我们从零开始设计了 TigerBeetle 的 Docs
Why We Designed TigerBeetle's Docs from Scratch
2025年2月27日
 Fabian Rühle
Fabian Rühle  Fabio Arnold
Fabio Arnold  matklad
matklad

我们最近从零开始重建了 TigerBeetle 的文档站点。我们希望将 TigerStyle 和第一性原理思维,不仅应用于我们的数据库,也应用于我们的文档。为了给用户提供尽可能快的体验,考虑到他们阅读所花费的时间,并且在不依赖 Docusaurus 的情况下做到这一点。在 TigerBeetle,我们构建事物的方式与我们构建的事物同样重要,因为方法论对积极性有二阶效应。
In the Beginning there were Dinosaurs
当 TigerBeetle 成立时,使用 Docusaurus 来原型化我们的文档站点。它启动很快,我们可以将 我们的文档维护在我们的主 GitHub 仓库中。
然而,也存在一些缺点:
- 违反了我们的零依赖原则:由于 Docusaurus 基于 NodeJS,它为我们的代码库添加了 大量的依赖。我们有一个检查,确保没有大型文件被提交到 git,而 package-lock.json 未通过此检查。
- 复杂性:Docusaurus 本质上是一个复杂的软件——一个 React 应用程序。虽然它擅长它所做的事情,但我们相信用更简单的方法可以实现同样好的结果。
- 不需要的额外代码:Docusaurus 在 Markdown 文件中添加了 额外的工件,这些工件也会在 GitHub 上可见(即元数据和额外的
_category_.json文件),我们希望 GitHub 对我们的文档的表示是纯粹的。 - 次优的搜索:通过外部服务提供的搜索体验有点模糊,并且没有得到最佳集成。
