从零开始构建一个现代化的 Durable Execution Engine

Restate
- Get Started
- Company
- Docs
- Blog
- Cloud
-
* [GitHub](https://restate.dev/blog/building-a-modern-durable-execution-engine-from-first-principles/<https:/github.com/restatedev/restate>) - Get Restate
 Bluesky
Bluesky Twitter
Twitter Discord
Discord Slack
Slack从零开始构建一个现代化的 Durable Execution Engine
Restate 的工作原理,第二部分 发布于 2025 年 2 月 20 日,作者:Stephan Ewen, Ahmed Farghal, and Till Rohrmann ‐ 阅读需要 20 分钟
我们深入探讨了 Restate 的架构细节,这是一个我们从头构建的 Durable Execution 引擎。Restate 不需要数据库/日志或其他系统,但实现了一个完整的堆栈,在持久性和操作方面与最好的日志竞争。
这是我们从零开始构建持久执行系统系列文章的第二篇。本系列的第一篇博文 Every System is a Log 从应用程序的角度来看待这个问题,并展示了统一的日志架构如何极大地简化分布式协调逻辑。这篇文章讨论了我们如何为该范例构建基于日志的运行时的细节。
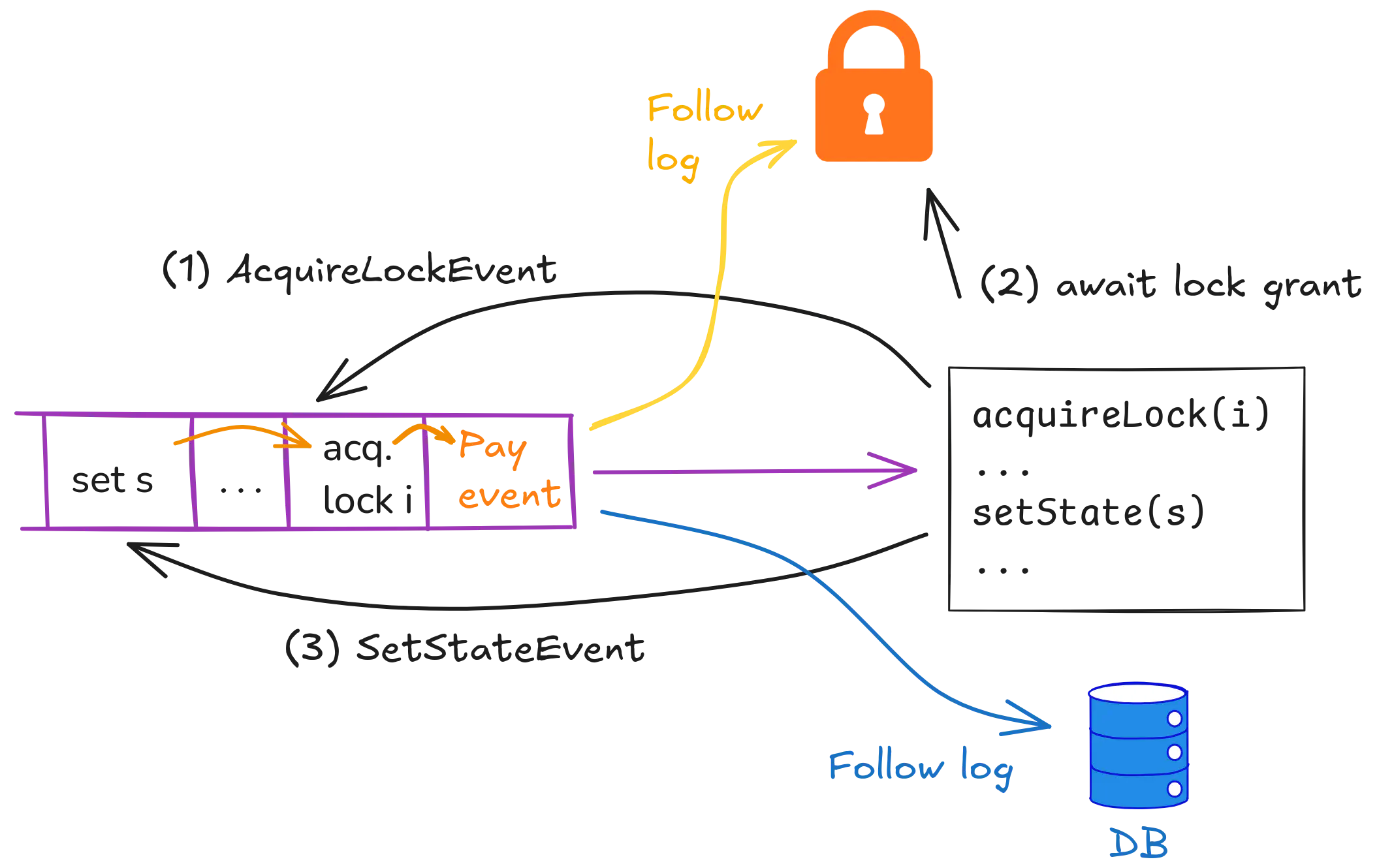
通过应用程序日志建模锁定和数据库更新,摘自Every System is a Log
为了构建这个运行时,我们问自己,如果从头开始设计这样的系统会是什么样子? 我们用 Stateful Functions 构建了它的前身,并且从那里吸取的所有教训中,我们得出了一个_围绕命令日志和事件处理器为中心的自包含完整堆栈的设计,并以单个 Rust 二进制文件的形式发布_。 要了解我们最终获得的用户体验,请查看公告帖子中的视频。
这与常见的观点 “不要构建新的有状态系统,只需使用 Postgres” 有些对比。 但是我们看到了构建新堆栈的明确理由,原因有很多: 首先,交互和访问模式与现有系统有很大的不同,以至于我们可以提供更好的性能和操作行为,类似于消息队列存在的原因,即使你可以使用 SQL 表进行排队。 第二,事件日志的架构近年来取得了重大进展,但高级实现仅限于专有堆栈和托管产品 - 开源日志和队列仍然遵循来自本地部署时代的架构。 第三,我们看到融合堆栈如何让我们提供更好的端到端开发者体验,从笔记本电脑上的首次实验到多区域生产部署。
