停止同步一切:探索高效的 Edge 数据同步方案
停止同步一切
Carl Sverre 2025 年 3 月
目录
- 一种不同的 Edge 复制方法
- Lazy: 按照你自己的节奏同步
- Partial: 只同步需要的内容
- Edge: 在最接近行动的地方同步
- Consistency: 安全地同步
- 你能用 Graft 构建什么?
- Graft SQLite 扩展 (libgraft)
- 如何参与
- 附录
- 路线图
- 与其他 SQLite 复制解决方案的比较
Partial replication 听起来很简单——只需同步你的应用需要的数据,对吗?但是选择一种方法是很棘手的:logical replication 精确地跟踪每一个更改,从而使强一致性变得复杂,而 physical replication 避免了这种复杂性,但需要同步每一个更改,即使是被丢弃的更改。如果你的应用可以将 physical replication 的简单性与 logical replication 的效率结合起来呢? 这就是 Graft 背后的核心思想,我今天发布的开源事务存储引擎。它专门为 lazy、partial replication 设计,具有强一致性、水平可扩展性和对象存储持久性。
Graft 的设计考虑了以下 用例:
- Offline-first & mobile apps:通过将复制和存储卸载到 Graft,简化开发 并提高可靠性。
- Cross-platform sync:在设备、浏览器和平台之间平滑地共享数据,而无需厂商锁定。
- Stateless multi-writer replicas:在任何地方部署副本,包括 serverless 和 embedded environments。
- Any data type:复制数据库、文件或自定义格式——所有这些都具有强大的数据一致性。
我第一次发现对 Graft 的需求是在构建 SQLSync 时。SQLSync 是一个前端优化的数据库栈,构建在 SQLite 之上,其同步引擎由来自 Git 和分布式系统的思想驱动。SQLSync 使 multiplayer SQLite 数据库成为现实,为直接在你的浏览器中运行的交互式应用提供支持。
然而,SQLSync 将整个更改日志复制到每个客户端——类似于某些数据库实现 physical replication 的方式。虽然这种方法在服务器上运行良好,但它不太适合 edge 和浏览器环境的约束。
在发布 SQLSync 之后,我决定找到一种更适合 edge 的复制解决方案。我需要一些能够:
- 让客户端按照自己的节奏同步
- 只同步他们需要的内容
- 从任何地方同步,包括 edge 和 offline devices
- 复制 任意数据,例如 SQLite 数据库、JSON 文档、文件,甚至自定义二进制格式
- 所有这些都提供 强大的数据一致性保证。
但市场上并没有这样的工具,所以我自己构建了一个。
#一种不同的 Edge 复制方法
![]()
如果你曾经尝试在客户端和服务器之间保持数据同步,你就会知道这比听起来要难。大多数现有的解决方案都属于以下两种阵营之一:
- Full replication,它将整个数据集同步到每个客户端——这对于诸如 serverless functions 或 web apps 之类的受约束环境来说是不切实际的。
- Schema-aware diffs,例如 Change Data Capture (CDC) 或 Conflict-free Replicated Data Types (CRDTs),它们在行或字段级别跟踪逻辑更改——但需要深入的应用程序集成,并且不能推广到任意数据。
Graft 采取了一条不同的道路。
与 full replication 一样,Graft 与 schema 无关。它不知道或不关心你正在存储什么类型的数据——它只是复制字节。但它不会发送所有数据,而是更像 logical replication 一样工作:客户端收到自上次同步以来发生的更改的简洁描述。
该模型的核心是 Volume:一个稀疏的、有序的、固定大小的 Pages 集合。客户端通过事务 API 与 Volumes 交互,在特定的 Snapshots 中进行读取和写入。在底层,Graft 只持久化和复制必要的内容——使用对象存储作为持久、可扩展的后端。
结果是一个 lazy、partial、edge-capable 且一致的系统。
想要尝试 Graft 的托管版本吗? 加入等待列表以获得早期访问权限:在此注册 →
这些属性中的每一个都值得仔细研究——让我们逐一解开它们。
#Lazy: 按照你自己的节奏同步
Graft 专为现实世界而设计——edge 客户端偶尔会醒来,面临不可靠的网络,并在生命周期短、资源受限的环境中运行。客户端不是依赖于连续复制,而是选择 何时 同步,并且 Graft 使快速前进到最新 snapshot 变得容易。
该同步始于一个简单的问题:自上次 snapshot 以来发生了什么变化?
