Yakread 推荐算法解析
 The one and onlyOpinions on any topicWhat are you doing here?How much wood should a woodchuck chuck?You look like you need some sunClojure is an esoteric language that attracts esoteric peopleThose are my cousins the guinea pigs!The turtleneck is the most flattering thing a man can wear.Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo.
The one and onlyOpinions on any topicWhat are you doing here?How much wood should a woodchuck chuck?You look like you need some sunClojure is an esoteric language that attracts esoteric peopleThose are my cousins the guinea pigs!The turtleneck is the most flattering thing a man can wear.Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo.
The one and onlyOpinions on any topicWhat are you doing here?How much wood should a woodchuck chuck?You look like you need some sunClojure is an esoteric language that attracts esoteric peopleThose are my cousins the guinea pigs!The turtleneck is the most flattering thing a man can wear.Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo.
The one and onlyOpinions on any topicWhat are you doing here?How much wood should a woodchuck chuck?You look like you need some sunClojure is an esoteric language that attracts esoteric peopleThose are my cousins the guinea pigs!The turtleneck is the most flattering thing a man can wear.Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo.
Yakread 的推荐算法
继续 Yakread 重写 的工作,上周末我重写了 Yakread 推荐算法中,将你的 newsletter/RSS 订阅和书签文章合并成一个个性化 feed 的部分。这基本上是 Yakread 的“核心”,也是我最初想做这个 app 的全部原因。(大约 200 行代码)。有趣的是,为了让这 200 行代码可用,还需要在上面堆叠多少其他东西。)
这部分算法主要做三件事:选择推荐哪些订阅的文章;选择推荐哪些书签文章;以及决定如何将这些文章混合在一起。最终结果是一批,比如 30 个项目,将显示在用户的 "For You" feed 上。
(我通常使用更通用的术语 "item" 来代替 "文章" 和 "书签",这是推荐系统中推荐的东西的常用术语。)
书签
首先,我们获取你所有未读的书签项目,并按照你之前滚动浏览它们的次数进行排序。对于跳过次数相同的项目,我们按书签的添加时间进行排序。“新鲜”的项目(那些被跳过次数较少且最近添加的书签)排在前面。
为了稍微改变一下,我们对这些项目进行部分洗牌。我编写了一个简单的洗牌算法,它倾向于将项目留在其原始位置附近。你可以设置一个 0 到 1 之间的“随机性”参数(我称之为 p):0 将使算法表现得像一个完全随机的洗牌,而 1 将使项目保持其原始顺序。