概述:Server 和 Services #
一个 Restate 应用程序堆栈由两个组件组成:Restate Server,它在您的堆栈中与消息代理类似的位置,以及应用程序 services,它们是包含应用程序逻辑的持久功能/处理程序。 服务器接收调用事件,持久化它们,并将它们推送到服务,类似于事件代理。 服务运行与 RPC 或事件处理程序、工作流、活动或参与者相对应的代码。 服务可以作为进程、容器甚至无服务器功能运行。
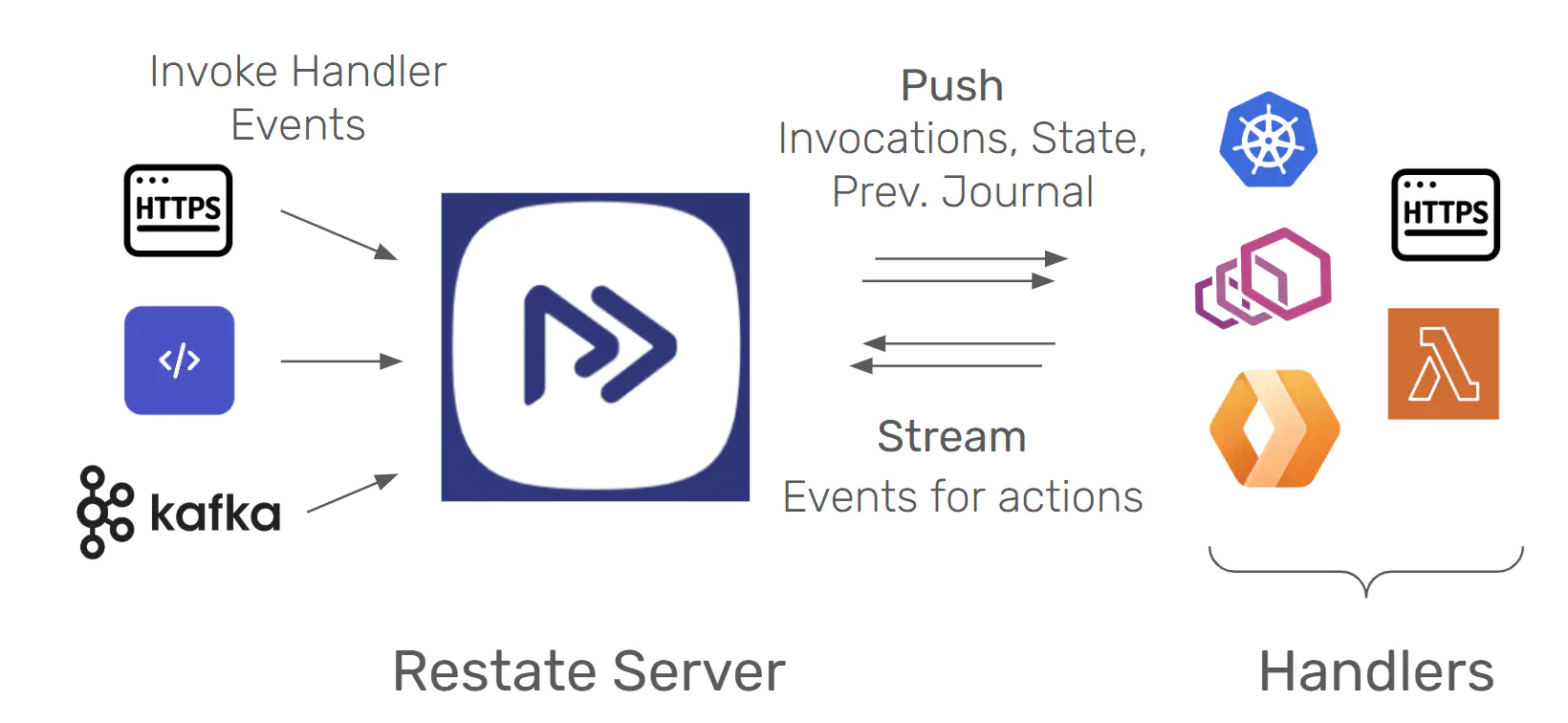
但 Restate 不仅仅推送调用,它还与正在执行的服务处理程序保持双向连接,并允许代码执行持久操作作为调用的一部分,包括日志步骤、向其他处理程序发送事件、访问/修改状态、创建持久 futures (回调) 和 timers。 这些服务使用一个薄 SDK 库,该库将动作传达给服务器 - 有点类似于 KafkaConsumer 或 JDBC 客户端,但级别更高。 有关示例代码和详细信息,请参见 Restate 的示例。
服务器处理调用生命周期、日志、嵌入式 K/V 状态的所有协调和持久性,并管理故障转移、leader 选举和 fencing。 服务器对调用及其日志的视图是真实来源; 这些服务遵循服务器的视图,并且可以根据需要取消/重置/重试功能执行。
这种方法使服务完全无状态且易于操作。 它们可以快速扩展,并在 AWS Lambda、Cloudflare workers 等无服务器基础设施上运行。 此特性还使我们能够相当轻松地以多种语言构建这些 SDK,包括 TypeScript, Java, Kotlin, Python, Go,和 Rust。
集群、对象存储和延迟差距 #
分布式 Restate 部署是由相互连接的节点组成的集群。 调用和事件可以发送到任何节点,并且所有节点都参与事件的存储和将调用分派到服务/功能。 从集群的角度来看,Restate 是 active/active 的,但在 各个分区 的粒度级别上具有 leader/follower 角色,类似于 Kafka 或 TiKV 等系统。
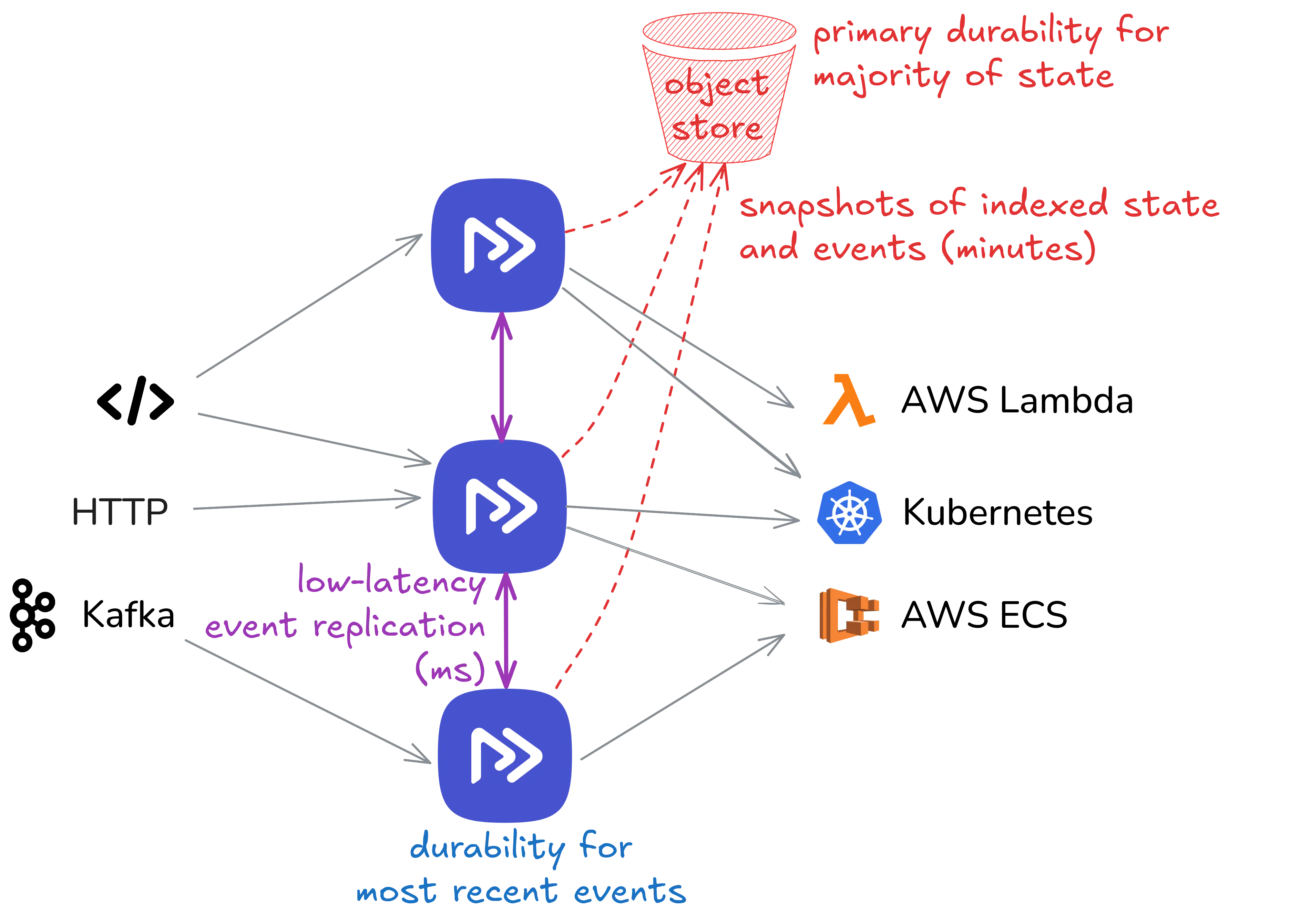
Restate 使用两种机制存储数据:新事件(调用、日志条目、状态更新...)保存在嵌入式复制日志中 (称为 Bifrost)。 从那里,事件移动到 RocksDB 中的状态索引,这些索引定期快照到对象存储。 因此,在任何时间点,大部分数据都在对象存储中持久存在(节点维护一个副本作为缓存),而较小部分数据在跨节点复制的日志中持久存在。
