AITER:用于 ROCm 的 AI Tensor Engine
AITER:用于 ROCm 的 AI Tensor Engine

2025年3月21日,作者:Shekhar Pandey, Liz Li, Carlus Huang, Lingpeng Jin, Anshul Gupta.
阅读时长 5 分钟 | 总字数 1331 字
在使用 GPU 时,性能优化至关重要,尤其是在涉及人工智能的任务中,这些任务可能非常耗费资源。为了充分利用先进硬件的功能,必须掌握优化策略,并确保有效利用每一个可用的资源。 在本博客中,我们将概述 AMD 的 AI Tensor Engine for ROCm (AITER),并向您展示将 AITER 内核集成到基本 LLM 训练和推理工作负载中是多么容易。 AITER 帮助开发人员专注于创建算子,同时允许客户将此算子集合无缝集成到他们自己的私有、公共或任何自定义框架中。
什么是用于 ROCm 的 AI Tensor Engine (AITER)
AMD 正在推出 AI Tensor Engine for ROCm (AITER),这是一个集中式仓库,其中包含旨在加速各种 AI 工作负载的高性能 AI 算子 [1]。 AITER 作为一个统一的平台,客户可以轻松地查找优化的算子并将其集成到他们现有的框架中——无论是私有的、公共的还是自定义构建的,正如您在下面的图 1 中看到的那样。 借助 AITER,AMD 简化了优化的复杂性,使用户能够最大限度地提高性能,同时提供灵活性以满足不同的 AI 要求。
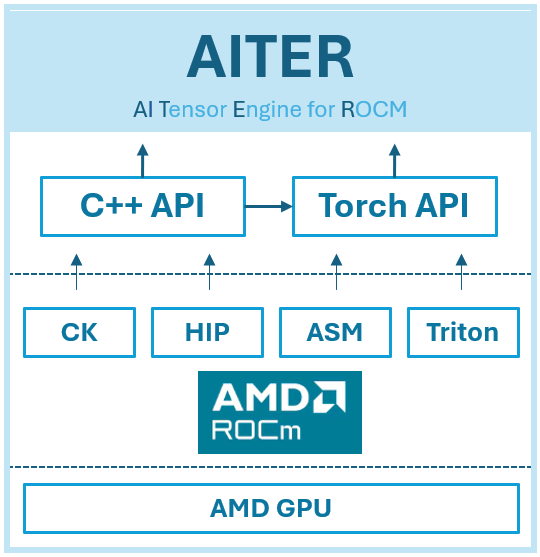
图 1:AITER 的块级图
主要特性
- 多功能且用户友好的设计: AITER 的架构经过精心设计,具有多功能性和易用性,可以无缝集成到各种工作流程和系统中。
- 双重编程接口: 在最高抽象级别,AITER 支持两个主要接口——C++ 和 Python (Torch API)。 这种双接口方法使 AITER 非常易于访问,可满足具有不同编程偏好和技能组合的开发人员的需求。
- 强大的内核基础设施: 在用户级 API 之下,AITER 采用强大而稳健的内核基础设施。 该基础设施建立在各种底层技术之上,包括 Triton、CK (Compute Kernel)、ASM (Assembly) 和 HIP (Heterogeneous Interface for Portability)。
- 全面的内核支持: AITER 内核生态系统有效地支持各种计算任务,例如推理工作负载、训练内核、GEMM (General Matrix Multiplication) 操作和通信内核。 这种全面的内核支持确保用户可以自信地处理复杂且资源密集型的 AI 任务。
- 可定制和优化的内核生态系统: 凭借其丰富的内核环境,AITER 允许开发人员执行专门针对其应用程序的定制优化。 这种灵活性有助于开发人员绕过或克服架构限制,从而显着提高性能和适应性。
- 与 AMD ROCm 无缝集成: AITER 的核心是利用 AMD 的 ROCm,确保优化内核和 AMD GPU 之间的有效桥接。 这种集成释放了 AMD GPU 的全部潜力和峰值性能,从而在各种 AI 工作负载中提供最佳效率。
通过结合用户友好的界面、广泛的内核功能和强大的 GPU 集成,AITER 使开发人员能够在他们的 AI 应用程序中实现最高的效率和性能。
AITER 的性能提升
通过利用 AITER 的高级优化,用户可以在各种 AI 操作中体验到显着的性能改进:
- AITER 块级 GEMM: 实现高达 2 倍的性能提升 [2],从而大大加速了通用矩阵乘法任务。
- AITER 块级融合 MoE: 提供高达 3 倍的性能提升 [3],优化了专家混合 (MoE) 操作的效率。
- AITER MLA for decode: 提供令人印象深刻的 高达 17 倍的性能提升[4],从而显着提高了解码效率。
- AITER MHA for prefill: 实现高达 14 倍的性能提升[5],从而显着提高了预填充阶段的多头注意力 (MHA) 性能。
AITER 在 vLLM/SGLang 中对 DeepSeek V3/R1 的集成