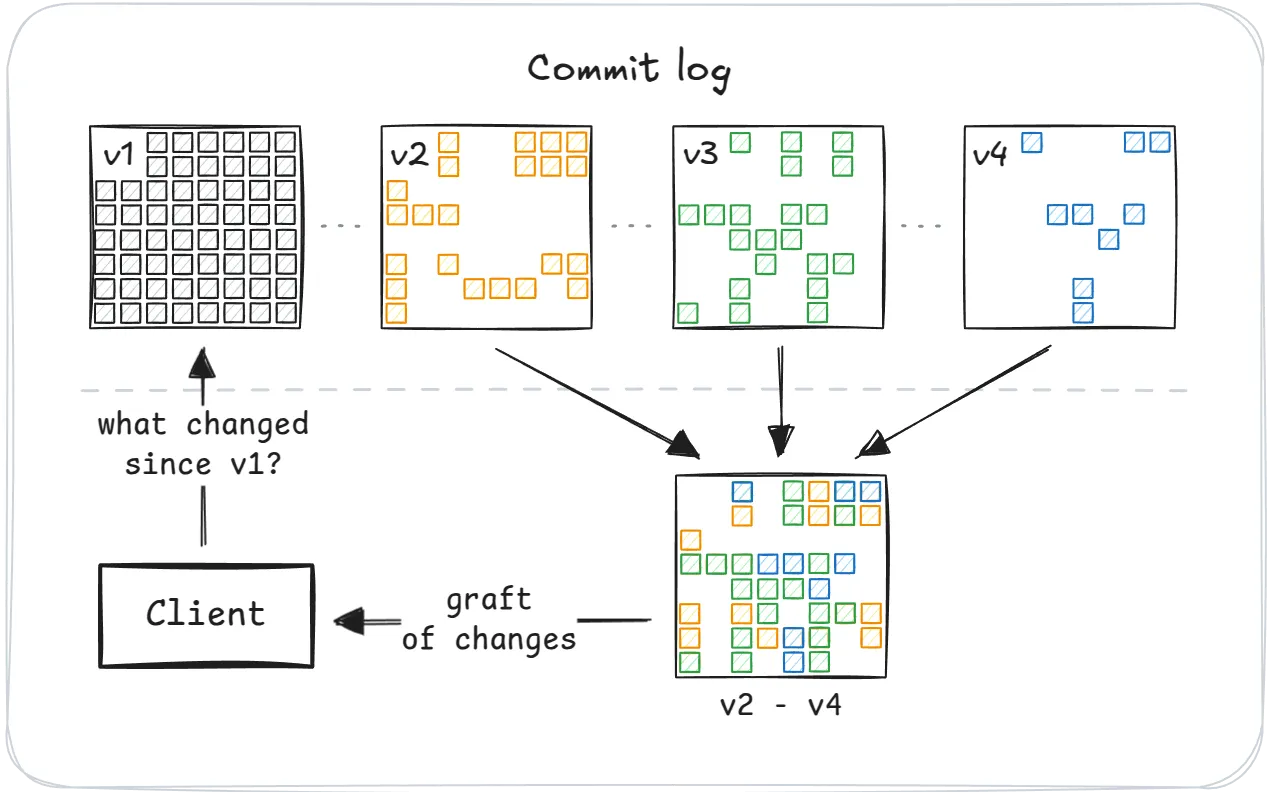
服务器以 graft 作为回应——自该 snapshot 以来所有提交中已更改的页面索引的紧凑位集。这就是该项目名称的由来:graft 将新更改附加到现有 snapshot——就像将分支嫁接到树上一样。它们充当指南,告知客户端哪些页面可以重用,哪些页面需要获取(如果需要)。
至关重要的是,当客户端从服务器拉取 graft 时,它不会收到任何实际数据——只收到有关更改的元数据。这使客户端可以完全控制获取什么以及何时获取,从而为 partial replication 奠定基础。
#Partial: 只同步需要的内容
当你为 edge 环境(浏览器选项卡、移动应用、serverless functions)构建时,你无法负担下载整个数据集,仅仅为了服务于少数查询。这就是 partial replication 发挥作用的地方。
在客户端拉取 graft 之后,它确切地知道发生了什么变化。它可以使用该信息来确定哪些页面仍然有效,哪些页面需要获取。客户端有选择地仅检索他们实际使用的页面——不多也不少,而不是拉取所有内容。

为了保持快速,Graft 支持多种预取页面的方式:
- General-purpose prefetching:Graft 包括一个基于 Leap 算法的内置预取器,该算法通过识别模式来预测未来的页面访问。
- Domain-specific prefetching:应用程序可以利用领域知识来抢先获取相关页面。例如,如果你的应用经常查询用户的个人资料,Graft 可以在需要数据之前预取与该个人资料相关的页面。
- Proactive fetching:如果需要,客户端可以始终回退到拉取所有更改,从而有效地恢复为 full replication。这对于在服务器端运行的 Graft workloads 尤其有用。
而且由于 Graft 将页面直接托管在对象存储上,因此它们自然具有持久性和可扩展性,为 edge-native replication 创建了强大的基础。
#Edge: 在最接近行动的地方同步
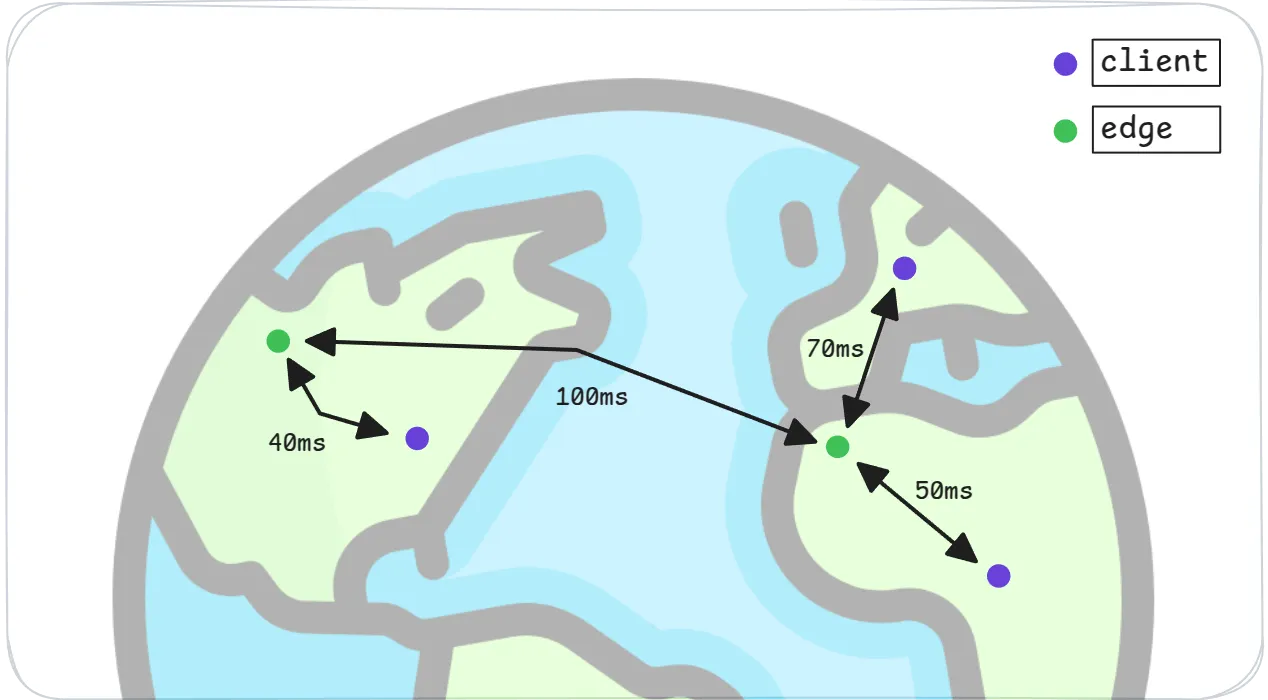
Edge replication 不仅仅是选择要同步哪些数据——而是要确保数据在实际需要的地方可用。Graft 通过两种关键方式做到这一点。
首先,页面通过全球 edge 服务器舰队从对象存储提供,从而允许频繁访问(“hot”)的页面缓存在客户端附近。无论你的用户碰巧在世界的哪个地方,这都可以保持低延迟和高响应能力。
其次,Graft 客户端本身是轻量级的,并且专门设计为嵌入式的。它具有最少的依赖项和极小的运行时,可以集成到诸如浏览器、设备、移动应用和 serverless functions 之类的受约束环境中。