这是一种存储分层形式,但不是像现代日志中那样的经典分层。 它更类似于数据库管理系统,其中 write-ahead-log (WAL) 将跨节点复制,而表数据文件和索引将持久存储在 S3 上(并在节点上缓存)。
对象存储 + 延迟差距 #
将大部分或全部数据保存在对象存储上的架构由于许多原因而变得流行:对象存储在可伸缩性、持久性和成本(AWS S3 引用了 11 个 9 的持久性,存储了超过 100 万亿个对象,并且比持久磁盘便宜)方面是无与伦比的。 此外,存储与计算节点分离存在,使节点无状态(或拥有少量状态),这对于高效操作非常理想。
我们遇到的最本地部署设置中也提供了对象存储。 对于我们来说,自然而然地设计 Restate,以便对象存储将成为大多数数据的主要持久性。
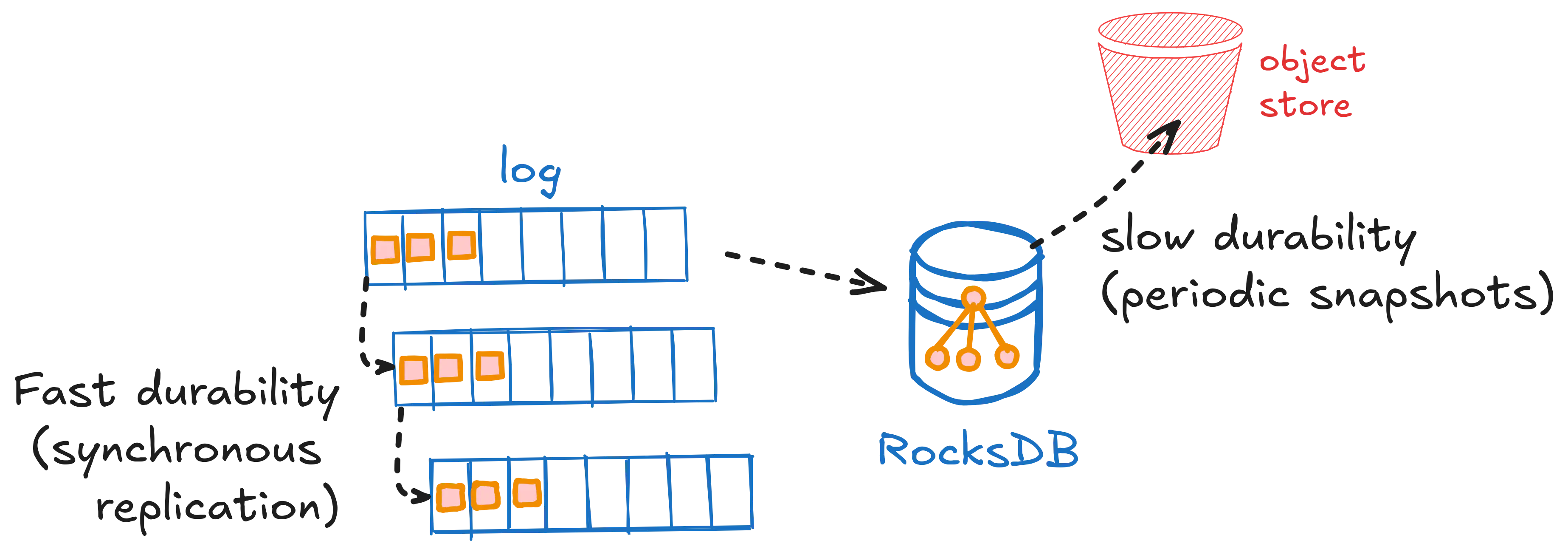
Restate 另外有一个复制层来持久化新事件(而不是将事件直接写入对象存储)的原因是提供低延迟。 纯对象存储方法的平均延迟约为 100 毫秒,才能使数据持久化,而尾部延迟是该延迟的倍数。 虽然这对于分析系统(例如 Apache Flink)和数据管道(如 WarpStream)来说是可行的,但对于许多应用程序来说,这种延迟可能会很快变得令人望而却步。
Restate 的复制弥合了快速持久功能的要求与对象存储的功能之间的延迟差距。
驾驭云延迟-成本-磁盘三要素 #
上面描述的设置是我们首先在 Restate 1.2 中发布的:一个在 Restate server 节点之间复制的快速日志。 但是,Restate 使用虚拟日志抽象,以便轻松支持其他日志实现,而无需每次都构建完整的共识机制。 这是 Restate 运行时实现的一个决定性特征,我们将在本系列的 下一篇文章 中更深入地探讨。 我们目前也正在使用该机制在日志中构建对象存储支持,这是一个强大的功能,可以将节点上持久存在的数据量减少到非常小的数量,甚至为零。
对于该设置,没有单一的最佳配置 - 只有一系列权衡可供选择。 在他的 Materialized View 新闻通讯中,Chris Riccomini 将其描述为类似于 CAP 定理的选择:

在我们的上下文中(持久执行运行时),持久性必须是给定的,但是我们还有一个额外的维度,即在节点上保留多少复制数据。 因此,Restate 的三要素是:延迟-成本-磁盘。
- ➕ 低延迟,➕ 低成本,➖ 磁盘上的一些数据: Quorum 复制到节点,异步批量写入 S3。节点通过复制提供快速持久性,并在将事件移动到对象存储之前,将数据保存几百毫秒到几分钟不等的时间。 Restate 1.2 可以看作是具有长刷新间隔的变体。
