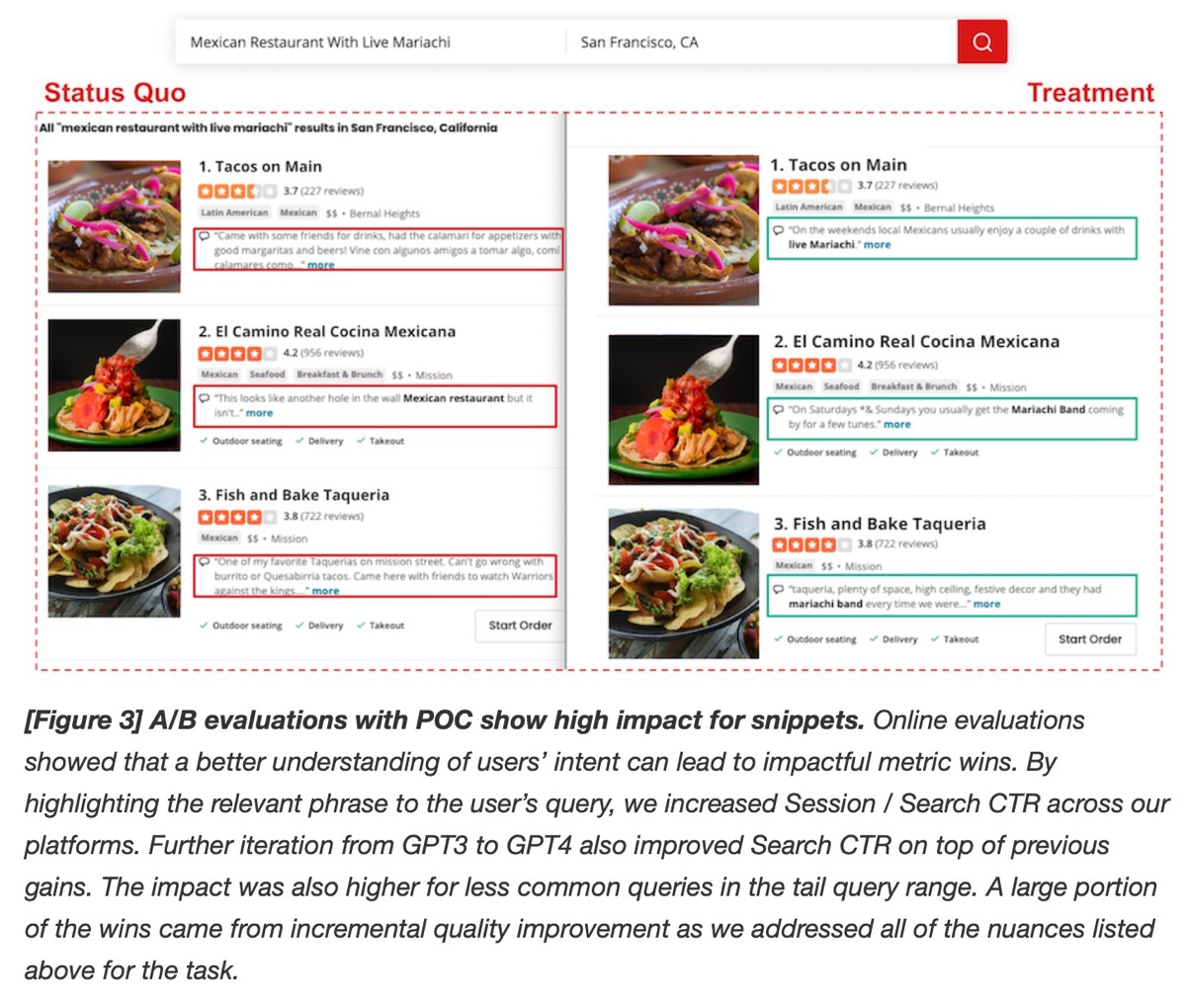
该团队分享了他们的方法——从初始 formulation 和 proof of concept (POC) 到 scale up。最初,他们评估了 LLM 的适用性并定义了 project 的范围。在 POC 期间,他们利用了 queries 的 power-law distribution,为覆盖大多数 traffic 的常见 queries 缓存了预先计算的 LLM responses。为了进行 scale,他们使用 GPT-4 outputs 创建了 golden datasets,并 finetuned 了较小的、具有成本效益的模型,例如 GPT-4o-mini。此外,像 BERT 和 T5 这样的实时模型解决了不太常见的 long-tail queries。
结果: Yelp 的 query segmentation 显著提高了 location intent detection,而增强的 review highlights 提高了 session 和 search click-through rates (CTR),尤其是有利于 long-tail queries。
Query Recommendations (Spotify) 详细介绍了他们如何构建 hybrid query recommendation system 以建议 exploratory search queries 以及直接结果。这种方法是必要的,以支持 Spotify 通过帮助用户探索这些内容,将其扩展到音乐以外的 podcasts、audiobooks 和多样化的 content types。
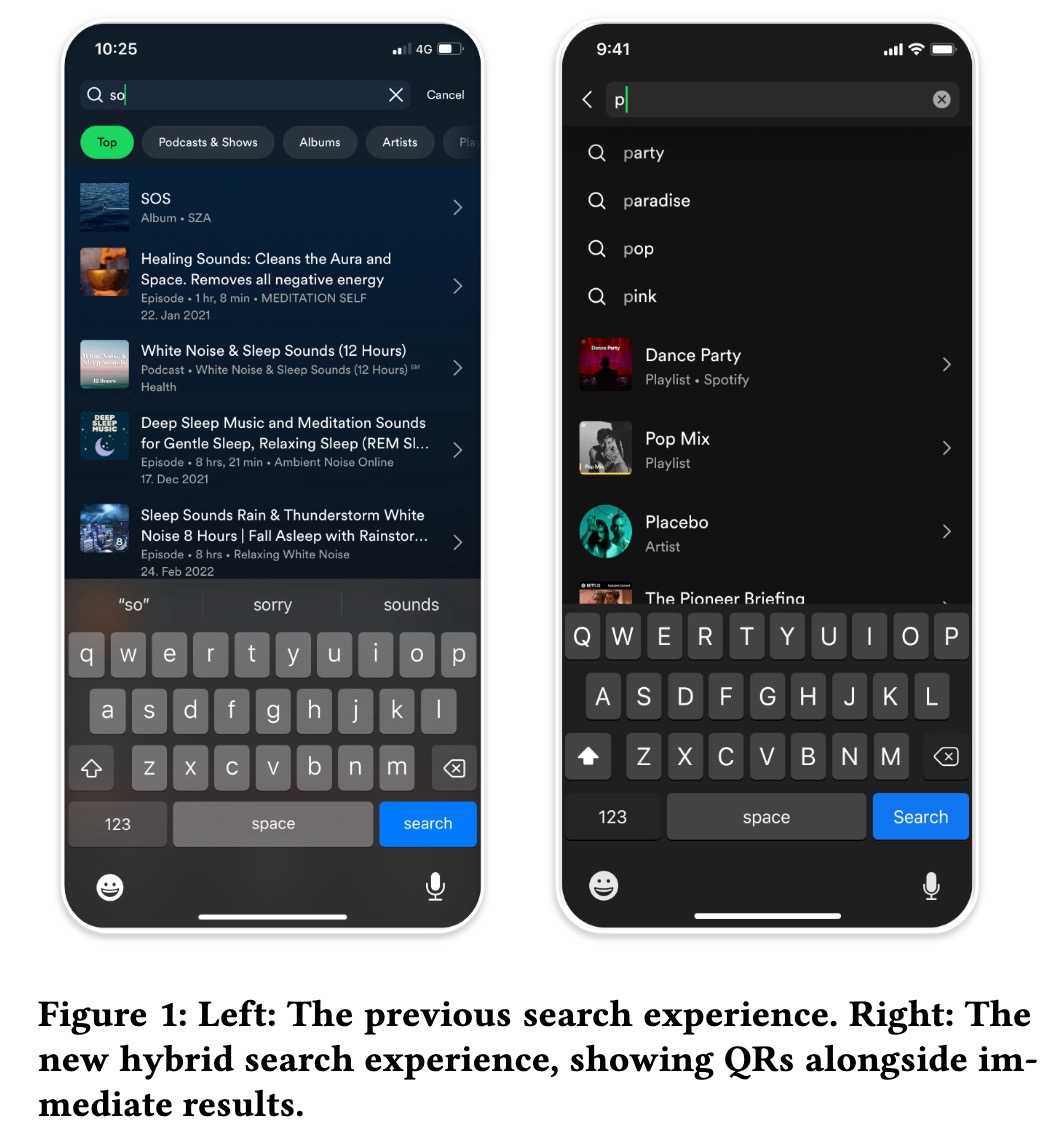
Spotify 通过以下方式生成 query suggestions:(i) 从 catalog titles、playlist names 和 podcasts 中提取,(ii) 从 search logs 中挖掘 suggestions,(iii) 利用用户最近的搜索,(iv) 应用 metadata 和 expansion rules(例如,“artist name” + “covers”),以及 (v) 通过 LLMs 生成 synthetic natural language queries。为了生成 synthetic queries,使用了 Doc2query 和 InPars 等技术来扩大 query variations,从而增强 exploratory searches 并减轻 retrievability bias。
