Cloudflare R2 数据目录:零出口费用的托管式 Apache Iceberg 表
R2 Data Catalog: 零出口费用的托管式 Apache Iceberg 表
2025-04-10
阅读需时 4 分钟
Apache Iceberg 正在迅速成为在对象存储中查询大型分析数据集的标准表格式。 我们亲身经历了这一趋势,越来越多的开发者和数据团队在 Cloudflare R2 上采用 Iceberg。 但到目前为止,将 Iceberg 与 R2 结合使用意味着要管理额外的基础设施或依赖外部数据目录。
因此,我们正在解决这个问题。 今天,我们推出了开放测试版的 R2 Data Catalog,这是一个直接构建到您的 Cloudflare R2 bucket 中的托管式 Apache Iceberg 目录。
如果您还不熟悉 Iceberg,它是一种开放的表格式,专为对象存储中存储的数据集进行大规模分析而构建。 借助 R2 Data Catalog,您可以获得 Iceberg 闻名的类数据库功能 – ACID 事务、schema 演化和高效查询 – 而无需管理自己的外部目录的开销。
R2 Data Catalog 公开了一个标准的 Iceberg REST catalog 接口,因此您可以连接已经使用的引擎,如 PyIceberg、Snowflake 和 Spark。 而且,与 R2 一样,始终没有出口费用,这意味着无论您的数据从哪个云或区域使用,您都不必担心不断增长的数据传输成本。
准备好立即在 R2 中查询数据了吗? 进入 developer docs,只需点击几下即可在您的 R2 bucket 上启用数据目录。 或者继续阅读以了解有关 Iceberg、数据目录、元数据文件如何在底层工作以及如何创建您的第一个 Iceberg 表的更多信息。
什么是 Apache Iceberg?
Apache Iceberg 是一种开放的表格式,用于分析对象存储中的大型数据集。 它将类数据库功能 – ACID 事务、时间旅行和 schema 演化 – 带到以 Parquet 或 ORC 等格式存储的文件中。
从历史上看,数据湖只是对象存储中原始文件的集合。 但是,如果没有统一的元数据层,数据集很容易损坏,难以演化,并且查询通常需要昂贵的整表扫描。
Iceberg 通过以下方式解决这些问题:
- 提供 ACID 事务,用于可靠的并发读写。
- 维护优化的元数据,以便引擎可以跳过不相关的文件,并避免不必要的整表扫描。
- 支持 schema 演化,允许添加、重命名或删除列,而无需重写现有数据。
Iceberg 已经得到了 Apache Spark、Trino、Snowflake、DuckDB 和 ClickHouse 等引擎的 广泛支持,并且背后有一个快速增长的社区。