- ➕ 低延迟,➖ 高成本,➕ 磁盘上没有数据: Quorum 直接复制到 S3 Express One Zone。Restate 的复制机制仅处理排序、quorum 和区域丢失时的修复,但不将数据保存在节点上(除了缓存)。
- ➖ 高延迟,➕ 低成本,➕ 磁盘上没有数据: 同步批量写入 S3。不使用 Restate 的复制机制。
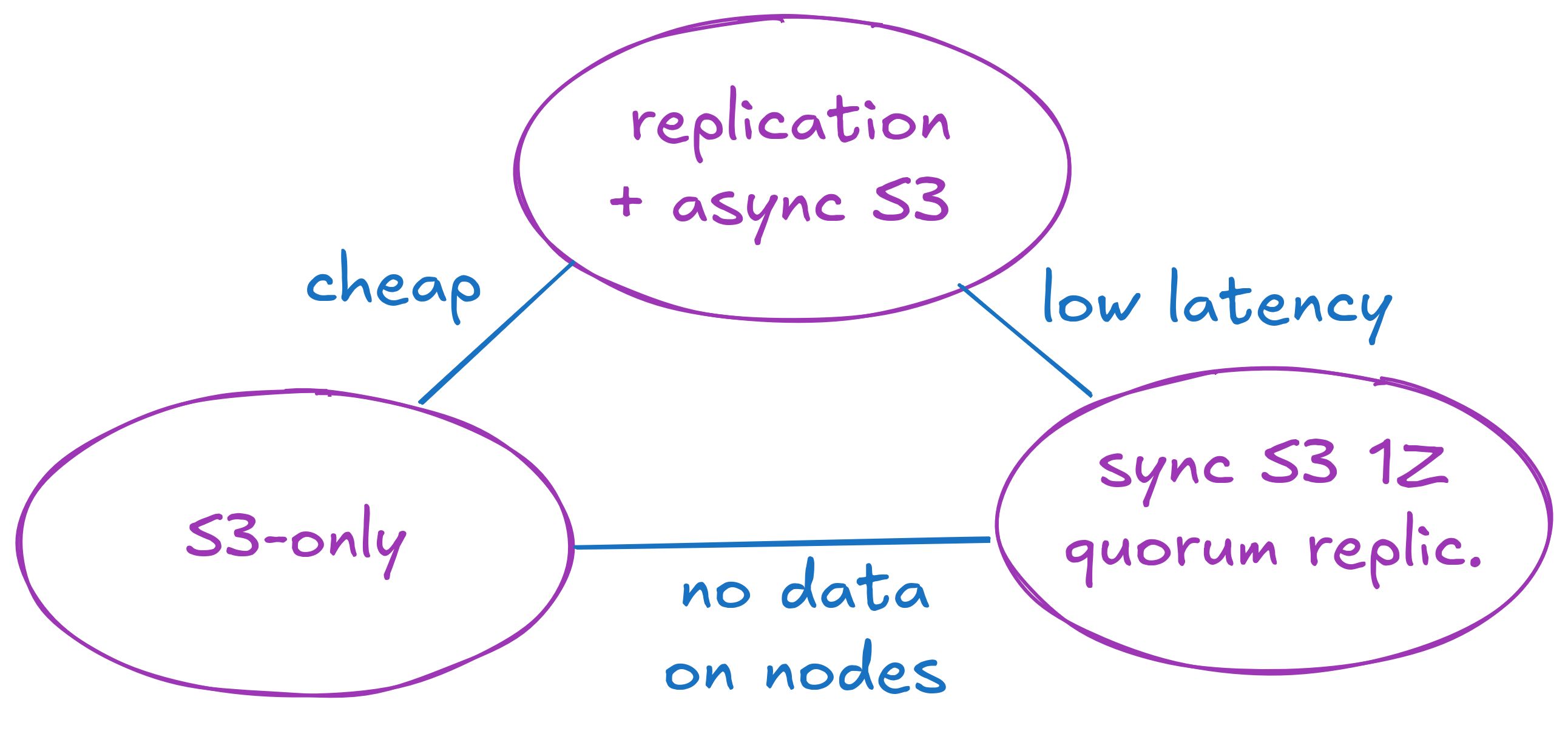
当然,有一些细微差别:直接复制比 S3 Express 1Z quorums 具有更低的延迟。 同步批量写入 S3 可能比其他任何方式都便宜,因为该方法可以避免跨 AZ 带宽成本。 在所有配置中,磁盘仍然作为缓存存在。 并且可以选择使用 quorum 复制到不同区域的 S3 Express 1Z,以支持多区域部署,而无需依赖磁盘。 但它表明存在一系列选项,我们旨在使开发人员能够在云和本地部署中的各种设置中使用 Restate,同时保持简单的依赖性:只需一个对象存储。
Restate 1.2 附带了所有虚拟日志基础设施和一个低延迟复制日志实现。 我们目前正在研究其他配置 - 如果您有兴趣成为早期测试人员或设计合作伙伴,请与我们联系。
最后,能够适应不同的权衡也有助于 Restate 及其用户适应不断变化的云定价模型。 引用另一位多产的 dist. sys. 作者:

分区扩展 #
Restate 遵循分区扩展模型:一个集群有一组分区,每个分区都有一个日志分区和一个事件处理器实例。 分区独立运行,并允许系统跨内核和节点进行扩展。
与调用相关的所有内容都发生在单个分区内:调用、幂等性 & 去重、日志条目、状态、promises/futures,从而避免了与其他任何分片同步和协调的需要。 调用的目标分区由哈希虚拟对象键、工作流 ID 或幂等键(如果适用)确定 - 否则,可以自由选择分区。
在某些情况下,函数执行会为另一个分区生成一个事件,例如 RPC 事件或完成。 在这种情况下,事件仍然写入本地分区,并且服务器有一个带外的一次性事件 shuffler,以将事件移动到正确的目标分区。
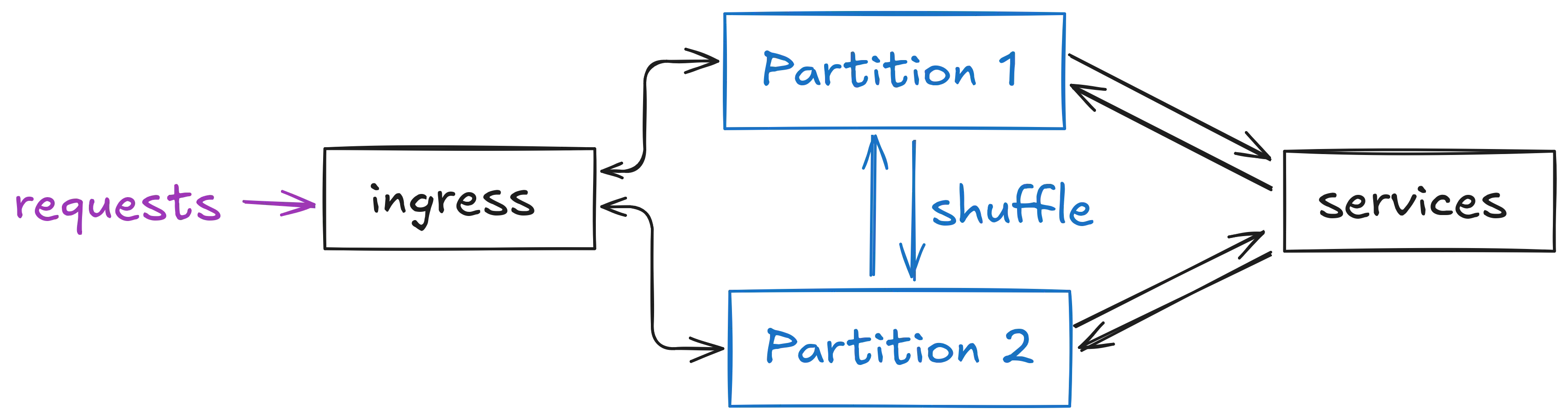
分区不会暴露给应用程序(尽管您在使用 restatectl 时会看到它们) - 只有键是可直接寻址的(虚拟对象 id、工作流 id、幂等键),以允许在不丢失一致性的情况下更改分区数。
从现在开始,我们只关注单个分区内发生的事情。
事件日志和处理器 #
