使用 Span.SequenceEquals 比 memcmp 更快
richardcocks
2025-03-30 什么比 Memcmp 更快?
在这篇文章中,我将探讨 .NET 的改进以及使用 Span 来提高性能和可移植性。
我正在检查一个代码库中的可移植性问题,该代码库我想从 .NET framework 4.8.1 迁移到 .NET8。 我发现了 msvcrt.dll 的使用。 我很快确定这是 stackoverflow 上一个很受欢迎的答案,提供了一种在 .NET 中快速比较字节数组的方法。
这个答案,被忠实地复制到代码库中,是这样的:
[DllImport("msvcrt.dll", CallingConvention=CallingConvention.Cdecl)]
static extern int memcmp(byte[] b1, byte[] b2, long count);
static bool ByteArrayCompare(byte[] b1, byte[] b2)
{
// 验证缓冲区长度是否相同。
// 这也确保了计数不会超过任何一个缓冲区的长度。
return b1.Length == b2.Length && memcmp(b1, b2, b1.Length) == 0;
}
现代 .NET 的一个重要的性能改进是 Span<T> 类型。 文档将其描述为:
提供对任意内存的连续区域的类型安全和内存安全的表示。 这个描述不是特别有用,但总结一下就是它是在栈上分配的,而不是在堆上分配的。
Span<T> 有一个扩展方法 SequenceEqual<T>(this ReadOnlySpan<T> span, ReadOnlySpan<T> other),我们将看看它的表现。
public static bool EqualsSpan(ReadOnlySpan<byte> b1, ReadOnlySpan<byte> b2)
{
return b1.SequenceEqual(b2);
}
让我们看看它与几个朴素的实现,一个 for 循环和使用 Enumerable.SequenceEquals 相比如何:
public static bool EqualsLoop(byte[] b1, byte[] b2)
{
if (b1.Length != b2.Length) return false;
for (int i = 0; i < b1.Length; i++)
{
if (b1[i] != b2[i]) return false;
}
return true;
}
public static bool EqualsSequenceEqual(byte[] b1, byte[] b2)
{
return b1.SequenceEqual(b2);
}
我们比较两个相同的数组,因为这通常是相等性检查的最坏情况,并且我们将在一系列数组大小上进行基准测试:10 字节,1KB,1MB 和 1GB。
[Params(10, 1_024, 1_048_576, 1073741824)]
public int Length { get; set; }
byte[] first;
byte[] second;
[GlobalSetup]
public void Setup()
{
var r = new Random(0);
first = new byte[Length];
second = new byte[Length];
r.NextBytes(first);
Array.Copy(first, second, Length);
}
设置很简单,我们用随机数据填充第一个数组,并将数据复制到第二个数组。
结果
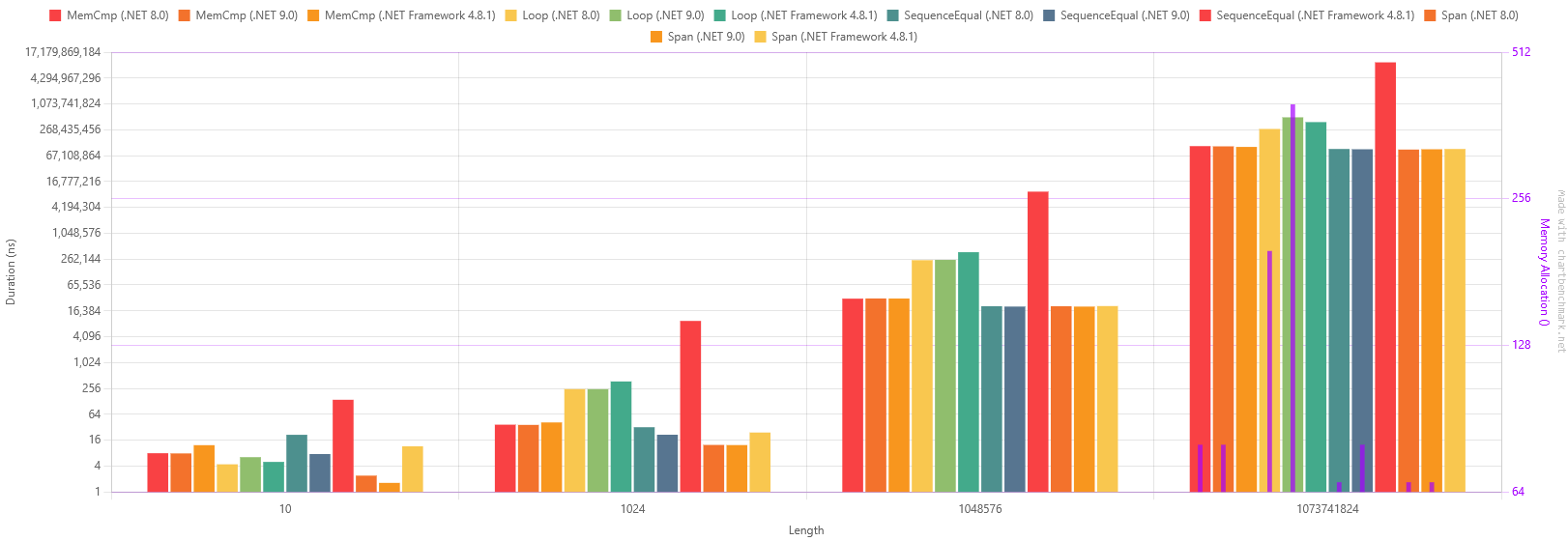
BenchmarkDotNet v0.14.0, Windows 10 (10.0.19045.5679/22H2/2022Update)
AMD Ryzen 7 3800X, 1 CPU, 16 logical and 8 physical cores
.NET SDK 10.0.100-preview.2.25164.34
[Host] : .NET 9.0.3 (9.0.325.11113), X64 RyuJIT AVX2
