交叉熵与 KL 散度 (Cross-Entropy and KL Divergence)
Cross-entropy and KL divergence
2025年4月12日 06:54 标签 Math , Machine Learning
交叉熵 (Cross-entropy) 广泛应用于现代 ML 中,用于计算分类任务的损失。 这篇文章简要概述了其背后的数学原理以及一个相关的概念,称为 Kullback-Leibler (KL) 散度。
单个随机事件的信息量
我们从一个概率为 p 的单一事件 (E) 开始。 该事件发生的信息内容(或“惊讶程度”)定义为:
\[I(E) = \log_2 \left (\frac{1}{p} \right )\]
这里使用以 2 为底的对数,以便我们可以用 比特 为单位计算信息。 直观地思考这个定义,想象一个概率为 p=1 的事件; 使用公式,我们通过观察此事件发生而获得的信息为 0,这是有道理的。 在另一个极端,当概率 p 接近 0 时,我们获得的信息是巨大的。 一个等效的公式写法是:
\[I(E) = -\log_2 p\]
一些数值示例:假设我们掷一个均匀的硬币,结果是正面。 此事件发生的概率是 1/2,因此:
\[I(E_{heads})=-\log_2 \frac{1}{2} = 1\]
现在假设我们掷一个均匀的骰子,结果是 4。 此事件发生的概率是 1/6,因此:
\[I(E_4)=-\log_2 \frac{1}{6} = 2.58\]
换句话说,掷出 4 的惊讶程度高于掷出正面的惊讶程度——考虑到所涉及的概率,这是有道理的。
除了对边界值表现正确之外,对数函数对于计算惊讶程度的另一个重要原因是:它对事件组合的表现方式。
考虑一下:我们掷一个均匀的硬币并掷一个均匀的骰子; 硬币结果是正面,骰子结果是 4。 发生此事件的概率是多少? 因为这两个事件是独立的,所以概率是单个事件概率的乘积,即 1/12,然后:
\[I(E_{heads}\cap E_{4})=-\log_2 \frac{1}{12} = 3.58\]
请注意,熵是各个事件熵的精确_和_。 这是意料之中的——一个事件我们需要这么多比特,另一个事件需要这么多比特; 比特总数加起来。 对数函数为我们提供了概率的这种行为:
\[\log(p_1 \cap p_2) = \log(p_1 \cdot p_2) = \log(p_1) + \log(p_2)\]
熵 (Entropy)
给定一个随机变量 X,其值为 x_1\dots x_n,相关概率为 p_1\dots p_n,X 的熵 定义为 X 的信息的期望值:
\[H(X)=-\sum_{j=1}^{n}p_j \log_2 p_j\]
高熵意味着高不确定性,而低熵意味着低不确定性。 让我们看几个例子:
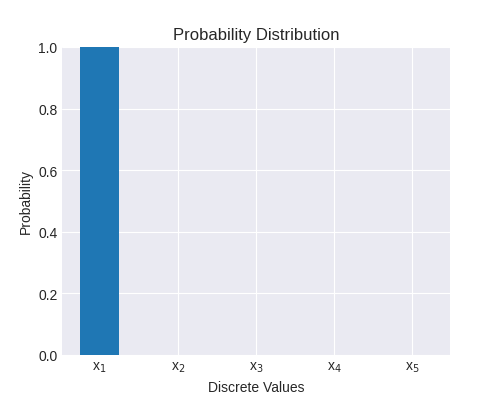
这是一个具有 5 个不同值的随机变量; x_1 的概率为 1,其余为 0。 这里的熵为 0,因为 1\cdot \log 1 = 0 并且 0\cdot \log 0 = 0 [1]。 通过观察从此分布中抽样的事件,我们没有获得任何信息,因为我们事先知道会发生什么。
另一个例子是 5 种可能结果的均匀分布:
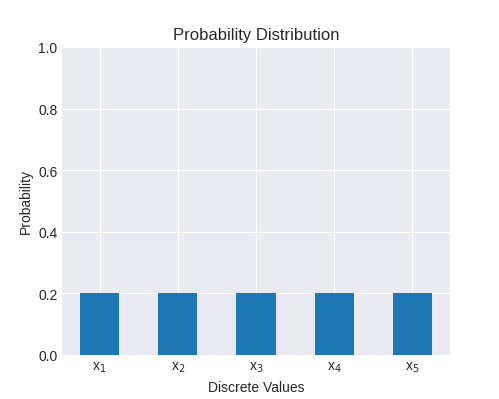
此分布的熵为:
\[H(X)=-\sum_{j=1}^{5}0.2 \log_2 0.2 = 2.32\]
