ClickHouse 中使用 Rust 的一年:回顾与展望
[正文内容]
参加我们的 Open House,ClickHouse 用户大会,5 月 28-29 日在旧金山举行。->->
博客 / 工程
ClickHouse 中使用 Rust 的一年
 Alexey Milovidov
2025 年 4 月 1 日 - 阅读需要 16 分钟
Alexey Milovidov
2025 年 4 月 1 日 - 阅读需要 16 分钟
- 第一步
- BLAKE3
- Skim
- PRQL
- Delta Kernel
- 问题
- 供应链
- 复杂的封装
- Panic
- Sanitizers
- 交叉编译
- 库链接
- 符号大小
- 可组合性
- 构建分析和缓存
- 依赖管理
- Rust 进行得如何?
Rust 是一种非常棒的编程语言,适用于终端应用程序、幻想主机和 web3。如果你做一个实验,在互联网上任何地方提到 "C++",一分钟之内就会有人跳出来告诉你 Rust 的存在。遗憾的是,ClickHouse 是用 C++ 编写的,而不是 Rust。如果我们有机会吸引一大批充满激情的 Rust 专业人士就好了……所以,我决定我们必须将 Rust 添加到 ClickHouse 中。
目标不是用 Rust 重写 ClickHouse —— 这将是浪费时间。我们用 C++ 编写 ClickHouse,然后将一些部分从 C++ 重写为更好的 C++。重写永远不是最终目标,尽管我知道一些工程师从 Rust 重写到 Rust的例子,如果他们喜欢用 Rust 重写一切的话。我们应该允许用 Rust 编写新的系统组件。它应该集成到构建系统中,以便 Rust 代码与 C++ 互操作,并且可以一起构建和测试,没有任何复杂性。
第一步
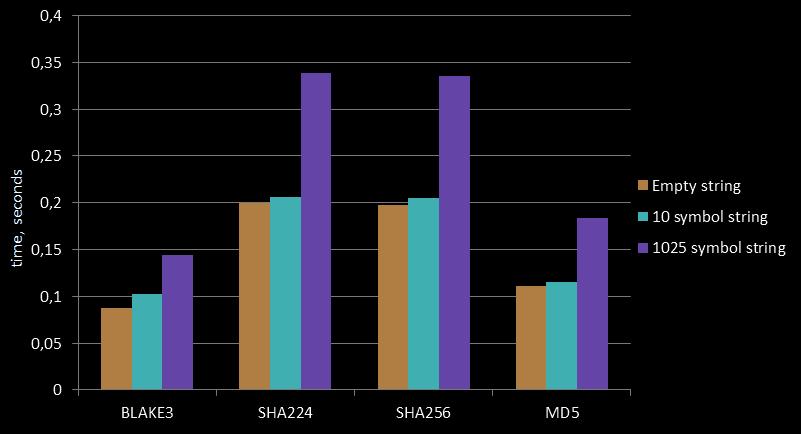
第一步是找到一个小的组件来启动 Rust 的集成。这个组件不应该在关键路径上,它应该是我们可以随时删除的东西,所以如果我们的工程师对 Rust 中毒感到过于恶心,我们可以直接回滚并忘记。同时,它应该足够大,以测试与构建系统的集成。为了不冒着我们宝贵的高级 C++ 开发人员的精神健康的风险,我将这项任务外包给了一名本科生。老实说,在本科生中找到 Rust 专家比在公司内部容易得多。Rust 在加密货币和 web3 中非常突出,所以测试它的第一个组件是——将 BLAKE3 哈希函数集成到 ClickHouse 中。当时,BLAKE3 仅用 Rust 实现,所以这至少还算合理。
BLAKE3
几个月后,感谢 Denis Bolonin,我们有了 ClickHouse 中的第一个 Rust 代码。Rust 通过 "corrosion" 集成被添加到 CMake 构建脚本中;一个专门用于 Rust 代码的目录被添加到项目树中,并且我们创建了为 Rust 库添加 C++ 封装的示例。你可以在这篇博客文章中阅读更多关于此贡献的信息。
Skim
我们已经使其成为可能,并且打开了闸门,让才华横溢的 Rust 开发人员进入 ClickHouse 代码库!所以现在他们可以编写一些除了旧终端应用程序的新版本之外的东西了。我急切地检查着 pull request 列表,想看看 Rust 爱好者的第一个外部贡献……他们果然来了!第一个带有 Rust 的外部 pull request 是通过添加交互式历史记录导航来改进我们的终端应用程序 clickhouse-client。注意:在此之前,它已经通过调用子进程添加了,但由于与 Rust 的集成,现在我们将此代码构建并链接到 ClickHouse 二进制文件中。然而,Rust 库 有一个 bug 并且崩溃了。

在添加了第二个 Rust 库 skim 之后,我们发现 BLAKE3 函数已经存在于我们也在使用的 LLVM 的 C++ 代码库中。在升级 LLVM 之后,发现从那里使用 BLAKE3 比使用 Rust 库要简单得多。为了证明 Rust 集成有效并且在 CI 中得到支持,只需要一个 Rust 库就足够了。因此,我们 将 BLAKE3 从 Rust 替换为 C++,并且性能上没有明显的差异。
PRQL