- 但是,最重要的是,我们希望将我们的文档视为数据库本身的一部分。这意味着文档必须使用我们投入到数据库本身的相同工艺标准,否则它们不会 感觉 像是数据库不可或缺的一部分。
Docusaurus 作为原型运行良好,但变革的时刻已经到来。我们开始创造我们在浏览和阅读文档时更喜欢的体验:简单、清晰和快速。不仅具有出色的“外部”用户体验,而且具有出色的“内部”用户体验(代码本身的实现,当你打开引擎盖时,例如网络上的 footprint)。因此,我们采取的路径不仅受到我们设计的影响,也受到我们工程考虑的影响。
As Clean as a Book
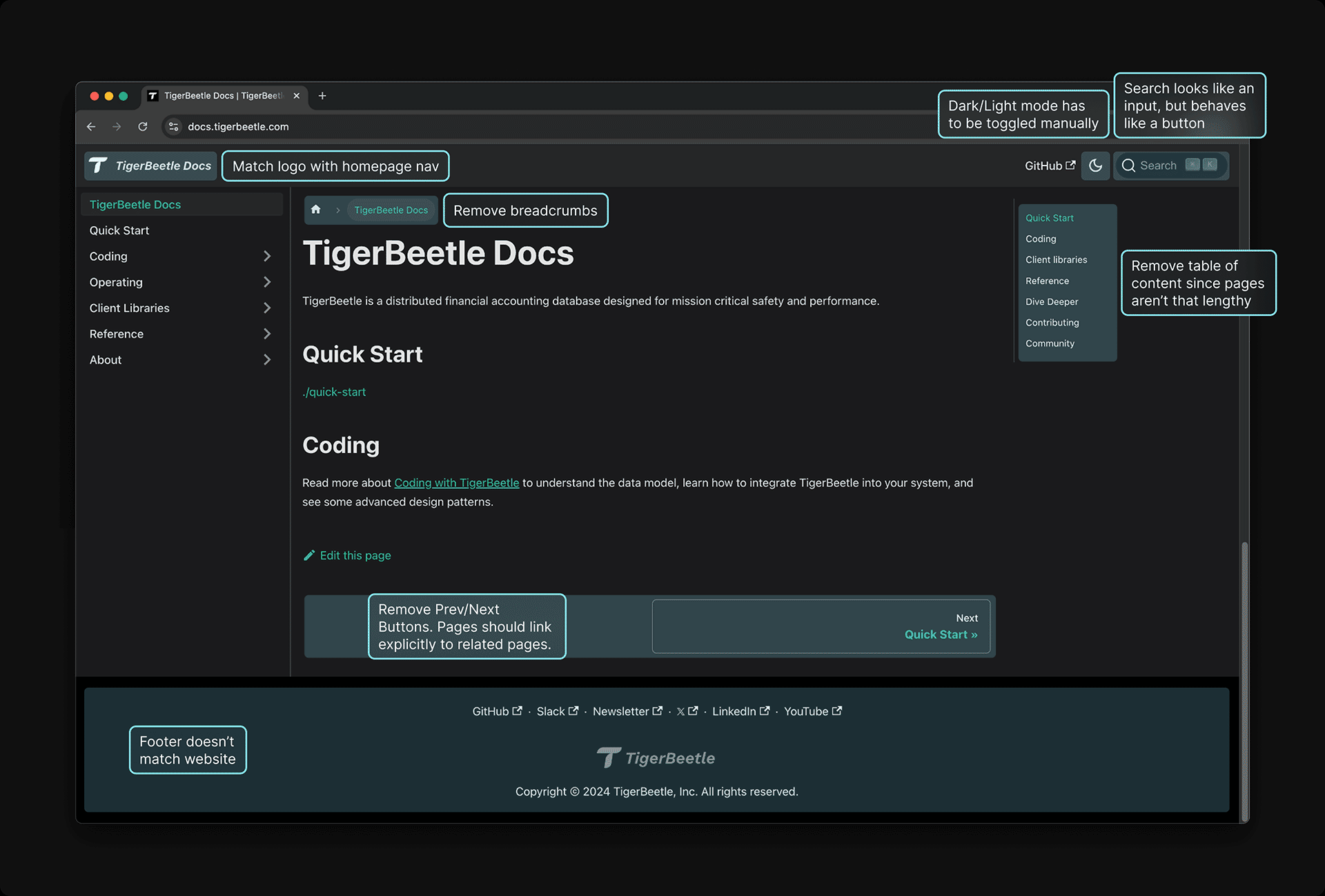
我们如何为读者提供最佳的阅读体验?阅读体验应该像一本书一样干净和简单。我们希望尽可能多地消除干扰,以保持设计的极简主义。通过删除面包屑、目录、页脚等元素,并将顶部导航集成到左侧导航中,我们为内容提供了更多空间。我们根据你的系统设置自动切换深色/浅色模式,因此你无需手动切换(因此我们不会为此引入任何 chrome),并且可以隐藏侧边导航或调整其宽度以实现最大程度的专注。
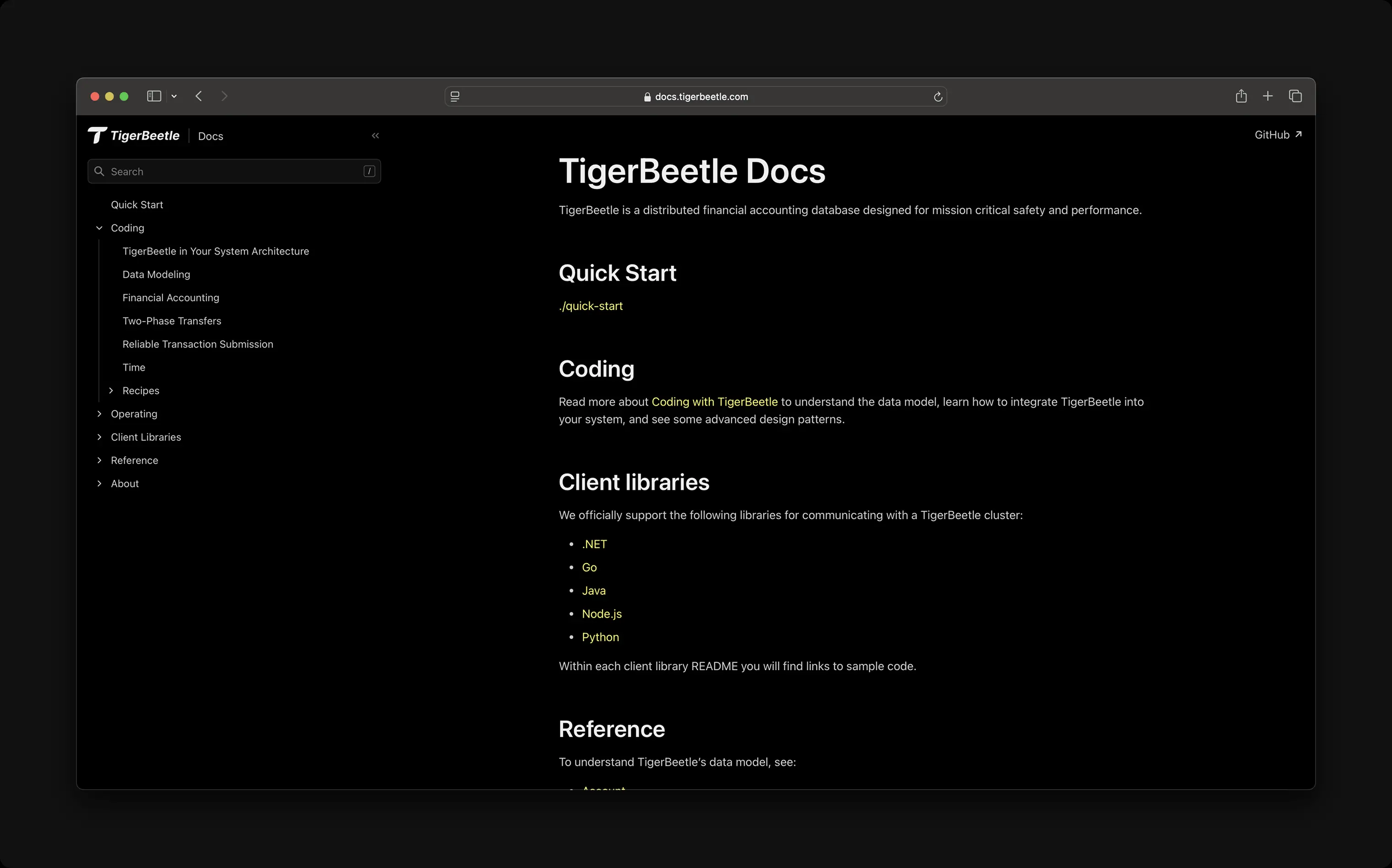
Website à la carte
鉴于 TigerBeetle 唯一的依赖项是 Zig 编译器,我们开始探索基于 Zig 的静态站点生成器(SSG)可能是什么样子。当时,我们的朋友 Loris Cro 正在构建他自己的 SSG,Zine,并且 一些公司已经使用它来生成他们的文档。
我们感到兴奋并考虑了 Zine。但是,Zine 使用 SuperMD,它被描述为 Markdown 的扩展,并且从根本上是不同类型的 Markdown。重要的是要了解我们的文档首先是内容,并且可以以三种不同的形式查看:
- 作为你选择的编辑器中的原始文本
- 在 GitHub 上
