加速结构(Acceleration Structures)的测量
Measuring acceleration structures
31 Mar 2025
硬件加速光线追踪,如 DirectX 12 和 Vulkan 所支持的那样,依赖于一种抽象的数据结构来存储场景几何体,这种结构被称为“加速结构”(acceleration structure),通常也称为“BVH”或“BLAS”。与光栅化的几何体表示不同,渲染引擎无法自定义数据布局;与纹理格式不同,其布局在不同供应商之间没有标准化。
这看起来可能是一件小事——当然,到 2025 年,所有实现在内存消耗方面都应该很接近了,主要的竞争集中在光线遍历性能和新的光线追踪特性上?让我们来看看。
实验设置
在这里做出任何概括性的声明都将很困难;而且测试这个需要使用许多不同供应商的许多不同的 GPU,这非常耗时。因此,为了本文的目的,我们将只关注一个场景——Amazon Lumberyard Bistro,或者更具体地说,是 Nvidia 的一个略微定制的版本,它比默认的 FBX 下载使用了更多的实例化。
结果是通过运行 niagara 渲染器捕获的;如果您想跟着做,您将需要 Vulkan 1.4 SDK 和驱动程序,以及类似这样的东西:
git clone https://github.com/zeux/niagara --recursive
cd niagara
git clone https://github.com/zeux/niagara_bistro bistro
cmake . && make
./niagara bistro/bistro.gltf
代码将解析 glTF 场景,转换网格以使用 fp16 位置,为每个网格构建一个 BLAS1,使用 VK_KHR_acceleration_structure 扩展的相关部分对其进行压缩,并打印生成的压缩大小。虽然在场景加载时会构建多个细节级别,但只有原始几何体会进入加速结构,总共有 1.754M 个三角形2。
构建使用 PREFER_FAST_TRACE 构建模式;在某些驱动程序上,使用 LOW_MEMORY 标志可以在牺牲一些遍历性能的情况下进一步减小 BLAS 大小,我们现在将忽略这一点。
实验结果
在所有相应供应商的最新(截至 3 月底)驱动程序上,在一系列不同的 GPU 上运行此程序,我们得到以下结果;总 BLAS 大小与近似的“字节/三角形”数一起呈现——计算这个数字实际上是不正确的,但我们仍然会这样做。
GPU | BLAS size | Bytes/triangle
---|---|---
AMD Ryzen 7950X (RDNA2 iGPU) | 100 MB | 57.0
AMD Radeon 7900 GRE (RDNA3) | 100 MB | 57.0
AMD Radeon 9070 (RDNA4) | 84 MB | 47.9
NVIDIA GeForce RTX 2080 | 46 MB | 26.5
NVIDIA GeForce RTX 3050 | 45 MB | 25.7
NVIDIA GeForce RTX 4090 | 45 MB | 25.7
NVIDIA GeForce RTX 5070 | 33 MB | 18.8
Intel Arc B580 | 79 MB | 45.0
哇,差距真大!早期 AMD GPU 和最新的 NVIDIA GPU 之间的差距是 3 倍;比较最新的 AMD 和 NVIDIA GPU,我们仍然看到内存消耗方面存在 2.5 倍的差异。Intel3 略微领先于 RDNA4,BLAS 比 NVIDIA 大 2.4 倍。
现在,此表呈现每个 BLAS 内存消耗作为 GPU 的函数——很明显,GPU 世代对内存消耗有一些影响。然而,另一个重要的促成因素是软件,或者更具体地说是驱动程序。对于 AMD,我们可以比较过去一年中各种驱动程序版本的结果,以及在同一 GPU (Radeon 7900 GRE) 上的替代驱动程序 radv4:
Driver (RDNA3) | BLAS size | Bytes/triangle
