Sharding:Postgres 向量检索加速方案

Sharding pgvector
Mar 25th, 2025 Lev Kokotov
如果你正在处理 embeddings,那么你肯定已经了解过向量数据库。如果你已经在使用 Postgres,那么 pgvector 是一个不错的选择。但是,一旦你的数据规模达到一定程度(大约一百万个数组),构建索引就会花费很长时间。虽然可以使用并行 workers 等方法来缓解,但你仍然需要将整个图放入内存。
解决大量数据问题的方法是增加计算资源,因此我们对 pgvector 进行了 sharding。在这里,我们特别讨论的是向量 index 的 sharding。在机器之间拆分表相对容易。我们的目标是实现快速且 好的 召回率:我们希望在搜索时能够快速找到匹配项。
一些背景知识
pgvector 有两种类型的索引:HNSW 和 IVFFlat。它们是在多维空间中组织向量的不同方式。HNSW 构建了一个可以快速搜索的多层图,时间复杂度为 O(log(n))。缺点是构建时间很长。
IVFFlat 将向量空间分割成多个部分,围绕着 centroids(即空间中看起来位于 中心 的点)进行分组。查找 中心 使用 K-means 算法,这是一种用于对任意事物进行分组的机器学习算法。IVFFlat 索引构建速度很快,但搜索速度较慢。将图分割成多个部分后,搜索的时间复杂度大约为 O(sqrt(n)))。最后,要找到 centroids,你需要预先拥有向量的代表性样本。Centroids 专门针对 你的 数据,不具有通用性。
当图的部分是热点而其他部分是冷数据时,这两种算法都能很好地工作。随着你的公司发展,热点区域也会增长,因为更多用户搜索更多内容。一旦热点区域超出你的内存,速度就会下降。如果你的算法具有线性时间组件,即使在内存中搜索也不总是你想要的速度。
Sharding 索引
从第一性原理出发,sharding 向量索引意味着将其拆分为多个部分。有时候,说出显而易见的事情也是有好处的。当你大声说出来时,IVFFlat 就成为显而易见的选择。它已经做到了这一点。它使用 K-means 将 embeddings 分组。这意味着,我们可以用同样的方法进行 sharding。只不过,我们不是将这些部分放在同一台机器上,而是将它们放在多台机器上。当我们搜索匹配项时,我们可以根据查询参数选择一个(或多个)host。
为了测试这个想法,我们使用了来自 HuggingFace 的一个公开数据集。它被称为 Cohere/wikipedia,它使用 AI embedding 模型对整个英文 Wikipedia 进行了编码。它产生具有 768 个点的 embeddings,因此我们在 Postgres 中的向量非常大:
CREATE TABLE embeddings (
title text,
body text,
embedding vector(768),
);
Wikipedia 文章有标题和正文。该模型生成文章内容的数学摘要,以便我们可以根据用户提供的上下文轻松找到文章。这被称为语义搜索,它无处不在,包括 Google。
准备好表结构后,下一步是确定 centroids。为此,我们使用了 scikit-learn。它非常易于使用,并且具有我们所需的所有算法。从 HuggingFace 下载样本(数据集已经为我们分割好)后,计算 K-means 非常简单。我现在就不让你去看代码了。所有代码都可以在我们的 GitHub repository 中找到。
你有没有想过人类所有知识的摘要在图上的样子?这是它,使用 PCA 降维到 2 维:
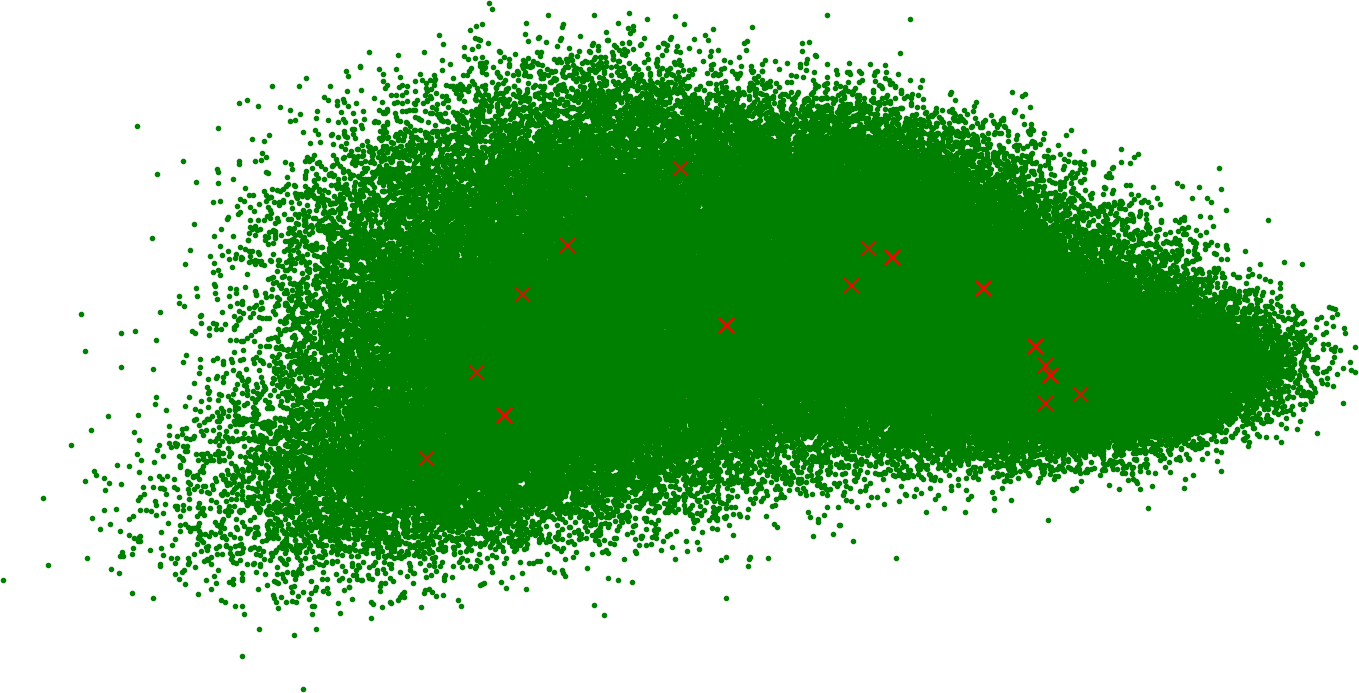
红色 x 是 centroids。我们计算了 16 个,因为这似乎是一个不错的起始数字。就我们的目的而言,我们需要与 shards 一样多的 centroids。如果你认识数据科学家,他们会告诉你你的数据集需要多少个 centroids。
数据的放置很重要,我们将在稍后介绍。目前,我们的 sharding 函数是:
shards = pick(min(l2_distance(vector, centroids)) mod shards, probes)
使用 Euclidean 距离,我们正在寻找具有最接近查询中向量的 centroids 的 shards。如果你已经在使用 pgvector,那么你知道它是 <-> 运算符或 vector_l2_ops 索引类型。
由于我们使用 IVFFlat,因此我们知道 1 个 probe 不够,因此我们选择多个。你可以在 pgdog.toml 中配置你想要的数量。默认情况下,我们将其设置为 sqrt(centroids),在本例中为 4。这类似于 pgvector 中的 ivfflat.probes 设置,并提高了召回率,但代价是计算利用率。性能不会受到太大影响,因为查找是在 warm 连接上并行完成的。
在 PgDog 中添加对向量的支持非常简单。我们正在使用 pg_query,这是一个直接捆绑 PostgreSQL 查询解析器的 Rust crate。PgDog 可以读取所有有效的 Postgres 查询。当搜索匹配项时,通常,你试图按距离对向量进行排序。它们彼此越接近,它们所代表的数据之间的语义匹配就越好。
