深入探索 Postgres Wire Protocol
深入探索 Postgres Wire Protocol
2025年4月14日 Lev Kokotov
![]() PgDog 是一个网络代理,它可以观察到 Postgres 和客户端之间发送的每一个字节。它理解 SQL,并且可以推断出查询应该发送到哪里,而不需要修改应用程序代码。
PgDog 是一个网络代理,它可以观察到 Postgres 和客户端之间发送的每一个字节。它理解 SQL,并且可以推断出查询应该发送到哪里,而不需要修改应用程序代码。
在本文中,我们将讨论如何处理 Postgres wire protocol 并对其进行操作,以便同时为多个数据库提供查询服务。
协议基础
Postgres 有两种通过网络发送查询的方式:
- Simple protocol
- Extended protocol
Simple protocol之所以如此命名,是因为它非常简单。它只有一个消息,叫做 Query,其中包含服务器执行它所需的一切:
'Q' | \x00\x00\x00& | SELECT * FROM users WHERE id = 25\0
Postgres 消息具有标准格式。每个消息都以一个 ASCII 字母(1 字节)开头,用于标识消息类型。 后面是一个 32 位的有符号整数,表示有效载荷的长度,以字节为单位,加上自身占用的 4 个字节。有效载荷对于每条消息都是唯一的。
为了路由查询,PgDog 需要理解两件事:
- 查询是读取还是写入数据?
- 它是否包含分片键?如果包含,它的值是什么?
为了实现这一点,我们需要一些帮助。为了回答第一个问题,从理论上讲,我们可以只看第一个单词,如果它是 “SELECT”,就假设是读取意图。虽然这在大多数情况下都有效,但我们会错过一些明显的例子,比如 CTEs。
棘手的部分是找到分片键。为此,我们需要使用一个理解 SQL 语法的工具来实际解释查询。这叫做解析器,幸运的是 Rust 生态系统已经有一个很棒的库,叫做 pg_query。解析器生成一个抽象语法树(Abstract Syntax Tree),我们可以读取这个数据结构来找到我们需要的东西:
let ast = pg_query::parse("SELECT * FROM users WHERE id = 25");