---|---|---
AMDVLK 2024.Q3 | 155 MB | 88.4
AMDVLK 2024.Q4 | 105 MB | 59.9
AMDVLK 2025.Q1 | 100 MB | 57.0
radv (Mesa 25.0) | 241 MB | 137.4
正如我们所看到的,在过去的 9 个月中,在相同的 AMD GPU 和相同的驱动程序代码库上,BLAS 内存消耗逐渐提高了 1.5 倍5,而如果您使用 radv,您的 BLAS 消耗现在比官方 AMD 驱动程序大 2.4 倍,更不用说最新的 NVidia GPU 了6。
嗯……这当然是很多不同的数字。让我们尝试理解至少其中的一些。
心理模型
让我们尝试构建一些模型来帮助我们理解我们应该期望什么。对于 1.754M 个三角形来说,100 MB 好吗?241 MB 坏吗?现在是时候谈谈 BVH 实际上是什么了。
首先,让我们结合我们正在输入多少数据来理解这一点。Vulkan / DX12 API 的工作方式是,应用程序向驱动程序提供几何体描述,该描述可以是三角形的平面列表,也可以是顶点索引缓冲区对。与光栅化不同,在光栅化中,顶点可以携带以应用程序想要的方式打包的各种属性,对于光线追踪,您只需指定每个顶点的位置,并且格式受到更严格的指定。如上所述,在这种情况下,我们向驱动程序提供 fp16 数据——这很重要,因为在 fp32 数据上,您可能会看到不同的结果,并且供应商之间的差异不会那么大。7
索引缓冲区是您通常在光栅化中看到的 32 位或 16 位数据;但是,在大多数或可能所有情况下,索引缓冲区只是一种将您的几何体传达给驱动程序的方式——与光栅化不同,在光栅化中您的索引和顶点缓冲区的效率至关重要,在这里,驱动程序通常会构建加速结构,而不考虑显式索引信息。
然后,平面三角形位置列表将占用每个三角形角 6 字节 * 每个三角形 3 个角 * 1.754M 个三角形 = 31.5 MB。这不是最节省内存的存储方式:此场景使用 1.672M 个唯一顶点,因此使用 16 位索引缓冲区将需要约 10 MB 用于顶点位置和约 10.5 MB 用于索引,并且一些 meshlet 压缩方案可以低于该值8;但无论如何,我们对不是非常高效的几何体存储的基线可能在 20-30 MB 左右,或者每个三角形最多 18 字节。
平面三角形列表没有用——驱动程序需要构建可用于有效跟踪光线的目标。这些结构通常被称为“BVH”——边界体积层次结构——并表示一个具有低分支因子的树,其中中间节点定义为边界框,而叶节点存储三角形。我们将在下一节中介绍具体的例子。
通常,您希望此结构具有较高的内存局部性——当在该数据结构中遇到三角形时,您不希望必须在内存中的其他位置查找该三角形的顶点数据。此外,Vulkan 和 DX12 允许访问光线命中的三角形 ID(必须与原始提供的数据中三角形的索引匹配);此外,多个网格几何体可以组合在一个树中,并且为了光线追踪性能,将几何体分成单独的子树是不经济的,因此三角形信息还必须携带几何体索引。有了这一切,我们得到了类似这样的东西:
struct BoxNode
{
float3 aabb_min[N];
float3 aabb_max[N];
uint32 children[N];
};
struct TriangleNode
{
float3 corners[3];
uint32 primid;
uint32 geomid;
};
N 是分支因子;虽然理论上可以在 2(对于二叉树)到 32 这样非常大的数字之间取任何数字,但在实践中,我们应该期望一个小的数字,该数字允许硬件快速测试相对较少数量的 AABB 相对于光线;我们现在假设 N=4。9

当 N=4 并且处处都是 fp32 坐标时,BoxNode 为 112 字节,TriangleNode 为 44 字节。如果这两个结构都使用 fp16 代替,我们将获得 64 字节用于框,26 字节用于三角形。我们(主要……)知道我们应该有多少三角形节点——每个输入三角形一个——但是有多少个框呢?
