Show HN:让 Python 拥有 Rust 的速度
![]()
Python at the Speed of Rust
 蛇正在追赶螃蟹!
蛇正在追赶螃蟹!
Python 是世界上最流行的编程语言。它是一种极其简单且易于访问的语言,使其成为众多领域开发人员的首选。从计算机科学入门课程到驱动我们正在经历的 AI 革命,它被应用于各种场景。
然而,Python 的便利性带来了两个显着的缺点:首先,与 C 或 Rust 等原生语言相比,运行解释型语言会导致执行速度慢得多。其次,将 Python 驱动的函数(例如 Numpy、PyTorch)嵌入到跨平台的消费者应用程序(例如 Web 应用程序、移动应用程序)中非常困难。
但是,如果我们能将 Python 编译成原始的本机代码呢?
编译一个玩具函数
人工智能,特别是大型语言模型 (LLM),严重依赖矩阵乘法。这些矩阵运算的核心是被称为 fused multiply-add (FMA) 的基本运算:
def fma (x, y, z):
"""
执行一个 fused multiply-add.
"""
return x * y + z
Nvidia 等硬件供应商提供了专门的指令,可以在一个步骤中执行 FMA,从而减少计算开销并提高数值精度。鉴于 LLM 执行数十亿次这些操作,即使是很小的性能差异也会显着影响整体效率。
result = fma(x=3, y=-1, z=2)
print(result)
# -1
让我们探索如何编译 fma 函数,使其能够以本机速度跨平台运行。
追踪函数
我们首先捕获函数中执行的所有操作作为计算图。我们称之为中间表示 (IR)。此 IR 图显式表示每个操作——算术运算、方法调用和数据访问——使其成为强大的编译抽象。
为了构建此图,我们利用 CPython 的 frame evaluation API 来执行符号追踪 (Symbolic Tracing)。 这允许我们检查 Python 字节码执行,在函数执行时动态捕获每个指令的输入、操作和输出。 通过实时跟踪每个 Python 操作,我们构建了函数逻辑的准确 IR。 例如:
from torch._dynamo.eval_frame import set_eval_frame
# 定义一个 tracer
class Tracer:
def __call__ (self, frame, _):
print(frame.f_code, frame.f_func, frame.f_locals)
# 设置 frame evaluation handler
tracer = Tracer()
set_eval_frame(tracer)
# 调用函数
result = fma(x=3, y=-1, z=2)
print(result)
# <code object fma at 0x106c51ca0, file "fma.py", line 9> <function fma at 0x106ba4860> {'x': 3, 'y': -1, 'z': 2}
# -1
跳过几个步骤,我们最终得到一个如下所示的图:
type name target args
-------------- ---------- ------------- --------
input x x ()
input y y ()
input z z ()
call_function mul_result _operator.mul (x, y)
call_function add_result _operator.add (mul_result, z)
output output output (add_result,)
一位敏锐的读者可能会注意到,为了构建上面的 IR 图,我们需要实际调用 fma 函数。 要做到这一点,我们需要将具有正确类型的输入传递给该函数。 我们可以简单地将类型注释添加到我们的 fma 函数,并生成虚假输入来调用该函数:
def fma (x: float, y: float, z: float) -> float:
"""
执行一个 fused multiply-add.