.NET 8.0 : .NET 8.0.14 (8.0.1425.11118), X64 RyuJIT AVX2
.NET 9.0 : .NET 9.0.3 (9.0.325.11113), X64 RyuJIT AVX2
.NET Framework 4.8.1 : .NET Framework 4.8.1 (4.8.9290.0), X64 RyuJIT VectorSize=256
Method | Job | Runtime | Length | Mean | Ratio | RatioSD | Allocated
---|---|---|---|---|---|---|---
MemCmp | .NET 8.0 | .NET 8.0 | 10 | 7.957 ns | 0.65 | 0.01 | -
MemCmp | .NET 9.0 | .NET 9.0 | 10 | 7.877 ns | 0.64 | 0.01 | -
MemCmp | .NET Framework 4.8.1 | .NET Framework 4.8.1 | 10 | 12.239 ns | 1.00 | 0.02 | -
Loop | .NET 8.0 | .NET 8.0 | 10 | 4.390 ns | 0.88 | 0.03 | -
Loop | .NET 9.0 | .NET 9.0 | 10 | 6.439 ns | 1.29 | 0.05 | -
Loop | .NET Framework 4.8.1 | .NET Framework 4.8.1 | 10 | 4.995 ns | 1.00 | 0.03 | -
SequenceEqual | .NET 8.0 | .NET 8.0 | 10 | 21.341 ns | 0.15 | 0.00 | -
SequenceEqual | .NET 9.0 | .NET 9.0 | 10 | 7.611 ns | 0.05 | 0.00 | -
SequenceEqual | .NET Framework 4.8.1 | .NET Framework 4.8.1 | 10 | 139.476 ns | 1.00 | 0.02 | 64 B
Span | .NET 8.0 | .NET 8.0 | 10 | 2.394 ns | 0.21 | 0.00 | -
Span | .NET 9.0 | .NET 9.0 | 10 | 1.624 ns | 0.14 | 0.00 | -
Span | .NET Framework 4.8.1 | .NET Framework 4.8.1 | 10 | 11.523 ns | 1.00 | 0.01 | -
MemCmp | .NET 8.0 | .NET 8.0 | 1024 | 36.745 ns | 0.89 | 0.01 | -
MemCmp | .NET 9.0 | .NET 9.0 | 1024 | 36.317 ns | 0.88 | 0.01 | -
MemCmp | .NET Framework 4.8.1 | .NET Framework 4.8.1 | 1024 | 41.452 ns | 1.00 | 0.01 | -
Loop | .NET 8.0 | .NET 8.0 | 1024 | 247.326 ns | 0.66 | 0.01 | -
Loop | .NET 9.0 | .NET 9.0 | 1024 | 246.738 ns | 0.66 | 0.01 | -
Loop | .NET Framework 4.8.1 | .NET Framework 4.8.1 | 1024 | 372.410 ns | 1.00 | 0.01 | -
SequenceEqual | .NET 8.0 | .NET 8.0 | 1024 | 32.069 ns | 0.003 | 0.00 | -
SequenceEqual | .NET 9.0 | .NET 9.0 | 1024 | 21.439 ns | 0.002 | 0.00 | -
SequenceEqual | .NET Framework 4.8.1 | .NET Framework 4.8.1 | 1024 | 9,542.293 ns | 1.000 | 0.02 | 64 B