Iceberg 表是如何存储的
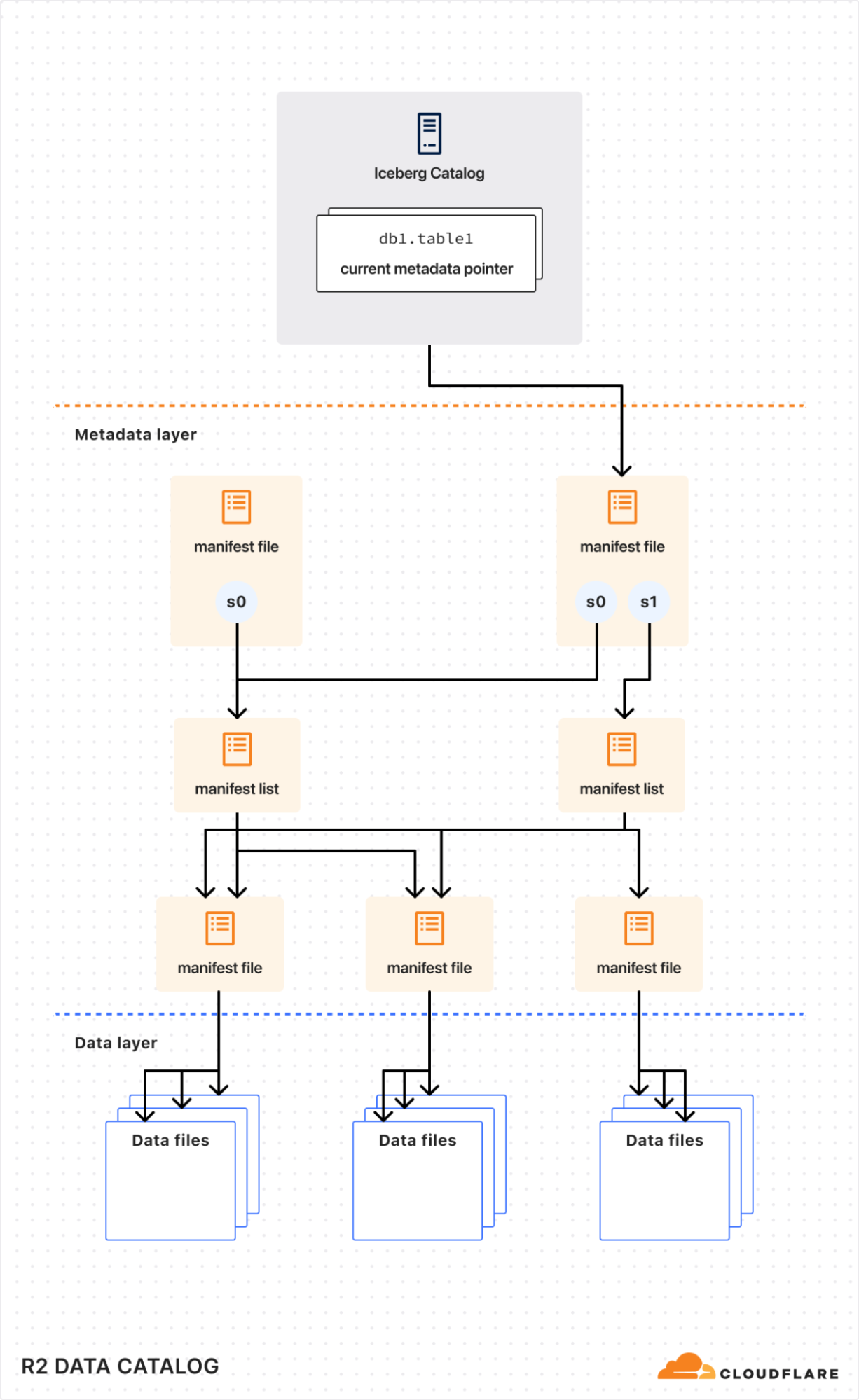
在内部,Iceberg 表是数据文件(通常以 Parquet 或 ORC 等列式格式存储)和元数据文件(通常以 JSON 或 Avro 格式存储)的集合,用于描述表快照、schema 和分区布局。
要了解查询引擎如何有效地与 Iceberg 表交互,查看 Iceberg 元数据文件(简化版)会有所帮助:
{
"format-version": 2,
"table-uuid": "0195e49b-8f7c-7933-8b43-d2902c72720a",
"location": "s3://my-bucket/warehouse/0195e49b-79ca/table",
"current-schema-id": 0,
"schemas": [
{
"schema-id": 0,
"type": "struct",
"fields": [
{ "id": 1, "name": "id", "required": false, "type": "long" },
{ "id": 2, "name": "data", "required": false, "type": "string" }
]
}
],
"current-snapshot-id": 3567362634015106507,
"snapshots": [
{
"snapshot-id": 3567362634015106507,
"sequence-number": 1,
"timestamp-ms": 1743297158403,
"manifest-list": "s3://my-bucket/warehouse/0195e49b-79ca/table/metadata/snap-3567362634015106507-0.avro",
"summary": {},
"schema-id": 0
}
],
"partition-specs": [{ "spec-id": 0, "fields": [] }]
}
一些重要的组件是:
schemas: Iceberg 跟踪 schema 随时间的变化。 引擎使用 schema 信息来安全地读取和写入数据,而无需重写底层文件。snapshots: 每个快照都引用一组特定的数据文件,这些数据文件表示表在某个时间点的状态。 这启用了时间旅行等功能。partition-specs: 这些定义了表是如何逻辑分区的。 查询引擎在规划期间利用此信息来跳过不必要的分区,从而大大提高查询性能。
通过读取 Iceberg 元数据,查询引擎可以有效地修剪分区,仅加载相关的快照,并仅获取所需的数据文件,从而加快查询速度。
为什么需要数据目录?