"""
return x * y + z
降低到原生代码
现在真正的乐趣开始了! 通过我们的 IR 图和带注释的输入类型,我们开始将 IR 图降低到原生代码的过程。 让我们看一下图中的第一个操作,x * y:
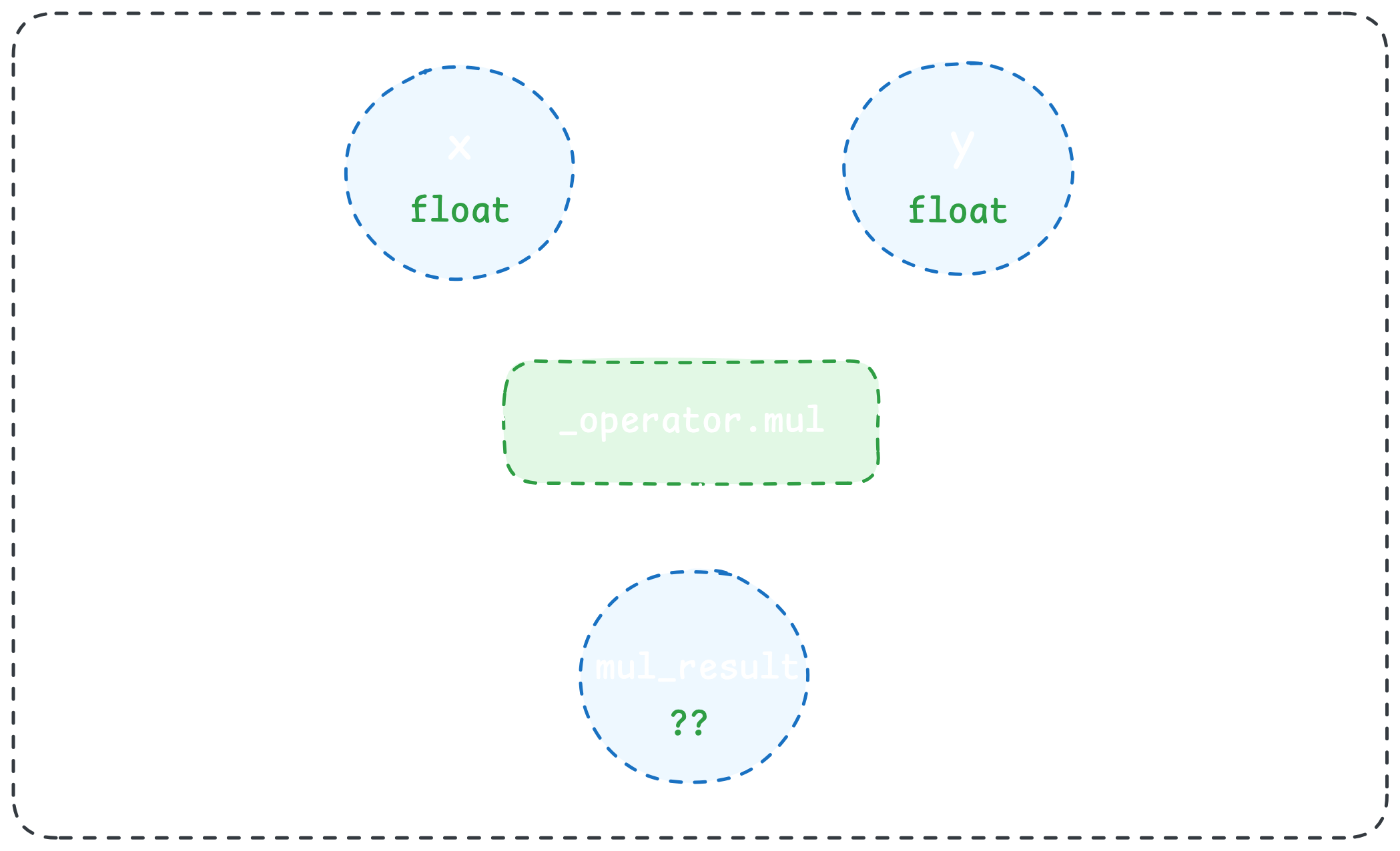
我们可以编写(*ahem * 生成)本机代码中 _operator.mul 操作的相应实现。 例如,这是一个 C 实现:
float _operator_mul (float x, float y) {
return x * y;
}
请注意,由于上面本机实现的返回类型,mul_result 的类型现在被限制为 float。 放大来看,这意味着给定具有已知类型的输入(即来自 Python 中的类型注释)以及 Python 操作的本机实现,我们可以完全确定操作输出的本机类型。 通过对 IR 图中的后续操作重复此过程,我们可以通过整个 Python 函数传播本机类型:
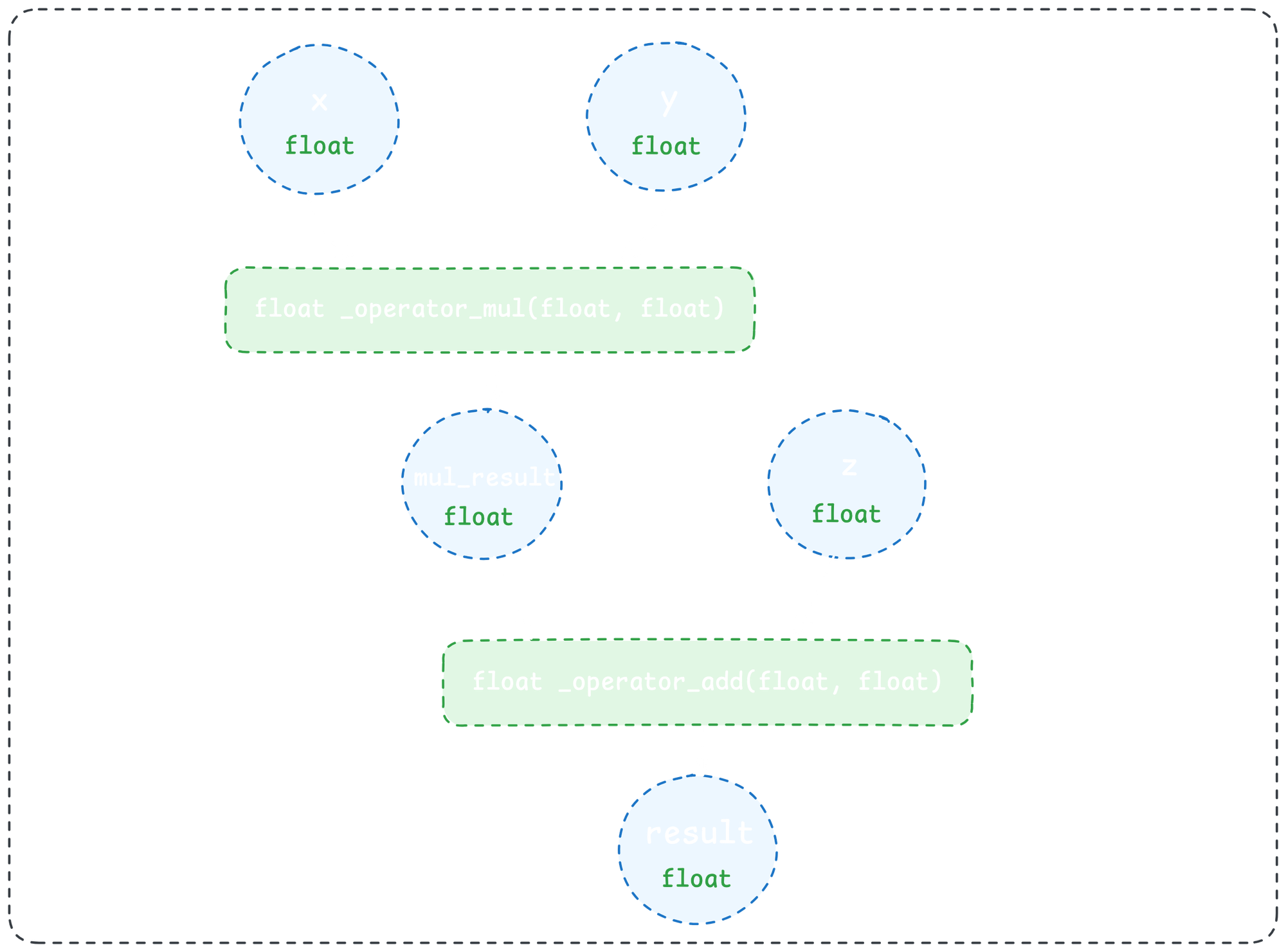
我们现在可以为我们想要的任何平台(WebAssembly、Linux、Android 等等)交叉编译这个本机实现。 这就是我们让 Python 像 Rust 一样快地运行——并且随处运行的方式!
编译函数
让我们使用 Function 基于上述过程编译 fma 函数。 首先,为 Python 安装 Function:
# 在终端中运行
$ pip install --upgrade fxn
接下来,使用 @compile 装饰器装饰 fma 函数:
from fxn import compile
@compile(
tag="@yusuf/fma",
description="Fused multiply-add."
)
def fma (x: float, y: float, z: float) -> float:
"""
执行一个 fused multiply-add.
"""
return x * y + z
要使用 Function 编译函数,请使用 @compile 装饰器。
最后,使用 Function CLI 编译函数:
# 在终端中运行
$ fxn compile fma.py
使用 Function CLI 编译函数。

让我们进行基准测试!
