在 Agentic Coding 中开发者技能的角色
Topics
Architecture Refactoring Agile Delivery Microservices Data Testing DSL
about me
content
Videos Content Index Board Games Photography
Thoughtworks
follow
RSS Mastodon LinkedIn X (Twitter) BGG
最新备忘录:在 Agentic Coding 中开发者技能的角色 2025年3月25日
随着 agentic coding 助手变得越来越强大,人们的反应也各不相同。有些人从最近的进展中推断说:“一年之内,我们就再也不需要开发者了。”另一些人则对 AI 生成代码的质量以及如何为初级开发者应对这种不断变化的局面提出担忧。
在过去的几个月里,我经常使用 Cursor、Windsurf 和 Cline 中的 agentic 模式,几乎完全用于更改现有代码库(而不是从头开始创建 Tic Tac Toe)。我对 IDE 集成方面的最新进展印象深刻,这些集成大大提升了这些工具协助我的方式。它们:
- 执行测试和其他开发任务,并尝试立即修复发生的错误
- 自动发现并尝试修复 linting 和编译错误
- 可以进行网络研究
- 有些甚至具有浏览器预览集成,可以发现控制台错误或检查 DOM 元素
所有这些都促成了与 AI 令人印象深刻的协作会话,有时可以帮助我在创纪录的时间内构建功能并解决问题。
但是。
即使在那些成功的会话中,我也一直在干预、纠正和指导。而且我经常决定甚至不提交这些更改。在本备忘录中,我将列出具体指导示例,以说明在 "受监督的代理" 模式下,开发人员的经验和技能扮演什么角色。这些例子表明,虽然进展令人印象深刻,但我们仍然离 AI 为非平凡任务自主编写代码相差甚远。它们也给出了开发人员在可预见的将来仍然必须应用的技能类型的一些想法。我们需要保存和培训这些技能。
我不得不指导的地方
我想先说明的是,AI 工具通常非常糟糕地处理我正在列出的事情。通过额外的提示或自定义规则,可以轻松缓解其中的一些示例。缓解,但不能完全控制:LLM 经常不听从提示的字面意思。编码会话的时间越长,就越容易出现问题。因此,无论提示多么严格,或者集成了多少上下文提供程序到编码助手中,我所列出的内容都绝对存在不可忽略的发生概率。
我将我的例子分为3种类型的影响范围:AI 错误:
a. 减慢了我的开发速度和提交时间,而不是加快了它(与没有辅助的编码相比),或者 b. 在该迭代中为团队流程制造了摩擦,或者 c. 对代码的长期可维护性产生负面影响。
