我的浏览器扛不住了:实战中使用 DuckDB, Apache Arrow 和 Web Workers
正文:
介绍
在 Motif Analytics,我们正在构建一个高度互动的分析工具,它允许完全在浏览器中找到相对大型数据集中的见解。 我们也有一个更传统的云模式,但“本地”(完全在浏览器中)模式对于我们的用户来说,是实验 Motif 并查看它是否符合他们的需求,而无需做出任何承诺的重要方式。 为了实现这一点,我们采用了多种技术,包括运行 DuckDB WASM、Apache Arrow 和 Web Workers。
在过去的几个月里,我们了解了使用这些技术的一些优点和缺点。 虽然这些经验是在我们特定的用例中获得的,但我们相信它仍然具有一定的普遍性,并且可能对任何致力于处理大量数据的现代、响应式 Web 应用程序的人都感兴趣。
并行化与 Web 浏览器有什么关系?
通过并行化来加速处理密集型分析任务的想法几乎与计算本身一样古老。 它经历了漫长的道路,从 20 世纪 60 年代和 70 年代的 共享内存架构 开始,到被 集群、网格计算 并最终被 云 所取代。 我仍然记得使用一些被遗忘的技术(如 PVM 或 MPI)构建学术项目的乐趣。 今天的世界非常不同,但最终所有数据处理问题在核心上都非常相似,并且围绕着能够将大型任务分解为较小的独立部分并同步它们的执行。
节能型多核 CPU 的出现,允许通过直接在 Web 浏览器中运行繁重的计算,从而使繁重的计算更接近用户。 可以使用 Web Workers并行化计算密集型任务,Web Workers 受到所有现代浏览器的支持,并且正成为编写响应式应用程序的重要工具,但存在重要的限制。
通过使用熟悉的工具(例如使用 SQL 描述查询),可以简化交互式数据分析。 这就是 DuckDB 的用武之地,DuckDB 是一种为 OLAP (Online Analytics Processing) 设计的开源数据库。 它之于数据仓库,就如同 Sqlite 之于 RDBMS。 它几乎没有外部依赖项,具有丰富的语言(漂亮的文档),并且运行速度非常快,这主要归功于利用了数据库分析中的最新技术。 DuckDB WASM 是 DuckDB 的一个特殊版本,它被编译为 WebAssembly,这允许它与页面脚本一起在浏览器虚拟机中运行。
这两个(Web Workers 和 DuckDB WASM)可以一起用于更复杂的处理架构。 例如,可以使用 Web Workers 并行执行一些自定义的、特定于域的处理代码,然后将其馈送到 DuckDB WASM,在该 DuckDB WASM 中,方便的 SQL 查询可以处理结果并计算聚合。
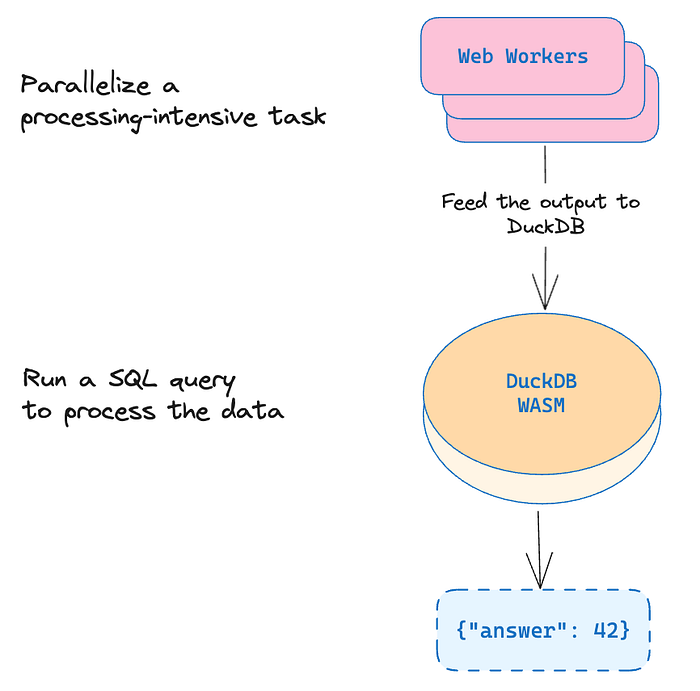
可以使用 Apache Arrow 将两者粘合在一起,Apache Arrow 是一个与语言无关的框架,它使用标准化的面向列的内存格式。
为了使其更具吸引力,相同的架构可以在服务器模式下执行。 Node.js worker threads 和 DuckDB Node library 可以以非常相似的方式组织,从而允许代码重用。
等等! 还有更多的用例! DuckDB 还可以用于(快速)交换使用一些流行的 数据格式,例如 Parquet, CSV 或 JSON。
虽然这一切听起来令人兴奋,但也带来了挑战,我们将在下面讨论。
DuckDB WASM 性能
虽然 DuckDB WASM 提供了与任何其他版本的 DuckDB 几乎相同的功能,但它是在基于堆栈的虚拟机中执行的,而不是作为本机库代码执行的。 虽然 WASM 被认为是快速的,但它增加了在本机运行代码的开销。 此外,目前 DuckDB WASM 是单线程引擎(现在已过时的 SharedArrayBuffer 使用限制 的残余),具有实验性的 COI 支持。