我们添加到 ClickHouse 的第三个 Rust 库是 PRQL。它是一种查询语言,是 SQL 的替代方案,允许以管道化、可组合的形式表达查询。缺点是,它比 SQL 的语法更重,让人想起 Clojure。它在互联网上很流行——有人展示 PRQL,其他人会想“多么美妙的想法,还有 Rust”,并在 GitHub 上给这个项目点赞。顺便说一句,这正是大多数 Rust 项目在 GitHub 上获得星标的方式。看起来没有人想使用这种语言,但我们想要的是蹭热度。另一位学生 选择 将 PRQL 集成到 ClickHouse 中作为毕业作品。
ClickHouse 方言中的 SQL 查询示例:
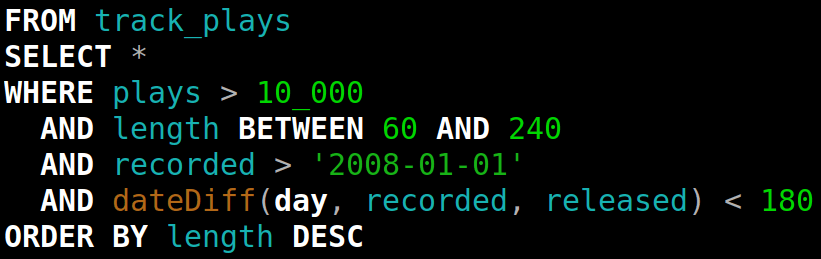
PRQL 中相同查询的示例:

几个月后,感谢 Alexander Nam,我们 将 PRQL 支持合并 到 ClickHouse 代码库中。ClickHouse 支持可切换方言。任何时候,你都可以编写 "SET dialect = 'prql'" 或 'kusto',或者将其设置回 'sql' 以在不同语言之间切换。你可以在用户配置文件中或在 HTTP API 的参数中指定方言,就像任何其他设置一样,并以选定的方言传递你的查询。然而,替代方言有一些缺点,例如除了 SQL 之外的所有方言都缺乏交互式语法高亮显示,并且与内置函数和扩展的集成较差。
无论其有用性如何,PRQL 都让我们对 Rust 更有信心。在我们的代码库中拥有两个 Rust 库之后,我们开始明白很难摆脱 Rust,而且我们可以容忍它。
Delta Kernel
这是我们添加的第一个不仅仅是为了 Rust,而是为了实际需要的库。Delta Lake 是来自 Databricks 的一种开放数据湖格式。它模仿 ClickHouse 中 MergeTree 表的操作,但基于对象存储中的 Parquet 文件。数据湖和“湖仓一体”(一个新术语,听起来与 ClickHouse 惊人地相似,但又有所不同)——正日益成为大型组织管理数据的流行方式,因为当数据格式独立于存储引擎时,会带来好处。因此,一个引擎(例如 Spark)可以将数据写入 Iceberg 或 Delta Lake 格式的数据湖中,而另一个引擎(例如 ClickHouse)可以对数据湖运行查询,因此整个架构被称为“数据湖仓一体”。
问题是,Iceberg 或 Delta Lake 都没有好的 C++ 实现。要么你使用 Java(这对我们来说将是一种耻辱),要么你用 C++ 从头开始编写它。乍一看,用 C++ 编写 Iceberg 和 Delta Lake 实现并不太难,因为每种格式都由以下组件表示:
- 对象存储上的一堆 Parquet 文件;
- 一堆元数据文件和快照描述,采用 JSON 和 Avro 等格式;
- 一个目录,它是一个用于查找表的 API。
我们已经有了每种数据湖格式的 C++ 实现:Iceberg v1、v2、Delta Lake 和 Apache Hudi。然而,这些实现很粗略,许多角落案例不受支持,而且编写它们并不是特别愉快(没有 C++ 工程师会对“读取此 JSON 文件并精确地遵循规范”的任务感到兴奋)。
在这里,Rust 日益普及以最佳方式展示出来。最近,Databricks 用 Rust 创建了 Delta Lake 的官方库,我们使用了它,替换了我们旧的 C++ 代码。请参阅 Oussama Saoudi(Databricks 的软件工程师)在我们发布电话会议上的演示。我们还提高了该库的质量,因为我们发现并 修复了一个 bug 并 添加了一个功能。这是 Rust 集成到 ClickHouse 中最复杂和最真实的集成。所以让我们回顾一下我们必须解决的问题……
问题
供应链
最初的 Rust 集成是在构建过程中 从互联网下载库,通过运行 cargo。但是我们的构建必须是封闭的并且是 可重现的。它必须在没有互联网访问的情况下工作,并且不应依赖于第三方服务,因为这可能是一个供应链问题。此外,我们应该从源代码构建所有内容——存储库中没有二进制 blob。
这个问题最初通过 建议一种禁用 Rust 的方法 来解决,然后通过 将依赖项隐藏在 docker 镜像中,最后通过 vendor 所有依赖项,尽管它 不是最终的。