AITER 集成到 vLLM/SGLang 中,用于 DeepSeek v3/r1 模型,这带来了总 token 吞吐量(每秒 token 数,tok/s)的显着提升。 在 AITER 集成之前,吞吐量为 6484.76 tok/s。 在整合 AITER 的优化之后,吞吐量显着增加到 13704.36 tok/s,这标志着处理速度提高了 2 倍以上[6],如下面的图 2 所示。
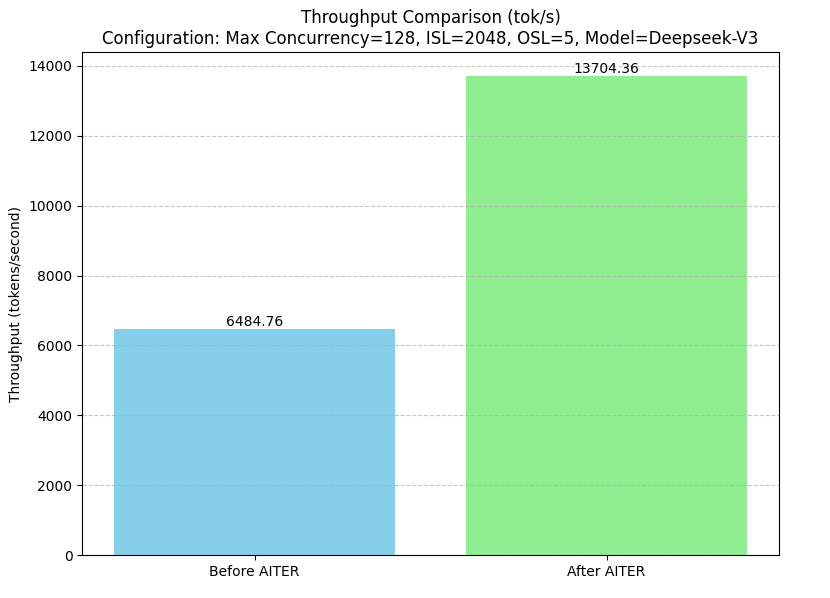
图 2.吞吐量比较:在 AMD Instinct™ MI300X 上 DeepSeek 模型上 SGLang 中集成 AITER 之前和之后。
使用 AITER 运行 Deepseek
使用 vLLM
VLLM_SEED=42VLLM_MLA_DISABLE=0VLLM_USE_TRITON_FLASH_ATTN=0\
VLLM_USE_ROCM_FP8_FLASH_ATTN=0VLLM_FP8_PADDING=1VLLM_USE_AITER_MOE=1\
VLLM_USE_AITER_BLOCK_GEMM=1VLLM_USE_AITER_MLA=0vllmserve\
/workspace/models/DeepSeek-R1\
--host0.0.0.0\
--port8000\
--api-keyabc-123\
--tensor-parallel-size8\
--trust-remote-code\
--seed42
使用 SGLang
CK_BLOCK_GEMM=1SGLANG_ROCM_AITER_BLOCK_MOE=1RCCL_MSCCL_ENABLE=0\
DEBUG_HIP_BLOCK_SYN=1024GPU_FORCE_BLIT_COPY_SIZE=64\
python3-msglang.launch_server--model/models/DeepSeek-V3/\
--tp8--trust-remote-code
AITER 入门
要开始使用 AITER,请按照以下简单的安装步骤操作:
- 克隆存储库:
gitclonehttps://github.com/ROCm/aiter.git
cdAITER
- 在 AITER 根目录下,运行以下命令以开发模式安装库:
python3setup.pydevelop
使用 AITER 实现一个简单的线性层
让我们演示一下如何使用 AITER 的 tgemm 函数来实现 PyTorch 线性层的简单副本。
from aiter.tuned_gemm import tgemm
import torch
class LinearLayer(torch.nn.Module):
def **init**(self, in_features, out_features):
super(LinearLayer, self).**init**()
self.weight = torch.nn.Parameter(torch.randn(out_features, in_features).cuda())
self.bias = torch.nn.Parameter(torch.randn(out_features).cuda())
def forward(self, input):
input = input.cuda()
return [tgemm.mm](http://tgemm.mm/)(input, self.weight, self.bias, None, None)
# Define input size and layer size
in_features = 128
out_features = 64
batch_size = 32
# Create custom AITER linear layer
layer = LinearLayer(in_features, out_features).cuda()
input_tensor = torch.randn(batch_size, in_features).cuda()
# Get output from AITER linear layer
output_aiter = layer(input_tensor)