结果呢?你的数据始终缓存在最具价值的地方——就在 edge 并且嵌入在你的应用程序中。
但是,在 edge 上缓存数据带来了新的挑战,尤其是在保持一致性和安全地处理冲突方面。这就是 Graft 的强大一致性模型发挥作用的地方。
#Consistency: 安全地同步
强大的数据一致性至关重要——尤其是在可能偶尔发生冲突的客户端之间同步数据时。Graft 通过提供清晰而强大的数据一致性模型来解决此问题:Serializable Snapshot Isolation。 有关 Graft 的隔离模型的更多详细信息 可以在 readme 中找到。
此模型为客户端提供了在特定 snapshots 中数据的隔离的、一致的视图,允许读取并发进行而不会产生干扰。与此同时,它确保写入是 严格序列化的,因此每个事务始终都有一个清晰的、全局一致的顺序。
但是,由于 Graft 专为 offline-first、lazy replication 设计,因此客户端有时会尝试基于过时的 snapshot 提交更改。盲目地接受这些提交将违反严格的可序列化性。相反,Graft 会安全地拒绝提交,并让客户端选择如何解决这种情况。通常,客户端会:
- Reset and replay,通过拉取最新 snapshot、重新应用本地事务并重试。
- 从全局来看,数据仍然是严格可序列化的。
- 从本地来看,客户端体验 Optimistic Snapshot Isolation,这意味着:
- 读取始终观察内部一致的 snapshots。
- 但是,如果提交被拒绝,则稍后可能会丢弃这些 snapshots。
- Merge 将其本地状态与来自服务器的最新 snapshot 合并。这可能会将全局一致性模型降级为 snapshot isolation。
- 永久 Fork the volume,创建一个新的、单独的 volume——从而保持全局可序列化性。
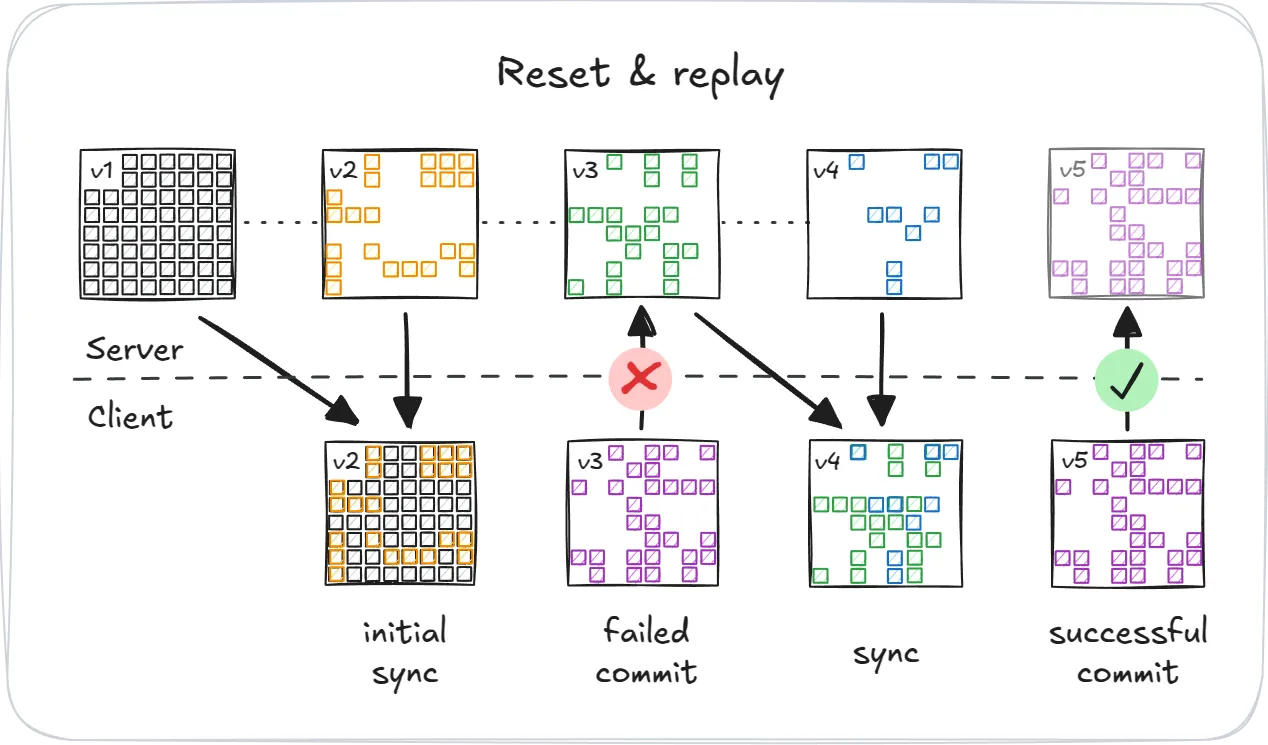
简而言之,Graft 确保你永远不必牺牲数据一致性——即使客户端零星地同步、offline 运行或与并发写入发生冲突。
#你能用 Graft 构建什么?
结合 lazy syncing、partial replication、edge-friendly deployment 和强大的数据一致性,Graft 为各种 edge-native applications 提供了强大的基础。以下是你可以使用 Graft 构建的一些示例:
Offline-first apps:部分 offline 运行的笔记、任务管理或 CRUD 应用。Graft 负责同步,从而使应用程序可以忘记网络的存在。与冲突处理程序结合使用时,Graft 还可以在任意数据之上启用 multiplayer。