复杂的封装
Rust 是一种内存安全的编程语言,但令我们的贡献者惊讶的是,添加 Rust 代码的第一次尝试通常会导致 段错误。这是因为 Rust 和 C++ 之间的互操作需要编写封装器,并且必须格外小心,不要搞砸谁拥有内存以及以什么顺序释放内存之类的事情。仅仅成为一名 Rust 工程师还不足以正确地完成它。值得庆幸的是,我们在 CI 系统中使用模糊测试,并且在合并之前发现了这些类型的错误。
Panic
#
 (Airplane!, Paramount Pictures, 1980)
(Airplane!, Paramount Pictures, 1980)
Rust 最明显的缺点之一是缺乏异常(但是,可以绕过它)。它使用错误值来代替,并且实现得非常好(比方说,比 Go 或 C 好得多)。然而,它需要在代码中为每种可能的异常情况增加开销。你不仅需要为用户解析 JSON 中的错误或套接字断开连接等情况这样做,还需要为来自操作系统的底层错误这样做。在 C++ 中,异常将通过堆栈传播,并且可以由服务器的查询处理线程报告。在 Rust 中,当人们不想承担处理错误的开销时,通常会使用 "panic",而 "panic" 将终止程序。这对于无法有意义地处理这些错误的批处理应用程序来说是可以的,但对于具有多个查询处理线程的多租户服务器来说则不然。
我们的 CI 中的模糊器会自动 发现一个问题,即某些格式错误的 PRQL 查询可能导致 panic 并使服务器崩溃。PRQL 的作者迅速 修复了该错误。这是拥有 C++ 代码库的优势之一——你学会了在你的 CI 系统中拥有如此强大的功能,以至于它也可以轻松地找到任何 Rust 代码中的错误,请参阅 1、2 和 3。
老实说,这与你在许多 C 库中发现的问题没有什么不同,当它们使用断言来捕获“不可能”的错误时,但我们的 CI 立即证明这些错误是完全有可能的。我们修复 Rust 库的方式与我们修复 C 库的方式相同。此外,Rust 中的 panic 实际上像异常一样通过 展开堆栈 工作,并且这也 被用作一种解决方案。
Sanitizers
当使用 C++ 编写时,你总是会使用 sanitizers。使用四个 sanitizers 非常重要:地址 Sanitizer(检查无效的内存访问)、内存 Sanitizer(检查 未初始化的内存使用情况)、线程 Sanitizer(检查数据竞争)和 UB Sanitizer(检查导致未定义行为的格式错误的的代码),所以我们在 CI 中这样做。我们非常彻底地这样做,因为所有 sanitizers 都针对每个 pull request 以及 master 和 release 分支中的每个提交运行所有类型的测试套件,并且我们通过额外的强化、随机化、压力测试和模糊测试来做到这一点。
你可能会说,在 Rust 中不需要 sanitizers,因为 Rust 非常安全。但问题是——现在我们有一个带有少量 Rust 的 C++ 应用程序,我们必须继续对整个应用程序使用 sanitizers。如果 C++ 分配一块内存,然后我们调用一个 Rust 函数来用数据填充它,然后 C++ 代码将从该内存中读取会发生什么?如果我们使用 MSan 构建,则必须检测所有内存写入,以便下次有人从内存中读取时,MSan 可以知道该内存之前已初始化。这意味着必须 使用 MSan 的检测来构建 所有代码(包括 Rust)(另一种选择是手动为来自 Rust 的数据调用 __msan_unpoison)。
Rust 支持使用 sanitizers 进行检测,但 MSan 仅在 "nightly"(前沿)Rust 工具链中可用,因此我们必须努力指定此版本的工具链并 将其固定为特定版本,以便它 不会随着时间的推移而中断。
由于某种原因,我们还必须 禁用 Rust 的线程 Sanitizer。
交叉编译
ClickHouse 使用交叉编译进行构建,这意味着——我们可以使用 x86_64 Linux 机器(“主机平台”——完成构建的地方)为 AArch64 mac 构建 ClickHouse(“目标平台”——我们构建的目标),反之亦然。事实上,即使主机平台与目标平台相同,例如,当我们在 x86_64 Linux 上为 x86_64 Linux 构建时,我们仍然使用交叉编译机制,以确保我们的构建过程不依赖于平台或环境,而是完全依赖于我们存储库中的源代码。这允许任何人都可以验证的封闭且可重现的构建。