- 在我们的 网站 上
因此,要求内容是 GitHub-flavored Markdown (GFM)。但不幸的是,我们发现 SuperMD 和 GFM 之间存在一些不兼容性。例如,按照设计,SuperMD 不支持原始内联 HTML,而 GFM 支持。我们没有使用 GFM 和 SuperMD 都支持的子集重写我们的文档,而是决定探索更多选项......
老实说,静态站点生成中最困难的部分是解析 Markdown,因为 Markdown 是一种复杂的语言。它周围的一切都是简单的脚本,我们可以轻松地自己完成。幸运的是,有 Pandoc ——一个由 CommonMark 规范的编辑本人创建的坚如磐石的工具。因此,我们破例依赖它。我们使用 Zig 的内置包管理器来提取 Pandoc 作为一个单独的静态构建的可执行文件(当然要验证它的哈希),然后使用 Zig 的构建系统来并行化 Markdown 源文件到最终 HTML 的转换。(有趣的事实:此博客是使用相同的设置生成的!)
你可以在 GitHub 上 找到完整的实现,但是,为了本博客文章的目的,我们实际上将当场编写一个小型原型。这是一个有用的练习,因为这个小程序教会了 很多 关于 build.zig 背后的哲学!
大局是将整个静态站点生成作为 Zig 构建系统的一个构建任务。这将免费为我们提供增量更新。也就是说,如果你更改单个 Markdown 文件并重新构建网站,则只会更新此单个文件。为此使用 build.zig 是一个绝妙的主意。可悲的是,这不是我们的——我们无耻地从 Zine 那里偷来的(谢谢,Loris!)。
如上所述,我们希望使用 Pandoc 来完成解析 Markdown 并将其转换为 HTML 的繁重工作。我们 依赖 于一个系统实用程序,Pandoc!这是人们通常求助于 Docker 或 Nix 的重型武器的地方,它通过将 你的 机器变成我的机器来解决“在我的机器上工作”的问题!
