查询引擎:推(Push) vs. 拉(Pull)模式 (2021)
Justin Jaffray
查询引擎:推(Push) vs. 拉(Pull)模式
2021年4月26日
人们经常谈论基于“拉(pull)”与“推(push)”的查询引擎,从字面上理解其含义相当简单,但有些细节可能比较难搞清楚。
从 Snowflake 的 Sigmod 论文 中的这段话来看,重要人士显然对这种区别进行了深入思考:
基于推(Push-based)的执行指的是,关系操作符将其结果推送到下游操作符,而不是等待这些操作符拉取数据(经典的 Volcano 风格模型)。基于推的执行提高了缓存效率,因为它从紧密循环中移除了控制流逻辑。它还使 Snowflake 能够有效地处理 DAG 形状的计划,而不仅仅是树,从而为中间结果的共享和流水线创建了更多机会。
然而,这就是他们在这个问题上所说的全部。这给我留下了两个主要的未解之谜:
- 为什么基于推的系统能够以拉(pull)模式不支持的方式“有效地处理 DAG 形状的计划”,以及谁关心这个?(DAG 代表有向无环图。)
- 为什么这能提高缓存效率,以及“从紧密循环中移除控制流逻辑”意味着什么?
在这篇文章中,我们将讨论基于拉(pull)和基于推(push)的查询引擎工作方式之间的一些理念上的差异,然后讨论在实践中为什么你可能更喜欢其中一个,并以我们试图回答的这些问题作为指导。
考虑以下 SQL 查询:
SELECT DISTINCT customer_first_name FROM customer WHERE customer_balance > 0
查询规划器通常会将像这样的 SQL 查询编译成一系列离散的操作符:
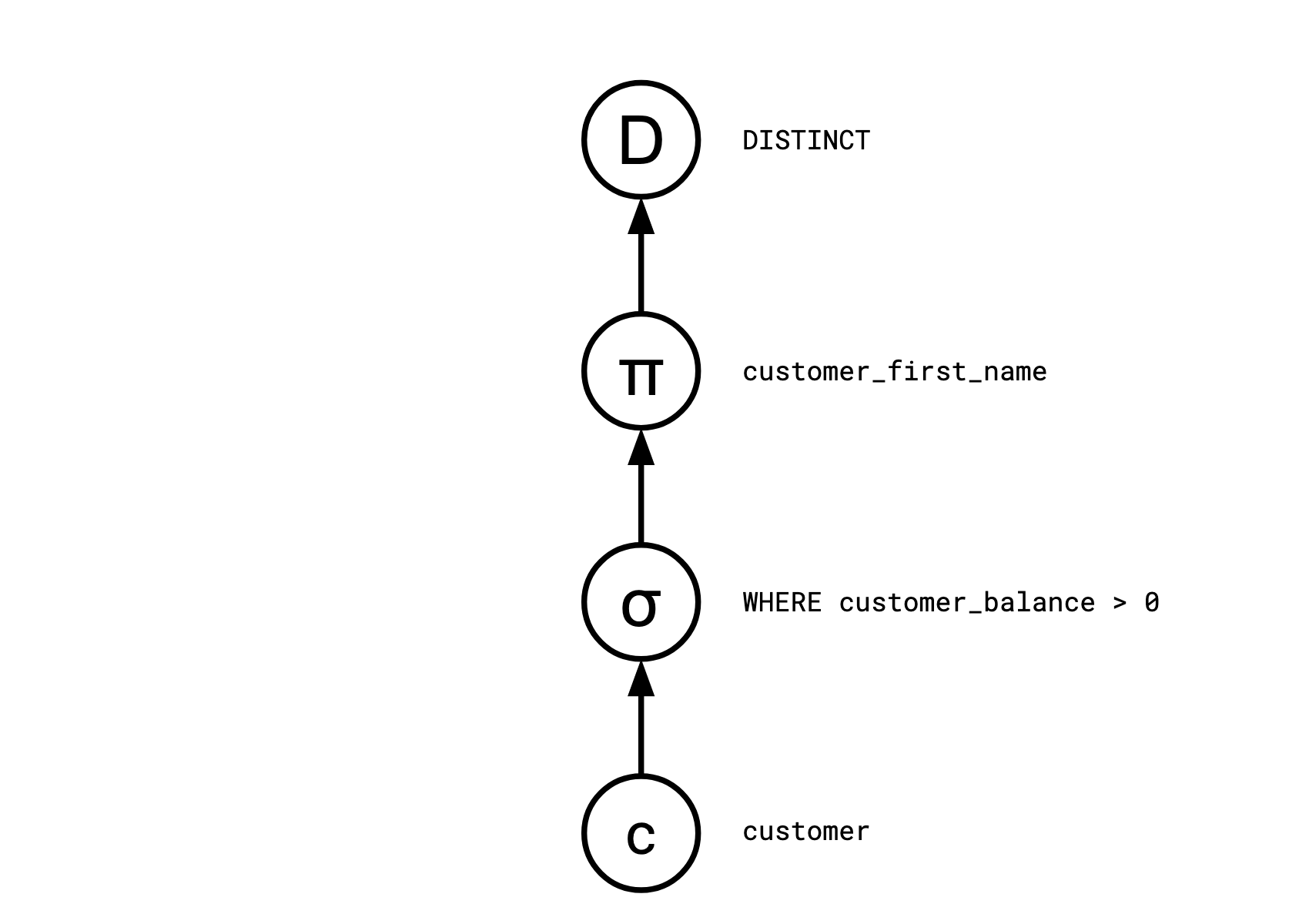
Distinct
<- Map(customer_first_name)
<- Select(customer_balance > 0)
<- customer
在*基于拉(pull)*的系统中,消费者驱动整个系统。每个操作符在被请求时生成一行:用户将向根节点 (Distinct) 请求一行,该节点将向 Map 请求一行,Map 将向 Select 请求一行,依此类推。
在基于推(push)的系统中,生产者驱动整个系统。每个操作符在拥有一些数据时,会将其告知下游操作符。customer 作为此查询中的基本表,将把其所有行告知 Select,这将导致其把它的行告知 Map,依此类推。
让我们从构建每种查询引擎的一个超简单实现开始。
一个基本的基于拉(pull)的查询引擎
基于拉(pull)的查询引擎通常也被称为使用 Volcano 或 Iterator 模型。这是最古老和最广为人知的查询执行模型,并以一篇在 1994 年 将其约定标准化的论文命名。
首先,我们将从一个关系和一个将其转换为 iterator 的方法开始:
let customer = [
{ id: 1, firstName: "justin", balance: 10 },
{ id: 2, firstName: "sissel", balance: 0 },