Cross-platform data:消除厂商锁定,并允许你的用户在移动平台、设备和 web 上无缝访问其数据。Graft 的架构可以嵌入到任何地方。
Stateless read replicas:由于 Graft 的独特的 replication 方法,可以启动一个没有本地状态的数据库副本,检索最新的 snapshot 元数据,并立即开始运行查询。无需下载所有数据并重播日志。
Replicate anything:Graft 只专注于一致的页面复制。它不关心这些页面中的内容。所以尽情发挥吧!使用 Graft 同步 AI 模型、Parquet 或 Lance 文件、Geospatial tilesets,或者只是你的 cats 的照片。使用 Graft,天空才是极限。
#Graft SQLite 扩展 (libgraft)
如今,libgraft 是开始使用 Graft 的最简单方法。它是一个 native SQLite 扩展,可在 SQLite 可以运行的任何地方工作。它使用 Graft 仅复制客户端实际使用的数据库部分,从而可以在资源受限的环境中运行 SQLite。
libgraft 实现了 SQLite virtual file system (VFS),从而可以拦截对数据库的所有读取和写入。当在 WAL mode 中运行时,它提供与 SQLite 相同的事务和并发语义。使用 libgraft 为你的应用程序提供以下好处:
- 异步 replication 到和从对象存储
- edge 和 devices 上的 lazy partial replicas
- Serializable Snapshot Isolation
- point in time restore
如果你有兴趣使用 libgraft,你可以在这里找到文档。
#如何参与
Graft 在 GitHub 上公开开发,非常欢迎来自社区的贡献。你可以打开 issue、参与讨论或提交 pull requests——请查看我们的 contribution guide 以获取详细信息。
如果你想聊聊 Graft,加入 Discord 或给我发送电子邮件。我很乐意听到你对 Graft 的 lazy、partial edge replication 方法的反馈。
我还计划推出 Graft Managed Service。如果你想加入等待列表,你可以 在此注册。
但是等等,还有更多! 继续阅读以了解 Graft 的路线图以及 Graft 与现有 SQLite 复制解决方案之间的详细比较。
#附录
#路线图
Graft 是一年研究、多次迭代和一个主要转折的结果。但是 Graft 远未完成。还有很多需要构建,而且路线图雄心勃勃。以下是计划的内容(不分先后顺序):