嗯,对于分支因子为 4 的树,如果我们有 1.754M 个叶节点(三角形),我们希望在下一层获得 1.754M/4 = 438K 个框节点,在下一层获得 438K/4 = 109K 个框节点,在下一层之后获得 109K/4 = 27K 个框节点,在下一层之后获得 27K/4 = 6.7K 个框节点,一直到我们到达根——这给了我们大约 584K 个框节点。如果您不想一次一步地使用枯燥的除法,这大约是三角形节点的三分之一,这是由 阿基米德在大约 2250 年前发现的。
方便的是,这意味着 N 个三角形应大约占用 N*sizeof(TriangleNode) + (N/3)*sizeof(BoxNode) 内存,或每个三角形 sizeof(TriangleNode) + sizeof(BoxNode)/3 字节。使用 fp32 坐标,这给了我们每个三角形约 81.3 字节,使用 fp16,则为约 47.3 字节。
由于多种原因,此分析不精确。它忽略了不平衡树的潜力(并非所有框都可以使用 4 个子节点来实现最佳空间分割);它忽略了各种硬件因素,如内存对齐和额外数据;它假设了一组特定的节点大小;并且它假设叶(三角形)节点的数量等于输入三角形的数量。当我们尝试了解 BVH 实际 如何工作时,让我们重新审视这些假设。
radv
由于 BVH 的内存布局最终取决于特定供应商的硬件和软件,并且我不希望过度概括这一点,因此让我们专注于 AMD。
AMD 的优势在于拥有其 RDNA 架构的多个版本——尽管 RDNA2 和 RDNA3 之间没有任何会影响内存大小的变化——并且拥有文档以及开源驱动程序。现在,需要注意的是,AMD 实际上没有正确记录 BVH 结构(预期的节点内存布局应该是 RDNA ISA 的一部分,但事实并非如此——AMD,请修复此问题),但在两个开源驱动程序之间,应该有足够的详细信息可用。相比之下,我们几乎对 NVidia 一无所知,但他们显然在这方面具有显着的竞争优势,因此他们可能有一些东西要隐藏。10
AMD 实现光线追踪的方式如下:硬件单元(“光线加速器”)可以作为类似于纹理提取的指令访问着色器核心;每个指令都提供了一个指向单个 BVH 节点和光线信息的指针,并且可以自动执行针对节点中所有框或三角形的光线-框或光线-三角形测试并返回结果。然后,驱动程序负责:
- 在构建时,生成由与 HW 格式匹配的节点组成的 BVH
- 在渲染时,构建遍历树的着色器代码,使用用于节点测试的特殊指令
虽然 RT 格式的官方文档缺乏,但我们不必进行逆向工程,因为我们有两个带有源代码的独立驱动程序。
radv,这是一个非官方驱动程序,是 Linux 和 SteamOS 上的默认驱动程序,它具有非常干净且易于阅读的代码库,该代码库将结构定义如下:
struct radv_bvh_triangle_node {
float coords[3][3];
uint32_t reserved[3];
uint32_t triangle_id;
/* flags in upper 4 bits */
uint32_t geometry_id_and_flags;
uint32_t reserved2;
uint32_t id;
};
struct radv_bvh_box16_node {
uint32_t children[4];
float16_t coords[4][2][3];
};
struct radv_bvh_box32_node {
