被爬取的代价:LLM Bots 与 Vercel Image API 的定价
LLM Bots + Next.js 图片优化 = 破产的配方(事后分析)
一个可能让我们损失 7,000 美元的错误配置
 Ilya Bezdelev
Published on February 10, 2025
Ilya Bezdelev
Published on February 10, 2025
目录
- TL;DR
- Context
- How we discovered the problem 1. Step 1: A cost spike 2. Step 2: Image Optimization API usage spike 3. Step 3: Tens of thousands of requests from LLM bots
- Mitigation 1. Step 1: Stop the bleeding 2. Step 2: Disable Image Optimization 3. Step 3: robots.txt
- How do we prevent this in the future? 1. Continue with a sensitive spend limit 2. Mindset for scale 3. Ready for defense
- Social media response
- Parting thoughts
- UPD: Vercel changed their image optimization pricing
TL;DR
2025 年 2 月 7 日星期五,我们托管在 Vercel 上的 Next.js Web 应用发生了一起事件,如果我们没有及时发现,可能会损失 7,000 美元。
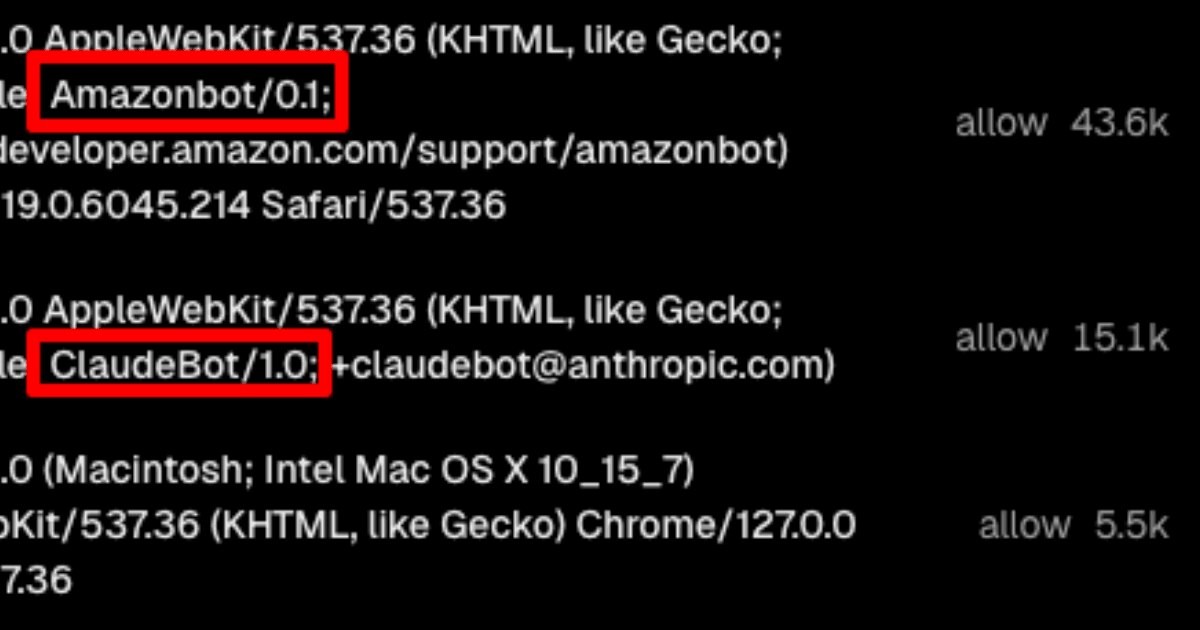