然后,将 query suggestions 与 regular results 相结合,并通过针对 downstream user actions(例如,流式传输或将 content 添加到 playlists)优化的 point-wise ranker 进行 ranking。Ranker 使用诸如 lexical matching、query statistics、retrieval scores 和 user consumption patterns 等 features。为了进行 personalization,他们依赖于 users 和 query suggestion candidates 的 vector representations。
结果: Spotify 发现 exploratory intent queries 增加了 9%,每个用户的最大 query length 增加了 30%,平均 query length 增加了 10%——这表明 query recommendation 更新帮助用户表达了更复杂的 intents。Online ablation 显示 ranker 的删除导致 recommendations 的点击量下降了 20%,从而强调了它的重要性。
Playlist Search (Amazon) 讨论了 Amazon 如何将 LLMs 集成到 playlist search pipelines 中以解决挑战, 例如数据稀缺、metadata enrichment 和 scalable evaluation,同时减少对 manual annotation 的依赖。
为了丰富 metadata,他们使用 LLMs (LLM curator) 根据社区 playlists 的初始 15 首歌曲创建详细的 descriptions,从而捕获 themes、genres、activities 和 artists。(这些社区 playlists 通常只有 playlist title。)这解决了 community-generated content 中的数据稀缺问题。然后,Flan-T5-XL 进行了 finetuning 以 scale 这个 inference process。