Restate Server 在一个分区内完成的工作发生在两个组件中:分布式持久日志 (称为 Bifrost) 和处理器。 该日志是事件的快速主持久性 (例如,进行调用、添加日志条目、更新状态、创建持久承诺...) ,处理器对事件采取行动(例如,调用处理程序)并实现其状态。 日志和处理器是协同分区的,这意味着分区处理器连接到一个日志分区。 它们是独立的,但经常位于同一进程中。
与数据库相比,您可以将 Bifrost 视为事务 WAL,并将处理器视为查询引擎和表存储。 与流处理相比,您可以将 Restate 的日志视为 Kafka,并将处理器视为流处理应用程序(如 KStreams 或 Flink)。
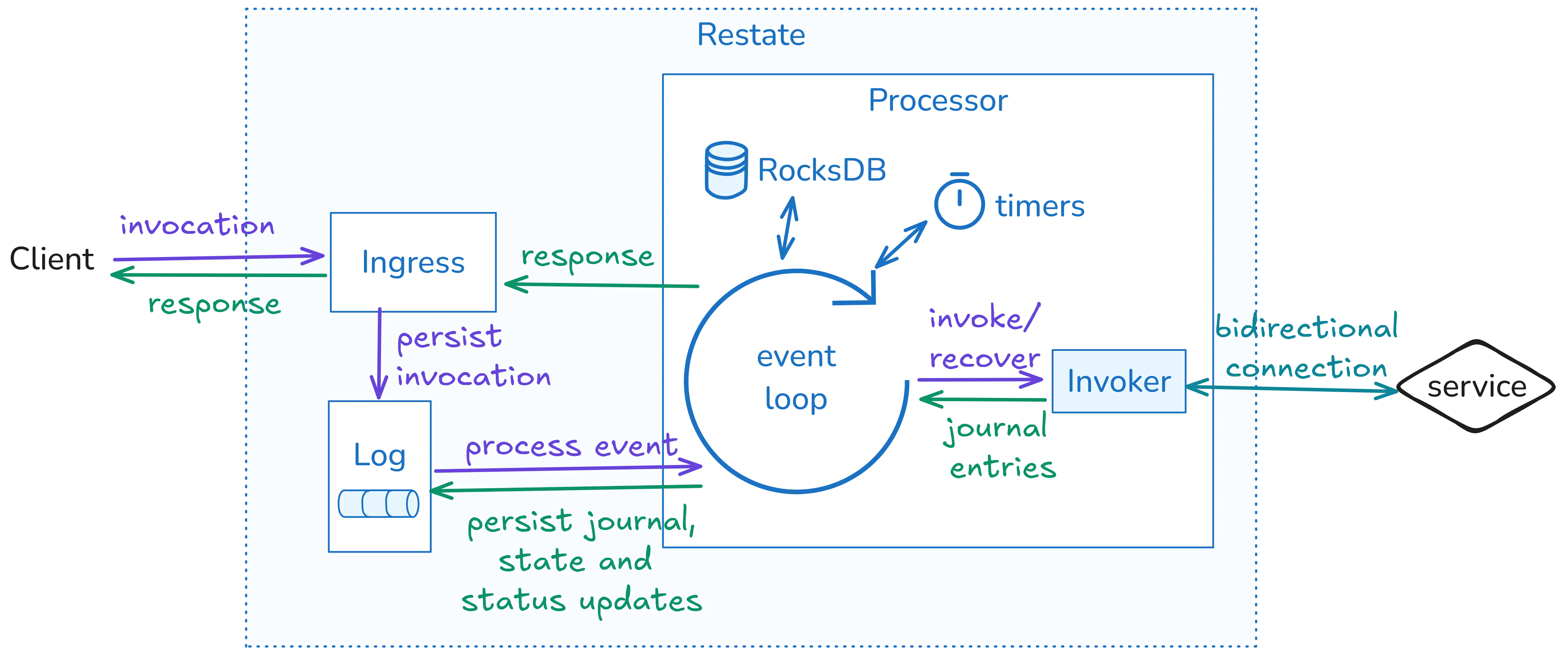
日志和处理器形成一个紧密的循环:处理器不断地跟踪日志,并对事件采取行动(例如,进行调用)。 这可能会产生更多事件(日志条目、状态更新...),这些事件被写入日志并再次由处理器处理。
让我们通过一个例子来说明这一点:
- 客户端通过 Restate 使用幂等键 K 调用服务处理程序
processPayment。 进入会将调用排队到日志分区,如哈希 K 所确定的那样。 - 分区的 leader 处理器接收该事件并检查其本地幂等键状态。 对于
processPayment,K 不包含在那里。 处理器以原子方式将 K 添加到状态并将调用转换为 running,然后建立与目标服务终结点的连接,并推送调用日志条目。 - 服务流回一个 step result 事件 (
ctx.run({...})) 并且处理器将该日志条目事件排队到日志中。 在日志中保持持久是“该步骤发生”的时间点,这意味着从那时起它将始终被恢复。 - 当处理器从日志中接收到该事件时(这意味着 没有其他处理器在此期间接管了领导),那么它会将该事件添加到调用的日志状态并向服务发送一个 ack。
- 当服务发送状态更新、timer、RPC 事件或创建持久承诺时,会发生类似的步骤。 事件总是首先添加到日志中,并且一旦它们被处理器接收到,就会对它们采取行动(例如,添加到日志、作为调用路由到其他服务等)。
- 一旦调用完成,处理器会将结果事件添加到日志中。 接收到该事件后,它会将调用状态设置为完成并将结果发回给客户端。
当函数执行失败时(例如,崩溃、连接丢失、用户定义的错误),处理器会调度一个新的调用,并附加到目前为止来自此调用的完整日志事件。 为了避免服务之间的 split brain 场景,处理器会跟踪调用执行尝试(重试),并且如果已经开始了一个新的尝试,则拒绝从调用发送的事件。 这可以用简单的内存状态来跟踪,因为调用对分区具有粘性,并且分区具有 强领导者。
状态存储 #