我已将 p 设置为 0.1。这可能听起来像是这些项目会大部分(但并非完全)处于随机顺序,从而最大限度地减少初始按新鲜度排序的影响。但是,该参数以非线性的方式影响随机性。以下图表大致显示了在给定 p 的不同值(x 轴)的情况下,洗牌列表中的第一个项目是原始列表中的前十个项目之一的概率(y 轴):
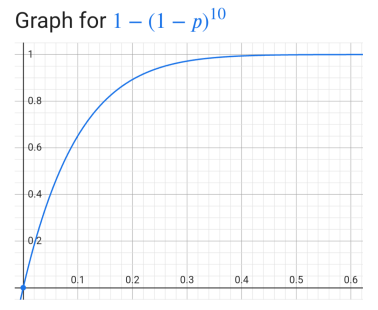
(从技术上讲,该公式还需要考虑原始列表大小的另一个术语;但是,如果原始列表至少有 50 个项目,则该术语非常小。)
因此,对于 p = 0.1,第一个书签项目有 65% 的可能性是前十个最新鲜的项目之一。在我开始使用重写的 app 之后,我可能会根据直觉调整该参数。
书签推荐的最后一步是,我们查看项目的 URL,并且每个网站(host)最多只推荐一个书签。我添加了这个过滤器,因为大约六个月前,我从某个特定网站上添加了几百篇文章的书签,它们仍然占据着我的 Yakread feed。我已经为订阅添加了类似的过滤器(每批订阅最多包含每个订阅的一篇文章)。
订阅
订阅推荐有两个主要步骤:首先,我们选择要推荐的订阅列表(以及它们的顺序);然后从每个订阅中选择一个 item。
我将首先解决第二步:它基本上与书签算法相同。我们按新鲜度对 item 进行排序,进行我们的随机洗牌,然后选择结果列表中的第一个 item。
为了首先选择订阅,我们首先为每个订阅计算一个“亲和力得分”,该得分代表你对它的喜欢程度。我查看你与每个订阅的 10 个最新互动:
- view: 你第一次点击了该 item。
- skip: 你点击了 "For You" feed 中的后续 item,但没有点击这个。
- like / dislike: 你在查看 item 时点击了“喜欢”/“不感兴趣”按钮。
为了将这些互动转化为一个单一的分数,我目前为每个互动分配了有些随意的权重(例如,view 为 +2,skip 为 -1),然后我采用“beta 分布期望值”,这意味着:如果你在抛硬币,+2 代表两次正面朝上,而 -1 代表一次反面朝上,那么下一次得到正面的概率是多少?此外,为了帮助新的订阅获得更多曝光,我给它们一个 +3 的起始分数。
这种方法很简单,而且效果似乎还不错(当我使用该分数查询我自己的前/后 10 个订阅时,结果似乎是合理的)。但是,如果能够消除我选择权重的需要就好了。在某个时候,我可能会尝试使用某种机器学习模型,该模型可以获取互动列表并预测下一次互动的概率(显然 RNN 会起作用)。然后,该分数可以是下一个操作是积极的(即 view 或 like)的概率。
在按亲和力得分对订阅进行排序后,我们为用户手动置顶的订阅提供一些额外的优先级。我们将订阅分为两个列表,置顶和未置顶。然后,我们通过反复选择从哪个列表获取下一个交错订阅,将这些列表交错回一个列表。
大多数情况下,我们只需选择亲和力得分最高的订阅(置顶或未置顶)。但是,在 30% 的情况下,我们选择下一个置顶订阅,而不管亲和力如何。
完成所有这些操作后,我们对订阅列表进行随机洗牌,然后我们继续执行上述步骤,即从每个订阅中选择一个 item。
交错订阅和书签
至此,我们有一个订阅 item 列表和一个书签 item 列表,我们需要将它们交错成一个最终列表,该列表将显示给用户。一种简单且不差的方法是为最终列表中的每个 item 抛硬币:正面朝上,它来自订阅,反面朝上,它来自书签。而且,在基本层面上,我就是这么做的。
但是,如果用户拥有的订阅 item 多于书签,反之亦然,这可能会出现问题。如果你已经多次滚动浏览了所有未读的书签 item,但你有很多新的订阅 item,我们可能应该倾向于推荐订阅 item。
我通过成对比较这两个列表,并根据它们之前被跳过的次数(即在 "For You" feed 中滚动浏览的次数)通过加权随机选择来选择 item 来做到这一点。例如,如果第一个书签 item 已被跳过两次,而第一个订阅 item 已被跳过一次,则我们有 40% 的机会选择订阅 item,而有 60% 的机会选择书签 item。
Published 7 Apr 2025
I write an occasional newsletter about my work and ideas.
Subscribe
Error: It looks like that email is invalid. Try a different one.
Error: reCAPTCHA check failed. Try again.
Error: There was an unexpected error. Try again.
RSS feed · Archive
𝔗𝔥𝔦𝔰 𝔰𝔦𝔱𝔢 𝔦𝔰 𝔭𝔯𝔬𝔱𝔢𝔠𝔱𝔢𝔡 𝔟𝔶 𝔯𝔢𝔠𝔞𝔭𝔱𝔠𝔥𝔞 𝔞𝔫𝔡 𝔱𝔥𝔢 𝔊𝔬𝔬𝔤𝔩𝔢 𝔓𝔯𝔦𝔳𝔞𝔠𝔶 𝔓𝔬𝔩𝔦𝔠𝔶 𝔞𝔫𝔡 𝔗𝔢𝔯𝔪𝔰 𝔬𝔣 𝔖𝔢𝔯𝔳𝔦𝔠𝔢 𝔞𝔭𝔭𝔩𝔶.