他们还应用 LLMs 生成 paired with playlists (和 associated metadata) 的 synthetic queries,从而为 bi-encoder 模型创建 training data。这些 pairs 由 LLM 生成和评分 (LLM labeler),以保持平衡的 positive 和 negative examples。最后,他们使用 LLM (LLM judge),在 human annotations 和仔细的 prompting 的指导下,以确保 alignment,从而简化 evaluations。
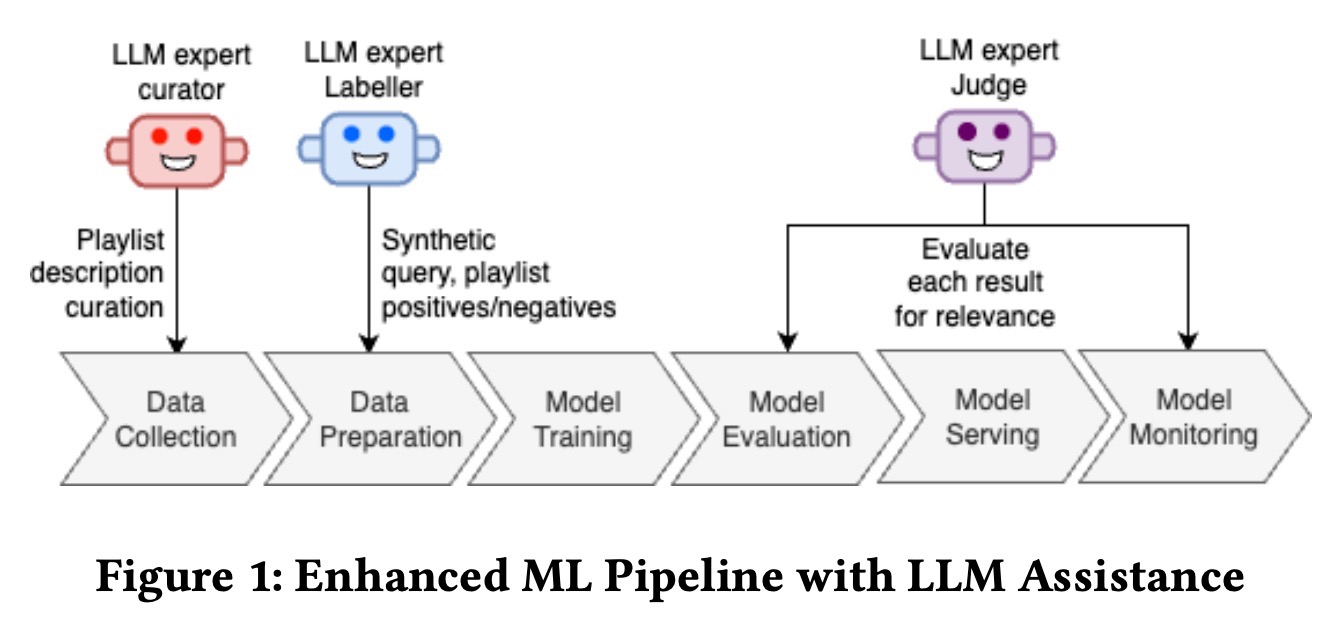
结果: LLMs 的集成导致 benchmarks、SEO 和 paraphrasing datasets 的 substantial double-digit recall improvements。总的来说,LLMs 的使用有助于克服数据稀缺和 evaluation scalability 的挑战,而无需大量的 manual effort。
• • •
Scaling Laws、迁移学习、蒸馏、LoRAs
另一个趋势是将来自大型语言模型 (LLMs) 和计算机视觉的训练方法应用于推荐系统。这包括探索 Scaling Laws(模型大小和数据量如何影响性能)、使用 knowledge distillation 将见解从大型模型迁移到较小的、高效的模型、应用跨域迁移学习来处理有限的数据,以及 parameter-efficient fine-tuning 技术,例如 LoRAs。
(👉 推荐阅读) Scaling Laws 调查了随着模型大小和数据 scale 的增加,基于 ID 的 sequential recommender models 的性能如何提高。 作者发现了一个可预测的 power-law relationship,其中性能随着模型和 datasets 大小的扩展而持续提高。