来自 Amazonbot、Claudebot、Meta 和一个未知 bot 的 LLM bot 流量激增。他们在一天之内向我们的网站发送了 66.5k 个请求。这些 bots 抓取了数千张使用 Vercel 的 Image Optimization API 的图片,这使我们花费了每 1k 张图片 5 美元。
我们这边的错误配置加上积极的 bot 流量,为我们这家小型自力更生的创业公司创造了一个经济上高风险的局面。
Context
Metacast 是一家播客技术创业公司。 我们的主要产品是适用于 iOS 和 Android 的 podcast app。
对于平台上每一个播客剧集,我们的 Web 应用都有一个网页。我们的平台有大约 140 万个剧集,这意味着我们有 140 万个网页可以被爬虫发现。这些页面在请求时在服务器端生成,然后被缓存。
How we discovered the problem
Step 1: A cost spike
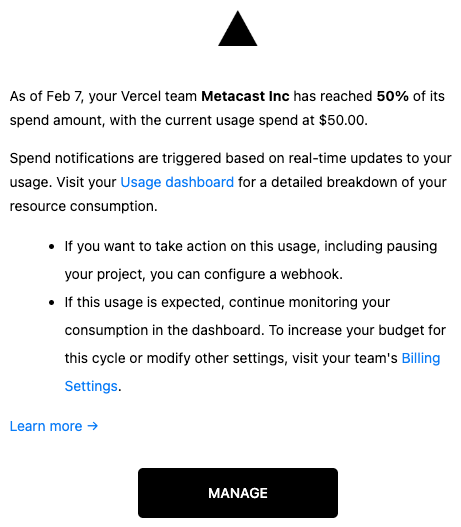
首先,我们收到了来自 Vercel 的成本警报,说我们已经达到了按使用量计费的资源的预算的 50%。
Step 2: Image Optimization API usage spike
我们对此进行了调查,发现它是由 Image Optimization API 驱动的,该 API 在 2 月 7 日达到峰值。
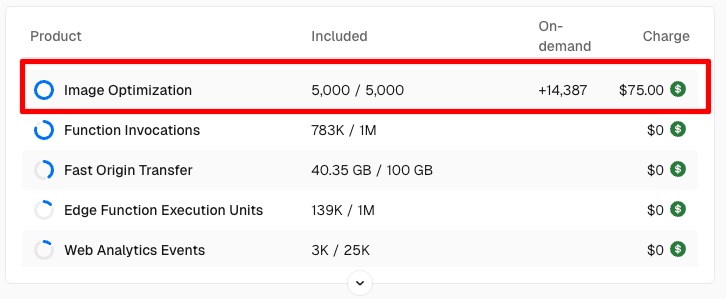

播客目录中的每个页面都包含一个播客封面图像(源图像尺寸为 3000x3000px)。通过 Image Optimization,播客封面被缩小到原来的 1/10,然后被缓存。Image Optimization 使 Web 应用非常流畅。它工作得非常好,但事实证明它非常昂贵。
Vercel 收费 每优化 1,000 张图像 5 美元。随着成千上万的请求涌入,我们正在以每 1k 个图像请求 5 美元的速度积累成本。在最坏的情况下,如果所有 140 万张图片都被抓取,我们假设会收到来自 Vercel 的 7 千美元账单。