首先,让我们修改我们的 fma 函数以重复执行 fused multiply-add:
def fma (x: float, y: float, z: float, n_iter: int) -> float:
for _ in range(n_iter):
result = x * y + z
return result
接下来,我们将创建一个等效的 Rust 实现:
use std::os::raw::c_int;
#[no_mangle]
pub extern "C" fn fma (x: f32, y: f32, z: f32, n_iter: c_int) -> f32 {
let mut result = 0.0;
for _ in 0..n_iter {
result = x * y + z;
}
result
}
编译两者后,这是我的 MacBook Pro 上的性能图:
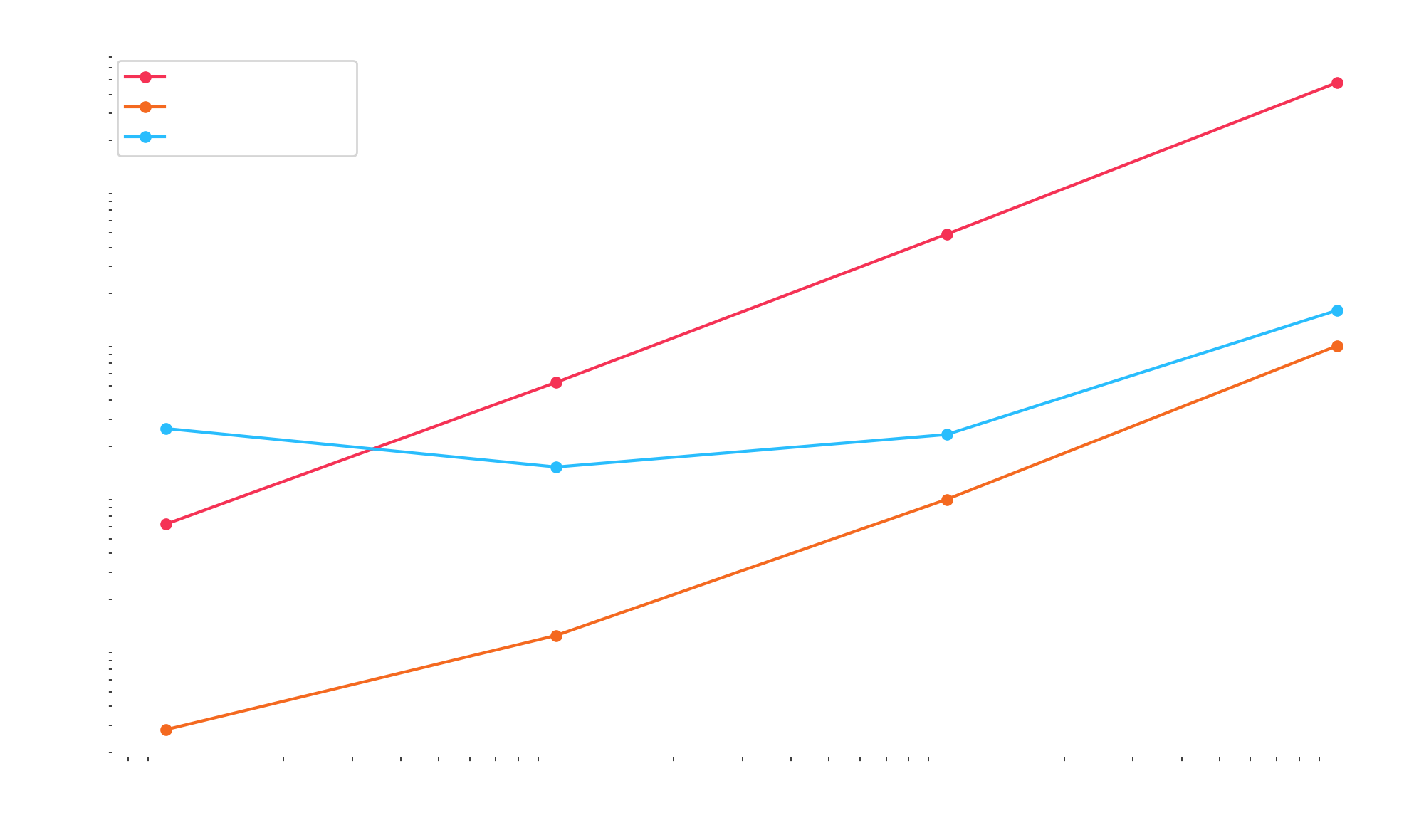
编译后的 Python 基准测试比 Rust 慢一个常数因子,因为 Function 具有额外的 scaffolding 来调用预测函数,而 Rust 实现使用直接调用。 您可以检查生成的本机代码,并使用此存储库重现该基准测试:
总结
能够编译 Python 的前景对我们来说非常令人兴奋。 这意味着我们可以加速科学计算、实时数据处理和 AI 工作负载,以便在更多设备上运行——所有这些都来自 Python 的便利性。
我们的编译器仍然是一个概念验证,但通过它,我们的设计合作伙伴一直在将应用程序投入生产,为从单目深度估计到实时姿势检测的所有内容提供动力。 下一步是什么? 设备上的 LLM 推理。 加入对话:
Yusuf Olokoba
Apr 8, 2025 ← Previous
Function © 2025. Powered by Ghost