Span | .NET 8.0 | .NET 8.0 | 1024 | 12.408 ns | 0.51 | 0.01 | -
Span | .NET 9.0 | .NET 9.0 | 1024 | 12.310 ns | 0.51 | 0.01 | -
Span | .NET Framework 4.8.1 | .NET Framework 4.8.1 | 1024 | 24.117 ns | 1.00 | 0.01 | -
MemCmp | .NET 8.0 | .NET 8.0 | 1048576 | 31,477.776 ns | 0.99 | 0.02 | -
MemCmp | .NET 9.0 | .NET 9.0 | 1048576 | 31,790.009 ns | 1.00 | 0.02 | -
MemCmp | .NET Framework 4.8.1 | .NET Framework 4.8.1 | 1048576 | 31,693.469 ns | 1.00 | 0.02 | -
Loop | .NET 8.0 | .NET 8.0 | 1048576 | 247,350.116 ns | 0.65 | 0.01 | -
Loop | .NET 9.0 | .NET 9.0 | 1048576 | 251,317.223 ns | 0.66 | 0.02 | -
Loop | .NET Framework 4.8.1 | .NET Framework 4.8.1 | 1048576 | 379,628.993 ns | 1.00 | 0.02 | -
SequenceEqual | .NET 8.0 | .NET 8.0 | 1048576 | 20,974.963 ns | 0.002 | 0.00 | -
SequenceEqual | .NET 9.0 | .NET 9.0 | 1048576 | 20,615.505 ns | 0.002 | 0.00 | -
SequenceEqual | .NET Framework 4.8.1 | .NET Framework 4.8.1 | 1048576 | 9,744,674.688 ns | 1.000 | 0.01 | -
Span | .NET 8.0 | .NET 8.0 | 1048576 | 20,955.331 ns | 0.99 | 0.02 | -
Span | .NET 9.0 | .NET 9.0 | 1048576 | 20,598.672 ns | 0.97 | 0.01 | -
Span | .NET Framework 4.8.1 | .NET Framework 4.8.1 | 1048576 | 21,176.643 ns | 1.00 | 0.02 | -
MemCmp | .NET 8.0 | .NET 8.0 | 1073741824 | 111,762,734.375 ns | 1.04 | 0.03 | 80 B
MemCmp | .NET 9.0 | .NET 9.0 | 1073741824 | 110,374,794.400 ns | 1.03 | 0.03 | 80 B
MemCmp | .NET Framework 4.8.1 | .NET Framework 4.8.1 | 1073741824 | 107,072,063.077 ns | 1.00 | 0.01 | -
Loop | .NET 8.0 | .NET 8.0 | 1073741824 | 280,450,679.167 ns | 0.69 | 0.02 | 200 B
Loop | .NET 9.0 | .NET 9.0 | 1073741824 | 523,091,792.857 ns | 1.29 | 0.02 | 400 B
Loop | .NET Framework 4.8.1 | .NET Framework 4.8.1 | 1073741824 | 404,927,735.714 ns | 1.00 | 0.01 | -