最终,这意味着查询的运行速度比本地的本机 DuckDB 实例(通过 shell 或作为 Node /Python /etc. 库执行)慢得多。
示例 1:TPC-H lineitem 查询
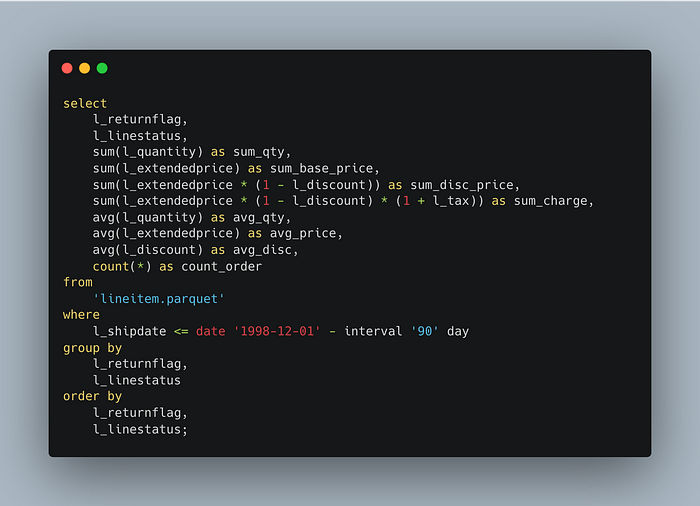 那么,我们可以从 DuckDB WASM 与本机 CLI 期望什么样的性能差异呢? 这是我在 M1 Pro 上的一个临时基准测试。
那么,我们可以从 DuckDB WASM 与本机 CLI 期望什么样的性能差异呢? 这是我在 M1 Pro 上的一个临时基准测试。
结果 1:DuckDB (native lib) CLI 0.9.2
D PRAGMA threads=1;D .timer onD select ...┌──────────────┬──────────────┬──────────┬────────────────────┬─────┐│ l_returnflag │ l_linestatus │ sum_qty │ sum_base_price │ ... ││ varchar │ varchar │ double │ double │ ... │├──────────────┼──────────────┼──────────┼────────────────────┼─────┤│ A │ F │ 380456.0 │ 532348211.6500006 │ ... ││ N │ F │ 8971.0 │ 12384801.37 │ ... ││ N │ O │ 742802.0 │ 1041502841.4499991 │ ... ││ R │ F │ 381449.0 │ 534594445.3500006 │ ... │└──────────────┴──────────────┴──────────┴────────────────────┴─────┘Run Time (s): real 0.807 user 0.590743 sys 0.035380
结果 2:DuckDB WASM Shell 0.9.2 on Chrome 119.0
duckdb> .timer onduckdb> select ...┌──────────────┬──────────────┬─────────┬────────────────────┬─────┐│ l_returnflag ┆ l_linestatus ┆ sum_qty ┆ sum_base_price ┆ ... │╞══════════════╪══════════════╪═════════╪════════════════════╪═════╡│ A ┆ F ┆ 380456 ┆ 532348211.6499983 ┆ ... ││ N ┆ F ┆ 8971 ┆ 12384801.369999997 ┆ ... ││ N ┆ O ┆ 742802 ┆ 1041502841.4499979 ┆ ... ││ R ┆ F ┆ 381449 ┆ 534594445.3499986 ┆ ... │└──────────────┴──────────────┴─────────┴────────────────────┴─────┘Elapsed: 03.257 s
我们得到 0.8 秒(本机库,单线程)与 3.3 秒 (WASM),这使得 WASM 在这种特定情况下 慢 4 倍。 但是等等。 如果我们先将数据复制到临时表中呢?