处理器将其所有非瞬态状态存储在嵌入式 RocksDB 实例中。 对该嵌入式存储的操作非常快,但是当节点丢失时,状态也会丢失。 但是,处理器的所有状态都是从持久日志中确定性地派生的,并且始终可以在恢复期间从日志中重建。 为了避免任意长的重建阶段,RocksDB 数据库会定期快照到对象存储,并且日志会被截断到快照的点。 可以通过获取最新快照并在拍摄快照时附加到事件序列号处的日志来恢复处理器。
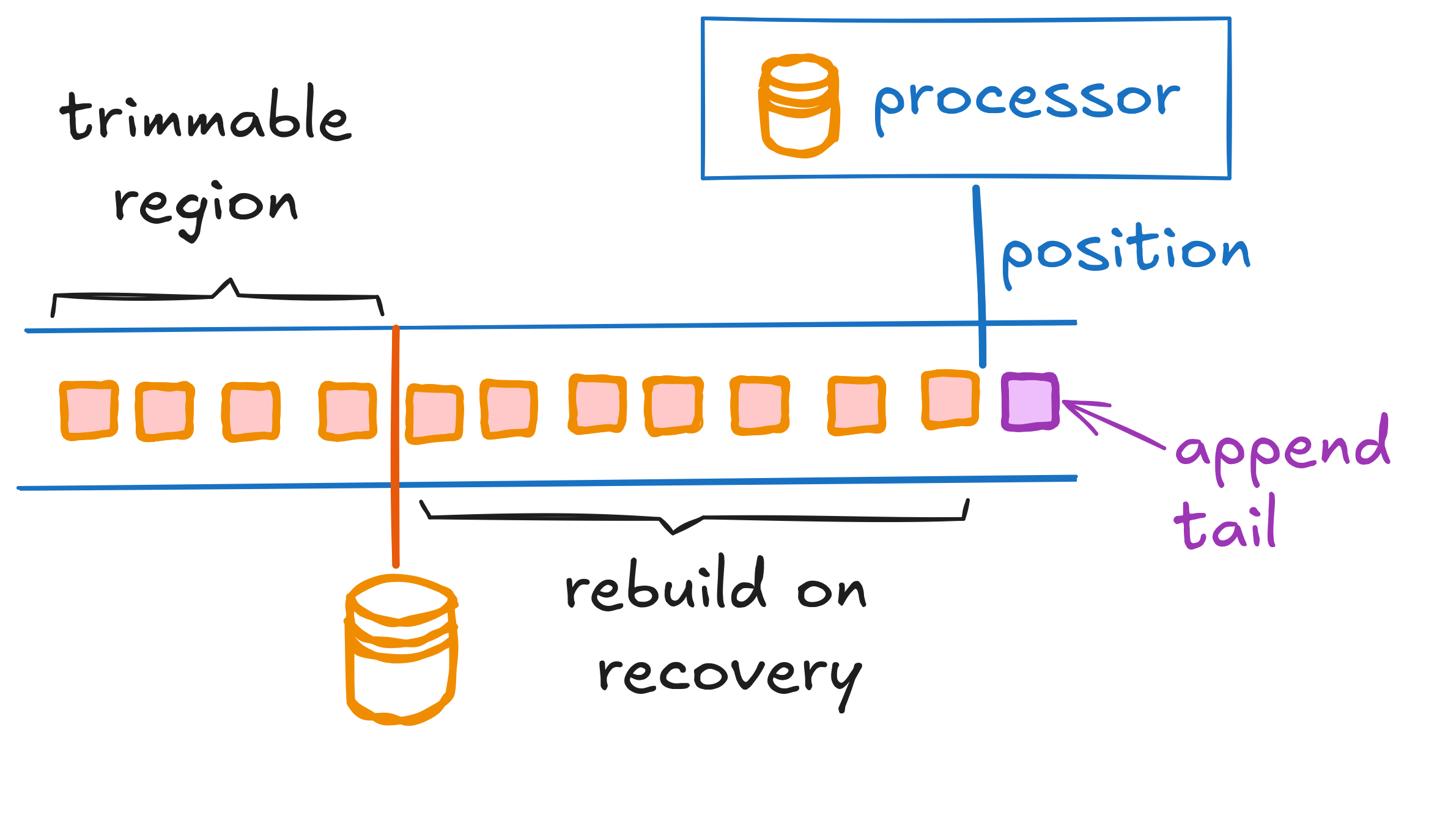
分区处理器的实现是 Rust 的 Tokio runtime 中的一个紧密的事件循环。 分区处理器彼此独立运行,并且专门访问本地数据结构(在内存中、RocksDB、流到正在进行的调用)。 在日志优先的设计中,分区的本地调用处理很容易,并且如果我们在通用数据库上构建它,则很难实现。
该属性还使设计既简单又快速:提交事件(例如,步骤/活动)意味着将事件附加到日志(获得写入 quorum)。 只要发生这种情况,事件就会从日志 leader 在内存中推送到附加的处理器并 ack-ed 到处理程序/工作流。 这需要单个网络往返来获得复制 quorum,而无需分布式读取。 RocksDB 的持久性完全在后台异步发生。
Leaders 和 Followers #
日志和处理器都有一个 leader 和可选的 followers。 对于日志,followers 通过额外的副本增加事件的持久性。 对于处理器,followers 是热备用设备,它们具有状态的副本(从日志中确定性地派生),并且可以在发生故障时快速接管。 只有处理器 leader 实际将函数和工作流的调用分派给服务,并且只有 leader 将快照写入对象存储。
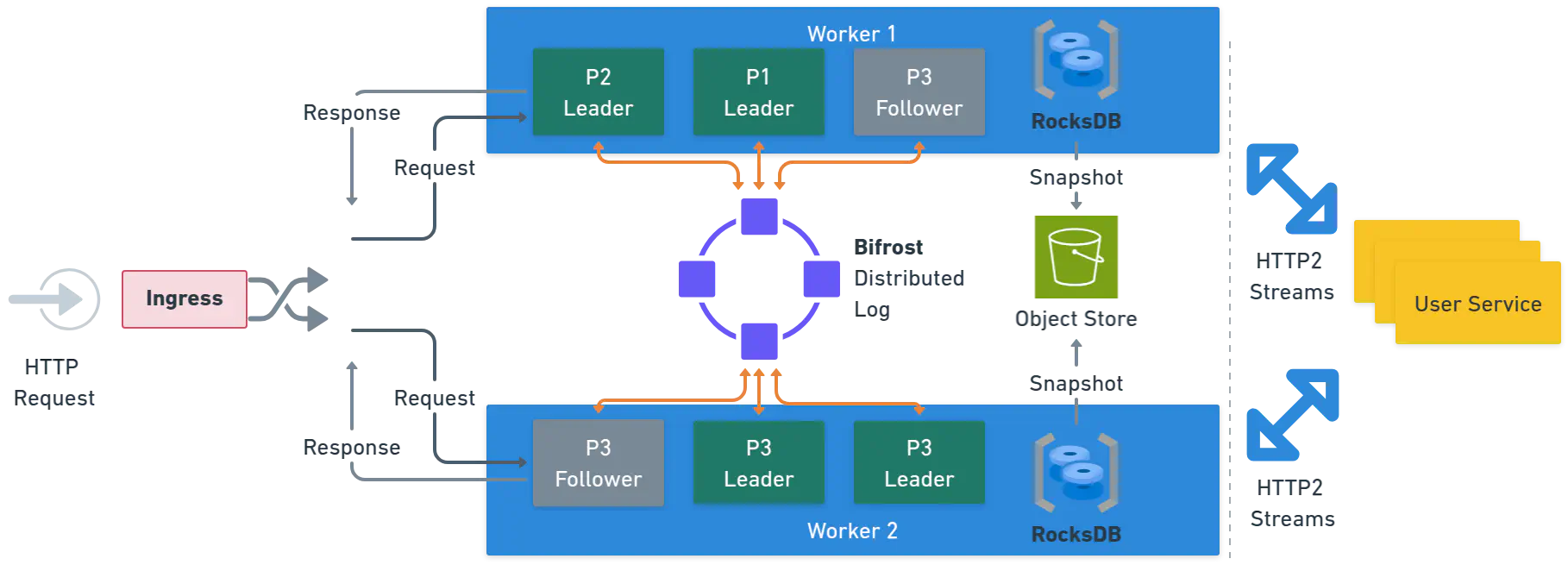 高级架构和请求流。
高级架构和请求流。
Control Plane, Data Plane, External Consensus #
到目前为止,我们所看到的一切都是系统的 data plane:日志和分区处理器。
一切都由一个 control plane 协调,该 control plane 负责故障检测、故障转移协调和重新配置。 control plane 存储集群的元数据(如配置),并运行处理分区放置和 leader 选举的集群控制器。
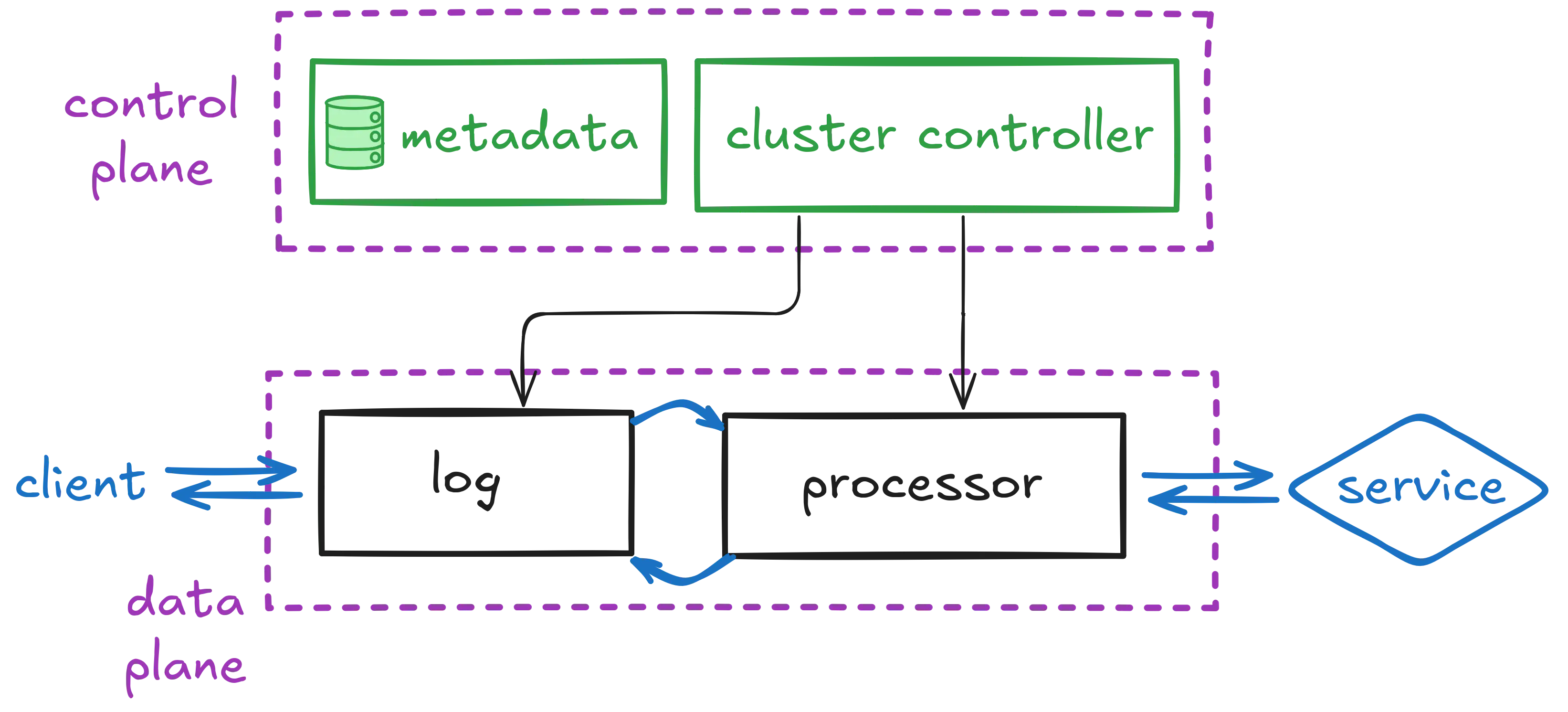
Control Plane 和 Data Plane
因为 Restate 为日志和处理器都有一个 control plane,所以它可以共同协调两者,例如,确保 leader 处理器始终与日志分区 leader 位于同一位置,以减少网络跳数并优化从本地内存缓存的读取。 相比之下,如果我们要在像 Kafka 这样的外部日志上透明地构建它,则很难实现这种并置。 这种联合 control plane 的好处体现在系统的许多部分中,并且是 Restate 更易于设置、扩展和操作的原因之一。