# Create PyTorch linear layer with same weights and bias
pytorch_layer = torch.nn.Linear(in_features, out_features).cuda()
pytorch_layer.weight = torch.nn.Parameter(layer.weight.clone())
pytorch_layer.bias = torch.nn.Parameter(layer.bias.clone())
# Get output from PyTorch linear layer
output_pytorch = pytorch_layer(input_tensor)
# Compare outputs
print("Output difference (max absolute error):", torch.max(torch.abs(output_aiter - output_pytorch)))
print("Output difference (mean absolute error):", torch.mean(torch.abs(output_aiter - output_pytorch)))
在日常工作负载中使用 AITER 非常简单,下面提到了一些其他的低级内核 API,可以用于集成到你的架构中。
内核 | API
---|---
MHA (Flash Attention) | aiter.flash_attn_func()
LayerNorm | aiter.layer_norm()
LayerNormFusedResidualAdd | aiter.layernorm2d_with_add_asm()
RoPE forward | aiter.rope_fwd()
RoPE backward | aiter.rope_bwd()
RMSNorm | aiter.rms_norm()
MLA Decode | aiter.ops.triton.mla_decode()
AITER 不仅限于上面提到的 API,还有很多可用的功能,如下表所示,而且很快就会推出更多功能。
功能 | 类型 (F=Forward, B=Backward) | 详情 ---|---|--- Prefill Attention | F/B | Fav3 FWD FP16/BF16 Fav3 BWD FP16/BF16 MLA FP16/BF16 FA FP8 FWD+BWD (Block-Scale) Chunked-prefill Decode Attention | F | Paged Attention FP16/BF16 Paged Attention FP8 per-tensor quant Paged Attention FP8/INT8 with KV per-token quant KVCache Update & Rotary Batched Decoding MLA Decoding Fused-Moe | F | Moe-Sorting kernel and tiling solution FP16/BF16 per-token Fused-Moe FP8/INT8 per-token Fused-Moe FP8 per-tensor Fused-Moe FP8/INT4 per-tensor Fused-Moe Fused-FFN Low Precision Gemm | F | FP8 per-token/channel Gemm FP8 Block Scale Gemm INT8 weight-only Gemm Distributed Gemm | F/B | Distributed GEMM Normalization and Fusion | F | Layernorm+quant/shortcut RMSNorm+quant/shortcut Custom Comm. | F | AR/AG fused with normalization AR/AG quantized, Optimized hipgraph support Conv2d/2d | F/B | FP16/BF16 fwd/bwd/wrw Fusion with bias/activation, etc.
