被遗忘的优化:理解 Fibonacci Hashing
Probably Dance
我可以编程,也喜欢游戏
Fibonacci Hashing: 被世界遗忘的优化 (或者:整数取模的更好替代方案)
作者:Malte Skarupke
我最近发表了一篇关于新型哈希表的博文,每当我做类似的事情时,我都会从评论中至少学到一件新东西。在我上次的评论区中,Rich Geldreich 谈到了他的哈希表,它使用了“Fibonacci Hashing”,这是我以前从未听说过的。我从事哈希表工作很多,所以我认为我至少听说过所有重要的技巧和技术,但我也知道有那么多小的调整和改进,你不可能全部都知道。我认为这可能是添加到集合中的另一个巧妙的小技巧。
事实证明我错了。这是一个大技巧。而且每个人都应该使用它。哈希表不应该是质数大小,并且它们不应该使用整数取模来将哈希值映射到槽中。Fibonacci Hashing 只是更好。然而,不知何故,没有人使用它,并且许多大型哈希表(包括 std::unordered_map 的所有大型实现)比它们应该的慢得多,因为它们没有使用 Fibonacci Hashing。所以让我们弄清楚这一点。
首先,我们如何找出这个 Fibonacci Hashing 是什么?Rich Geldreich 称其为“Knuth 的乘法方法”,但在《计算机程序设计艺术》中查找之前,我尝试在 Google 上搜索它。现在排名第一的结果是这个页面,这个页面很老,版权来自 1997 年。Wikipedia 上没有提到 Fibonacci Hashing。你会发现更多提到它的页面,主要来自在他们的“哈希表介绍”材料中介绍它的大学。
由此我认为这是一种他们在大学里教授的技术,但最终没有人使用它,因为它实际上在某种程度上更昂贵。哈希表中有很多这样的东西:因为理论上很好而被教授的东西,但在实践中很糟糕,所以没有人使用它们。
但不知何故,在这一点上,线路被交叉了。每个人都使用不必要地慢并且导致更多问题的算法,而没有人使用更快的同时对有问题模式更健壮的算法。Knuth 谈到了 Integer Modulo 和 Fibonacci Hashing,每个人都应该从中得出结论,他们应该使用 Fibonacci Hashing,但他们没有,每个人都使用整数取模。
在深入研究之前,让我向你展示一个简单基准测试的结果:在哈希表中查找项目:

在这个基准测试中,我正在比较各种 unordered_map 实现。我正在测量当键只是一个整数时它们的查找速度。X 轴是容器的大小,Y 轴是找到一个项目的时间。为了测量这一点,基准测试只是在一个循环中旋转,调用此容器上的 find(),最后我将循环所花费的时间除以循环中的迭代次数。因此,在左侧,当表足够小以适合缓存时,查找速度很快。在右侧,该表太大而无法放入缓存,并且查找变得慢得多,因为我们的大多数查找都会遇到缓存未命中。
但我主要想引起注意的是 ska::unordered_map 的速度,它使用了 Fibonacci Hashing。否则,它是一个完全正常的 unordered_map 实现:它只是一个链表的 vector,每个元素都存储在单独的堆分配中。在左侧,当表适合缓存时,ska::unordered_map 可以比 std::unordered_map 的 Dinkumware 实现快两倍以上,后者是下一个最快的实现。(这是你使用 Visual Studio 时得到的结果)
因此,如果你使用 std::unordered_map 并在循环中查找东西,如果哈希表使用 Fibonacci Hashing 而不是整数取模,则该循环可能会快两倍。
它是如何工作的
所以让我解释一下 Fibonacci Hashing 是如何工作的。它与黄金比例 



(该视频是分为三个部分系列的第二部分,第一部分在这里)
我知道这个技巧,因为它在程序化内容生成中很有用:任何时候你希望某些东西看起来是随机分布的,但你想确保没有集群,你至少应该尝试看看是否可以使用黄金比例。(如果这不起作用,在尝试随机数之前,也值得尝试 Halton 序列)但是不知何故,我从未想到将同样的技巧用于哈希表。