他们采用 decoder-only transformer 架构,试验了从 98.3K 到 0.8B parameters 的模型。他们在 MovieLens-20M 和 Amazon-2018 datasets 上评估了这些模型。对于 Amazon dataset,将来自 29 个 domains 的 interaction records 组合在一起,按时间顺序排序,并简化为仅包含 item IDs,而没有额外的 metadata。然后,将 datasets 格式化为每个包含 50 个 items 的固定长度序列;较短的序列被填充,较长的序列被截断。然后,对模型进行优化,以根据前 t 个 items 预测时间步长 t + 1 的下一个 item。
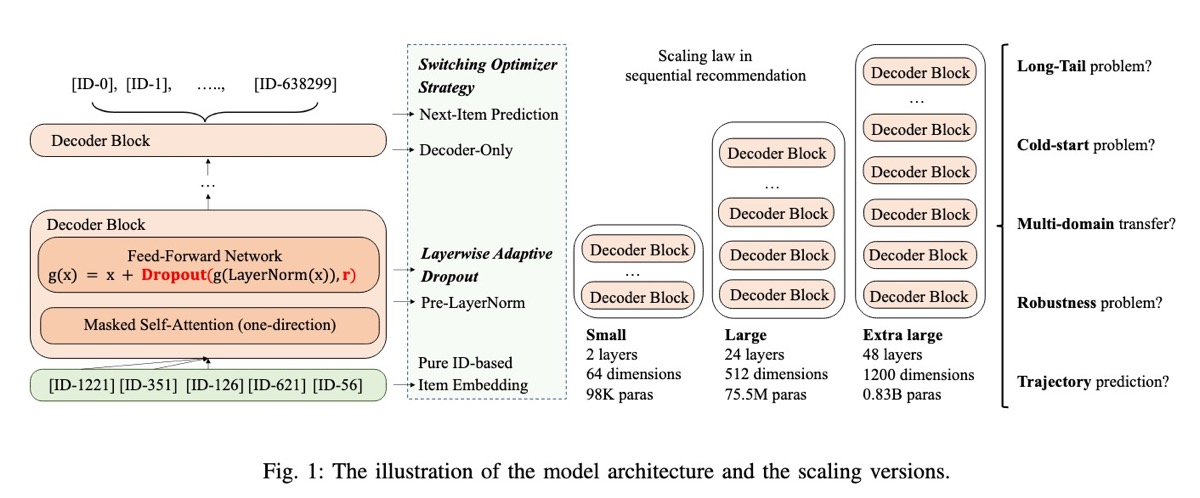
为了解决训练较大模型时的不稳定性,作者引入了两项关键改进。首先,他们实现了 layer-wise adaptive dropout,在较低的 layers 中应用较高的 dropout rates,而在较高的 layers 中应用较低的 dropout rates。直觉是较低的 layers 处理来自数据的直接输入,更容易 overfitting。相反,较高的 layers 构建更抽象的表示,因此受益于较少的 dropout,以减少可能导致 underfitting 的信息丢失。
第二个改进是在训练期间动态切换 optimizers——从 Adam 开始,然后在预定义的点切换到 stochastic gradient descent (SGD)。这种方法的动机是观察到 Adam 在早期训练阶段迅速减少了损失,但最终 SGD 实现了更好的收敛。
结果: 毫不奇怪,增加的模型容量(不包括 embedding parameters)持续降低了 cross-entropy loss。他们使用 power-law 曲线对其进行建模,并准确预测了较大模型(75.5M 和 0.8B params)的性能。类似地,他们观察到,即使使用较小的 datasets,较大的模型也可以实现较低的损失,而较小的模型需要更多的数据才能达到相当的性能。例如,与较大的 75.5M-parameter 模型(9.2M interactions)相比,较小的 98.3K-parameter 模型需要两倍的数据(18.5M interactions)才能获得相似的性能。
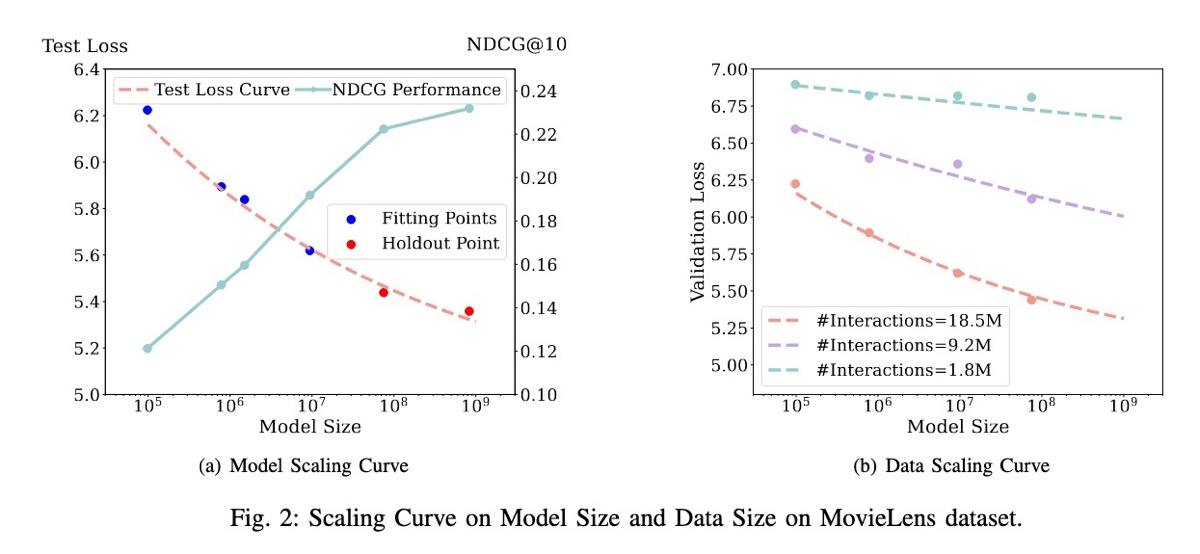