WebAssembly support:支持 WebAssembly (Wasm) 将允许 Graft 在浏览器中使用。我希望最终支持 SQLite 的官方 Wasm build、wa-sqlite 和 sql.js。
Integrating Graft and SQLSync:一旦 Graft 支持 Wasm,将其与 SQLSync 集成将非常简单。该计划是拆分出 SQLSync 的 mutation、rebase 和 query subscription 层,以便它可以位于使用 Graft replication 的数据库之上。
More client libraries:我很乐意看到流行的语言(包括 Python、Javascript、Go 和 Java)的 native Graft-client wrappers。这将允许 Graft 用于复制这些语言中的任意数据,而不是仅限于 SQLite。
Low-latency writes:Graft 当前会阻止 push 操作,直到它们已完全提交到对象存储中。这可以通过多种方式解决:
- 试验 S3 express zone
- 在位于对象存储前面的低延迟持久共识组中缓冲写入。
Garbage collection, checkpointing, and compaction:这些功能是最大化查询性能、最小化浪费的空间以及启用永久删除数据所必需的。它们都与 Graft 决定将数据直接存储在对象存储中并将更改批量处理到称为段的文件中有关。
Authentication and authorization:这是一个相当广泛的任务,涵盖从 Graft managed service 上的帐户到细粒度的授权以读取/写入 Volumes 的所有内容。
Volume forking:Graft service 已经设置为执行零拷贝 fork,因为它可以通过简单地将 Segment 引用复制到新的 Volume。但是,要执行本地 fork,Graft 当前需要复制所有页面。可以通过在本地分层 volume 并允许读取 fall through 或更改本地寻址页面的方式来解决此问题。
Conflict handling:Graft 应提供内置的冲突解决策略和扩展点,以便应用程序可以控制如何处理冲突。最初的内置策略将自动合并不重叠的事务。虽然这会将全局一致性放松到 optimistic snapshot isolation,但它可以显着提高协作和 multiplayer 场景中的性能。
#与其他 SQLite 复制解决方案的比较
Graft 建立在许多其他项目率先提出的想法之上,同时为该领域增加了其独特的贡献。以下是 SQLite 复制领域的简要概述以及 Graft 的比较。
注意 本节中的信息是从文档和博客文章中收集的,可能不是完全准确。如果我歪曲或误解了一个项目,请告诉我。
#mvSQLite