uint32_t children[4];
vk_aabb coords[4];
uint32_t reserved[4];
};
这些应该是不言自明的(vk_aabb 有 6 个浮点数来表示最小值/最大值),并且主要映射到我们之前的草图。由此我们可以推断出 RDNA GPU 支持 fp16/fp32 框节点,但需要对三角形节点使用完整的 fp32 精度。此外,这里的三角形节点为 64 字节,fp16 框节点为 64 字节,fp32 框节点为 128 字节:也许毫不奇怪,GPU 喜欢对齐事物,这反映在这些结构中。
更仔细地查看源代码,您可以发现一些额外的内存 分配来存储“父链接”:对于整个 BVH 的每 64 个字节,驱动程序分配一个 4 字节的值,该值将存储与此 64 字节块关联的节点的父索引(由于对齐,每个 64 字节对齐的块只是一个节点的一部分)。这对于遍历很重要:着色器使用一个小堆栈进行遍历,该堆栈保留当前正在遍历的节点的索引,但该堆栈可能不足以满足大型树的完整深度。为了解决这个问题,可以回退到使用这些父链接——可以以完全无堆栈的形式实现递归遍历,但是对于每一步从内存中读取额外的父指针的成本可能高得令人望而却步。
另一个更关键的观察结果是,在撰写本文时,radv 不支持 fp16 框节点——发出的所有框节点都是 fp32。因此,我们可以尝试使用 radv 结构重做我们之前的分析:
- 三角形节点 64 字节/三角形
- 框节点 128 * 1/3 ~= 43 字节/三角形
- 父链接 (64 + 43) / 64 * 4 ~= 7 字节/三角形
… 总共 ~114 字节/三角形,我们希望从 radv 获得。现在,radv 的 实际 数据是 137 字节/三角形 - 未解释的 23 字节!现在是时候提到,虽然我们希望树是完全平衡的,并且分支因子确实是 4,但在现实中,我们希望存在一定程度的不平衡——这既是构建这些树的算法的本质,这些算法本质上是高度并行的并且并不总是达到最佳状态,也是由于一些几何体配置只需要树的一部分中稍微不均匀的分割以获得最佳遍历性能11。
AMDVLK
鉴于 BVH 节点的硬件格式是固定的,因此 BVH 可以占用多少内存似乎没有那么大的回旋余地。使用 fp32 框节点,我们估计 BVH 在 AMD 硬件上至少可以占用 114 字节/三角形,但即使我们从官方驱动程序中看到的最大数字也是 88.4 字节/三角形。这是怎么回事?
现在是时候查阅官方 AMD 光线追踪实现了。它或多或少是在 Windows 和 Linux 版本的 AMD 驱动程序中运行的内容;它可能应该被视为权威来源,尽管不幸的是它比 radv 难得多。
特别是,它不包含 BVH 节点的 C 结构定义:那里的大部分代码都在 HLSL 中,它使用带有宏偏移的单个字段写入。也就是说,对于 RDNA2/3,我们需要更仔细地查看 三角形节点:
// Note: GPURT limits triangle compression to 2 triangles per node. As a result the remaining bytes in the triangle node
// are used for sideband data. The geometry index is packed in bottom 24 bits and geometry flags in bits 25-26.
#define TRIANGLE_NODE_V0_OFFSET 0
