AudioX:用于万物到音频生成的 Diffusion Transformer
AudioX:用于万物到音频生成的 Diffusion Transformer
[Zeyue Tian](https://zeyuet.github.io/AudioX/<https:/scholar.google.com/citations?user=dghq4MQAAAAJ&hl=zh-CN&authuser=1&oi=ao >)1, [Yizhu Jin](https://zeyuet.github.io/AudioX/< >)1, Zhaoyang Liu1, Ruibin Yuan1, Xu Tan, Qifeng Chen1, Wei Xue1†, Yike Guo1† 1HKUST †通讯作者 arXiv Code 🤗 Model
摘要
音频和音乐生成已成为许多应用中的关键任务,但现有方法面临重大局限:它们在孤立状态下运行,缺乏跨模态的统一能力,高质量、多模态训练数据稀缺,并且难以有效地整合各种输入。在这项工作中,我们提出了 AudioX,一个统一的 Diffusion Transformer 模型,用于万物到音频和音乐生成。与之前特定领域的模型不同,AudioX 可以高质量地生成通用音频和音乐,同时提供灵活的自然语言控制以及对包括文本、视频、图像、音乐和音频在内的各种模态的无缝处理。其关键创新是一种多模态掩码训练策略,该策略掩盖跨模态的输入,并迫使模型从被掩盖的输入中学习,从而产生强大而统一的跨模态表示。为了解决数据稀缺问题,我们整理了两个全面的数据集:vggsound-caps,包含基于 VGGSound 数据集的 19 万个音频标题;以及 V2M-caps,包含来自 V2M 数据集的 600 万个音乐标题。大量实验表明,AudioX 不仅匹配或优于最先进的专用模型,而且在统一架构中提供了处理各种输入模态和生成任务的卓越多功能性。
演示视频
文本到音频生成
提示: 雷雨中的悲伤钢琴独奏 提示: 在键盘上打字 提示: 海浪拍打 点击这里查看更多示例 提示: 一个人在打鼾 提示: 马桶冲水 提示: 雨落在屋顶上 提示: 飞机起飞 提示: 爆炸和噼啪声 提示: 婴儿在哭 提示: 雪地里的脚步声 提示: 猫不停地喵喵叫 提示: 食物和油滋滋作响