CREATE TABLE lineitem AS SELECT * FROM 'lineitem.parquet';
这使得这两种情况都更快了,将时间缩短到 0.1 秒(本机库,单线程)与 0.4 秒 (WASM),保持了我们之前观察到的 4 倍因子。
示例 2:调用昂贵的函数
另一个例子怎么样? 我们将使用相同的数据集,但构建一个不同的查询。 一个调用有点昂贵的函数,该函数必须为所有行执行。
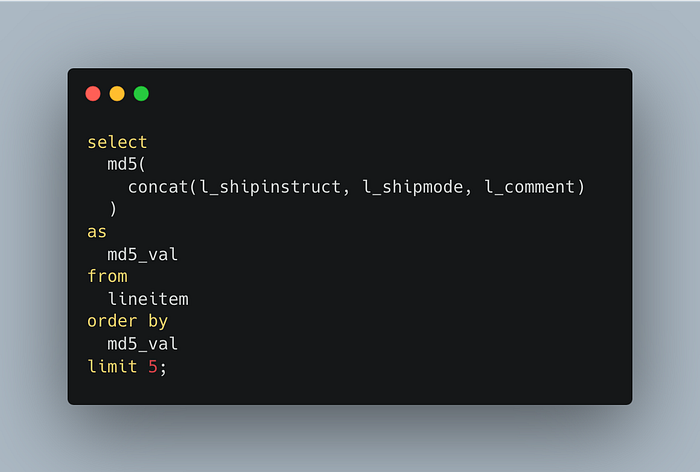 结果 3:DuckDB (native lib) CLI 0.9.2
结果 3:DuckDB (native lib) CLI 0.9.2
D PRAGMA threads=1;D .timer onD select ...┌──────────────────────────────────┐│ md5_val ││ varchar │├──────────────────────────────────┤│ 0000031428caeaafcddcf1a1f5d4ea26 ││ 000005560d5cc20991b8bb57e64f58a0 ││ 00000aa836f58524e6ae1d75c9246511 ││ 000016d700b533970506d1164d0ee003 ││ 00001921a51a1880a184ed25fc3d95b8 │└──────────────────────────────────┘Run Time (s): real 1.679 user 1.533280 sys 0.098910
如果我们增加线程数会怎么样? 这是在我的 M1 Pro 笔记本电脑上发生的事情:
D PRAGMA threads=8;D select ...┌──────────────────────────────────┐│ md5_val ││ varchar │├──────────────────────────────────┤│ 0000031428caeaafcddcf1a1f5d4ea26 ││ 000005560d5cc20991b8bb57e64f58a0 ││ 00000aa836f58524e6ae1d75c9246511 ││ 000016d700b533970506d1164d0ee003 ││ 00001921a51a1880a184ed25fc3d95b8 │└──────────────────────────────────┘Run Time (s): real 0.313 user 1.742058 sys 0.019078
结果 4:DuckDB WASM Shell 0.9.2 on Chrome 119.0
duckdb> .timer onduckdb> select ...┌──────────────────────────────────┐│ md5_val │╞══════════════════════════════════╡│ 0000031428caeaafcddcf1a1f5d4ea26 ││ 000005560d5cc20991b8bb57e64f58a0 ││ 00000aa836f58524e6ae1d75c9246511 ││ 000016d700b533970506d1164d0ee003 ││ 00001921a51a1880a184ed25fc3d95b8 │└──────────────────────────────────┘Elapsed: 01.881 s
现在,持续时间几乎相同。 我们得到 1.7 秒(本机库,单线程)与 1.9 秒(WASM),这使得以 WASM 形式执行查询时,只有适度的 10% 的损失。 非常令人印象深刻!