但是使用 Zig,你可以直接且轻松地处理系统依赖项,前提是可以下载静态版本。Pandoc 就是这种情况。它的 GitHub 版本 包含适用于我们所有相关操作系统和 CPU 架构的预构建二进制文件。要使用这些二进制文件,我们将它们添加到 build.zig.zon(zon 代表 Zig Object Notation):
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb1-1>).{
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb1-2>) .name = "Build Zig Docs",
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb1-3>) .version = "0.0.0",
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb1-4>) .dependencies = .{
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb1-5>) .pandoc_macos_arm64 = .{
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb1-6>) .url = "https://github.com/jgm/pandoc/releases/download/3.4/pandoc-3.4-arm64-macOS.zip",
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb1-7>) .hash = "1220c2506a07845d667e7c127fd0811e4f5f7591e38ccc7fb4376450f3435048d87a",
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb1-8>) .lazy = true,
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb1-9>) },
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb1-10>) .pandoc_linux_amd64 = .{
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb1-11>) .url = "https://github.com/jgm/pandoc/releases/download/3.4/pandoc-3.4-linux-amd64.tar.gz",
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb1-12>) .hash = "1220139a44886509d8a61b44d8b8a79d03bad29ea95493dc97cd921d3f2eb208562c",
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb1-13>) .lazy = true,
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb1-14>) },
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb1-15>) },
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb1-16>) .paths = .{"."},
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb1-17>)}
在这里,我们有两个依赖项,一个用于 MacOS,一个用于 Linux。至关重要的是,依赖项是用内容哈希指定的!这解决了可重现性问题,并大大降低了供应链攻击的风险——我们静态站点生成器的每个用户都保证获得 bit-for-bit 相同的 Pandoc 版本!
重要的是,哈希不是 .zip 存档本身的 物理 哈希。它是存档内容的 逻辑 哈希。要计算哈希,Zig 会解压缩存档,然后递归遍历生成的文件树,对文件内容进行哈希处理。换句话说,依赖项的实际 身份 是其哈希,而 url 只是如何获取正确内容的建议。如果出于任何原因,我的本地驱动器上已经有一个具有匹配哈希的内容的目录,我可以将其替换为 .zip 存档,因为哈希是相同的,并且只有哈希才重要。
当然,提取从互联网下载的随机存档是一个安全隐患,因为存档格式指定不明确、冗余并且包含足够的负空间来隐藏各种恶意内容。但是 Zig 实际上并不 支持各种存档格式的全部通用性。它不会 shell out 到第三方实用程序进行解压缩,并且它不支持 任何 文件属性。它只提取 内容 ,这可以相对安全地完成:虽然仍然很难做到健壮,但它比支持典型存档格式支持的所有内容要 窄得多 。
仅内容提取创建了一个难题:如何处理像我们的 Pandoc 这样的可执行文件?由于属性未保留,因此该文件不会被标记为 +x。答案是内容为王!如果一个文件有一个 hash-bang,或者一个 ELF 头部(或者,在我们的 PR 之后,一个 Mach-O 头部),它会自动标记为可执行文件。
使用此依赖项规范,我们可以从我们的构建中获得对 Pandoc 二进制文件的访问权限:
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb2-1>)const std = @import("std");
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb2-2>)const builtin = @import("builtin");
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb2-3>)const os = builtin.os;
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb2-4>)const cpu = builtin.cpu;
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb2-5>)
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb2-6>)pub fn build(b: *std.Build) !void {
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb2-7>) const pandoc_dependency = if (os.tag == .linux and cpu.arch == .x86_64)
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb2-8>) b.lazyDependency("pandoc_linux_amd64", .{}) orelse return
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb2-9>) else if (os.tag == .macos and cpu.arch == .aarch64)
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb2-10>) b.lazyDependency("pandoc_macos_arm64", .{}) orelse return
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb2-11>) else
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb2-12>) return error.UnsupportedHost;
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb2-13>) const pandoc = pandoc_dependency.path("bin/pandoc");
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb2-14>)}
在这里,我们利用了所谓的惰性依赖。根据主机操作系统,只需要下载 一个 二进制文件。为了避免同时下载这两个文件,可以向 build.zig.zon 添加一些额外的平台元数据,但 Zig 实现了一个更优雅和通用的解决方案。
Zig 的 lazyDependency 函数按名称返回依赖项,但如果尚未获取依赖项,也可以返回 null。在这种情况下,构建只是在下载依赖项后重新运行。
因此,上面的代码运行了两次!在第一次运行时,我们从 orelse return 中退出,但 Zig 也了解到需要两个依赖项中的哪一个。在第二次迭代中,我们得到了我们的 Pandoc。这就是 通过重放过去来捕捉未来!