文本到音乐生成
提示: 管弦乐,史诗,带有鼓、弦乐和铜管乐器 提示: 带有合成器、贝斯、鼓和缓慢渐进的电子舞曲 提示: 带有环境纹理和独奏大提琴的悲伤情感配乐 点击这里查看更多示例 提示: 鬼屋里令人紧张的场景 提示: 为幻想世界创作的管弦乐 提示: 用于旅行视频博客的令人振奋的尤克里里琴曲 提示: 日落场景的浪漫原声吉他音乐 提示: 带有柔和节奏的流畅都市 R&B 节拍 提示: 为舞会制作欢快的电子音乐 提示: 为复古平台游戏创作有趣的 8-bit chiptune 音乐 提示: 深空环境中的环境合成器音乐
视频到音频生成
点击这里查看更多示例
视频到音乐生成
点击这里查看更多示例
预告片
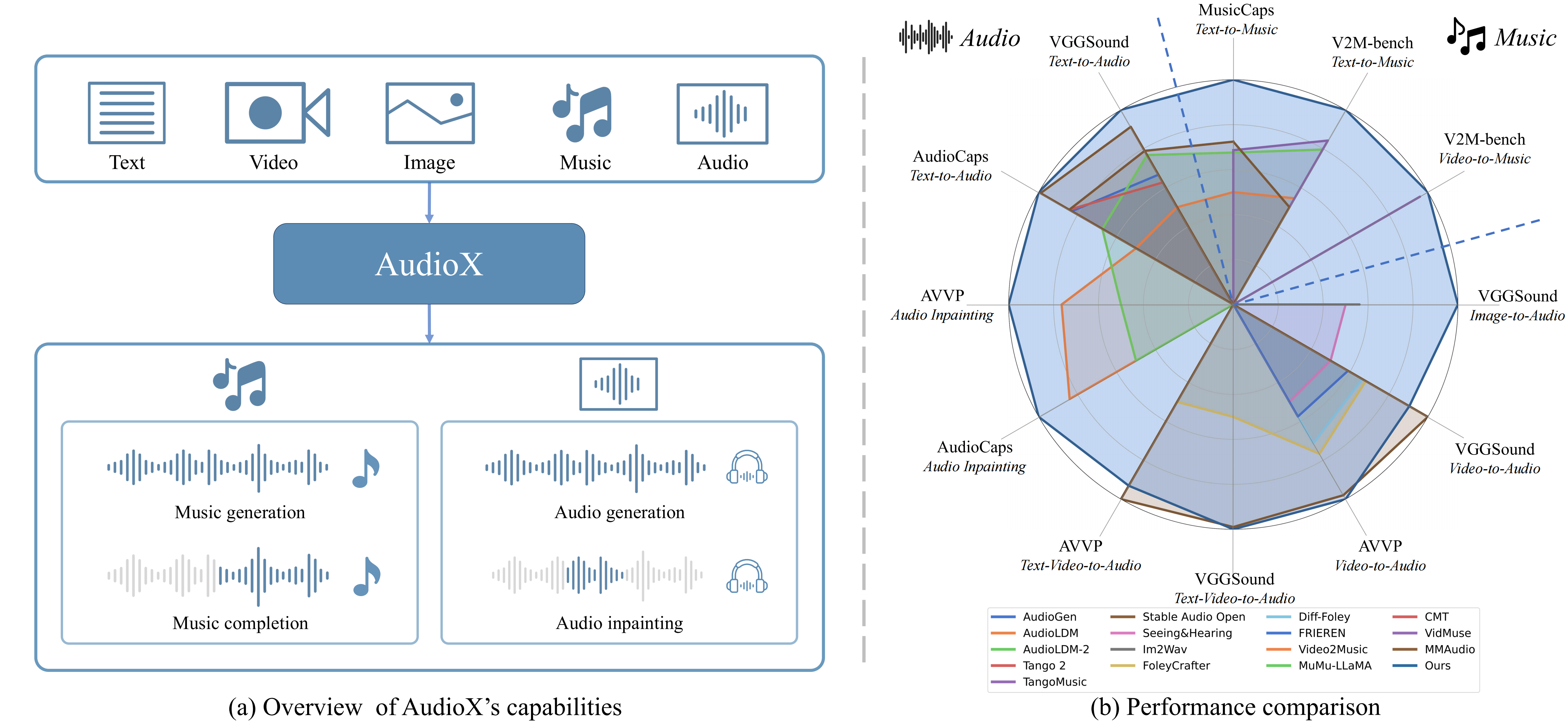 (a) AudioX 概述,展示了其在各种任务中的能力。(b) 雷达图比较了不同方法在多个基准测试中的性能。AudioX 在音频和音乐生成任务中,在一系列不同的数据集中表现出卓越的 Inception Scores (IS)。
(a) AudioX 概述,展示了其在各种任务中的能力。(b) 雷达图比较了不同方法在多个基准测试中的性能。AudioX 在音频和音乐生成任务中,在一系列不同的数据集中表现出卓越的 Inception Scores (IS)。
方法
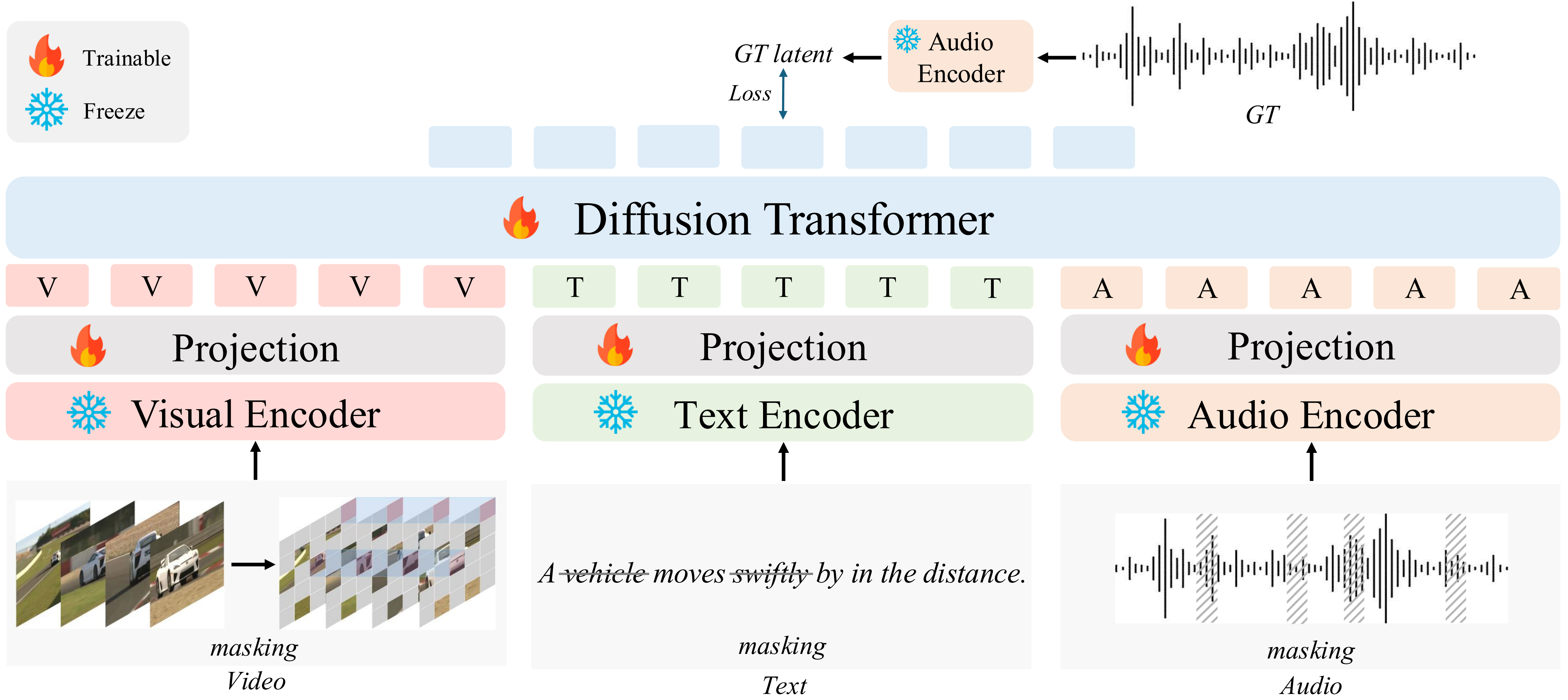 AudioX 框架。
AudioX 框架。
BibTeX
如果您觉得我们的工作有用,请考虑引用:
@article{tian2025audiox,
title={AudioX: Diffusion Transformer for Anything-to-Audio Generation},
author={Tian, Zeyue and Jin, Yizhu and Liu, Zhaoyang and Yuan, Ruibin and Tan, Xu and Chen, Qifeng and Xue, Wei and Guo, Yike},
journal={arXiv preprint arXiv:2503.10522},
year={2025}
}