总结
在本博客中,我们介绍了 AMD 的 AI Tensor Engine for ROCm (AITER),这是一个集中式的高性能 AI 算子仓库,旨在显着加速 AMD GPU 上的 AI 工作负载。 AITER 已经通过大幅加速 AI 工作负载并显着提高效率和性能展示了其价值。 AMD 仍然致力于持续创新,目前正在进行许多进一步的增强和优化工作。 该路线图包括更大的进步,有望在 AI 计算中树立新标准。 请继续关注 AMD,因为它将继续突破性能的界限,确保机器学习工程师可以始终如一地实现更快、更高效、更强大的 AI 解决方案。
附加资源
AITER GitHub:ROCm/aiter
免责声明
第三方内容由拥有该内容的第三方直接授权给您,而不是由 AMD 授权给您。 所有链接的第三方内容均按“原样”提供,不提供任何形式的保证。 使用此类第三方内容的风险由您自行承担,在任何情况下,AMD 均不对任何第三方内容对您承担责任。 您承担所有风险,并对因您使用第三方内容而可能造成的任何损害承担全部责任。
[1] AI 算子:优化的数学函数或计算内核,用于执行基本的 AI 和机器学习任务,例如矩阵乘法、卷积和激活,这些对于加速 AI 工作负载至关重要。
[2] 平均而言,配置了 AMD Instinct™ MI300X GPU 的系统表明,AITER 块级 GEMM 提供了 2 倍的性能提升,从而大大加速了通用矩阵乘法任务。 AMD 在 2025 年 3 月 11 日完成的测试,结果可能会因配置、使用情况、软件版本和优化而异。
系统配置:AMD Instinct™ MI300X 平台 - 系统型号:Supermicro GPU A+ Server AS - 8125GS-TNMR2 - CPU:2x AMD EPYC 9654 96 核处理器(2 个插槽,每个插槽 96 个内核,每个内核 2 个线程) - NUMA 配置:每个插槽 2 个 NUMA 节点 - 内存:2.3 TiB(24 个 DIMM,4800 mts,96 GiB/DIMM) - 磁盘:根驱动器 + 数据驱动器组合:- 2x 960GB Samsung MZ1L2960HCJR-00A07 - 4x 3.84TB Samsung MZQL23T8HCLS-00A07 - GPU:8x AMD MI300X 192GB HBM3 750W - 主机操作系统:带有 Linux 内核 5.15.0-116-generic 的 Ubuntu 22.04.4 LTS。 - 系统 BIOS:3.2 - 系统 BIOS 供应商:American Megatrends International, LLC. - 主机 GPU 驱动程序(amdgpu 版本):6.10.5
[3] 平均而言,配置了 AMD Instinct™ MI300X GPU 的系统表明,AITER 块级融合 MoE 提供了 3 倍的性能提升,从而优化了专家混合 (MoE) 操作的效率。 AMD 在 2025 年 3 月 11 日完成的测试,结果可能会因配置、使用情况、软件版本和优化而异。
系统配置:AMD Instinct™ MI300X 平台 - 系统型号:Supermicro GPU A+ Server AS - 8125GS-TNMR2 - CPU:2x AMD EPYC 9654 96 核处理器(2 个插槽,每个插槽 96 个内核,每个内核 2 个线程) - NUMA 配置:每个插槽 2 个 NUMA 节点 - 内存:2.3 TiB(24 个 DIMM,4800 mts,96 GiB/DIMM) - 磁盘:根驱动器 + 数据驱动器组合:- 2x 960GB Samsung MZ1L2960HCJR-00A07 - 4x 3.84TB Samsung MZQL23T8HCLS-00A07 - GPU:8x AMD MI300X 192GB HBM3 750W - 主机操作系统:带有 Linux 内核 5.15.0-116-generic 的 Ubuntu 22.04.4 LTS。 - 系统 BIOS:3.2 - 系统 BIOS 供应商:American Megatrends International, LLC. - 主机 GPU 驱动程序(amdgpu 版本):6.10.5
[4] 平均而言,配置了 AMD Instinct™ MI300X GPU 的系统表明,AITER MLA for decode 提供了 17 倍的性能提升,从而提高了解码效率。 AMD 在 2025 年 3 月 11 日完成的测试,结果可能会因配置、使用情况、软件版本和优化而异。