所以这是想法:假设我们的哈希表有 1024 个槽,并且我们想将任意大的哈希值映射到该范围。我们做的第一件事是使用上面的技巧将其映射到完整的 64 位数字范围。因此,我们将传入的哈希值乘以 
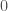

size_t fibonacci_hash_3_bits(size_t hash)
{
return (hash * 11400714819323198485llu) >> 61;
}
这将返回在与魔法常量相乘之后,上面的三个位。我们只看三个位,因为它很容易看到,当我们只看上面三个位的时候,黄金比例环绕是如何表现的。如果我们为哈希值传入一些小的数字,我们会从它得到下面的结果:
fibonacci_hash_3_bits(0) == 0
fibonacci_hash_3_bits(1) == 4
fibonacci_hash_3_bits(2) == 1
fibonacci_hash_3_bits(3) == 6
fibonacci_hash_3_bits(4) == 3
fibonacci_hash_3_bits(5) == 0
fibonacci_hash_3_bits(6) == 5
fibonacci_hash_3_bits(7) == 2
fibonacci_hash_3_bits(8) == 7
fibonacci_hash_3_bits(9) == 4
fibonacci_hash_3_bits(10) == 1
fibonacci_hash_3_bits(11) == 6
fibonacci_hash_3_bits(12) == 3
fibonacci_hash_3_bits(13) == 0
fibonacci_hash_3_bits(14) == 5
fibonacci_hash_3_bits(15) == 2
fibonacci_hash_3_bits(16) == 7
这给出了一个很好地均匀分布:数字 0 出现了三次,所有其他的数字出现了两次。而且每个数字都离上一个和下一个数字很远。如果我们将输入增加一,输出会跳跃很多。所以这开始看起来像一个好的哈希函数。同样是一个把一个大范围的数字映射到0到7的范围的好方法。
事实上,我们在这里已经有了整个算法。为了得到二的任意次方范围,所有我们需要做的就是改变偏移的量。所以如果我的哈希表的大小是 1024,那么我们不想只看上面 3 个位,我们想看上面 10 个位。所以我偏移 54,而不是 61。足够简单了。
现在,如果你真的运行一个完整的哈希函数分析在这个上面,你会发现它不是一个很好的哈希函数。它不是糟透了,但是你会快速地发现模式。但是如果我们创建一个具有 STL 风格接口的哈希表,无论如何我们都不能控制哈希函数。哈希函数由用户提供。因此,我们将仅使用 Fibonacci Hashing 将哈希函数的结果映射到我们想要的范围。
整数取模的问题
那么,为什么整数取模无论如何都很糟糕?两个原因:1. 它很慢。2. 它可能对输入数据中的模式真的很愚蠢。因此,首先整数取模有多慢?如果你只是做一个像这样的直接实现:
size_t hash_to_slot(size_t hash, size_t num_slots)
{
return hash % num_slots;
}
那么这真的很慢。在我的机器上大约需要 9 纳秒。如果哈希表在缓存中,这大约比查找的其余部分花费的时间长五倍。如果你遇到缓存未命中,那么这些会占主导地位,但是整数取模使我们的查找在表在缓存中时慢几倍是不好的。尽管如此,GCC、LLVM 和 Boost 的 unordered_map 实现都使用此代码将哈希值映射到表中的一个槽。而且它们因此变得非常慢。Dinkumware 实现稍微聪明一点:它利用了当表的大小设置为二的幂时,你可以通过使用二进制与来执行整数取模的事实:
size_t hash_to_slot(size_t hash, size_t num_slots_minus_one)