直观地:我们有 5 个具有相同概率的不同值,因此我们需要 \log_{2} 5=2.32 比特来表示它。 请注意,熵始终是非负的,因为 0\leq p_j \leq 1,因此对于适当的概率分布中的所有 j,\log_2 p_j \leq 0。
不难证明,随机变量的最大可能熵发生在均匀分布中。 在所有其他分布中,某些值的表示形式比其他值更多,这使得结果不那么令人惊讶。
交叉熵 (Cross-entropy)
当存在两个不同的概率分布时,交叉熵是熵概念的扩展。 对机器学习有用的典型公式是:
\[H(P,Q)=-\sum_{j=1}^{n}p_j \log_2 q_j\]
其中:
- P 是实际观察到的数据分布
- Q 是预测的数据分布
与熵类似,交叉熵是非负的; 事实上,当 P 和 Q 相同时,它会简化为熵公式:
\[H(P,P)=-\sum_{j=1}^{n}p_j \log_2 p_j=H(P)\]
交叉熵的信息论解释是:当我们假设数据遵循 Q 时,编码实际概率分布 P 所需的平均比特数。
这是一个数值示例:
p = [0.1, 0.2, 0.4, 0.2, 0.1]
q = [0.2, 0.2, 0.2, 0.2, 0.2]
绘制:
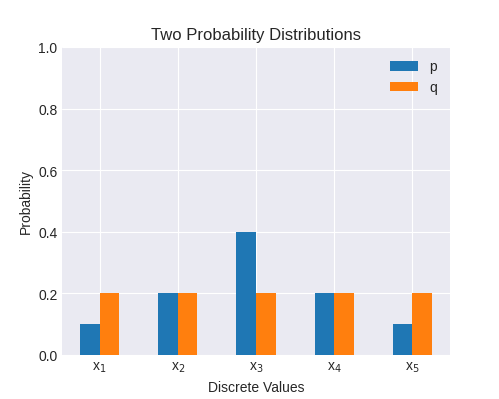 这两个分布的交叉熵为 2.32
这两个分布的交叉熵为 2.32
现在让我们尝试一个略微接近 P 的 Q:
p = [0.1, 0.2, 0.4, 0.2, 0.1]
q = [0.15, 0.175, 0.35, 0.175, 0.15]
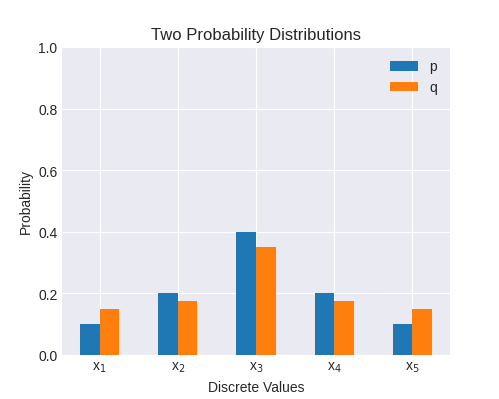 这些分布中的交叉熵略低,为 2.16; 这是预料之中的,因为它们更相似。 换句话说,当我们的模型预测 Q 时,测量 P 的结果就不那么令人惊讶了。
这些分布中的交叉熵略低,为 2.16; 这是预料之中的,因为它们更相似。 换句话说,当我们的模型预测 Q 时,测量 P 的结果就不那么令人惊讶了。
KL 散度 (KL Divergence)
交叉熵对于跟踪模型的训练损失很有用(下一节将对此进行更多介绍),但它具有一些数学特性,使其不太适合作为比较两个概率分布的统计工具。 具体来说,H(P,P)=H(P),它(通常)不为零; 这是交叉熵的最低可能值。 换句话说,交叉熵总是保留 P 的固有不确定性。
KL 散度通过从交叉熵中减去 H(P) 来解决这个问题:
\[D_{KL}(P,Q)=H(P,Q)-H(P)=-\left (\sum_{j=1}^{n}p_j \log_2 q_j - \sum_{j=1}^{n}p_j \log_2 p_j \right )\]
操作对数,我们还可以得到这些替代公式:
\[D_{KL}(P,Q)=-\sum_{j=1}^{n}\log_2 \frac{q_j}{p_j}=\sum_{j=1}^{n}\log_2 \frac{p_j}{q_j}\]
因此,KL 散度更适合作为两个概率分布之间的 divergence 的度量,因为 D_{KL}(P,P)=0。 但是请注意,它不是真正的 距离度量,因为它不是对称的:
\[D_{KL}(P,Q)\ne D_{KL}(Q,P)\]
在机器学习中的应用
在 ML 中,我们经常有一个模型进行预测,以及一组定义真实世界概率分布的训练数据。 根据两个分布(模型的预测和真实数据)之间的差异定义损失函数是很自然的。
交叉熵非常有用,因为它为非负数,并提供了一个标量值,该标量值对于相似的分布较低,而对于不相似的分布较高。 此外,如果我们将交叉熵视为 KL 散度:
\[H(P,Q)=D_{KL}(P,Q)+H(P)\]