系统配置:AMD Instinct™ MI300X 平台 - 系统型号:Supermicro GPU A+ Server AS - 8125GS-TNMR2 - CPU:2x AMD EPYC 9654 96 核处理器(2 个插槽,每个插槽 96 个内核,每个内核 2 个线程) - NUMA 配置:每个插槽 2 个 NUMA 节点 - 内存:2.3 TiB(24 个 DIMM,4800 mts,96 GiB/DIMM) - 磁盘:根驱动器 + 数据驱动器组合:- 2x 960GB Samsung MZ1L2960HCJR-00A07 - 4x 3.84TB Samsung MZQL23T8HCLS-00A07 - GPU:8x AMD MI300X 192GB HBM3 750W - 主机操作系统:带有 Linux 内核 5.15.0-116-generic 的 Ubuntu 22.04.4 LTS。 - 系统 BIOS:3.2 - 系统 BIOS 供应商:American Megatrends International, LLC. - 主机 GPU 驱动程序(amdgpu 版本):6.10.5
[5] 平均而言,配置了 AMD Instinct™ MI300X GPU 的系统表明,带有 AITER MHA for prefill 的系统显示了 14 倍的性能提升,从而提高了预填充阶段的多头注意力 (MHA) 性能。AMD 在 2025 年 3 月 11 日完成的测试,结果可能会因配置、使用情况、软件版本和优化而异。
系统配置:AMD Instinct™ MI300X 平台 - 系统型号:Supermicro GPU A+ Server AS - 8125GS-TNMR2 - CPU:2x AMD EPYC 9654 96 核处理器(2 个插槽,每个插槽 96 个内核,每个内核 2 个线程) - NUMA 配置:每个插槽 2 个 NUMA 节点 - 内存:2.3 TiB(24 个 DIMM,4800 mts,96 GiB/DIMM) - 磁盘:根驱动器 + 数据驱动器组合:- 2x 960GB Samsung MZ1L2960HCJR-00A07 - 4x 3.84TB Samsung MZQL23T8HCLS-00A07 - GPU:8x AMD MI300X 192GB HBM3 750W - 主机操作系统:带有 Linux 内核 5.15.0-116-generic 的 Ubuntu 22.04.4 LTS。 - 系统 BIOS:3.2 - 系统 BIOS 供应商:American Megatrends International, LLC. - 主机 GPU 驱动程序(amdgpu 版本):6.10.5
[6] 平均而言,配置了 AMD Instinct™ MI300X GPU 的系统表明,在 AITER 集成之前,吞吐量为 6484.76 tok/s。 在整合 AITER 的优化之后,吞吐量显着增加到 13704.36 tok/s,这标志着处理速度提高了 2 倍以上。 AMD 在 2025 年 3 月 11 日完成的测试,结果可能会因配置、使用情况、软件版本和优化而异。
系统配置:AMD Instinct™ MI300X 平台 - 系统型号:Supermicro GPU A+ Server AS - 8125GS-TNMR2 - CPU:2x AMD EPYC 9654 96 核处理器(2 个插槽,每个插槽 96 个内核,每个内核 2 个线程) - NUMA 配置:每个插槽 2 个 NUMA 节点 - 内存:2.3 TiB(24 个 DIMM,4800 mts,96 GiB/DIMM) - 磁盘:根驱动器 + 数据驱动器组合:- 2x 960GB Samsung MZ1L2960HCJR-00A07 - 4x 3.84TB Samsung MZQL23T8HCLS-00A07 - GPU:8x AMD MI300X 192GB HBM3 750W - 主机操作系统:带有 Linux 内核 5.15.0-116-generic 的 Ubuntu 22.04.4 LTS。 - 系统 BIOS:3.2 - 系统 BIOS 供应商:American Megatrends International, LLC. - 主机 GPU 驱动程序(amdgpu 版本):6.10.5