除了管理重新配置和故障转移之外,control plane 还为 data plane 提供了 外部共识,从而使 data plane 可以更有效地运行并具有比完全共识更简单的属性。 我们将在 下一篇博文 中详细介绍 Restate 的日志实现 - 目前,一个有用的高级思考方式是,control plane 在前一个配置不再起作用(发生了故障)或所需配置(例如,重新平衡)时,将 data plane 从一个稳定配置移动到另一个稳定配置。 来自 Jack Vanlightly 的 这篇博文 对该概念进行了很好的介绍。
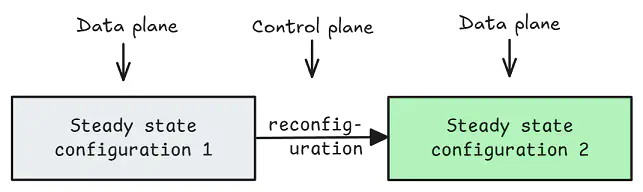 Control Plane 重新配置 Data Plane(图来自 Jack Vanlightly 的“Delos 中的虚拟共识简介”)
Control Plane 重新配置 Data Plane(图来自 Jack Vanlightly 的“Delos 中的虚拟共识简介”)
这种设计的另一个好处是,它允许 Restate 在 control plane 上使用更简单/更慢的共识实现,因为它很少被调用。 Restate 将其共识抽象为仅仅是一个原子比较和交换 (CAS) 元数据操作,该操作通过 RAFT 共识算法的实现来备份内置的元数据存储。 但是,只要它们支持原子 CAS,就可以轻松扩展到插入不同的存储系统。
故障转移 & 重新配置 #
尽管 control plane 共同协调日志和处理器重新配置,但每个都有自己的机制来确保一致性。
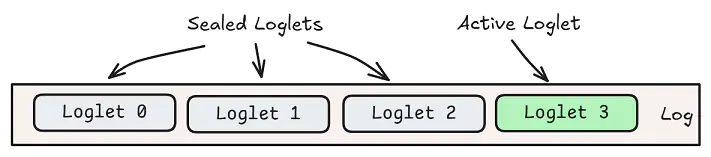 分段日志(图来自 Jack Vanlightly 的“Delos 中的虚拟共识简介”)
分段日志(图来自 Jack Vanlightly 的“Delos 中的虚拟共识简介”)
Bifrost(日志)的机制基于 Delos(虚拟共识)和 LogDevice 的混合。 从高级别来看,bifrost 是分段的,故障转移或重新配置会密封活动段并创建一个新段,可能具有一个新的 leader 和一组不同的存储副本的节点。 对于外部和分区处理器,一切看起来都像一个连续的日志。