{
return hash & num_slots_minus_one;
}
在我的机器上大约需要 0 纳秒。由于 num_slots 是二的幂,这只会截断所有上面的位,并且仅保留下面的位。因此,为了使用这个,你必须确保所有重要的信息都在下面的位中。Dinkumware 通过使用比其他实现更复杂的哈希函数来确保这一点:对于整数,它使用 FNV1 哈希。它比整数取模快得多,但由于 FNV1 很昂贵,它仍然使你的哈希表比它可能的速度慢两倍。并且存在一个更大的问题:如果你提供你自己的哈希函数,因为你想将自定义类型插入到哈希表中,你必须知道这个实现细节。
我们在工作中已被这个实现细节困扰了好几次。例如,我们有一个自定义 ID 类型,它只是一个 64 位整数的包装器,它由多个信息来源组成。并且它只是碰巧该 ID 类型在上面的位中具有非常重要的信息。令人惊讶的是,有人花了很长时间才注意到我们的代码库中有一个慢速哈希表,只需更改哈希函数中位的顺序就可以使它的速度提高一百倍,因为整数取模会截断上面的位。
其他表,例如 google::dense_hash_map 也使用二的幂哈希大小来获得快速整数取模,但是它没有提供它自己的 std::hash<int> 实现(因为它不能),因此当使用 dense_hash_map 时,你必须对你的上面的位非常小心。
谈到 google::dense_hash_map,整数取模为其开放寻址表带来了更多问题。因为如果你将所有数据存储在一个数组中,输入数据中的模式突然开始变得更加重要。例如,如果你插入大量连续的数字,google::dense_hash_map 会变得非常非常慢。因为所有这些连续的数字都被分配了彼此相邻的槽,并且如果你随后尝试查找表中不存在的键,你必须探测通过许多密集占据的槽,然后才能找到你的第一个空槽。如果你只查找实际在映射中的键,你永远不会注意到这一点,但是不成功的查找可能比它们应该的速度慢几十倍。
尽管存在这些缺陷,但所有最快的哈希表实现都使用“二进制与”方法来将哈希值分配给槽。然后你通常尝试通过使用更复杂的哈希函数来弥补这些问题,例如 Dinkumware 实现中的 FNV1。
为什么 Fibonacci Hashing 是解决方案
Fibonacci Hashing 解决了这两个问题。1. 它真的很快。它是一个整数乘法,然后是一个移位。在我的机器上大约需要 1.5 纳秒,这足够快,以至于很难测量。2. 它混合了输入模式。这就像你从第一个哈希函数完成之后免费获得第二个哈希步骤。如果第一个哈希函数实际上只是恒等函数(对于整数应该是这样),那么这至少会为你提供一些你原本不会得到的混合。
但实际上它更好,因为它更快。当我在哈希表上工作时,我总是对我们在“将大数映射到小数”这个简单问题上花费了多少时间感到沮丧。它实际上是哈希表中最慢的操作。(当然,除了缓存未命中之外,但让我们假装你正在连续进行几次查找并且表已缓存)唯一的替代方法是“二的幂二进制与”版本,它丢弃哈希函数中的位,并且如果你不小心,可能会导致各种问题。所以你的选择要么是慢而安全,要么是快而丢失位,并且如果你不小心,可能会得到很多哈希冲突。每个人都有这个问题。我用 Google 搜索了很多这个问题,想着“肯定有人必须有一种很好的方法将一个大数带入一个小范围”,但是每个人要么做慢的事情,要么做坏的事情。例如,这里 是一种方法(称为“fastrange”),它几乎重新发明了 Fibonacci Hashing,但是它夸大了 Fibonacci Hashing 打破模式的模式。它的速度与 Fibonacci Hashing 相同,但是当我尝试使用它时,它对我不起作用,因为我突然发现我的哈希函数中存在我甚至没有意识到的模式。(并且使用 fastrange,你的微妙模式突然被夸大为巨大的问题)尽管存在问题,但它仍被用于 Tensorflow 中,因为每个人都迫切需要更快地解决将大数映射到小范围的问题。
如果 Fibonacci Hashing 如此出色,为什么没有人使用它?