#define TRIANGLE_NODE_V1_OFFSET 12
#define TRIANGLE_NODE_V2_OFFSET 24
#define TRIANGLE_NODE_V3_OFFSET 36
#define TRIANGLE_NODE_GEOMETRY_INDEX_AND_FLAGS_OFFSET 48
#define TRIANGLE_NODE_PRIMITIVE_INDEX0_OFFSET 52
#define TRIANGLE_NODE_PRIMITIVE_INDEX1_OFFSET 56
#define TRIANGLE_NODE_ID_OFFSET 60
#define TRIANGLE_NODE_SIZE 64
所以它仍然是 64 字节;但是这个“NODE_V3”字段是什么,这个三角形压缩是什么?确实,radv_bvh_triangle_node 结构在 coords 数组之后有一个字段 uint32_t reserved[3];;事实证明,AMD HW 格式中的 64 字节三角形节点可以存储多达 2 个三角形,而不仅仅是一个。
AMD 文档将其称为“三角形压缩”或“对压缩”。在 Intel 的硬件中也可以看到相同的概念,称为“QuadLeaf”。在任何一种情况下,节点都可以存储共享边的两个三角形,这只需要 4 个顶点。三角形不必共面;硬件交集引擎将忠实地将光线与两者相交,并根据需要返回一个或两个交点。
现在,这种类型的共享并非总是可能的。例如,如果输入由不相交的三角形组成的三角形汤组成,那么我们将遇到每个叶节点一个三角形的最坏情况。在某些情况下,即使可以合并两个三角形,如果其中一个三角形大得多,这样做也可能会损害 SAH 指标。但是,一般来说,我们希望将很多三角形分组为一对。
这大大改变了我们的分析:
- 对于叶子,我们只有 32 字节/三角形,而不是 64 字节/三角形
- 由于我们的叶子数量只有一半,我们也将只有一半的框节点,约为 21 字节/三角形
- 父链接成本也相应减少了一半,约为 4 字节/三角形
这将总数提高到 57 字节/三角形……假设理想条件:所有三角形都可以成对合并,所有节点的分支因子为 4(我们知道根据 radv 结果,这可能是不正确的)。实际上,这是 AMD 驱动程序在 2024.Q3 驱动程序中运行的配置,它的 88 字节/三角形 - 比预期多 31 字节 - 这可能是我们预期的框节点数量更多,以及三角形配对不太完美的结果。这里的另一个怪癖是 AMDVLK 驱动程序实现了所谓的 SBVH:单个三角形可以“拆分”到多个 BVH 节点上,从而有效地在树中多次出现。这有助于长三角形的光线追踪性能,并且可能会进一步扭曲我们的统计数据,因为存储在叶节点中的三角形数量实际上可能大于提供的输入!12
radv 目前没有实现任何优化;重要的是,除了这会显着影响内存消耗外,我预计这也会对光线追踪成本产生重大影响 - 实际上,我的测量结果表明,radv 在此场景中的速度明显慢于官方 AMD 驱动程序,但那是另一个故事。
现在,AMD 的 2024.Q4 版本中发生了什么?如果我们密切跟踪源代码更改(这是非平凡的,因为提交结构是从源代码转储中删除的,但我很高兴我们至少有这么多!),很明显发生的事情是 fp16 框节点现在默认启用。在此之前,框节点默认使用 fp32,并且通过此更改,许多框节点将改为使用 fp16。