关于数据重复,大小为 75.5M 和 98.3K parameters 的模型在单个 training epoch 之后继续改进,在两个到五个 epochs 中观察到显着 gains。令人惊讶的是,更改模型形状对性能的影响最小。Ablation studies 表明,layer-wise adaptive dropout 和 optimizer switching 大大提高了较大模型(24 layers)的性能,但较小的模型(2 layers)基本上没有受到影响。对五个具有挑战性的 recommendation tasks 的进一步 ablations 强调了较大模型的优势,特别是对于 long-tail items 和 cold-start users。
PrepRec 展示了如何将 pretraining 调整为推荐系统,从而实现跨域的 zero-shot recommendations。 关键创新是利用仅从 user interactions 中导出的 item popularity dynamics,而不依赖于 item metadata。
PrepRec 使用在粗略(每月)和精细(每周)时间尺度上计算出的 popularity statistics。这些 popularity metrics 会转换为 percentiles,然后编码为 vector representations。此外,该模型还包含 user interactions 之间的相对时间间隔,并对 user sequence 中的每个 interaction 使用 fixed positional encoding。(恕我直言,虽然该方法有效,但它依赖于几种专门的技术——粗略与精细粒度的 periods、相对时间间隔和 positional encodings——这可能会限制其 generalizability。)
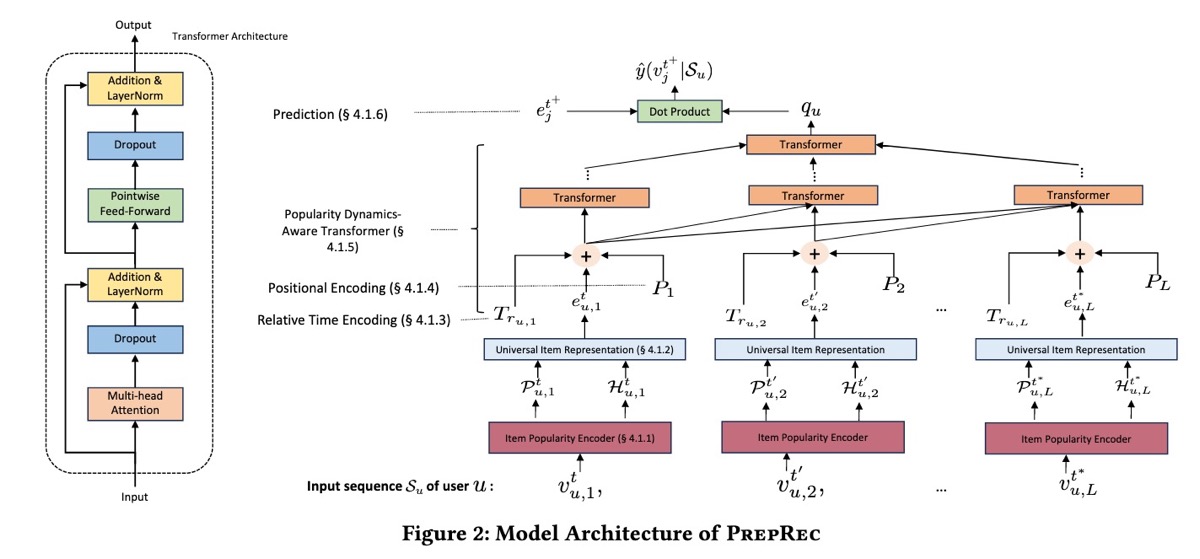
对于训练,PrepRec 将 binary cross-entropy 作为目标,并使用 Adam 进行优化。模型和 baselines 具有一致的设置:embedding dimension 为 50、最大 sequence length 为 200,batch size 为 128。在 inference 期间,PrepRec 从 target domain 计算 item popularity dynamics,然后在 pretrained 模型上通过 inference 生成 recommendations。