pg_query 很特别。它实际上并没有实现 SQL 解析。它的工作原理是从 Postgres 中直接提取 C 源代码,并用一个不错的 Rust 接口来包装它。这使得 PgDog 能够理解 Postgres 可以理解的 所有 查询。
PgDog 的核心是 Postgres 分片。一旦我们在查询中找到分片键,我们就必须弄清楚如何处理它。让我们快速了解一下 Postgres 分区。
分片函数
选择正确的分片函数至关重要。这不是你可以轻易更改的东西。我在 Instacart 做这件事时学到的一件事是:选择一个可以在多个地方使用的分片函数。让我解释一下。
在现实世界中,无论你构建什么,都不会是与你的系统交互的 唯一 方式。要么你不想(现在)接触生产环境,要么你只需要临时移动一些东西,你希望工程师能够提前预处理数据,并有多种方式与你的系统进行交互。
因此,PgDog 没有实现自定义的分片函数。它使用的是 Postgres 声明式分区中使用的哈希函数:
CREATE TABLE users (id BIGINT, email VARCHAR)
PARTITION BY HASH(id);
如果你知道分片的数量,你可以创建相同数量的数据分区,然后直接用 COPY 命令将数据导入到表中。如果你使用带有 postgres_fdw 的 FOREIGN tables,你可以直接与分片数据库进行交互。
为了在 PgDog 中实现这一点,我们借鉴了 pg_query 的经验。我们可以自己实现这个函数,但最好直接从 Postgres 中获取代码,并用一个 Rust 接口来包装它。
Rust 让这件事变得相当容易。使用 cc (C/C++ compiler) 库,并通过复制/粘贴一些代码,我们有了一个可以工作的 FFI 接口,直接连接到 Postgres 源代码树中的 hashfn.c。我们只需要传递正确的数据,并应用模运算来获得分片编号。
提取参数
我们的示例只有一个过滤器:id = 25。这是最简单的情况,但也是最常见的情况。使用 pg_query 从 SQL 中获取这个值非常简单。一旦我们有了它,我们就可以将它传递给分片函数,然后就得到了分片编号。
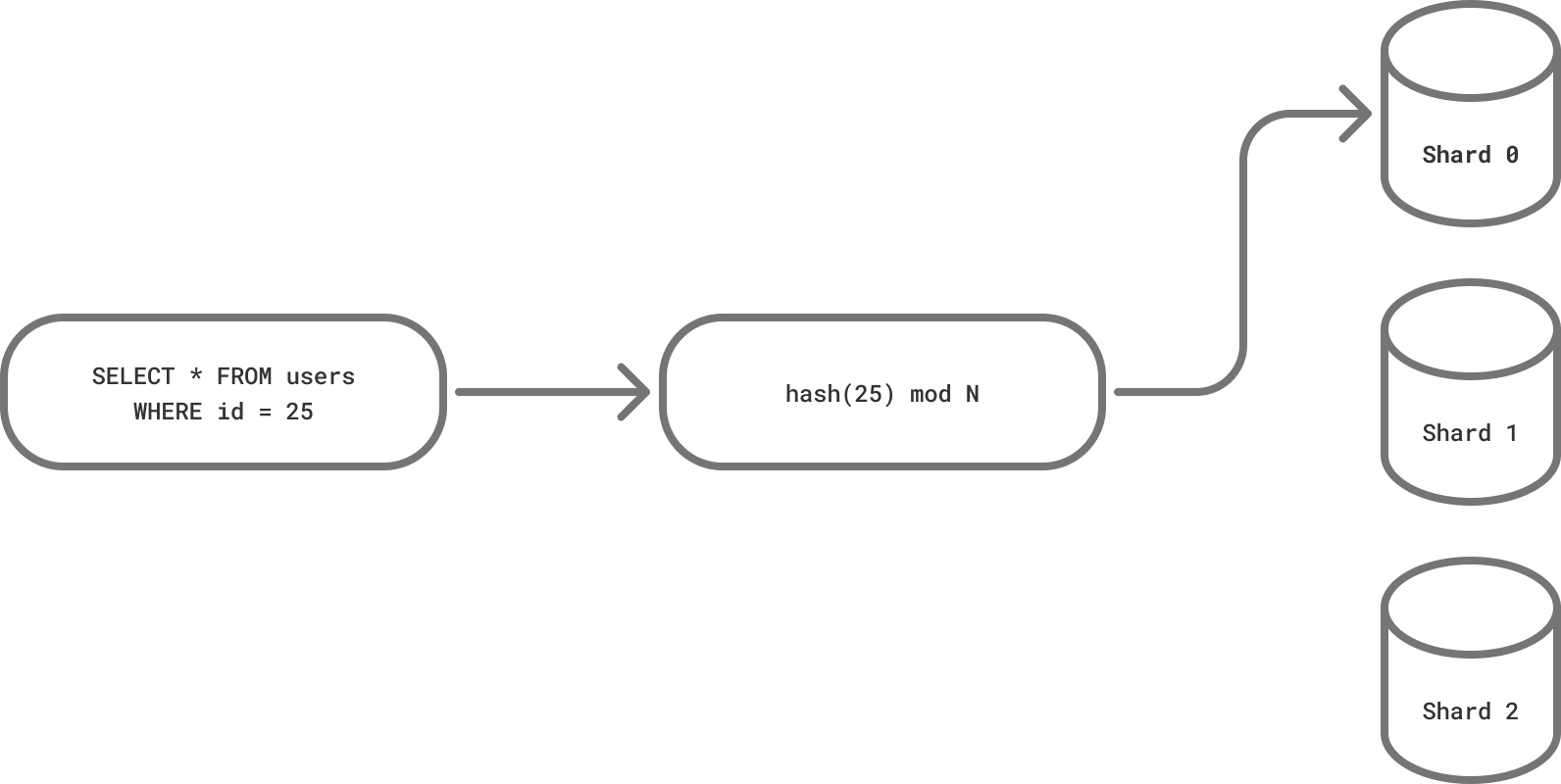
UPDATE 和 DELETE 查询的工作方式相同。它们都有(可选的)WHERE 子句,如果它有一个带有分片键的过滤器,我们就可以处理它。如果没有,查询将被发送到所有分片(稍后会详细介绍)。
