Jargonic:行业可调优的 ASR 模型介绍
Jargonic 发布:世界上最精确的行业定制 ASR 模型
简介
在过去十年中,自动语音识别 (ASR) 取得了显著进步,但市场上大多数 ASR 模型提供的都是通用转录。它们在干净、受控的环境中表现良好,但在处理以下情况时会失效:
- 技术术语和首字母缩略词 – 标准 ASR 模型无法识别大多数行业中使用的专业术语(即,医疗术语、制造术语等)。
- 嘈杂的工业环境 – 背景噪音、重叠的语音和其他降低转录质量的实际条件。
- 缺乏实时适应性 – 大多数 ASR 模型需要大量再训练才能在新领域中有效工作。
Jargonic 是 aiOla 用于 ASR 的新型基础模型,通过高级领域自适应、实时上下文关键词识别和零样本学习来解决这些问题,使其能够开箱即用地处理行业特定语言,并支持实际的企业部署。
Jargonic 的工作原理
Jargonic 利用最先进的 ASR 架构,专为企业级应用而设计,确保卓越的鲁棒性和精度,尤其是在专业行业词汇方面。
Jargonic 没有依赖大量的微调,而是采用了一种上下文感知的自适应学习机制,使其能够在无需再训练的情况下识别特定领域的术语。专业术语由专有的关键词识别 (KWS) 机制检测,该机制深度集成到 ASR 架构中。与需要手动管理词汇表的标准 ASR 模型不同,Jargonic 通过其推理管道学习并自动适应行业特定的术语。也就是说,关键词不需要以声音方式给出,并且不需要进一步的训练或微调即可将新关键词(例如,术语)引入系统。
结合关键词识别与 ASR
Jargonic 的方法将专有的 KWS 机制与高级语音识别集成在一个两阶段架构中。首先,专有的 KWS 系统识别音频流中是否存在领域特定的术语。然后,此上下文信息通过自适应层馈送到核心 ASR 引擎,有效地将模型的生成引导到相关的领域上下文。
这种架构使 Jargonic 能够在处理专业词汇识别的同时,实现通用语音的卓越准确性。KWS 系统是零样本的,只需提供新的关键词列表即可立即重新配置为不同的行业词汇表,从而可在任何具有大量专业术语的语音领域中实现灵活性。通过这种方法,Jargonic 提高了包含行业特定术语的音频样本的整体准确性,同时消除了通常领域自适应所需的资源密集型再训练。
用于多语言语音识别的创新噪声鲁棒性
Jargonic 使用一种与语言无关的专有噪声处理方法进行训练。与传统方法不同,我们开发了一种专门的数据增强过程,该过程在不同条件下利用各种类型的工业噪声,无论是否存在语音。这种方法是语言独立的,使我们的模型能够保持一致的性能,而不管正在处理哪种语言。传统的噪声鲁棒性技术通常添加主要针对英语优化的基本白噪声或混响模式,这可能会对模型在处理日语或德语等其他语言时推广性能改进的能力产生负面影响。我们的方法通过使用来自工业环境的真实噪声配置文件和一个可在整个语言套件中有效推广的管道来避免此限制,从而即使在制造业车间等具有挑战性的声学环境中也能确保可靠的转录。
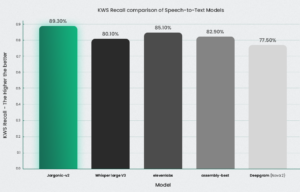
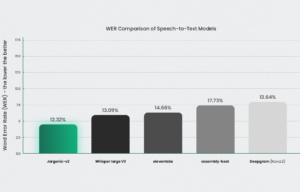
性能基准
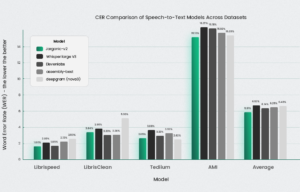
这些图表比较了 Jargonic V2 与 OpenAI Whisper (v3)、DeepGram、AssemblyAI 和 ElevenLabs 在多种语言上的性能。一个图表说明了词错误率 (WER),其中较低的值表示更好的性能,而另一个图表显示了术语的召回率,其中较高的值是首选。总的来说,Jargonic V2 在大多数语言和数据集上实现了卓越的 WER,并且在关键词检测和转录方面始终优于所有其他模型。
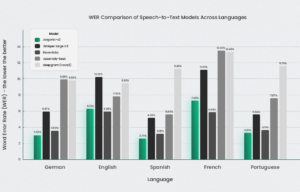
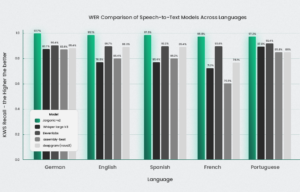
即使没有关键词识别机制,Jargonic V2 也能取得出色的效果。图 3 显示了各种英语数据集的英语结果。它表明,在大多数情况下,Jargonic V2 优于竞争对手,在大多数测试用例中表现出卓越的性能,并在所有基准测试中保持最高的平均性能。

作者
Assaf Asbag
Assaf Asbag 是一位经验丰富的技术和数据科学专家,拥有超过 15 年的经验,目前担任 aiOla 的首席技术和产品官 (CTPO),他在那里推动 AI 创新和市场领导地位。