结果: PrepRec 实现了 promising 的 zero-shot 性能,与专门在 target domains 上训练的模型(如 SasREC 和 BERT4Rec)相比,只有较小的减少(2-6% recall@10)。在 target domains 上从头开始训练时,由于没有 item-specific embeddings,PrepRec 在 regular sequential recommendations 中与这些模型匹配或略微超过这些模型,尽管只使用了它们 1-5% 的 parameters。Ablations 表明,建模相对时间间隔可以显着提高性能,并且捕获粗略和精细粒度的 popularity trends 对于跟踪 evolving user interests 至关重要。
E-CDCTR (Meituan) 展示了通过使用 organic item data 来改进 advertising 中的 click-through rate (CTR) predictions 的迁移学习的潜力, 从而解决了 sparse ad data 的挑战。
E-CDCTR 具有三个组件:tiny pretraining model (TPM)、complete pretraining model (CPM) 和 advertising CTR model (A-CTR)。TPM 是一个 lightweight 模型,只有 embedding 和 MLP layers,每月在六个月的 organic impressions 和 clicks 上进行训练。它通过 historical user 和 item embeddings 捕获长期 collaborative filtering signals。Features 包括 user 和 item IDs、category IDs 等。
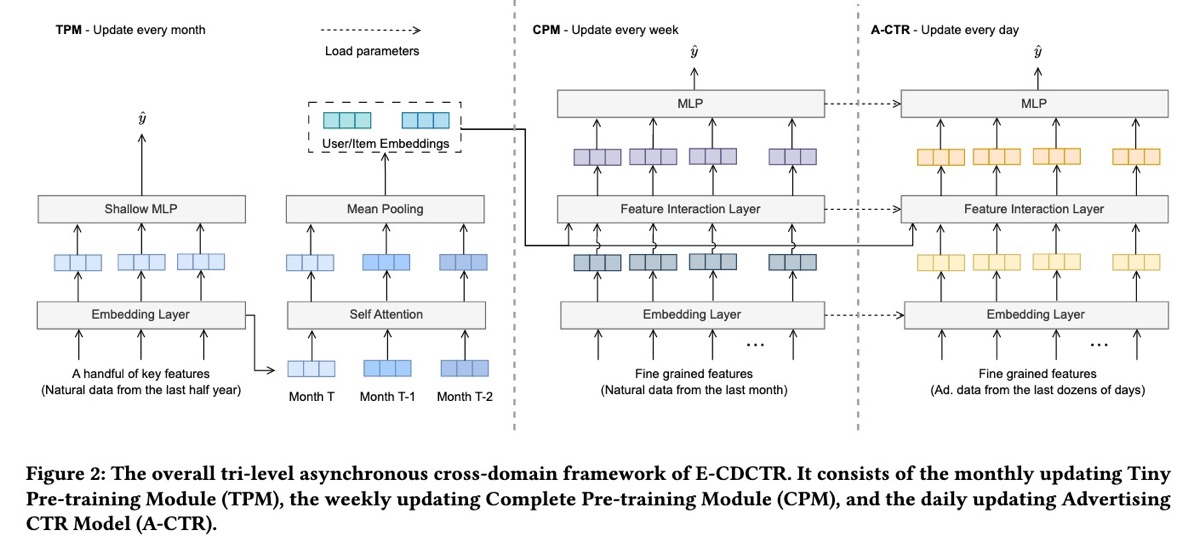