这是一个棘手的问题,因为互联网上关于 Fibonacci Hashing 的信息很少,但我认为这与历史误解有关。在《计算机程序设计艺术》中,Knuth 介绍了三个用于哈希表的哈希函数:
- 整数取模
- Fibonacci Hashing
- 与 CRC 哈希有关的东西
从今天的角度来看,将整数取模包含在此列表中有点奇怪,因为它不是一个哈希函数。它只是从一个较大的范围映射到一个较小的范围,并且没有做其他任何事情。Fibonacci Hashing 实际上是一个哈希函数,不是最好的哈希函数,但这是一个很好的介绍。第三个对我来说太复杂了,无法理解。这是关于为 CRC 哈希提出好的系数,这些系数具有关于避免哈希表中冲突的某些属性。可能非常聪明,但其他人必须弄清楚这一点。
所以这里发生的事情是 Knuth 使用“哈希函数”这个术语的方式与我们今天使用它的方式不同。今天,哈希表中的步骤类似于这样:
- 哈希键
- 将哈希值映射到一个槽
- 比较槽中的项目
- 如果它不是正确的项目,使用不同的项目重复步骤 3,直到找到正确的项目或满足某些结束条件
我们使用“哈希函数”这个术语来指代步骤 1。但 Knuth 使用“哈希函数”这个术语来指代同时执行步骤 1 和步骤 2 的东西。因此,当他提到哈希函数时,他的意思是同时哈希传入的键,并将其分配给表中的一个槽。因此,如果表只有 1024 个项目大,哈希函数只能返回值从 0 到 1023。这解释了为什么“整数取模”对 Knuth 来说是一个哈希函数:它在步骤 1 中什么都不做,但它在步骤 2 中工作得很好。所以如果这两个步骤只是一个步骤,那么整数取模在这个步骤中做得很好,因为它在我们的步骤 2 中做得很好。但是当我们像那样将它分开时,我们会看到 Fibonacci Hashing 在这两个步骤中都比整数取模有所改进。并且因为我们只将它用于步骤 2,所以它允许我们对步骤 1 使用更快的实现,因为哈希函数从 Fibonacci Hashing 所做的额外混合中获得了一些帮助。
但是这种术语上的差异,即 Knuth 使用“哈希函数”来表示与 std::unordered_map 中的“哈希函数”不同的东西,向我解释了为什么没有人使用 Fibonacci Hashing。当被判断为今天意义上的“哈希函数”时,它不是那么好。
在我发现 Fibonacci Hashing 在任何地方都没有被提及之后,我做了更多的 Google 搜索,并且在搜索“乘法哈希”时更成功。Fibonacci Hashing 只是一个简单的乘法哈希,带有一个精心挑选的魔法数字。但是我发现的描述乘法哈希的语言解释了为什么没有人使用它。例如,Wikipedia 对乘法哈希有这样的说法:
乘法哈希是一种简单的哈希函数,通常被教师用来向学生介绍哈希表。乘法哈希函数简单快速,但在哈希表中的冲突率高于更复杂的哈希函数。
因此,仅仅从这一点来看,我当然不会受到鼓励去查看这个“乘法哈希”是什么。或者为了了解教师是如何介绍它的,这里 是 MIT 讲师 Erik Demaine(我非常推荐他的视频)介绍哈希函数,他说:
我将给你三个哈希函数。其中两个是,我们假设是常见的做法,第三个实际上在理论上是好的。所以前两个在理论上是不好的,你可以证明它们是不好的,但至少它们会给你一些味道。
然后他谈到了整数取模、乘法哈希以及两者的组合。他没有提及乘法哈希的 Fibonacci Hashing 版本,并且这个介绍可能不会激发人们去寻找更多关于它的信息。
所以我认为人们只是了解到乘法哈希不是一个好的哈希函数,并且他们永远不会了解到乘法哈希是将大值映射到小范围的好方法。
当然,也可能是我错过了 Fibonacci Hashing 一些未知的重大缺点,并且有充分的理由说明为什么没有人使用它,但是我没有找到任何这样的东西。但可能我没有找到任何关于 Fibonacci Hashing 的坏处,仅仅是因为很难找到任何关于 Fibonacci Hashing 的信息,所以让我们做我们自己的分析:
分析 Fibonacci Hashing