SequenceEqual | .NET 8.0 | .NET 8.0 | 1073741824 | 95,954,794.298 ns | 0.010 | 0.00 | 67 B
SequenceEqual | .NET 9.0 | .NET 9.0 | 1073741824 | 94,486,122.500 ns | 0.010 | 0.00 | 80 B
SequenceEqual | .NET Framework 4.8.1 | .NET Framework 4.8.1 | 1073741824 | 9,944,911,760.000 ns | 1.000 | 0.00 | -
Span | .NET 8.0 | .NET 8.0 | 1073741824 | 92,945,091.026 ns | 0.97 | 0.01 | 67 B
Span | .NET 9.0 | .NET 9.0 | 1073741824 | 94,375,230.882 ns | 0.99 | 0.03 | 67 B
Span | .NET Framework 4.8.1 | .NET Framework 4.8.1 | 1073741824 | 95,817,247.619 ns | 1.00 | 0.02 | -
第一个值得注意的结果是,对于非常小的数组,调用 memcmp 的开销相对于简单的循环来说是一种浪费。 在 .NET Framework 中,对于 10 个元素的数组,循环总体上是最快的。 这并不意外,但需要注意的是:如果你的数组确实很小,不要尝试优化。 然而,循环的扩展性并不好,并且这种优势在只有 1000 个元素的情况下就完全消失了。
更大的区别在于 .NET framework 和 .NET 8 之间。 即使循环在 .NET 8 中也明显更快。 从 .NET 8 到 .NET 9 对于 1GB 数组存在一个奇怪的性能下降,我将单独对此进行调查以尝试确认该结果,这可能是基准测试中的一个故障,因为内存分配是原来的两倍,所花费的时间也是原来的两倍。
当我们查看 IEnumerable<T>.SequenceEqual 时,在 .NET 8 中,对于我们的 1MB 数组,它比 .NET framework 快 500 倍。 在 .NET8 和 .NET9 中,IEnumerable<T>.SequenceEqual 比我机器上的 memcmp 版本更快。
ReadOnlySpan<T>.SequenceEqual 和 IEnumerable<T>.SequenceEqual 之间没有显著差异,差异大约在误差范围内。
memcmp 在各个方面仍然比 SequenceEqual 稍慢。 它仍然非常快,比简单的方法快得多,但显然不再是实现高性能数组比较所必需的了。 当最初的 stackoverflow 答案被编写时,.NET 中没有任何东西可以接近这种性能,因为那是 Span<T> 被添加到运行时之前。
与使用 IEnumerable<T>.SequenceEqual 相比,ReadOnlySpan<T> 实现的一个好处是,我们还可以相信,当我们以 .NET Framework 为目标时,它仍然可以接受地执行。
结论
如果您正在使用 .NET 8 并且不需要在 .NET Framework 运行时中运行,请不要编写自己的实用程序函数,而只需使用 IEnumerable<T>.SequenceEqual,它非常快并且不需要任何外部依赖项即可正常工作。
如果您使用的是 .NET Framework,则引入 System.Memory 并使用 Span<T>.SequenceEquals 而不是依赖外部 C 库。 确保检查对 IEnumerable<T>.SequenceEquals 的任何调用,以确保它们不在大型数组上运行。
其他考虑因素
如果您经常需要比较非常大的数组,并且它们是仅追加的,和/或比较的频率高于构造的频率,那么通过使用一种包含并维护其内容的顺序敏感哈希的数据结构来完全避免比较可能是有意义的。 大多数否定情况可以通过在进行更昂贵的数组比较之前进行哈希比较来排除。 然而,对于改组或删除项目的数组,重建此哈希可能会很昂贵。
源代码
生成这些结果的源代码可在 https://github.com/richardcocks/memcomparison/ 获得。 欢迎提交 Pull Request。