当分区处理器失败时,control plane 会为该分区选择一个新的 leader。 故障转移过程依赖于 control plane 提供的外部共识:新的 leaders 在严格单调的序列中获得下一个 epoch(因此,新的 leaders 具有更高的 epoch)。 新的 leader 向日志附加一条消息,以指示他们的 epoch 现在处于活动状态,然后简单地开始从其操作中附加事件。 旧的 leader(可能仍在跟踪日志)将接收到 epoch 提升消息并在该确切点停止 - 它将继续实现状态(作为 follower),但不再分派调用。 旧的 leader 还会中止正在进行的函数执行,并允许新的 leader 恢复这些函数执行。
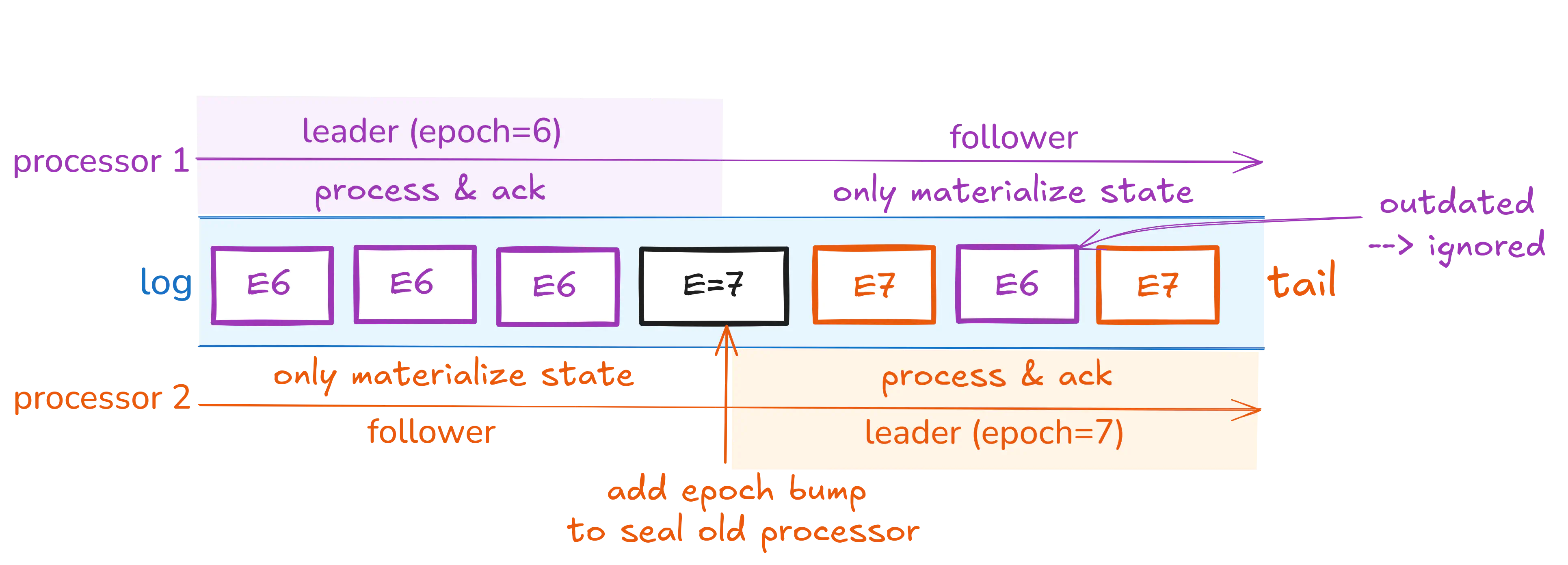 通过日志中的消息进行 leader 切换
通过日志中的消息进行 leader 切换
任何携带低于最新 epoch 提升消息的 epoch 的消息都将被忽略,这将过滤旧的 leader 在发现它被另一个 leader 取代之前可能仍在附加到日志的消息。 如果旧的 leader 试图提交日志条目,但消息是在 epoch 提升消息之后附加的,则无法提交该提交:新的 leader 将(或者可能已经)在没有该日志条目的情况下恢复该进程并执行和提交该步骤。 此机制可确保任何步骤/活动结果都只提交一次。 不可能出现 split brain 视图。
此机制还会自动解决对领导权的并发竞争 - 最高的 epoch 将获胜,并且始终如一地忽略延迟事件。
融合的单个二进制文件 #
Restate 的架构设计为一组彼此通信且不假设其对等方位置的单独组件。 Restate 二进制文件可以运行每个组件或其中的一个子集; 一组组件由一个角色描述。
默认配置是融合模式,其中每个二进制文件都运行每个角色。 在这种情况下,您将在单个二进制文件中获得分布式架构。 您可以启动更多二进制文件的实例来形成集群。 这种模式易于使用且高效,因为它还允许不同的组件尽可能通过内存通道和缓存进行有效通信(例如,日志到处理器)。
 Restate 的角色和组件
Restate 的角色和组件
但是,您当然也可以将其作为分离设置运行,其中不同的节点集运行不同的角色。 这样,您可以将 control plane 与 data plane 分开,并根据元数据和数据的成本/持久性/可用性选择最佳的权衡。 例如:
- 在三个不同的区域中部署三个具有 admin 角色的节点,以确保应用程序和共识元数据具有防灾性。
- 在三个可用性区域中部署六个具有 Log-Server 角色的节点,以确保数据被复制以容忍区域中断。
- 在一个可用性区域中部署 Ingress 和 Worker 角色,以严格地将它们与区域本地服务并置。
Restate 的架构为您提供了出色的开发者体验,从一开始(在您的笔记本电脑上启动单个二进制文件)到复杂的分布式部署(分离的分布式设置)。