接下来,CPM 使用来自最近一个月的 organic data 和 TPM 学习到的 user 和 item embeddings,每周对 CTR 模型进行 pretrain。最后,A-CTR 模型从 CPM 初始化,并在 advertising-specific data 上每天进行 finetuning。A-CTR 还使用来自 TPM 的 user 和 item embeddings。A-CTR 还使用更丰富的 features,例如 user behavior sequences、user context、item metadata 和 feature interactions,从而产生了更 sophisticated 的模型架构,其中包括 sequential input、feature crosses 和更大的 MLP layer。
对于 online inference,E-CDCTR 采用 TPM 从过去三个月生成的 user 和 item embeddings。然后,A-CTR 模型使用这些 embeddings 来预测 advertising CTR。(作者提到了使用 self-attention 来组合 embeddings,但提供的有关训练它的详细信息有限。)
结果: E-CDCTR 优于跨域 baselines,例如 KEEP、CoNet、DARec 和 MMoE。Ablation studies 确认了 TPM 和 CPM 的价值,CPM 具有更 substantial 的影响。此外,将 historical embeddings 从一个月扩展到三个月进一步增强了性能,而简单地将 advertising data 与 organic data 合并并没有产生改进。
Bridging the Gap (YouTube) 分享了在 YouTube 的 large-scale personalized video recommendations 中应用 knowledge distillation 的见解。
他们的 recommenders 是 multi-objective pointwise models,用于 ranking videos。这些模型同时优化短期目标(如 video CTR)和长期目标(如用户的 estimated long-value value)。他们的模型通常采用 teacher-student 设置,其中 teacher 和 student 模型共享相似的架构,但 teacher 模型比 student 模型大 2 - 4 倍。
