Google Cloud Rapid Storage
标题:Google Cloud 快速存储方案
介绍 Ironwood TPUs 以及 AI Hypercomputer 的最新创新
2025年4月9日

Mark Lohmeyer
VP & GM, Compute & AI Infrastructure
George Elissaios
VP, Product Management, Compute Engine & AI Infrastructure
Google Cloud Next 直播
关于 AI 和云的直播主题演讲和点播讲座 立即观看
今天的创新并非诞生于实验室或绘图板,而是建立在 AI 基础设施的基石之上。AI 工作负载具有新的和独特的需求——解决这些问题需要精心设计的硬件和软件组合,以实现大规模的性能和效率,以及访问此基础设施所需的易用性和灵活性。在 Google Cloud,我们通过 AI Hypercomputer 提供这一点。
AI Hypercomputer 是一个集成的超级计算系统,它提炼了 Google 在 AI 领域十多年的专业知识。AI Hypercomputer 支撑着几乎所有在 Google Cloud 上运行的 AI 工作负载;当您使用 Vertex AI 时,它在后台运行,或者您可以直接访问 AI Hypercomputer 的性能优化硬件、开放软件和灵活的消费模式,从而精细地控制您的基础设施——所有这些都旨在以始终如一的低廉价格为训练和服务 AI 工作负载提供更多的智能。这种集成系统方法在市场上与众不同,也是 Gemini Flash 2.0 的每美元智能比 GPT-4o 高 24 倍,比 DeepSeek-R11 高 5 倍的原因之一。
今天,我们正在推出 AI Hypercomputer 堆栈中的新创新,这些创新旨在协同设计,从而为 AI 工作负载提供最高的每美元智能。
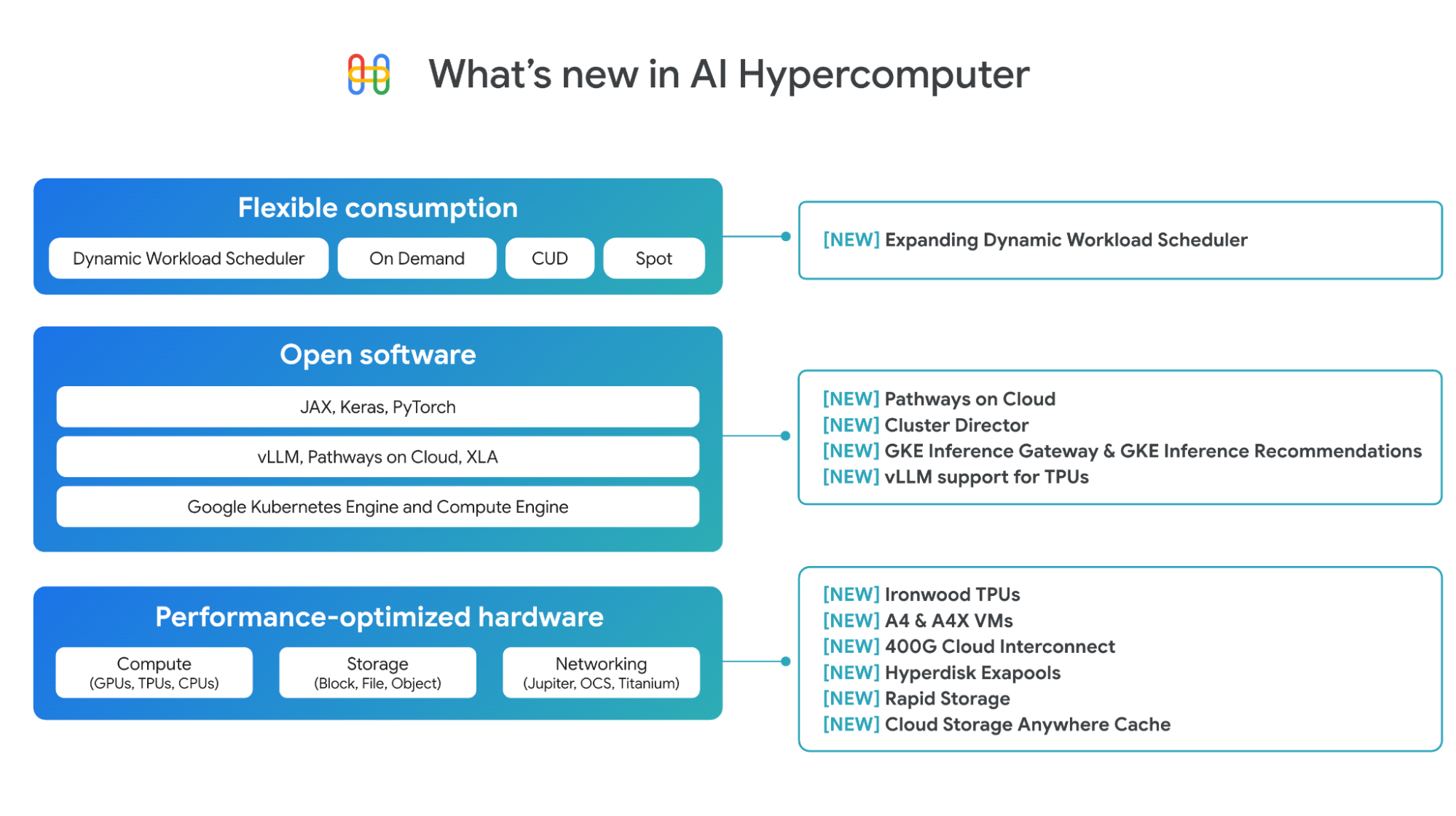
性能优化硬件方面的进展
我们继续扩展我们的性能优化硬件组合,以提供各种用于计算、网络和存储的选项。
Ironwood,我们的第七代 TPU: Ironwood 专为推理而构建,与上一代 Trillium 相比,提供 5 倍以上的峰值计算能力和 6 倍的高带宽内存 (HBM) 容量。Ironwood 有两种配置:256 个芯片或 9,216 个芯片,每个配置都可用作单个纵向扩展 pod,更大的 pod 提供惊人的 42.5 exaFLOPS 的计算能力。Ironwood 在实现这一目标的同时,比 Trillium 节能 2 倍,从而每瓦特提供更高的价值。开发人员可以通过我们的优化堆栈,跨 PyTorch 和 JAX 访问 Ironwood。在此处了解有关此突破性 TPU 的更多信息here。

A4 和 A4X VMs: Google Cloud 是第一家提供带有 A4 和 A4X VMs 的 NVIDIA B200 和 GB200 NVL72 GPUs 的超大规模厂商。我们于上个月在 NVIDIA GTC 上宣布 A4 VMs (NVIDIA B200) 正式发布,A4X VMs (NVIDIA GB200) 现在处于预览阶段。在此处了解有关 A4 和 A4X 的更多信息 here。
增强的网络: 为了支持 AI 工作负载所需的超低延迟,我们的新 400G Cloud Interconnect 和 Cross-Cloud Interconnect 提供高达 4 倍于我们的 100G Cloud Interconnect 和 Cross-Cloud Interconnect 的带宽,从而提供从本地或其他云环境到 Google Cloud 的连接。在今天的网络博客中阅读更多信息 here。