{ id: 3, firstName: "justin", balance: -3 },
{ id: 4, firstName: "smudge", balance: 2 },
{ id: 5, firstName: "smudge", balance: 0 },
];
function* Scan(coll) {
for (let x of coll) {
yield x;
}
}
一旦我们有了 iterator,我们就可以反复地向其请求 next 元素。
let iterator = Scan(customer);
console.log(iterator.next());
console.log(iterator.next());
console.log(iterator.next());
console.log(iterator.next());
console.log(iterator.next());
console.log(iterator.next());
这会输出:
{ value: { id: 1, firstName: 'justin', balance: 10 }, done: false }
{ value: { id: 2, firstName: 'sissel', balance: 0 }, done: false }
{ value: { id: 3, firstName: 'justin', balance: -3 }, done: false }
{ value: { id: 4, firstName: 'smudge', balance: 2 }, done: false }
{ value: { id: 5, firstName: 'smudge', balance: 0 }, done: false }
{ value: undefined, done: true }
然后,我们可以创建一些操作符来将 iterator 转换为另一种形式。
function* Select(p, iter) {
for (let x of iter) {
if (p(x)) {
yield x;
}
}
}
function* Map(f, iter) {
for (let x of iter) {
yield f(x);
}
}
function* Distinct(iter) {
let seen = new Set();
for (let x of iter) {
if (!seen.has(x)) {
yield x;
seen.add(x);
yield x;
}
}
}
然后,我们可以将原始查询:
SELECT DISTINCT customer_first_name FROM customer WHERE customer_balance > 0
转换为:
console.log([
...Distinct(
Map(
(c) => c.firstName,
Select((c) => c.balance > 0, Scan(customer))
)
),
]);
它会按预期输出:
[ 'justin', 'smudge' ]
一个基本的基于推(push)的查询引擎
基于推(push)的查询引擎,有时被称为 Reactive,Observer,Stream 或 callback hell 模型,正如你可能期望的那样,就像我们之前的例子,但完全相反。
让我们从定义一个合适的 Scan 操作符开始。
let customer = [
{ id: 1, firstName: "justin", balance: 10 },
{ id: 2, firstName: "sissel", balance: 0 },
{ id: 3, firstName: "justin", balance: -3 },
{ id: 4, firstName: "smudge", balance: 2 },
{ id: 5, firstName: "smudge", balance: 0 },
];
function Scan(relation, out) {
for (r of relation) {
out(r);
}
}
我们将“此操作符告知下游操作符”建模为一个它调用的闭包。
Scan(customer, (r) => console.log("row:", r));
它会输出:
row: { id: 1, firstName: 'justin', balance: 10 }
row: { id: 2, firstName: 'sissel', balance: 0 }
row: { id: 3, firstName: 'justin', balance: -3 }
row: { id: 4, firstName: 'smudge', balance: 2 }
row: { id: 5, firstName: 'smudge', balance: 0 }
我们可以类似地定义其余的操作符:
function Select(p, out) {
return (x) => {
if (p(x)) out(x);
};
}
function Map(f, out) {
return (x) => {
out(f(x));
};
}
function Distinct(out) {
let seen = new Set();
return (x) => {
if (!seen.has(x)) {
seen.add(x);
out(x);
}
};
}
现在我们的查询可以这样编写:
let result = [];
Scan(
customer,
Select(
(c) => c.balance > 0,
Map(
(c) => c.firstName,
Distinct((r) => result.push(r))
)
)
);
console.log(result);
按预期输出:
[ 'justin', 'smudge' ]
比较
在基于拉(pull)的系统中,操作符会处于空闲状态,直到有人向它们请求一行。这意味着从系统中获取结果的方式很明显:你向它请求一行,它就会给你。然而,这也意味着系统的行为与它的消费者紧密相关;你只在被要求时才执行工作,否则就不执行。