虽然 Iceberg 数据和元数据文件本身直接位于对象存储(如 R2)中,但表列表和指向当前元数据的指针需要由数据目录集中跟踪。
将数据目录视为图书馆的索引系统。 虽然书籍(您的数据)在物理上分布在书架(对象存储)上,但索引提供了一个关于存在哪些书籍、它们的位置以及它们的最新版本的单一事实来源。 如果没有此索引,读者(查询引擎)将浪费时间搜索书籍,可能访问过时的版本,或者可能以使其无法找到的方式意外地将新书上架。
同样,数据目录确保一致、协调的访问,允许多个查询引擎安全地读取和写入同一张表,而不会发生冲突或数据损坏。
在 R2 上创建您的第一个 Iceberg 表
准备好尝试了吗? 这是一个使用 PyIceberg 和 Python 的快速示例,可帮助您入门。 有关详细的分步指南,请查看我们的 developer docs。
- 在您的 bucket 上启用 R2 Data Catalog:
npx wrangler r2 bucket catalog enable my-bucket
或者使用 Cloudflare 仪表板:导航至 R2 Object Storage > Settings > R2 Data Catalog,然后点击 Enable。
-
创建一个具有 R2 存储和数据目录权限的 Cloudflare API token。
pip install pyiceberg pyarrow
- 连接到目录并创建表:
import pyarrow as pa
from pyiceberg.catalog.rest import RestCatalog
# Define catalog connection details (replace variables)
WAREHOUSE = "<WAREHOUSE>"
TOKEN = "<TOKEN>"
CATALOG_URI = "<CATALOG_URI>"
# Connect to R2 Data Catalog
catalog = RestCatalog(
name="my_catalog",
warehouse=WAREHOUSE,
uri=CATALOG_URI,
token=TOKEN,
)
# Create default namespace
catalog.create_namespace("default")
# Create simple PyArrow table
df = pa.table({
"id": [1, 2, 3],
"name": ["Alice", "Bob", "Charlie"],
})
# Create an Iceberg table
table = catalog.create_table(
("default", "my_table"),
schema=df.schema,
)
现在,您可以像使用任何 Apache Iceberg 表一样,附加更多数据或运行查询。
定价
在 R2 Data Catalog 处于开放测试阶段时,除了查询引擎访问数据产生的标准 R2 存储和操作成本外,不会产生额外费用。 启用 R2 Data Catalog 的 bucket 的 Storage pricing 与标准 R2 bucket 相同 – 每 GB-月 0.015 美元。 与往常一样,直接从 R2 bucket 出站的出口费用始终为 0 美元。
未来,我们计划为目录操作(例如,创建表、检索表元数据等)和数据压缩引入定价。
以下是我们目前对未来定价的考虑。 我们将在计费开始前详细说明时间安排,以便您可以自信地规划您的工作负载。
定价
R2 存储,标准存储类 | 每 GB-月 0.015 美元(无变化) R2 Class A 操作 | 每百万次操作 4.50 美元(无变化) R2 Class B 操作 | 每百万次操作 0.36 美元(无变化) Data Catalog 操作,例如,创建表、获取表元数据、更新表属性 | 每百万次目录操作 9.00 美元 Data Catalog 压缩数据处理 | 每 GB 处理 0.05 美元,每百万个对象处理 4.00 美元 数据出口 | 0 美元(无变化,始终免费)
接下来是什么?
我们很高兴看到您如何使用 R2 Data Catalog! 如果您以前从未使用过 Iceberg – 甚至没有使用过分析数据 – 我们认为这是开始使用的最简单方法。
我们路线图上的下一步是解决压缩和表优化。 查询引擎在处理较少但较大的数据文件时通常表现更好。 我们将自动将小数据文件的集合重写为较大的文件,以提供更快的查询性能。
我们还在与广泛的 Apache Iceberg 社区合作,以扩展查询引擎与 Iceberg REST Catalog 规范的兼容性。
我们很乐意听取您的反馈。 加入 Cloudflare Developer Discord 提出问题并在公开测试期间分享您的想法。 有关更多详细信息、示例和指南,请访问我们的 developer documentation。