接下来,我们需要获取要转换的 Markdown 文件列表。我们可以编写代码来遍历文件系统,使用 Dir.Iterator,但是,为了说明目的,让我们作弊并让 git 在这里完成所有繁重的工作:
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb3-1>)const markdown_files = b.run(&.{ "git", "ls-files", "content/*.md" });
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb3-2>)var lines = std.mem.tokenizeScalar(u8, markdown_files, '\n');
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb3-3>)while (lines.next()) |file_path| {
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb3-4>)
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb3-5>)}
b.run 是一个方便的函数,它直接运行一个外部命令,并将其输出作为 []const u8 返回,我们可以逐行拆分并迭代它。
我们 可以 使用 b.run 也可以运行 Pandoc,但那样我们将无法利用构建系统缓存。每次你调用 zig build 时,b.run 都会运行该命令,如果可能,应避免使用。相反,应该将工作委托给具有跟踪输入的构建任务。这就是我们对 Pandoc 所做的:
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb4-1>)fn markdown2html(
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb4-2>) b: *std.Build,
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb4-3>) pandoc: std.Build.LazyPath,
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb4-4>) markdown: std.Build.LazyPath,
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb4-5>)) std.Build.LazyPath {
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb4-6>) const pandoc_step = std.Build.Step.Run.create(b, "run pandoc");
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb4-7>) pandoc_step.addFileArg(pandoc);
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb4-8>) pandoc_step.addArgs(&.{ "--from=markdown", "--to=html5" });
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb4-9>) pandoc_step.addFileArg(markdown);
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb4-10>) return pandoc_step.captureStdOut();
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb4-11>)}
markdown2html 函数不直接运行 Pandoc,而是只创建一个关于如何运行它的配方。然后,构建系统可以决定是否真的需要运行它,或者是否可以重用缓存的结果。这就是为什么该函数的输入和输出是 LazyPath 的原因。LazyPath 是一个指向文件系统中某个文件的 逻辑 路径,但该文件不一定已经存在,它可能会在将来创建。
换句话说,如果某些其他步骤需要 markdown2html 的结果,那么 Zig 将运行 Pandoc,将输入文件传入,并捕获 Pandoc 的 stdout。如果再次需要该文件,将重用旧结果。如果输入文件或 Pandoc 本身发生更改,则将重新生成结果。
现在,我们可以创建一个整个网站的配方——我们从一个空目录开始,并添加所有经过 markdown 处理的文件:
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-1>)const website = b.addWriteFiles();
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-2>)
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-3>)const markdown_files = b.run(&.{ "git", "ls-files", "content/*.md" });
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-4>)var lines = std.mem.tokenizeScalar(u8, markdown_files, '\n');
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-5>)while (lines.next()) |file_path| {
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-6>) const markdown = b.path(file_path);
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-7>) const html = markdown2html(b, pandoc, markdown);
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-8>)
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-9>) // map `content/pure-awesomeness.md` to `pure-awesomeness.html`
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-10>) var html_path = file_path;
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-11>) html_path = cut_prefix(html_path, "content/").?;
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-12>) html_path = cut_suffix(html_path, ".md").?;
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-13>) html_path = b.fmt("{s}.html", .{html_path});
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-14>)
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-15>) _ = website.addCopyFile(html, html_path);
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-16>)}
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-17>)
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-18>)fn cut_prefix(text: []const u8, prefix: []const u8) ?[]const u8 {
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-19>) if (std.mem.startsWith(u8, text, prefix))
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-20>) return text[prefix.len..];
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-21>) return null;
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-22>)}
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-23>)
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-24>)fn cut_suffix(text: []const u8, suffix: []const u8) ?[]const u8 {
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-25>) if (std.mem.endsWith(u8, text, suffix))
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-26>) return text[0 .. text.len - suffix.len];
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-27>) return null;
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb5-28>)}
再次强调,此循环实际上并不运行 Pandoc。相反,它创建了一个任务图,如下所示:
要获取目录
website,你需要为所有这些输入.md文件运行 Pandoc,并将 Pandoc 的 stdout 写入相应的.html文件。
最后,为了启动一切,我们要求将目录 安装 到 zig-out 中:
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb6-1>)b.installDirectory(.{
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb6-2>) .source_dir = website.getDirectory(),
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb6-3>) .install_dir = .prefix,
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs-from-scratch/<#cb6-4>) .install_subdir = ".",
[](https://tigerbeetle.com/blog/2025-02-27-why-we-designed-tigerbeetles-docs