Step 3: Tens of thousands of requests from LLM bots
我们查看了 Vercel 中防火墙中请求的用户代理,看到了 Amazonbot、ClaudeBot、meta_externalagent 和一个伪装成浏览器的未知 bot。
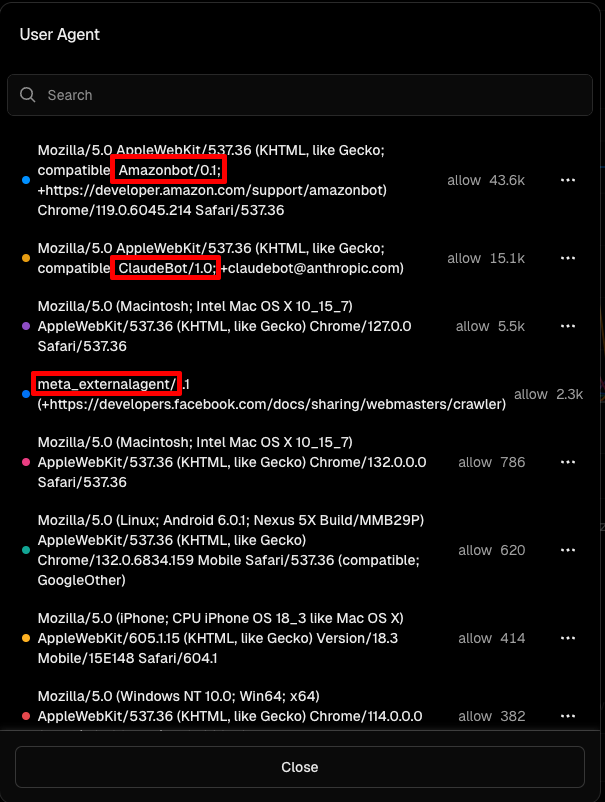
我们无法明确地说出哪些 bots 正在下载图片,因为我们使用的是 Vercel 上的 Pro 计划,无法再访问星期五的日志。我们只知道那是 bot 流量。
Mitigation
Step 1: Stop the bleeding
我们俩都曾在 AWS 工作,在那里我们内化了事件恢复的黄金法则 - 首先止血,稍后再进行长期修复。
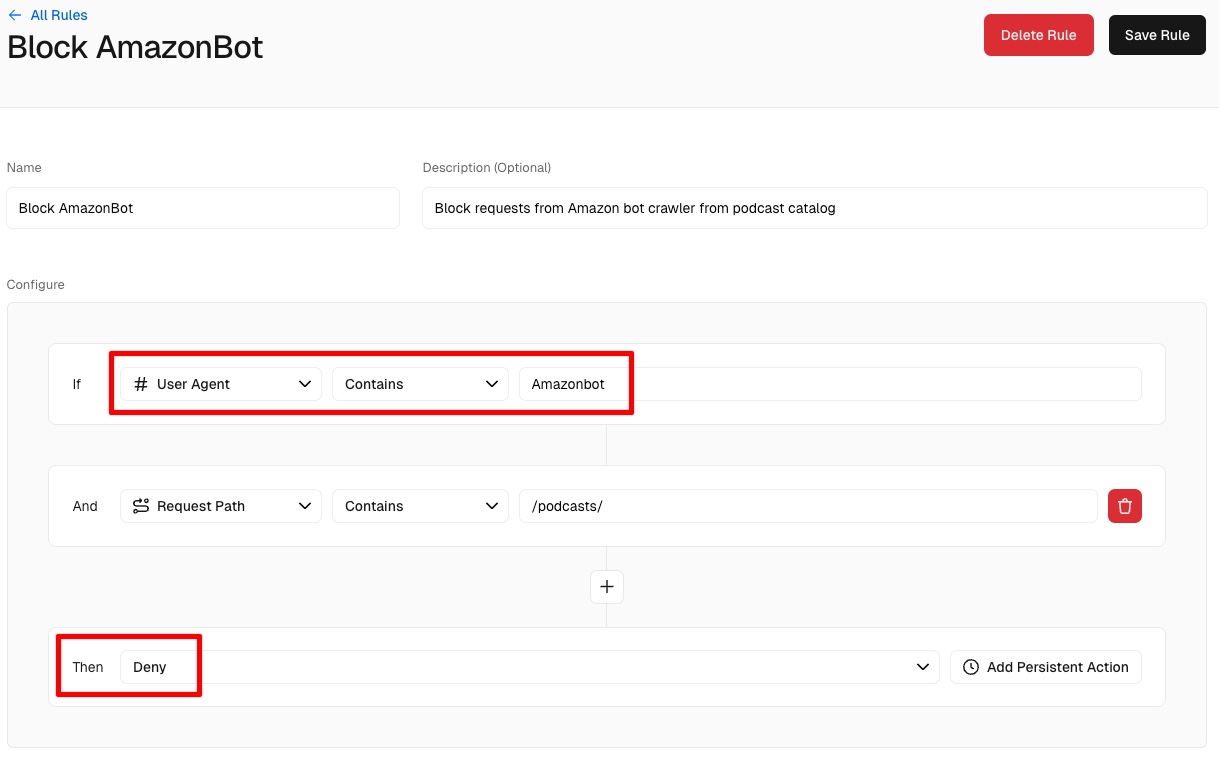
我们在 Vercel 中配置了防火墙规则,以阻止来自 Amazon、Anthropic、OpenAI 和 Meta 的 bots。公平地说,OpenAI 没有抓取我们的网站,但我们阻止了它作为预防措施。
Step 2: Disable Image Optimization
首先,我们通过在 Next.js 中将 unoptimized 属性添加到播客图片来禁用图片优化。我们的理由是,访问页面的用户将获得带有未优化图片的最新版本页面。
我们没有考虑到:
- Bots 已经抓取了数千个页面,并将使用从“旧”HTML 中提取的 URL 抓取 优化 图片。
- 我们的网站为所有外部主机启用了图片优化。
后者是故事中最令人尴尬的部分。我们错过了 Web 应用中一个明显的漏洞。
const nextConfig = {
images: {
remotePatterns: [
{
protocol: 'https',
hostname: '**',
},
{
protocol: 'http',
hostname: '**',
},
],
},
...