所以我不得不承认,我对分析哈希函数知之甚少。似乎最好的测试是查看哈希函数与严格雪崩标准有多接近,后者“如果每当单个输入位发生变化时,每个输出位都以 50% 的概率发生变化,则满足该标准”。
为了测量这一点,我写了一个小程序,该程序接受哈希 


然后,每次我将哈希表加倍后,我都会运行相同的测试,因为使用不同大小的哈希表,输出中会有更多的位:如果哈希表只有四个槽,则输出中只有两个位。如果哈希表有 1024 个槽,则输出中有十个位。最后,我为结果着色并绘制整个内容,使其看起来像这样:

让我解释一下这张图片。每个像素行代表输入哈希的 64 位中的一位。最底行是第一位,最顶行是第 64 位。每列代表输出中的一个位。前两列是大小为 4 的表的输出位,接下来的三列是大小为 8 的表的输出位,依此类推,直到最后 23 位是大小为 800 万的表的输出位。颜色编码意味着:
- 黑色像素表示当该行的输入像素发生变化时,该列的输出像素有 50% 的几率发生变化。(这是理想的)
- 蓝色像素表示当输入像素发生变化时,输出像素有 100% 的几率发生变化。
- 红色像素表示当输入像素发生变化时,输出像素有 0% 的几率发生变化。
对于一个真正好的哈希函数,整张图片都是黑色的。所以 Fibonacci Hashing 不是一个真正好的哈希函数。
我们可以看到的最糟糕的模式是在图片顶部:输入哈希的最后一位(图片中最顶行)始终只能影响表中输出槽的最后一位。(每个部分的最后一列)因此,如果该表有 1024 个槽,则输入哈希的最后一位只能确定数字 512 的输出槽中的位。它永远不会更改输出中的任何其他位。输入中较低的位可以影响输出中更多的位,因此对于这些位,有更多的混合在进行。
输入中的最后一位只能影响输出中的一位,这不好吗?如果我们将此用作哈希函数,那将是不好的,但如果我们仅使用此函数从大范围映射到小范围,则不一定是不好的。由于每行至少有一个蓝色或黑色像素,我们可以确定我们没有丢失信息,因为将使用输入中的每一位。对于从大范围映射到小范围而言,如果某行或某列中只有红色像素,那将是不好的。
让我们也看看整数取模会是什么样子,从使用素数的整数取模开始:

这个在顶部具有更多的随机性,但是在底部具有更清晰的模式。所有这些红色表示输入哈希中的前几位只能确定输出哈希中的前几位。这对于整数取模是有意义的。一个小数取模一个大数永远不会产生一个大数,因此小数的更改永远不会影响后面的位。
对于从大范围映射到小范围而言,这张图片仍然是“好的”,因为我们在每个块中都有一条亮蓝色像素的对角线。为了展示一个糟糕的函数,这是一个大小为二的幂的整数取模:

这个显然很糟糕:哈希值的上面的位具有完全红色的行,因为它们将被简单地截断。只有输入中的较低位有任何影响,并且它们只能影响其自身在输出中的位。这张图片直接表明,使用二的幂大小要求你对哈希表哈希函数的选择要小心:如果那些红色的行代表重要的位,你将简单地丢失它们。
最后,让我们也看一下我上面简要提到的“fastrange”算法。对于二的幂大小,它看起来真的很糟糕,因此让我向你展示它对于素数大小看起来像什么:

我们在这里看到的是 fastrange 丢弃了输入范围的较低位。它仅使用上面的位。我之前已经使用过它,并且我注意到较低位的更改似乎没有产生太大的影响,但是我从未意识到它只是完全丢弃了较低位。这张图片完全解释了为什么我在 fastrange 中遇到了这么多问题。Fastrange 是从大范围映射到小范围的不良函数,因为它丢弃了较低位。
回到 Fibonacci Hashing,实际上你可以做一个简单的更改来改善顶部的坏模式:向下移动顶部的位并对它们进行一次异或。因此,代码更改为:
size_t index_for_hash(size_t hash)
{
hash ^= hash >> shift_amount;
return (11400714819323198485llu * hash) >> shift_amount;
}
它几乎看起来更像一个适当的哈希函数,不是吗?这使函数慢了两个周期,但是它为我们提供了以下图片:

这看起来更好一点,顶部的问题模式已经消失了。(并且我们现在看到了更多的黑色像素,这是哈希函数的理想选择)但我没有使用它,因为我们实际上并不需要一个好的哈希函数,我们需要一个好的函数来从大范围映射到小范围。并且这是哈希表的关键路径,在我们甚至可以进行第一次比较之前。在这里添加的任何周期都会使上面图中的整条线向上移动。
所以我一直在说我们需要一个好的函数来从大范围映射到小范围,但是我还没有定义“好”在那里意味着什么。我不知道像雪崩分析这样的用于哈希函数的适当测试,但是我对“好”的第一个定义尝试是较小范围内的每个值都同样有可能发生。不过,该测试非常容易实现:所有方法(包括 fastrange)都满足该标准。那么,我们如何选择输入范围中的一系列值,并检查输出中的每个值是否同样可能?我上面给出了数字 0 到 16 的示例。我们也可以做 8 的倍数或所有 2 的幂或所有素数或 Fibonacci 数。或者让我们尝试尽可能多的序列,直到我们弄清楚函数的行为。
查看上面的列表,我们看到 4 的倍数可能存在一个有问题的模式:fibonacci_hash_3_bits(4) 返回 3,fibonacci_hash_3_bits(8) 返回 7,fibonacci_hash_3_bits(12) 再次返回 3,fibonacci_hash_3_bits(16) 再次返回 7。让我们看看,如果我们将前十六个 4 的倍数打印出来,它是如何发展的:
这里是结果:
0 -> 0
4 -> 3
8 -> 7
12 -> 3
16 -> 7
20 -> 2
24 -> 6
28 -> 2
32 -> 6
36 -> 1
40 -> 5
44 -> 1
48 -> 5
52 -> 1
56 -> 4
60 -> 0
64 -> 4
实际上看起来不太糟糕:每个数字出现两次,除了数字 1 出现三次。那么 8 的倍数呢?
0 -> 0
8 -> 7
16 -> 7
24 -> 6
32 -> 6
40 -> 5
48 -> 5
56 -> 4
64 -> 4
72 -> 3
80 -> 3
88 -> 3
96 -> 2
104 -> 2
112 -> 1
120 -> 1
128 -> 0
再一次看起来不太糟糕,但是我们肯定会得到更多重复的数字。那么 16 的倍数呢?
0 -> 0
16 -> 7
32 -> 6
48 -> 5
64 -> 4
80 -> 3
96 -> 2
112 -> 1
128 -> 0
144 -> 7
160 -> 7
176 -> 6
192 -> 5
208 -> 4
224 -> 3
240 -> 2
256 -> 1
这看起来又好了一点,并且如果我们要查看 32 的倍数,它会看起来更好。数字 8 开始看起来有问题的原因不是因为它是一个 2 的幂。它开始看起来有问题是因为它是一个 Fibonacci 数。如果我们查看后面的 Fibonacci 数,我们会看到更多有问题的模式。例如,这里是 34 的倍数:
0 -> 0
34 -> 0
68 -> 0
102 -> 0
136 -> 0
170 -> 0
204 -> 0
238 -> 0
272 -> 0
306 -> 0
340 -> 1
374 -> 1
408 -> 1
442 -> 1
476 -> 1
510 -> 1
544 -> 1
这看起来很糟糕。并且后面的 Fibonacci 数只会看起来更糟。但是再一次,你多久会插入 34 的倍数到哈希表中呢?事实上,如果你必须选择一组会给你带来问题的数字,Fibonacci 数不是最糟糕的选择,因为它们不会自然地出现那么多。作为提醒,这里是前几个 Fibonacci 数:1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584... 前几个数字不会给我们带来不好的输出模式,但是任何大于 13 的数字都会。并且其中的大多数都是相当无害的:我无法想到任何会给出这些数字的倍数的情况。144 有点困扰我,因为它是一个