影响范围越大,团队捕获这些问题所需的反馈循环就越长。
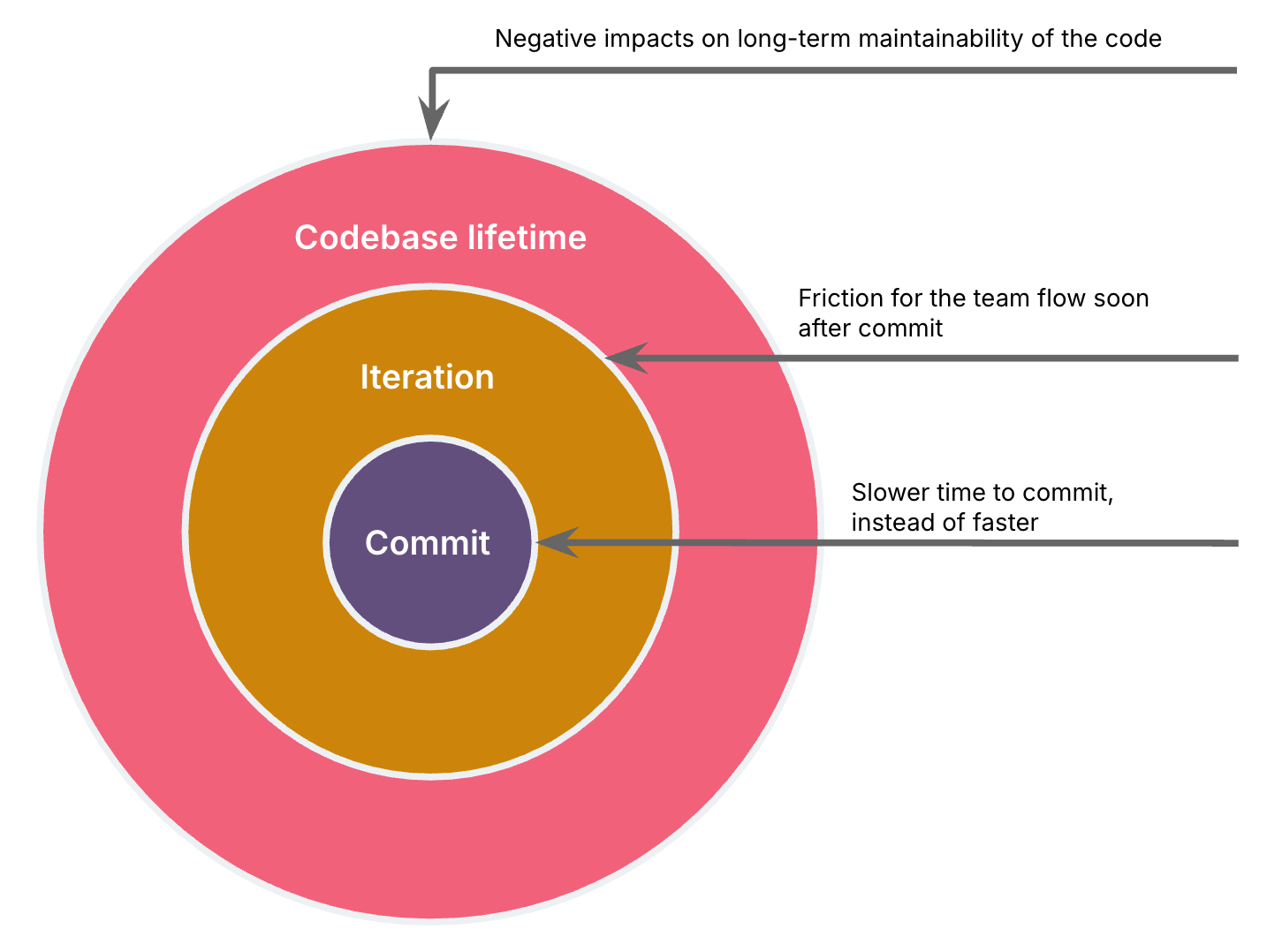
影响范围:提交时间
这些是 AI 阻碍我的情况多于帮助我的情况。这实际上是最不麻烦的影响范围,因为这是最明显的失败模式,而且更改很可能甚至不会进入提交。
没有可用的代码
有时,我需要进行干预才能使代码能够工作,简单明了。因此,我的经验要么发挥了作用,因为我可以快速纠正错误之处,要么是因为我早早知道什么时候放弃,要么开始与 AI 进行新的会话,要么自己解决问题。
对问题的误诊
当 AI 误诊问题时,它经常会陷入兔子洞。在很多情况下,我可以根据我以前处理这些问题的经验将工具从这些兔子洞的边缘拉回来。
例子:它假设 Docker 构建问题是由于该 Docker 构建的架构设置引起的,并基于该假设更改了这些设置 - 而实际上,该问题源于复制为错误架构构建的node_modules。由于这是我多次遇到的典型问题,我可以快速捕获它并重定向。
影响范围:迭代中的团队流程
此类别是关于在没有审查和干预的情况下,导致在交付迭代期间团队出现摩擦的情况。我在许多交付团队工作的经验有助于我在提交之前纠正这些错误,因为我多次遇到这些二阶效应。我认为即使使用 AI,新的开发人员也会通过陷入这些陷阱并从中学习来学习这一点,就像我所做的那样。问题是,AI 增加的编码吞吐量是否会加剧这种情况,以至于团队无法以可持续的方式吸收它。
过多的前期工作
AI 经常进行广泛的工作,而不是增量地实施可用的功能片段。这有在意识到技术选择不可行或对功能需求的理解有误之前浪费大量前期工作的风险。
例子:在前端技术堆栈迁移任务期间,它试图一次转换所有 UI 组件,而不是从一个组件和与后端集成的垂直切片开始。
使用蛮力修复而不是根本原因分析
AI 有时会采取蛮力方法来解决问题,而不是诊断出实际导致问题的原因。这会将根本问题延迟到后面的阶段,并延迟到其他必须在没有原始更改上下文的情况下进行分析的团队成员。
例子:当在 Docker 构建期间遇到内存错误时,它增加了内存设置,而不是质疑为什么首先要使用这么多内存。
使开发人员工作流程复杂化
在一种情况下,AI 生成的构建工作流程创建了糟糕的开发人员体验。推动这些更改几乎会立即对其他团队成员的开发工作流程产生影响。
例子:引入两个命令来运行应用程序的前端和后端,而不是一个。
例子:未能确保热重载工作。
例子:使我和 AI 本身感到困惑的复杂构建设置。
例子:处理 Docker 构建中的错误,而不考虑如何在构建过程中更早地捕获这些错误。
误解或不完整的要求