为了解释我们最初为什么这样做,我们需要添加一些关于播客的重要背景信息。
我们不拥有网站上显示的播客内容。与其他播客应用(如 Apple 和 Spotify)类似,我们从 RSS 源中提取播客信息并将其显示在我们的目录中。封面图片托管在专门的播客托管平台上,例如 Transistor, Buzzsprout,等等。但是播客可以托管在从 WordPress 网站到 S3 存储桶的任何地方。允许列出所有可能的主机是不切实际的。
优化图像意味着 Next.js 首先从其中一个主机下载图像到 Vercel,对其进行优化,然后将其提供给用户。如果我们想让我们的网站流畅,我们必须自己构建和维护图像优化管道,或者使用内置功能。作为一个资金紧张的创业公司,Web 应用充其量是次要的,我们选择了更快的路线,而没有过多考虑。
事后看来,我们应该研究一下它是如何工作的。我们很幸运没有人开始将我们的网站用作图片优化 API。
为了完全缓解这个问题,我们禁用了任何外部 URL 的图像优化。现在,仅对托管在我们自己域上的图像启用图像优化。播客封面的加载速度明显变慢。我们最终需要对此采取一些措施。
但这还不是全部。
Step 3: robots.txt
当然,我们知道 robots.txt,这是一个告诉爬虫它们是否被允许爬取网站的文件。
由于我们俩都是管理大型内容网站的新手(我们的背景是后端、API 和身份验证后面的 Web 应用),我们甚至没有考虑 LLM bots。这根本不在我们的考虑范围内。因此,我们的 robots.txt 是一个简单的允许所有,除了我们不允许的几个路径。
我们的第一个反应是禁用除 Google 之外的所有 bot 流量。但是,当我们了解到问题的根本原因在于错误配置的图像优化时,我们决定保持我们的网站对所有 LLM 和搜索引擎 bots 开放。提供文本内容不会花费我们太多,但我们可能会受益于在 LLM 中显示为数据源,这类似于在搜索引擎结果页面 (SERP) 上显示。
我们使用 Next.js 中的 robots.ts 以编程方式生成 robots.txt。我们研究了这些 bots,并将它们的用户代理添加到我们的代码中。如果我们将来需要禁用任何 bots,我们现在可以非常快速地完成。当我们这样做时,我们为 SEO bots(例如 Semrush 和 MJ12Bot)禁用了一些路径。
请注意,robots.txt 只有在 bots 尊重它时才有效。这是一个基于荣誉的系统,仍然有一些坏的 bots 会忽略它和/或试图伪装成用户。
User agents of LLM bots
User Agent | Link
---|---
Amazonbot | Amazon
CCBot | Common Crawl
ClaudeBot | Anthropic
GPTBot | OpenAI
Meta-ExternalAgent | Meta
PerplexityBot | Perplexity
User agents of search engine crawlers
User Agent | Link
---|---
Applebot | Apple
Baiduspider | Baidu
Bingbot | Bing
ChatGPT-User & OAI-SearchBot | OpenAI
DuckDuckBot | DuckDuckGo
Googlebot | Google
ImageSift | ImageSift by Hive
Perplexity‑User | Perplexity
YandexBot | Yandex
User agents of SEO bots
User Agent | Link
---|---
AhrefsBot | Ahrefs
DataForSeoBot | DataForSeoBot
DotBot | DotBot
MJ12bot | MS12Bot
SemrushBot | Semrush
How do we prevent this in the future?