结论
与往常一样,YMMV 取决于数据集的属性和查询复杂性,但观察到这种差异并不奇怪。 与本机版本不同,WASM 在虚拟机中运行。 此外,使其使用多个 worker 相当新(使用 next-coi 实验版本 应该取消单线程限制),我不确定是否已经可以推荐它。
最重要的是,WASM 可用的内存受到浏览器的限制(对于 Chrome,该限制目前设置为每个选项卡 4GB)。 当尝试加载更大的数据集或进行重要的连接时,这可能会让人痛苦地学习到这一点。 DuckDB 以“从不抛出内存不足”而闻名(并且理所当然地如此),但如果 WASM 在处理查询时无法装入可用内存,则无法使用本地持久性来溢出数据。 同样,希望后者很快会发生变化,目前正在进行中。 但是,在此之前,它只是另一个已知的 WASM 限制。
尽管如此,DuckDB WASM 目前是全浏览器查询速度最快的引擎之一(如果不是最快的)。 但是,如果可能,运行本机代码(不受浏览器限制)将始终更快,并且支持更大的查询。
Web Workers 和 Schema 一致性
在我们的架构中,我们使用 Web Workers 来并行化一项复杂的任务,并将其输出馈送到 DuckDB。 在我们深入了解一些具体细节之前,值得注意的是,使用 Web Workers 与在 Golang、Java 或 Rust 中编写并发代码有很大不同。 Surma 在他的文章中很好地讨论了这一点,但 TLDR,Web Workers 在很大程度上彼此独立,并且只能传递 Byte Array 缓冲区(无论是作为 SharedArrayBuffer 还是 [可传输的 ArrayBuffer](https://motifanalytics.medium.com/https:/developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API/Transferable_objects)。
这意味着用于同步的消息量应该相当低,并且在选择序列化/反序列化方法时必须格外小心。 这只是 Apache Arrow 非常适合这里的原因之一,因为它的 IPC 缓冲区非常匹配(向量数据模型甚至不需要序列化,并且可以仅作为内存块传递)。
DuckDB 在以 Arrow 格式读取数据时执行查询时,只会增加非常小的开销,这使得它成为一个非常引人注目的用例。 我们希望在低延迟分析应用程序中使用的一个。
这种架构可以在很大程度上按以下图表实现。
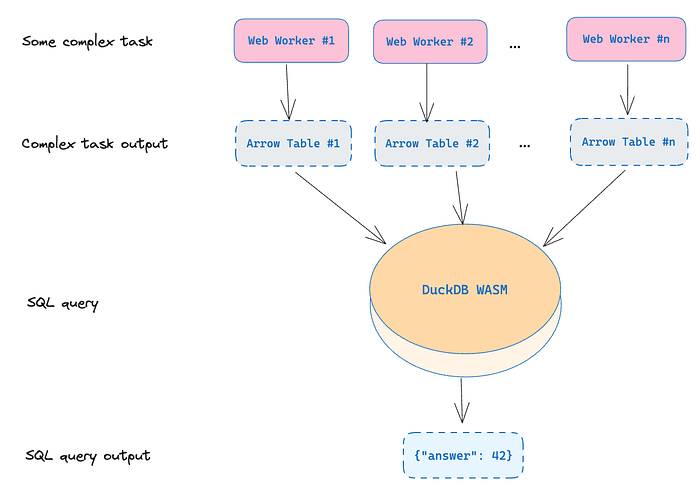 在运行 SQL 查询之前,我们只需要从 worker 收集 Apache Arrow 表,并将这些表传递给 DuckDB,从而形成一个单一的逻辑表。 用于实现该目标的代码可以用以下代码段来说明:
在运行 SQL 查询之前,我们只需要从 worker 收集 Apache Arrow 表,并将这些表传递给 DuckDB,从而形成一个单一的逻辑表。 用于实现该目标的代码可以用以下代码段来说明:
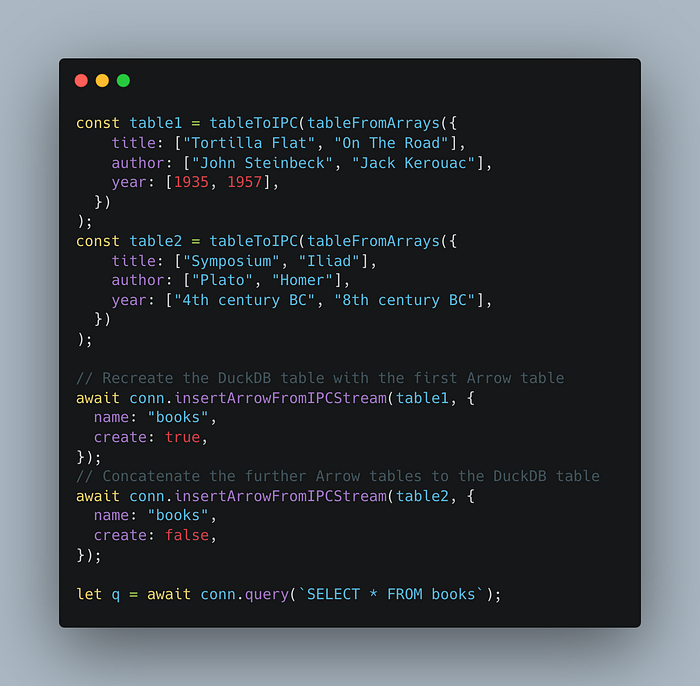 不幸的是,运行它将会失败,并显示以下错误:
不幸的是,运行它将会失败,并显示以下错误:
Conversion Error: Failed to insert into table 'books': Could not convert string '4th century BC' to DOUBLE at O.onMessage (index.js:11583:17)
虽然每个 Arrow Table 本身都是一个有效的表,并且它们的所有列名都匹配,但它们具有(稍微)不一致的 Schema,因此在执行插入时会被 DuckDB 拒绝。 事实证明,即使对于更简单的情况,这也很棘手,因为如 ARROW-2860 中所示,字段在某些分区中可能为 null,这已有 5 年历史。
使用多个 Arrow Tables,其中每个表可能包含一组单独的 BatchRecords,似乎未在 Apache Arrow spec 中得到解决,因此也许可以将其视为“灰色区域”,并且似乎应该尽一切可能来避免处理此问题。
最终,似乎没有针对 Schema 协调的简单通用解决方案。 C++ Arrow API 具有 ConcatenateTables,它允许通过将 unify_schemas 属性设置为 true(并根据需要提供更多 详细信息>)来处理某些情况,但无法从 Javascript(或任何其他调用 FFI 不可行的语言)调用它。 有一些旨在弥合访问 C++ 库的丰富性的差距的奇异计划,例如 Apache Arrow WebAssembly 库实现,但这些似乎未积极开发 或基于 较旧的 Arrow 版本。
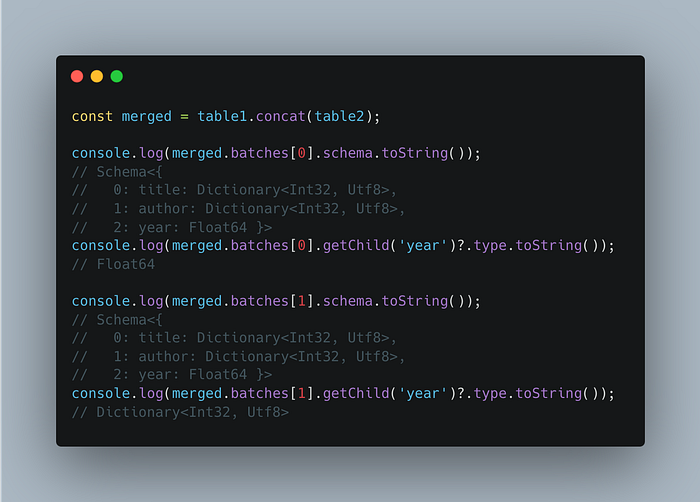 最终,必须自己处理这种情况,或者(最好)首先避免处理 Schema 协调,尽管并非总是如此。
最终,必须自己处理这种情况,或者(最好)首先避免处理 Schema 协调,尽管并非总是如此。
功能上的差距和……Bug
虽然 DuckDB WASM 最近受到了很多关注,但也许 Python 和 Java 库的使用最为活跃(一年前,它们的下载量比 Nodejs 库高一个数量级)。 因此,可能 WASM 和 Node.js DuckDB 库都不应被视为非常成熟的项目。 社区非常活跃,DuckDB 团队为此付出了巨大的努力,但简而言之,很容易遇到各种差距。
为了给出个人观点,这里有一些我最近遇到的例子:
- 查询某些 JSON 字符串或 Parquet 文件 抛出“内存访问超出范围”错误。 它似乎没有发生在 DuckDB WASM v1.27.0 或更早版本上,因此降级是一种可行的解决方法,直到修复完成。
- 只有第一个表由 register_buffer() 注册 — 该函数暗示可能传递多个 Apache Arrow 表,这些表可以形成一个单一的逻辑 DuckDB 表。 但事实并非如此。 我发现的解决方法是分别注册每个 Apache Arrow 表,然后连接到临时表中。 可能更好的方法是协调所有记录批次并注册一个 Apache Arrow 表。
- 在某些 UNION ALL 和 ORDER BY 查询中崩溃库 — 此问题的修复程序正在积极开发中。 这使得 DuckDB Node 库无法挽救,并且整个过程需要重新启动(哎呀!)。 降级到 DuckDB v0.8 可作为临时解决方法。
所有这些可能看起来令人沮丧,但也可以将其视为对该项目突然爆发的兴趣的结果,该项目需要经历一个磨合阶段。 社区欢迎贡献者,并且与任何开源项目一样,最终由我们用户来报告并帮助修复 发现的问题。
此外,由于团队的辛勤工作,几个月前的一些限制已不复存在。 例如,现在可以在 DuckDB WASM 中使用许多扩展。 几个月前(当我需要更好的 JSON 支持时),我不得不编写一些解决方法。 由于在 DuckDB WASM 中启用了 JSON 扩展,现在不再需要这些(这只是其中之一)。 这是另一篇文章的主题,但 DuckDB 扩展架构确实令人惊叹。
总结
通过使用一些最近流行的技术,可以加速构建快速的浏览器内处理堆栈。 该配方基本上是:采用 DuckDB WASM(数据交换和 SQL)、Web Workers(并行化处理密集型、特定于域的任务)并通过 Apache Arrow 将它们粘合在一起。
不幸的是,它们都有局限性,有时需要付出额外的努力才能使它们协同工作。 我相信这些问题中的许多问题将在未来几个月内消失。 例如,通过添加对 OPFS 和采用 COI 版本的支持,DuckDB WASM 容量限制应得到大大改善。 随着社区进行更多测试并且发现的 Bug 得到解决,“磨合问题”有望减少。
从开发人员的角度来看,可以将此视为一个机会。 DuckDB 带来了许多广受欢迎的功能,并且正处于 加速发展曲线中。 我们将看到它更多的用例。 截至今天,它仍然存在一些挑战,这使得它成为一个绝佳的机会,可以跳入其中,帮助社区并同时学习。
如果您有兴趣了解更多信息,可以与我们联系。
注册以发现加深您对世界理解的人类故事。
免费
无干扰阅读。 无广告。 使用列表和高亮组织您的知识。 讲述您的故事。 找到您的受众。 免费注册
会员
阅读仅限会员的故事 支持您阅读最多的作家 为您的写作赚钱 收听音频解说 使用 Medium 应用离线阅读 以每月 5 美元的价格试用