更复杂的例子,比如 IN (1, 2, 3) 或 id != 25 也可以处理。对于前者,我们可以对所有值进行哈希,并将查询路由到匹配的分片。对于后者,我们将查询发送到所有分片。当然,有些情况是行不通的,例如 WHERE id < 25。需要哈希的值太多了,而且这个查询无论如何都会命中所有分片。
INSERT 语句更有趣一些,有两种变体:
INSERT INTO users (id, email) VALUES (25, 'hi@pgdog.dev');
INSERT INTO users VALUES (25, 'hi@pgdog.dev');
第一个指定了列的顺序,所以我们可以直接提取分片键。第二个没有指定,所以我们必须从 Postgres 获取 schema 并推断列的顺序。这稍微复杂一些,但仍然是一个可以解决的问题。我们还没有处理这个问题,但它在我们的路线图上。
像 Rails 和 Django 这样的 ORM 倾向于显式地为所有查询提供完全限定的列名和表名。这让我们的工作更容易,但我们不能总是依赖每个人都使用 ORM,而且我们当然不想对用户施加任意的限制。
Simple protocol 很简单,但如果客户端使用 prepared statements 和 extended protocol,事情会变得更有趣。
Extended protocol
Extended protocol 有多个消息。就我们的目的而言,我们只对两个感兴趣:
Parse,其中包含查询和参数占位符Bind,其中包含参数值
将两者分开允许 Postgres 解析一次查询,并使用不同的参数多次执行它。这对查询性能和避免 SQL 注入攻击很有帮助,但它要求我们做一些额外的步骤来获得我们需要的东西:
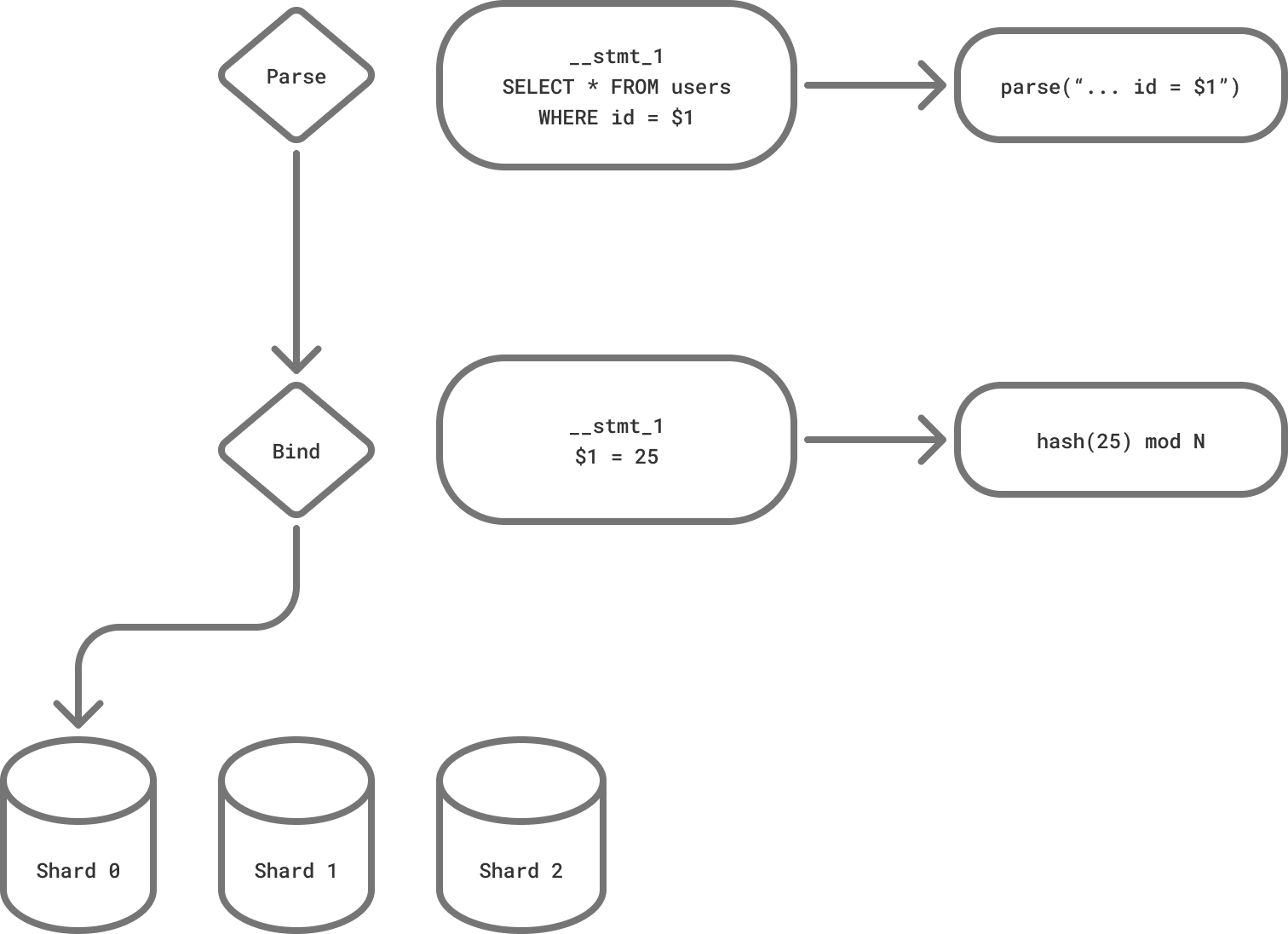
如果使用了 prepared statements,客户端通常会为每个查询发送一个 Parse 消息。PgDog 解析它并将 AST 存储在它的内存缓存中。这些语句是在全局级别上区分的,所以即使多个客户端发送相同的语句,它们也只会被评估一次。
这种优化对于在生产环境中快速运行至关重要。解析 SQL 并不免费,我们只会在必要时才这样做。消息本身保存在内存缓冲区中,而 PgDog 则等待实际的参数值到达。