在基于推(push)的系统中,系统会处于空闲状态,直到有人告知它一行。因此,系统正在进行的工作与其消费是解耦的。
你可能已经注意到,与我们基于拉(pull)的系统相比,在我们上面的基于推(push)的系统中,我们必须进行一种奇怪的操作,创建一个缓冲区 (result),我们指示查询将其结果推入其中。这就是基于推(push)的系统给人的感觉,它们的存在与它们指定的消费者无关,它们只是存在,当事情发生时,它们会做出响应。
DAG,哟
让我们回到我们的第一个主要问题:
为什么基于推(push)的系统能够以拉(pull)模式不支持的方式“有效地处理 DAG 形状的计划”,以及谁关心这个?
“DAG 形状的计划”指的是将其数据输出到多个下游操作符的操作符。事实证明,这比听起来更有用,即使在 SQL 的上下文中,我们通常认为 SQL 本质上是树状结构的。
SQL 有一个名为 WITH 的构造,允许用户在查询中多次引用一个结果集。这意味着以下查询是有效的 SQL:
WITH foo AS (<some complex query>)
SELECT *
FROM (SELECT * FROM foo WHERE c) AS foo1
JOIN foo AS foo2 ON foo1.a = foo2.b
它有一个查询计划,看起来像这样:
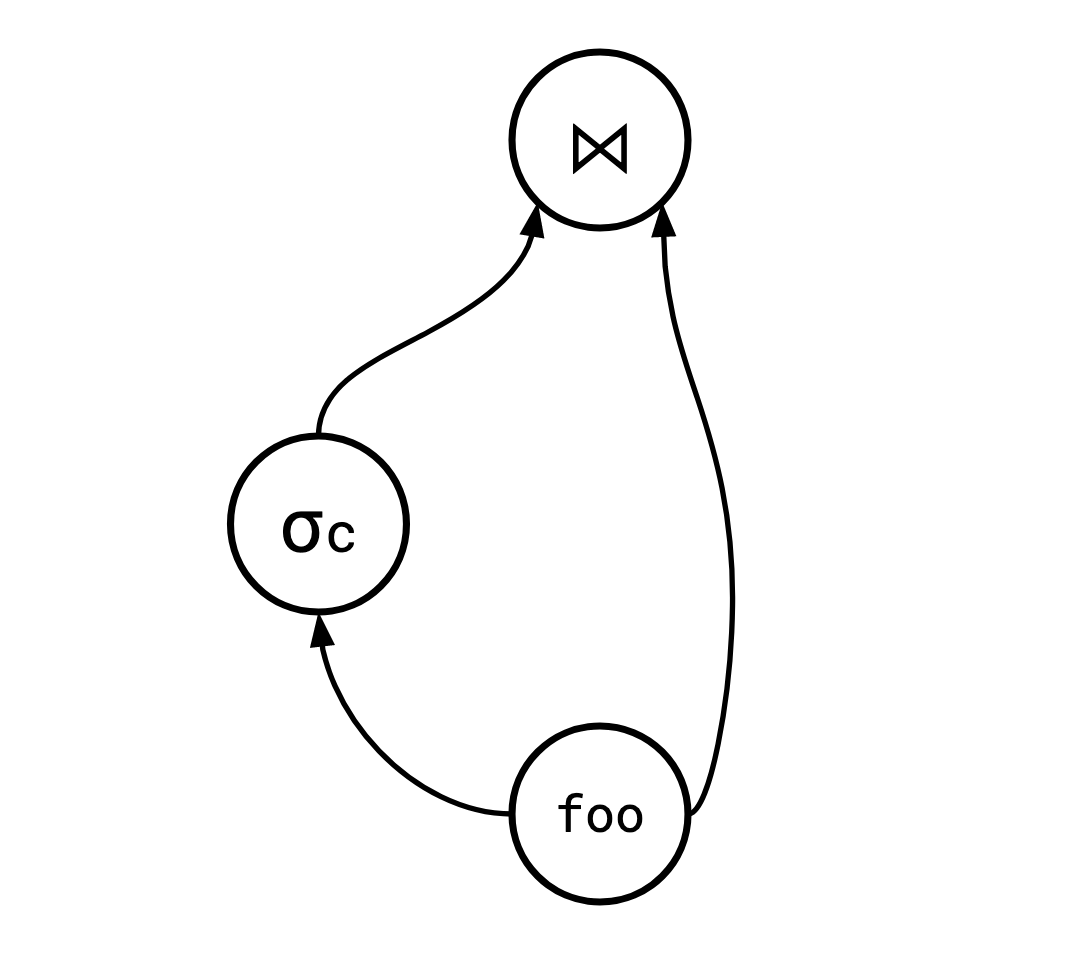
除了这个明确的例子之外,一个聪明的查询规划器通常可以利用 DAG 性来重用结果。例如,Jamie Brandon 有一篇文章 描述了一种在 SQL 中取消相关子查询的通用方法,该方法广泛使用 DAG 查询计划以提高效率。因此,能够处理这些情况而不只是复制计划树的一个分支是很有价值的。
在拉(pull)模式中,有两件事使得这很难:调度和生命周期。
调度
在每个操作符只有一个输出的情况下,何时运行操作符以生成一些输出是很明显的:当你的消费者需要它时。这在多个输出的情况下至少会变得更加混乱,因为“请求行”和“计算以生成行”不再是一对一的。
相比之下,在基于推(push)的系统中,操作符的调度从一开始就没有与它们的输出相关联,因此丢失该信息没有任何影响。
生命周期
在拉(pull)模式中,DAG 的另一个棘手之处在于,这种系统中的操作符受其下游操作符的支配:任何可能在未来被其任何消费者读取的行都必须保留(或者必须能够重新计算)。一种通用的解决方案是让操作符缓冲所有输出的行,以便你可以重新分发它们,但是在每个操作符边界引入潜在的无限制缓冲是不希望的(但对于具有多个消费者的 WITH 来说,这是 Postgres 和 CockroachDB 必须要做的事情)。
这在基于推(push)的系统中不是一个大问题,因为操作符现在驱动着它们的消费者处理行的时间,它们可以有效地强制它们获取行的所有权并处理它。在大多数情况下,这将导致某种必要的缓冲,即使在没有 DAG 的情况下也需要(例如,对于 Distinct 或哈希连接操作),或者只是立即处理并传递。
缓存效率
现在让我们来谈谈第二个问题。
为什么这能提高缓存效率,以及“从紧密循环中移除控制流逻辑”意味着什么?