在某些特定条件下会发生这种情况 - 如果您从 radv 结构中注意到,fp32 框节点还有一个 reserved 字段,而 fp16 框节点没有 - 此字段实际上用于存储一些额外的,在某些情况下可能被认为对每个节点都很重要的信息13。但无论如何,RDNA2/3 系统的 完美 配置似乎是:
- 每个 64 字节叶子 2 个三角形 = 32 字节/三角形
- 64 字节 fp16 框 * 1/3 * 1/2 = 11 字节/三角形
- 每个 64b 4 字节的父链接 = 3 字节/三角形
… 总共 46 字节/三角形。这是绝对最好的情况,正如我们之前看到的那样,期望对于像 Bistro 这样的复杂几何体是不现实的;AMD 驱动程序中的最佳结果使用 57 字节/三角形,比理论上的最佳结果多 11 字节。14
值得注意的是,2025.Q1 版本将内存消耗从 ~60 字节/三角形降低到 ~57 字节/三角形。由于我们知道与最佳结构相比,在各种结构效率低下中会丢失一些内存,因此将来可能会从这方面榨取更多汁 - 但鉴于硬件单元期望使用固定格式,并且如果您需要保持良好的跟踪性能,则不可避免地会损失一些效率,因此剩余的收益将受到限制。
RDNA4
… 直到下一个硬件修订版。
虽然 RDNA3 在很大程度上保留了 RDNA2 的 BVH 格式(一些以前保留的位现在用于各种剔除标志,但这是一个不影响内存消耗的微小变化),但 RDNA4 似乎完全重新设计了存储格式。据推测,由于 radv 在没有更改的情况下工作,因此仍然支持所有先前的节点类型,但 gpurt 实现了两个主要的新节点类型:
顾名思义,BVH8 节点存储 8 个子节点;它不是使用 fp16 作为框边界,而是以特殊格式15存储框角,该格式具有 12 位尾数和在所有角之间共享的 8 位指数,以及完整的 fp32 原点角。总共有 128 字节 - 从内存的角度来看,它与 RDNA2/3 中的两个 fp16 BVH4 节点一样多,但它应该允许边界框值的完整 fp32 范围 - fp16 框节点无法表示坐标在 +-64K 之外的几何体! - 因此我预计 RDNA4 BVH 数据不需要使用任何 BVH4 节点,这允许 AMD 将其他类型的数据嵌入到框节点中,例如用于其新旋转支持的 OBB 索引和父指针(您可能还记得,以前需要单独分配)。
struct ChildInfo
{
uint32_t minX : 12;
uint32_t minY : 12;
uint32_t cullingFlags : 4;
uint32_t unused : 4;
uint32_t minZ : 12;
uint32_t maxX : 12;
uint32_t instanceMask : 8;
uint32_t maxY : 12;
uint32_t maxZ : 12;
uint32_t nodeType : 4;
uint32_t nodeRange : 4;
};
struct QuantizedBVH8BoxNode
{
uint32_t internalNodeBaseOffset;
uint32_t leafNodeBaseOffset;
uint32_t parentPointer;
float3 origin;
uint32_t xExponent : 8;
uint32_t yExponent : 8;
uint32_t zExponent : 8;
uint32_t childIndex : 4;
uint32_t childCount : 4;