Hyperdisk Exapools:块存储,具有每个 AI 集群最高的性能和容量,因此您可以在单个精简配置的池中配置高达 exabytes 的块存储容量和许多 TB/s 的吞吐量。
Rapid Storage: 一种新的 Cloud Storage 区域存储桶,使您能够将主存储与 TPU 或 GPU 并置,以实现最佳利用率。它提供比 Cloud Storage 区域存储桶快 20 倍的随机读取数据加载速度。
Cloud Storage Anywhere Cache: 一种新的、强一致的读取缓存,可与现有区域存储桶配合使用,以在选定的区域内缓存数据。Anywhere Cache 通过使数据更接近加速器,将延迟降低 70%,从而实现响应式和实时推理交互。
$300 免费额度用于试用 Google Cloud 基础设施
使用可扩展且灵活的计算资源为您的应用程序提供动力,新客户可获得 300 美元的免费额度。此外,所有客户都可以免费每月使用 20 多种产品,包括 Compute Engine。 免费开始构建
用于训练和推理的开放软件功能
硬件的真正价值在于协同设计的软件所释放的价值。AI Hypercomputer 的软件层通过开放和流行的 ML 框架和库(如 PyTorch、JAX、vLLM 和 Keras)帮助 AI 从业者和工程师更快地行动。对于基础设施团队来说,这意味着更快的交付时间和更具成本效益的资源利用率。我们在 AI 训练和推理方面都取得了显着进展。
Pathways on Cloud: Pathways 由 Google DeepMind 开发,是为 Google 的内部大规模训练和推理基础设施提供支持的分布式运行时,现在首次在 Google Cloud 上可用。对于推理,它包括解耦服务等功能,该功能允许在单独的计算单元上动态扩展推理工作负载的预填充和解码阶段,每个单元独立扩展以提供超低延迟和高吞吐量。客户可以通过 JetStream 访问它,JetStream 是我们的高吞吐量和低延迟推理库。Pathways 还支持弹性训练,允许您的训练工作负载在失败时自动缩减,在恢复时自动扩展,同时提供连续性。要了解有关 Pathways on Cloud 的更多信息,包括 Pathways 架构的其他用例,请阅读 documentation。
以高性能和高可靠性训练模型
训练工作负载是高度同步的作业,跨数千个节点运行。单个降级的节点可能会中断整个作业,从而导致更长的上市时间和更高的成本。要快速配置集群,您需要针对特定模型架构调整的 VMs,这些 VMs 位于紧邻的位置。您还需要能够快速预测和排除节点故障,并确保在发生故障时工作负载的连续性。
Cluster Director for GKE 和 Cluster Director for Slurm。Cluster Director(以前称为 Hypercompute Cluster)允许您将一组加速器部署和管理为具有物理共置 VMs、目标工作负载放置、高级集群维护控制和拓扑感知调度的单个单元。今天,我们宣布 Cluster Director 的新更新,将于今年晚些时候推出:
- **Cluster Director for Slurm,**一种完全托管的 Slurm 产品,具有简化的 UI 和 APIs,用于配置和操作 Slurm 集群,包括常见工作负载的蓝图,其中包含预配置的软件,以使部署可靠且可重复。
- 360**°**可观测性功能 包括仪表板,用于查看集群利用率、健康状况和性能,以及 AI Health Predictor 和 Straggler Detection 等高级功能,以主动检测和修复故障,直至单个节点。
- 作业连续性功能,如端到端自动化运行状况检查,可持续监控集群并抢先更换不健康的节点。即使在降级的集群中,也能实现不间断的训练,并具有多层检查点,可加快保存和检索速度。