有时,当我不详细描述功能需求时,AI 会得出错误的结论。抓住这一点并重定向代理不一定需要特殊的开发经验,只需要注意。但是,这种情况经常发生在我身上,并且是一个例子,说明完全自主的代理如何在没有开发人员观看它们工作并在开始而不是在结束时进行干预的情况下失败。无论是没有思考的开发人员,还是完全自主的代理,都将在故事生命周期中稍后发现这种误解,并且会导致大量来回纠正工作。
影响范围:长期可维护性
这是最阴险的影响范围,因为它具有最长的反馈循环,这些问题可能仅在几周或几个月后才会被发现。这些是代码现在可以正常工作,但将来更改会更加困难的情况。不幸的是,这也是我超过 20 年的编程经验最重要的类别。
冗长且多余的测试
虽然 AI 在生成测试方面非常出色,但我经常发现它会创建新的测试函数,而不是向现有测试函数添加断言,或者添加过多的断言,即某些断言已经在其他测试中涵盖了。与经验不足的程序员的直觉相反,更多的测试不一定更好。重复的测试和断言越多,维护就越困难,并且测试变得越脆弱。这可能会导致这样一种状态:每当开发人员更改部分代码时,多个测试都会失败,从而导致更多的开销和挫败感。我曾尝试通过自定义指令来缓解此行为,但这种情况仍然经常发生。
缺乏重用
AI 生成的代码有时缺乏模块化,这使得在应用程序的其他地方应用相同的方法变得困难。
例子:没有意识到 UI 组件已经在其他地方实现,因此创建了重复的代码。
例子:使用内联 CSS 样式而不是 CSS 类和变量
过度复杂或冗长的代码
有时,AI 会生成过多的代码,需要我手动删除不必要的元素。这可能是技术上不必要的代码,并且使代码更复杂,这会在将来更改代码时导致问题。或者,它可能比我当前实际需要的功能更多,这会增加不必要代码行的维护成本。
例子:每次 AI 为我进行 CSS 更改时,我都会然后逐个删除有时是大量的冗余 CSS 样式。
例子:AI 生成了一个新的 Web 组件,可以动态显示 JSON 对象中的数据,并且构建了一个当时不需要的非常详细的版本。
例子:在重构过程中,它未能识别现有的依赖项注入链并引入了不必要的额外参数,从而使设计更加脆弱且难以理解。例如,它为服务构造函数引入了一个不必要的参数,因为已经注入了提供该值的依赖项。(value = service_a.get_value(); ServiceB(service_a, value=value))
结论
这些经验意味着,根据我个人的想象,我们将在一年内拥有能够自主编写 90% 代码的 AI。它会协助编写 90% 的代码吗?也许。对于某些团队和某些代码库。它今天在 80% 的情况下帮助了我(在一个中等复杂度、相对较小的 15K LOC 代码库中)。