在基于 SQLite 的项目中,mvSQLite 在概念上与 Graft 最接近。它实现了一个自定义 VFS 层,该层将 SQLite 页面直接存储在 FoundationDB 中。
在 mvSQLite 中,每个页面都按其内容哈希存储,并通过 (page_number, snapshot version) 引用。此结构允许读者根据需要 lazy 地从 FoundationDB 获取页面。通过利用页面级别的版本控制,mvSQLite 支持并发写入事务,前提是它们的读写集不重叠。
Graft 的比较:Graft 和 mvSQLite 共享相似的存储层设计,使用页面级别的版本控制来实现 lazy、按需获取和 partial 数据库视图。主要区别在于数据存储位置以及如何跟踪页面更改。mvSQLite 依赖于 FoundationDB,要求所有节点都具有直接集群访问权限——这使其不适合于广泛分布的 edge devices 和 web applications。此外,Graft 基于 Splinter-based 的更改集是独立的、易于分发的,并且不需要直接查询 FoundationDB 来确定已更改的页面版本。
#Litestream
Litestream 是一种流式备份解决方案,可将 SQLite WAL 帧持续复制到对象存储。其主要重点是异步持久性、point-in-time restore 和 read replicas。它在你的应用程序外部运行,通过文件系统监视 SQLite 的 WAL。
Graft 的比较:与 Litestream 不同,Graft 通过其自定义 VFS 直接集成到 SQLite 的提交过程中,从而实现 lazy、partial replication 和分布式写入。与 Litestream 一样,Graft 将页面复制到对象存储,并支持 point-in-time restores。
#cr-sqlite
cr-sqlite 是一个 SQLite 扩展,它将表转换为 Conflict-free Replicated Data Types (CRDTs),从而实现逻辑的、行级别的复制。它提供自动冲突解决,但需要 schema 感知和应用程序级别的集成。
Graft 的比较:Graft 与 schema 无关,并且不依赖于逻辑 CRDTs,从而使其与任意 SQLite 扩展和自定义数据结构兼容。但是,为了实现全局可序列化性,Graft 希望应用程序显式处理冲突解决。相比之下,cr-sqlite 会自动合并来自多个写入者的更改,从而实现 causal consistency。
#Cloudflare Durable Objects with SQLite Storage