我们将从我们做得很好的一件事开始。
Continue with a sensitive spend limit
我们有一个非常敏感的支出限制警报。我们知道我们不应该在 Vercel 上花费太多,所以我们设置得很低。当它被触发时,我们知道有些不对劲。
这可能是所有创业公司和大企业最重要的教训 - 始终为您的基础设施设置支出限制,否则账单可能会毁了您。您可能可以与 Vercel、AWS、GCP 等进行协商,他们会减少或免除您的账单。但最好不要让自己陷入不得不寻求帮助的境地。
Mindset for scale
我们学到了很多,并且(希望)已经适应了:
- 我们正在运营的规模 – 我们正在服务数百万个页面,并且需要为该规模的用户流量做好准备。这些 bots 让我们体验了如果我们的应用程序走红会是什么样子。
- Web 爬虫的规模,无论是好是坏 – 我们需要准备好被“anthropized”、“openAIed”、“amazoned”或“semrushed”。这是新的 slasdot effect,但没有立即获得满足感的好处。
Ready for defense
我们现在更好地理解了如果我们将来必须这样做,我们可以选择哪些选项来防火墙自己免受 bots 的攻击。 我们可以使用 Vercel 防火墙作为第一道防线,如果情况变得危急,可以从 Cloudflare 添加更高级的 WAF。
请参阅 Cloudflare 的这篇文章:Declare your AIndependence: block AI bots, scrapers and crawlers with a single click
Social media response
当我们发现 bots 爬取我们网站的速度时,我们在 LinkedIn 上发布了它。我们只是实时分享正在发生的事情,但它确实触动了神经。 近 40 万次展示,2.4k 个赞,270+ 条评论,120+ 次转发。
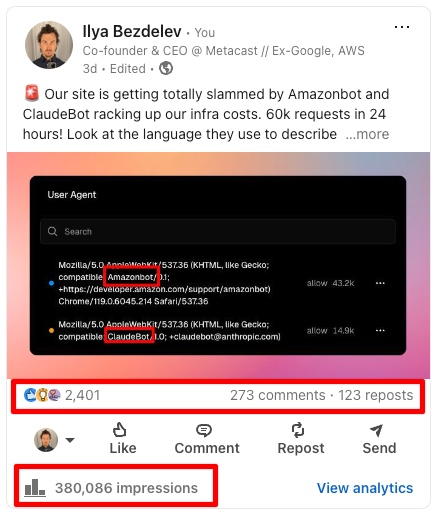
我们已经阅读了帖子上的所有评论,并回复了大部分评论。
许多人提供了解决方案,例如 CloudFlare、使用中间件、速率限制等。有些人提出向 LLM bots 反馈垃圾信息。
我们了解了 tarpit 工具,例如 iocaine 和 Nepenthes。
你可以把它们引诱到蜜罐里吗? 就像猪笼草或 locaine 一样。 如果你想毒害人工智能
人们正确地指出,您可能会被云资源的无限可扩展性所摧毁。