Cluster Director for GKE 将原生支持新的 Cluster Director 功能,因为它们会变得可用。Cluster Director for Slurm 将在未来几个月内推出,包括对 GPU 和 TPU 的支持。注册 以获得早期访问权限。
以任何规模高效地运行推理工作负载
AI 推理在过去一年中发展迅速。更长且高度可变的环境窗口导致更复杂的交互;推理和多步推理正在将计算的增量需求(以及因此产生的成本)从训练时间转移到推理时间(测试时间缩放)。要为最终用户启用有用的 AI 应用程序,您需要能够有效服务于今天和未来交互的软件。
宣布 GKE 中的 AI 推理功能: Inference Gateway 和 Inference Quickstart。
- GKE Inference Gateway 提供智能缩放和负载平衡功能,通过 gen AI 模型感知缩放和负载平衡技术帮助您处理请求调度和路由。
- 借助 GKE Inference Quickstart,您可以选择一个 AI 模型和您想要的性能,GKE 将配置正确的基础设施、加速器和 Kubernetes 资源来匹配。
这两个功能今天都处于预览阶段,与其他的托管的和开源的 Kubernetes 产品相比,总体上将服务成本降低超过 30%,尾部延迟降低 60%,吞吐量提高多达 40%。
vLLM 支持 TPU: vLLM 以其快速而高效的推理库而闻名。从今天开始,您可以轻松地使用 vLLM 在 TPU 上运行推理,并在不更改软件堆栈的情况下获得其性价比优势,只需进行一些配置更改即可。Compute Engine、GKE、Vertex AI 和 Dataflow 中都支持 vLLM。借助 GKE custom compute classes,您可以在同一个 vLLM 部署中同时使用 TPU 和 GPU。
使消费更加灵活
Dynamic Workload Scheduler (DWS) 是一个资源管理和作业调度平台,可帮助您轻松且经济地访问加速器。今天,我们宣布在 DWS 中扩展的加速器支持,包括 TPU v5e、Trillium、A3 Ultra (NVIDIA H200) 和 A4 (NVIDIA B200) VMs,通过 Flex Start 模式进行预览,TPU 的 Calendar 模式支持将于本月晚些时候推出。此外,Flex Start 模式现在支持一种新的配置方法,其中可以立即配置资源并动态缩放,使其适用于长时间运行的推理工作负载和更广泛的训练工作负载。这是 Flex Start 模式的排队配置方法的补充,该方法要求同时配置所有节点。
在 Next ‘25 了解有关 AI Hypercomputer 的信息
不要错过行动。收听我们所有的公告以及对 event website 的深入探讨。首先是 What’s next in compute and AI infrastructure,然后查看以下分组:
- AI Hypercomputer: Performance, scale, and the power of Pathways,
- Google Cloud TPUs and specialized AI hardware: Jeff Dean on what's next,
- GKE and AI Hypercomputer: Build a scalable, secure, AI-ready container platform,
- Inference at scale with Google Cloud’s AI Hypercomputer