首先,Snowflake 的论文引用了 Thomas Neumann 的一篇论文 来支持这一说法。我真的不认为这篇论文孤立地支持这个说法,如果我必须总结这篇论文,它更像是,“我们希望将查询编译成机器代码以提高缓存效率,并且为此目的,基于推(push)的范例是更可取的。” 这篇论文非常有趣,我建议你阅读它,但在我看来,除非你从想要使用像 LLVM 这样的东西编译你的查询的立场出发(从一些粗略的研究来看,我不清楚 Snowflake 是否这样做),否则它的结论并不真正适用。
在为本节进行研究时,我发现了 Shaikha, Dashti 和 Koch 的这篇论文,它很好地强调了每种模型的一些优点和缺点。事实上,他们引用了 Neumann 的论文:
最近,提出了一种操作符链模型,它分享了避免中间结果物化的优点,但它颠倒了控制流;元组从源关系向前推送到生成最终结果的操作符。最近的论文似乎表明,这种推(push)模型始终比拉(pull)模型带来更好的查询处理性能,即使没有提供直接、公平的比较。
本文的主要贡献之一是揭穿了这种神话。正如我们所展示的,如果进行公平的比较,基于推(push)和基于拉(pull)的引擎具有非常相似的性能,具有各自的优势和劣势,并且没有明确的赢家。本质上,推(push)引擎只在查询编译的上下文中被考虑过,混淆了推(push)范例的潜在优势与代码内联的潜在优势。为了公平地比较它们,必须将这些方面解耦。
他们的结论是,这里没有明显的赢家,但观察到编译基于推(push)的查询会产生更简单的代码。主要的想法是,将同步的、基于推(push)的查询展开成你手写的等效代码实际上非常容易。以我们之前的查询为例:
let result = [];
Scan(
customer,
Select(
(c) => c.balance > 0,
Map(
(c) => c.firstName,
Distinct((r) => result.push(r))
)
)
);
console.log(result);
这很自然地展开为:
let result = [];
let seen = new Set();
for (let c of customer) {
if (c.balance > 0) {
if (!seen.has(c.firstName)) {
seen.add(c.firstName);
result.push(c.firstName);
}
}
}
console.log(result);
如果你尝试展开等效的基于拉(pull)的查询,你会发现生成的代码不太自然。
我认为很难得出关于哪个“更好”的任何真正结论,我认为最明智的做法是根据任何特定查询引擎的需求做出选择。
考虑事项
阻抗失配
这些系统可能出现的一个问题是边界处的失配。从拉(pull)系统到推(push)系统的边界需要轮询其状态,而从推(push)系统到拉(pull)系统的边界需要物化其状态。这些都不是决定性因素,但都会产生一些成本。
这就是为什么在像 Flink 或 Materialize 这样的流式系统中,你通常会看到使用基于推(push)的系统:这种系统的输入本质上是基于推(push)的,因为你在监听传入的 Kafka 流或类似的东西。
在流式设置中,如果你希望你的最终消费者能够以基于拉(pull)的方式与系统进行交互(例如,在需要时针对它运行查询),则需要引入某种物化层,在该层中你从结果构建索引。
相反,在不公开某种流式传输/尾部机制的系统中,如果你想知道何时某些数据发生了更改,你唯一的选择将是定期轮询它。
算法
有些算法根本不适合在推(push)系统中使用。正如 Shaikhha 论文中所讨论的:合并连接算法的工作原理从根本上基于以锁定步骤遍历两个 iterator 的能力,这在消费者几乎没有控制权的推(push)系统中是不切实际的。
类似地,LIMIT 操作符在推(push)模型中可能会出现问题。在没有引入双向通信或将 LIMIT 融合到底层操作符(这并非总是可行)的情况下,生成操作符无法知道一旦它们的消费者满足了,它们就可以停止工作。在拉(pull)系统中,这不是问题,因为消费者可以在不需要更多结果时停止请求更多结果。
循环
在不详细介绍的情况下,在这两种模型中拥有不仅是 DAG,而且是完整的循环图是非平凡的,但解决此问题的最著名的系统是 Naiad, a Timely Dataflow System,其现代版本是 Timely Dataflow。这两个系统都是推(push)系统,并且与 DAG 一样,许多事情在这种推(push)模型中效果更好。
结论
绝大多数入门级数据库资料都侧重于 iterator 模型,但现代系统,尤其是分析系统,开始更多地探索推(push)模型。正如 Shaikhha 论文中所指出的,很难找到苹果对苹果的比较,因为迁移到推(push)模型的许多动机是希望将查询编译为较低级别的代码,并且由此带来的好处掩盖了结果。
尽管如此,存在一些定量差异,使每种模型都适合在不同的场景中使用,如果你对数据库感兴趣,那么大致了解它们的工作方式是值得的。将来,我想更详细地介绍这些系统的构造方式,并尝试揭示使它们能够工作的一些魔力。