我们会注意到 H(P)(真实世界分布的熵)根本不依赖于模型。 因此,优化交叉熵等效于优化 KL 散度。 我在之前的文章中写过关于交叉熵作为损失函数的具体用法:
也就是说,KL 散度有时也更有用; 例如,在用于 Variational autoencoders 的 evidence lower bound 中。
与最大似然估计的关系
本文中讨论的概念与 Maximum Likelihood Estimation 之间存在有趣的关系。
假设我们有一个真实的概率分布 P 和一个预测概率分布 Q_\theta 的参数化模型。 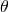 代表我们模型的所有参数(例如,深度学习网络的所有权重)。
代表我们模型的所有参数(例如,深度学习网络的所有权重)。
观察从 P 中抽取的一组样本 x_1\cdots x_n 的 似然性 为:
\[L=\prod ^{n}_{i=1}P(x_i)\]
但是,我们并不真正知道 P; 我们所知道的是 Q_\theta,所以我们可以计算:
\[L(\theta)=\prod ^{n}{i=1}Q\theta(x_i)\]
这个想法是找到一组最佳参数 \widehat{\theta},使得这种似然性最大化; 换句话说:
\[\widehat{\theta}=\underset{\theta}{argmax}\ L(\theta)=\underset{\theta}{argmax}\ \prod ^{n}{i=1}Q\theta(x_i)\]
然而,处理乘积是不方便的,因此使用对数将乘积转换为和(由于 log(f(x)) 是单调递增函数,因此最大化它类似于最大化 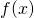 本身):
本身):
\[\widehat{\theta}=\underset{\theta}{argmax}\ \log L(\theta)=\underset{\theta}{argmax}\ \sum ^{n}{i=1}\log Q\theta(x_i)\]
这是 最大对数似然性。
现在采用一种聪明的统计技巧; 首先,我们将我们要最大化的函数乘以常数 \frac{1}{n} - 当然,这不会影响最大值:
\[\widehat{\theta}=\underset{\theta}{argmax}\ \frac{1}{n}\sum ^{n}{i=1}\log Q\theta(x_i)\]
argmax 内部的函数现在是从真实概率分布 P 获得的 n 个样本的平均值。 大数定律 表明,对于足够大的 n,此平均值收敛于从此分布中抽取的期望值:
\[\widehat{\theta}=\underset{\theta}{argmax}\ \sum ^{n}{i=1}P(x_i)\log Q\theta(x_i)\]
这应该开始看起来很熟悉了; 剩下的就是否定总和并最小化负数:
\[\widehat{\theta}=\underset{\theta}{argmin}\ -\sum ^{n}{i=1}P(x_i)\log Q\theta(x_i)\]
我们现在要最小化的函数是 交叉熵 P 和 Q_\theta 之间。 我们已经表明,最大似然估计等效于最小化真实数据分布和预测数据分布之间的交叉熵。
[1]| 这可以通过取极限 \lim_{p\to 0} p \log p 并使用 L'Hopital 法则表明它变为 0 来证明。
---|---
如有评论,请发送电子邮件给我。
© 2003-2025 Eli Bendersky
返回顶部