为了使其工作,我们解析包含 <-> 运算符的 ORDER BY 子句,并将其路由到参数附近的 shards:
SELECT title, body, embedding FROM embeddings
ORDER BY embedding <-> $1;
$1 只是一个占位符,用于表示调用者使用 prepared statements 传入的 embedding。实际上,它是一个具有 768 维的向量,你的应用程序使用相同的 AI 模型为搜索查询生成该向量。
召回率
结果非常好。你可以使用 GitHub 中的代码来重现它们,但这是一个例子:
title | body
----------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Species | Fewer than a quarter of the species have not been identified, named and catalogued. At the present rate, it might take over 1000 years to complete this job. Some will become extinct before this count is complete.
Locust | The origin and apparent extinction of certain species of locust—some of which grew to in length—are unclear.
Lizard | There are other versions, and the taxonomy will probably not settle until more molecular evidence is collected.
Fish | Fish used to be a class of vertebrates. Now the term covers five classes of animals that live in the water:
Pheasant | In many countries pheasant species are hunted, often illegally, as game, and several species are threatened by this and other human activities.
(5 rows)
乍一看,这些看起来非常相似。它们都提到了某种动物,并使用了像 species 这样的词。我选择了一个 centroids 作为我的参数,所以这是有道理的:Wikipedia 的很大一部分都在谈论动物。
我们做了一个更科学的测量。我们抽取了 1,000 个 embeddings,并按升序查找距离为 0.1 个单位的相邻项。使用 1 个 shard,我们获得了 96% 的查询结果。使用 16 个 shard,我们可以让所有查询都返回一些内容。
IVFFlat 是一种近似。实际上,你正在寻找的东西可能是一个异常值,因此你选择的 centroid 可能是错误的,即使它看起来很接近。更常见的是,它只是将点放在错误的集群中,你的查询会错过它。这一切都是权衡。
最简单的解决方法是根本不使用 IVFFlat。只需使用一些其他的 sharding key 将数据均匀地分布在所有 shards 上,并为每个查询与它们全部通信。PgDog 支持并行的跨 shard 查询,因此对你的 n 个向量索引(甚至只是表扫描,以获得完美的召回率)进行 map-reduce 是可行的。
我们还可以将附近的 centroids “bin pack” 到同一个 shards 上。进行多个 probes 变得更便宜:它们已经在同一台机器上并且可以放入内存。要使此工作,你需要将原始 K-means centroids 数量增加到足够高的值,以便能够正确分割你的数据集。这里需要进行一些实验。
关于 sharding 算法选择的快速说明。IVFFLat 仅用于 PgDog 中的 shard 选择。每个 shard(一个 Postgres 数据库)可以使用 IVFFlat 或 HNSW 或根本不使用索引。如果使用索引,你会立即注意到 sharding 的性能优势,尤其是在初始构建过程中。权衡是从在另一个(数据库索引)之上堆叠近似值(PgDog 索引)而降低的召回率。
下一步
更多距离算法,如 cosine similarity (< =>)、negative inner product (<#>) 等都在路线图上。我们还需要使用 SIMD 指令来进行 L2(以及所有其他算法),以便我们可以更快地处理数字。这对于大型 embeddings 来说很重要,即使在测试中差异也很明显。
PgDog 才刚刚开始。如果这看起来很有趣,请与我们联系。PgDog 是一个用于 sharding Postgres 的开源项目,正在寻找早期的设计合作伙伴。
© 2025 PgDog, Inc. 保留所有权利。