ClickHouse 非常便于移植。例如,IBM 的人们希望在大端 s390x 系统上运行 ClickHouse,所以我们在 CI 中构建它。我的老朋友,住在带有五只猫的车库里,想在 FreeBSD 上运行 ClickHouse,所以我们为 FreeBSD 构建它(猫很可爱)。

事实证明,这在 Rust 中并不容易。好吧,也许这在 Rust 中很容易,甚至比在 C++ 中更容易,但是当你 一起使用 Rust 和 C++ 时,这并不容易。
库链接
ClickHouse 构建受到限制,无法使用系统中的任何库——我们通过使其独立于操作系统发行版来隔离构建。然而,delta-kernel-rs 依赖于另一个名为 "reqwest" 的库,并且它想要链接系统中的 OpenSSL,而我们要求静态链接 OpenSSL 的树内构建。我们 解决了这个问题。
符号大小
C++ 模板因减慢编译速度、膨胀二进制文件大小和生成非常长的符号名称而臭名昭著(符号名称是二进制文件中一段代码或数据的名称,链接器使用它来将不同的库绑定在一起)。但 Rust 可能会更糟。它也有编译时代码生成,并且它也可能失控。在添加 PRQL 之后,我对二进制文件大小的增加感到惊讶,并发现 PRQL 中的符号 接近 85 KB 大小(这不仅仅是代码,而是生成的函数名称!)。PRQL 的作者迅速 修复了这个问题。此外,我们 禁用了所有 Rust 库的调试信息,因为 Rust 是安全的,谁需要调试它?
 Rust 中符号名称的示例。它比图片中显示的长度长约 300 倍。
我使用我的二进制可视化工具找到了违规代码,该工具可在 ClickHouse 的
Rust 中符号名称的示例。它比图片中显示的长度长约 300 倍。
我使用我的二进制可视化工具找到了违规代码,该工具可在 ClickHouse 的 /binary 处理程序中使用。
 ClickHouse 二进制代码可视化。尝试在此处找到 Rust。
ClickHouse 二进制代码可视化。尝试在此处找到 Rust。
更新:在撰写本文时,我发现该问题尚未修复,并且变得更糟:现在来自 Rust 的某些符号接近 几乎 1 MB 大小。我必须紧急修复它。
可组合性
当我们的 C++ 代码使用一些约定来执行诸如管理与外部存储的连接或对分配的内存进行记帐之类的事情时,并且 Rust 代码使用其他约定,就会出现问题。我们维护 S3 的连接池,我们确保请求仅使用适量的并行性,均匀地分布在多个端点上,并在适当的时间保持活动状态,以允许适当的重新平衡并避免缓慢启动,并且连接使用实践中证明的适当的指数退避。当我们代码中的任何内容分配内存时,我们会在查询上下文中对其进行记帐,以控制内存使用量。但是很难期望外部库能够支持提供自定义内存分配器、自定义连接池等的可组合性水平。也许这在 Haskell 或 Julia 中很常见,但是祝你好运使用它们。不可避免地,Rust 库会做一些略有不同的事情,然后我们将不得不对其进行修补。现在这意味着我们必须深入研究 Rust 代码。在旅程开始时,麻烦的数量并不明显。
构建分析和缓存
我们的构建基础架构支持构建过程的分布式缓存和分析。添加 Rust 意味着我们还必须 支持 Rust 构建的缓存 和分析。实际上,这意味着在很长一段时间内,我们都在没有 Rust 的构建缓存的情况下工作,并且为此付出了更多的钱。
依赖管理
Rust 具有高度模块化的生态系统,并且库的组成比 C++ 更好。缺点是,Rust 库通常具有大量的依赖项扇出,很像 Node.js。这需要注意避免 依赖项爆炸,并处理 dependabot 的烦恼。
Rust 进行得如何?
Rust 进行得很顺利! 如果你的朋友渴望用 Rust 编写一些东西,请邀请他们加入 ClickHouse,我们保证热烈欢迎。
立即 开始使用 ClickHouse Cloud,并获得 300 美元的信用额度。在 30 天试用期结束时,继续使用按需付费计划,或 联系我们 以了解更多关于我们基于交易量的折扣的信息。访问我们的 定价页面 了解详情。