- Hypercompute Cluster: GPU infrastructure platform for large-scale distributed AI workloads
1. arXiv (LMArena), Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference, Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios 1 Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E. Gonzalez, Ion Stoica, 2024. Accurate as of Mar 19, 2025. This benchmark compares model output quality (as judged by human reviewers) to the price/1M tokens required to generate the output, creating an efficiency comparison. We define ‘intelligence’ as a human’s perception of model output quality. 发布于
相关文章
 ComputeGoogle Axion processors boost AlloyDB, Cloud SQL, major customers, and ISVsBy Mark Lohmeyer • 5-minute read
ComputeGoogle Axion processors boost AlloyDB, Cloud SQL, major customers, and ISVsBy Mark Lohmeyer • 5-minute read
 ComputeDriving enterprise transformation with new compute innovations and offeringsBy Nirav Mehta • 7-minute read
ComputeDriving enterprise transformation with new compute innovations and offeringsBy Nirav Mehta • 7-minute read
 Infrastructure ModernizationAccelerate Mainframe Modernization with gen AI from Google Cloud and its partnersBy Nirav Mehta • 4-minute read
Infrastructure ModernizationAccelerate Mainframe Modernization with gen AI from Google Cloud and its partnersBy Nirav Mehta • 4-minute read
 AI & Machine LearningAnyscale powers AI compute for any workload using Google Compute EngineBy Matthew Connor • 8-minute read
AI & Machine LearningAnyscale powers AI compute for any workload using Google Compute EngineBy Matthew Connor • 8-minute read
页脚链接
关注我们
Google Cloud
-
LanguageEnglishDeutschFrançais한국어日本語