uint32_t obbMatrixIndex;
ChildInfo childInfos[8];
};
图元节点与三角形节点有些相似,但它更大(128 字节)并且用途更广:它可以存储每个节点可变数量的三角形对,并且使用看起来像微网格格式的东西来执行此操作,其中三角形对使用顶点索引,128 字节数据包的单独部分存储顶点位置 - 每个顶点使用可变数量的位来存储位置。
对于位置存储,单个节点中坐标内的所有位都分为三个部分:前缀(对于同一轴的所有浮点数必须相同),值,尾随零;对于同一轴上的节点中的所有顶点,所有部分都具有相同的位宽。对于 fp16 源位置,我预计前缀存储会删除位置之间共享的初始位段,这些位置在空间上会很接近,并且大部分尾随 fp32 位为零。在这种设置下,平均而言,每个顶点大约 30-33 位(3 * 10 位尾数,大部分指数位共享并删除尾随零)可能是合理的。
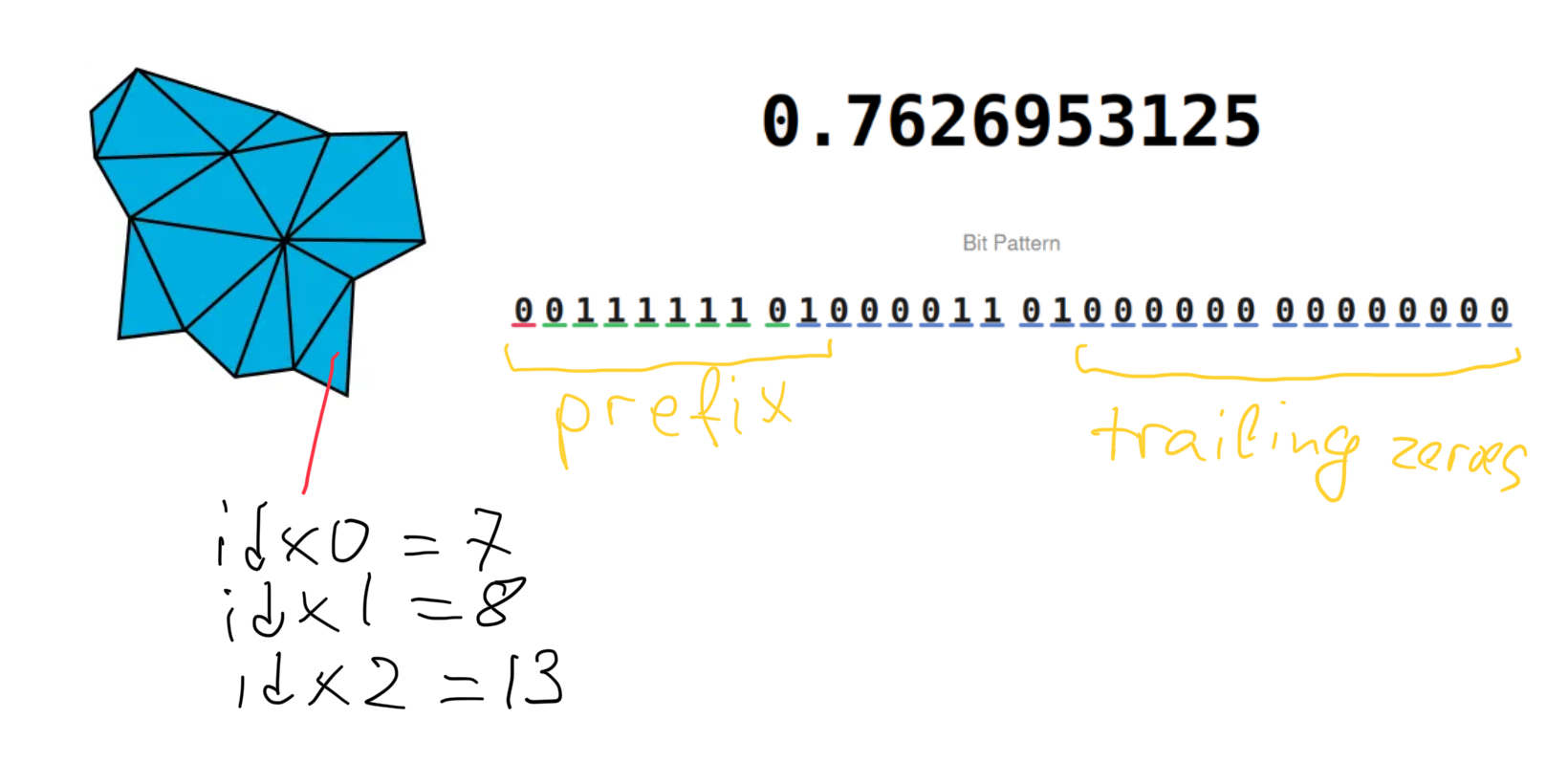
三角形对顶点索引使用每个索引 4 位进行编码,其他几个位用于其他字段;图元索引存储为与图元节点中的单个基值的增量,类似于位置。值得注意的是,三角形对的每个三角形的三个角都有三个独立的索引 - 因此,看起来该对不一定必须共享几何边,这可能会以每个其他三角形增加 8 位的小成本来提高将几何体转换为这种格式的效率16。每个节点的对数限制为 8 对,或 16 个三角形。
这种索引存储格式似乎与帖子前面提到的内容不一致:如果在 BLAS 构建期间驱动程序丢弃了初始索引缓冲区,它如何在这里使用索引?答案是 BVH 构建像以前一样进行,并且一些子树被 打包到图元节点中。在这种打包过程中,使用顶点角之间的按位相等性来机会主义地识别共享顶点 - 因此,只要三角形角位置完全相等,源几何体是否已索引无关紧要。
所有这些都使得正确估计此类节点的最佳存储容量变得困难。在限制为 16 个三角形的情况下,我们理想地希望能够打包一个 3x5 顶点网格(15 个顶点,8 个四边形)17。如果每个顶点约 30 位的用于位置存储是准确的,那么 15 个顶点将占用 57 字节的存储空间。每个三角形对占用 29 位,8 对将占用 29 字节,总共 86 字节。标头、用于重建位置和图元索引的各种锚点以及每个三角形的少量位(用于图元索引)都需要一些额外的字节,假设空间连贯的输入三角形 - 这可能可以合理地期望容纳。因此,可以将密集网格打包到每个节点 16 个三角形或 ~8 字节/三角形。
由于 BVH 节点是 8 宽的,这也成比例地减少了框节点的总预期数量,从图元节点的 1/3 减少到仅 1/718。鉴于父指针已经嵌入到框节点中,这给了我们一个最佳情况下的理论界限:
- 具有 16 个三角形/节点的 128 字节图元节点 = 8 字节/三角形
- 128 字节的框节点,三角形的 1/7 的 1/16 = 1.2 字节/三角形
… 总共 9.2 字节/三角形。现在,根据 实际 数字 ~48 字节/三角形,这显然是一个非常不切实际的目标:
- 即使使用 BVH4,我们也没有在实践中看到接近 4 倍分支因子,在我们的测试几何体上;在不降低 BVH 质量的情况下实现 8 倍应该更加困难
- RDNA4 加速单元可以一次处理 八个框或两个三角形 交集;因此,具有 16 个三角形的节点与具有 2 个三角形的节点相比,处理成本要高得多。这可能意味着驱动程序会人为地限制每个叶子节点中的三角形数量,以保持跟踪性能。
- 上面的