但是,teacher 和 student 之间的 distribution shifts 可能会导致 biases。为了解决这个问题,作者提出了一种 auxiliary distillation strategy——不是直接使用 teacher 的 predictions(soft labels),而是通过单独的 task logits 将 hard labels 从 soft teacher predictions 中解耦出来。这使 student 模型可以有效地从 teacher 那里学习,而无需继承 unwanted biases。
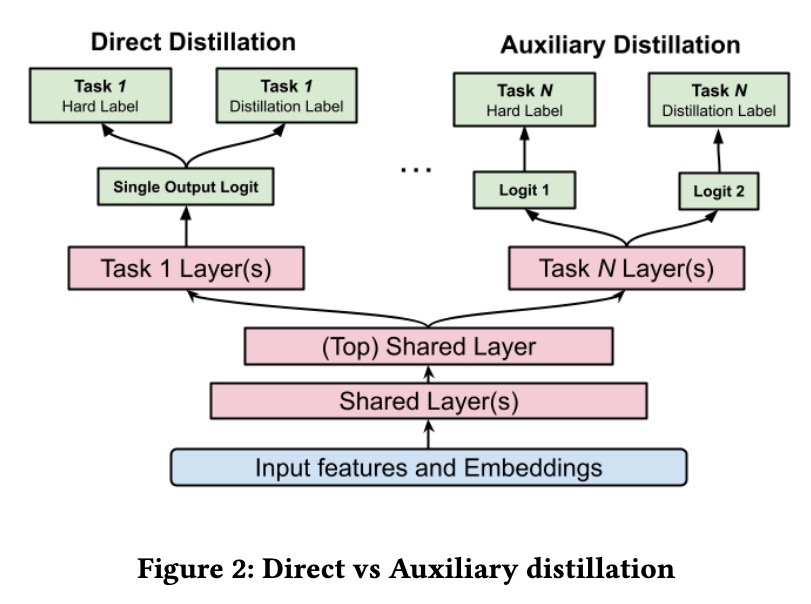
为了摊销训练大型 teacher 模型的成本,他们使用单个 teacher 来改进多个 student 模型。因此,单个 teacher 模型可以为各种专门的 recommendation tasks 提供 distilled knowledge,从而减少冗余和计算开销。Teacher labels 存储在 columnar database 中,该数据库优先考虑 student 在训练期间的读取性能。
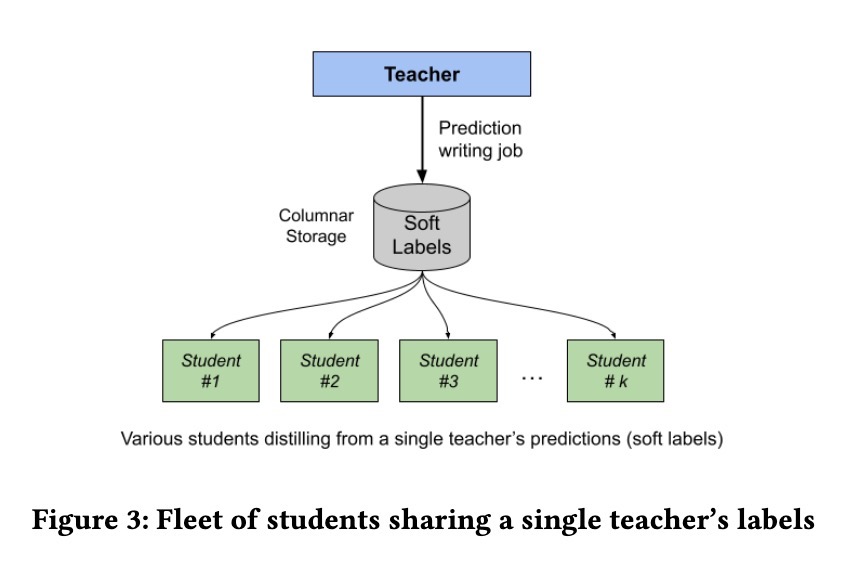
结果: 与直接蒸馏方法相比,auxiliary distillation strategy 在 E(LTV) prediction 方面提高了 0.4%,而直接蒸馏方法的性能与没有蒸馏的模型相似。这证实了 auxiliary distillation 方法在减少 teacher noise 方面的有效性。在 teacher size 的 ablation studies 中,即使是 modest 的 teacher(2 倍于 student 的大小)也带来了有意义的改进(+0.42% engagement,+0.34% satisfaction),而 4 倍 teacher 则带来了 +0.43% engagement 和 +0.46% satisfaction。
类似地,Self-Auxiliary Distillation (Google) 引入了一个蒸馏框架,旨在提高 large-scale recommendation models 的 sample efficiency。