通过将 Durable Objects 与 SQLite 结合使用,你将获得一个强一致且高度持久的数据库,其中包含你的业务逻辑,并且托管在 Cloudflare 庞大的 edge 网络中(希望离你的用户很近)。在底层,此解决方案类似于 Litestream,因为它将 SQLite WAL 复制到对象存储并执行周期性检查点。
Graft 的比较:Graft 将复制作为一流公民公开,并且旨在高效地复制到和从 edge。相比之下,Durable Objects 中的 SQLite 专注于使用 SQLite 的全部功能扩展 Durable Objects。
#Cloudflare D1
Cloudflare D1 是一个托管的 SQLite 数据库,其运行方式类似于传统的数据库服务(例如 Amazon RDS 或 Turso),应用程序通过 HTTP API 访问它。
Graft 的比较:Graft 将数据直接复制到 edge,将其嵌入到客户端应用程序中。这种分散的复制模型与 D1 的集中式数据服务形成鲜明对比。
#Turso & libSQL
Turso 通过 libSQL(一个开源 SQLite fork)提供托管的 SQLite 数据库和嵌入式副本。与 Litestream 和 Cloudflare Durable Objects SQL Storage 类似,Turso 将 SQLite WAL 帧复制到对象存储并定期检查点。副本通过检索这些检查点并重播日志来赶上进度。
Graft 的比较:Graft 通过 partial replication 和对任意的、与 schema 无关的数据结构的支持来区分自己。Graft 的后端服务直接在页面级别运行,并将整个事务生命周期外包给客户端。
#rqlite & dqlite
rqlite 和 dqlite 背后的关键思想是在多个服务器上分布 SQLite。这是通过基于 Raft 的共识和通过网络协议将 SQLite 操作路由到当前的 Raft leader 来实现的。
Graft 的比较:这些项目专注于通过共识和传统复制来提高 SQLite 的持久性和可用性。它们旨在跨一组有状态节点进行扩展,这些节点维护着彼此的连接。Graft 的根本不同之处在于,它是一个构建在对象存储之上的无状态系统,旨在将数据复制到和从 edge 复制。
#Verneuil
Verneuil 专注于通过对象存储将 SQLite snapshots 异步复制到 read replicas,从而在不引入其他故障模式的情况下优先考虑可靠性。Verneuil 明确避免使用减少复制延迟或陈旧性的机制。
Graft 的比较:Graft 的行为更像一个 multi-writer 分布式数据库,强调选择性的、实时的 partial replication。同时,Verneuil 的方法强调单向异步 snapshot replication,而没有保证复制新鲜度。