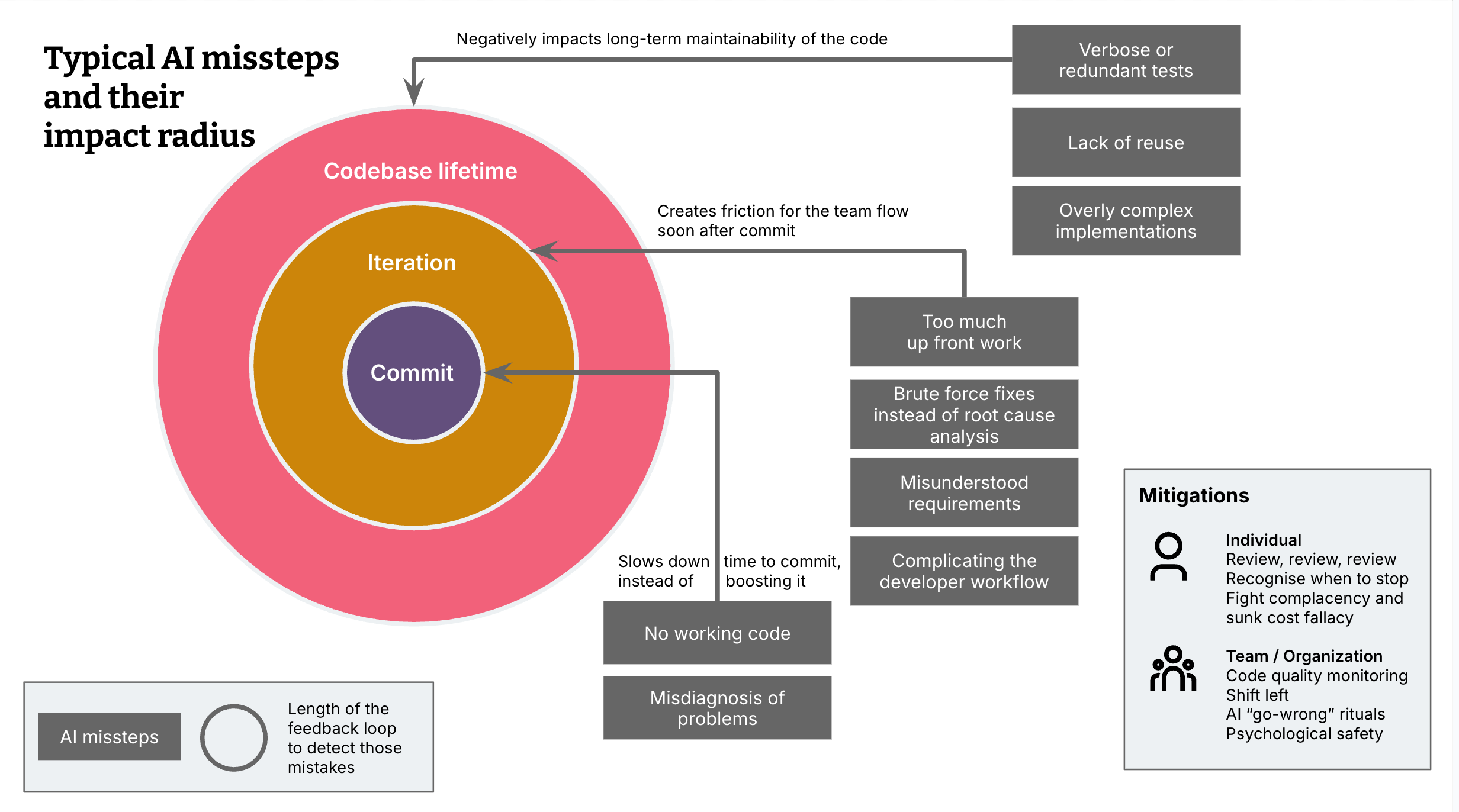
你能做些什么来防止 AI 错误?
那么,你如何保护你的软件和团队免受 LLM 支持工具的反复无常的影响,从而利用 AI 编码助手的优势?
个体编码员
- 始终仔细审查 AI 生成的代码。 我很少没有发现需要修复或改进的东西。
- 当你感到被正在发生的事情淹没时,请停止 AI 编码会话。 要么修改你的提示并开始新的会话,要么回退到手动实现 - 正如我的同事 Steve Upton 所说的 "手工编码"。
- 对在很短时间内奇迹般地创建的 "足够好" 的解决方案保持谨慎, 但会引入长期维护成本。
- 实践结对编程。 四只眼睛比两只眼睛捕捉到的更多,并且两个大脑比一个大脑不自满。
团队和组织
- 良好的代码质量监控。 如果你还没有这些,请设置像 Sonarqube 或 Codescene 这样的工具来提醒你有关代码异味。虽然它们无法捕捉到所有内容,但它是安全网的良好构建块。某些代码异味在使用 AI 工具时变得更加突出,应比以前更密切地监控,例如代码重复。
- 预提交挂钩和 IDE 集成代码审查。 记住尽可能左移 - 有许多工具可以在拉取请求期间或在管道中审查、lint 和安全检查你的代码。但是,你越能在开发期间直接捕捉到,效果就越好。
- 重新审视良好的代码质量实践。 鉴于此处描述的陷阱类型以及团队经历的其他陷阱,创建仪式来重申减轻外部两个影响半径的实践。例如,你可以保留一个 "出错" 事件日志,其中 AI 生成的代码导致团队摩擦或影响可维护性,并每周反思一次。
- 利用自定义规则。 现在大多数编码助手都支持规则集或指令的配置,这些规则集或指令将与每个提示一起发送。你可以作为一个团队利用这些来迭代提示指令的基线,以编纂你的良好实践并减轻此处列出的一些错误。但是,如开头所述,不能保证 AI 会遵循它们。会话越大,因此上下文窗口越大,就越容易出现问题。
- 信任和开放沟通的文化。 我们正处于转型阶段,这项技术正在严重破坏我们的工作方式,每个人都是初学者和学习者。具有信任文化和开放沟通的团队和组织能够更好地学习和处理由此产生的漏洞。例如,一个高度重视他们的团队 "因为你现在有 AI" 的速度更快的组织更容易受到此处提到的质量风险的影响,因为开发人员可能会为了满足期望而偷工减料。并且具有高度信任和心理安全的团队中的开发人员会更容易分享他们在 AI 采用方面面临的挑战,并帮助团队更快地学习以充分利用这些工具。
感谢 Jim Gumbley、Karl Brown、Jörn Dinkla、Matteo Vaccari 和 Sarah Taraporewalla 的反馈和意见。