这是我对云提供商最大的担忧。 你犯了一个小错误(每个人都会犯),成本可能会在一夜之间飙升。
我们了解到有些人不知道 LLM bot 爬取活动或其规模。 他们感谢我们提高认识。
哇 - 感谢您提醒我们。
有些人像我们一样对 bots 感到惊讶。
我也是。 起初我很高兴收到这么多新订阅。 我们做了 reCaptcha 和 Cloudflare。 事情已经平静下来了。 谢谢你的帖子。 我以为我们是唯一的人
有些人根本不感到惊讶,并认为这是一个问题。
非常容易识别(不幸的是)。 这些(主要是 AI)bots 从 2024 年 5 月/6 月开始显着攻击我们的平台。 浪费了大量的时间和精力来控制我们的账单。 我们还发现并非所有人都尊重 Robots.txt,因此确实也需要 WAF。 我(不能)想象这对于较小的企业来说必须/将会是多么痛苦……
有些人责怪我们没有做好准备,并指责我们指责 AI 公司。其他人为我们辩护。 病毒式传播是一把双刃剑。
很大一部分评论声称数据抓取是不道德的、非法的等等。人们感到愤怒。 这不是我们的意图,但我们的帖子将这个问题带到了当天的时代精神中。
Parting thoughts
我的一部分很高兴发生了这件事。
我们在达到规模之前就体验到了大规模运营 Web 应用的滋味。 阻止 bots 很容易,但如果是用户流量造成的,我们就必须承担成本或降低体验。 Bots 是煤矿里的金丝雀。
任何技术都有负外部性。
有些是显而易见的,有些则不是。 在发生的所有事情中,我担心我们会受到播客托管商的惩罚,因为我们访问他们的端点的速度与 bots 从我们的网站请求图像的速度相同。
在互联网上大规模运营是一场防御游戏
我们可以随心所欲地抱怨 bots,但这 就是 我们所处的现实。 所以我们最好承认它并处理它。
P.S. 我们将在下一集 Metacast: Behind the scenes 播客中讨论这个话题。 无论您在哪里收听播客,都可以关注我们,以听到更多细微差别的故事。
UPD: Vercel changed their image optimization pricing
2025 年 2 月 18 日,就在我们发表这篇博文几天后,Vercel 更改 了他们的图像优化定价。 按照新的定价,我们不会面临巨额账单。
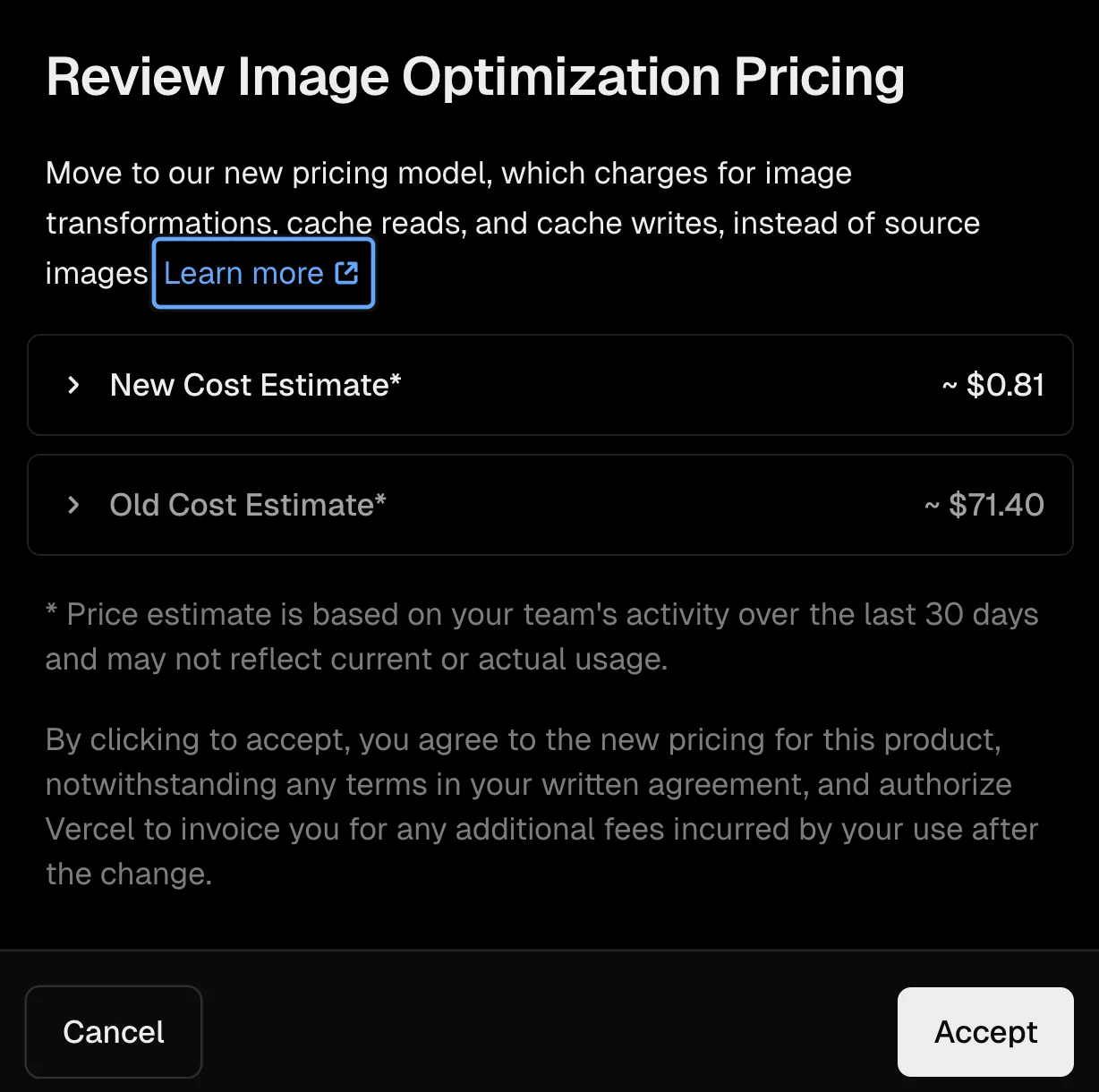
但是,这无法解决我们需要优化托管在我们域外的图像的问题。 我们最终实现了我们自己的图像优化。