Bind 消息在每次执行语句时都会随之而来。如果语句是匿名的(未命名的),我们只会收到一个 Bind 消息。在任何一种情况下,我们都知道分片键的位置,基于查询中编号的参数。
通过对分片键进行哈希,我们可以将两条消息转发到 Postgres 服务器连接并开始执行查询。
Simple protocol 和 extended protocol 都要求 PgDog 构建连接的内部状态,并跟踪流经的消息。只要我们保持协议同步,我们就可以操作 Postgres 接收到的消息以及发送回客户端的消息。当我们开始同时与多个服务器通信时,这一点就变得很重要。
跨分片查询
Postgres 查询响应包含多个消息。它们按照出现的顺序是:
RowDescription,其中包含列名和它们的数据类型DataRow具有实际值,每个结果集中的每一行都对应一个消息CommandComplete指示查询已完成运行,以及受影响的行数ReadyForQuery指示服务器已准备好进行下一个查询

由于 PgDog 是一个独立的代理,Postgres 服务器不知道它们正在执行一个多分片查询。每个服务器连接都会按照这个顺序返回所有这些消息。但是,除了 DataRow 消息之外,客户端期望每种消息只有一个。
管道中的每条消息都以不同的方式处理。对于 RowDescription,只返回最后一条。预计所有分片都具有相同的 schema,因此这些消息在分片之间应该是相同的。如果它们不相同,则数据类型必须兼容,例如 VARCHAR 和 TEXT。
这里还有一些细微的差别。例如,如果数据库有扩展创建的自定义数据类型,如 pgvector 或 PostGIS,它们的 OID 在不同的 Postgres 数据库中将不匹配,我们需要确保客户端只知道一组 OID。如果使用文本编码(默认情况下是这样),混合使用 BIGINT 和 INTEGER 也是可以的,尽管我不建议这样做。虽然像 Ruby 和 Python 这样的语言不区分这两者,但像 Rust 和 Java 这样的语言肯定会区分。
DataRow 消息有两种可能的处理方式。如果查询有一个 ORDER BY 子句,消息将被缓冲。一旦所有消息都被接收到,它们将被相应地排序,并以正确的顺序返回给客户端。如果行没有排序,PgDog 会立即将它们发送给客户端,以它从服务器接收到的任何顺序。
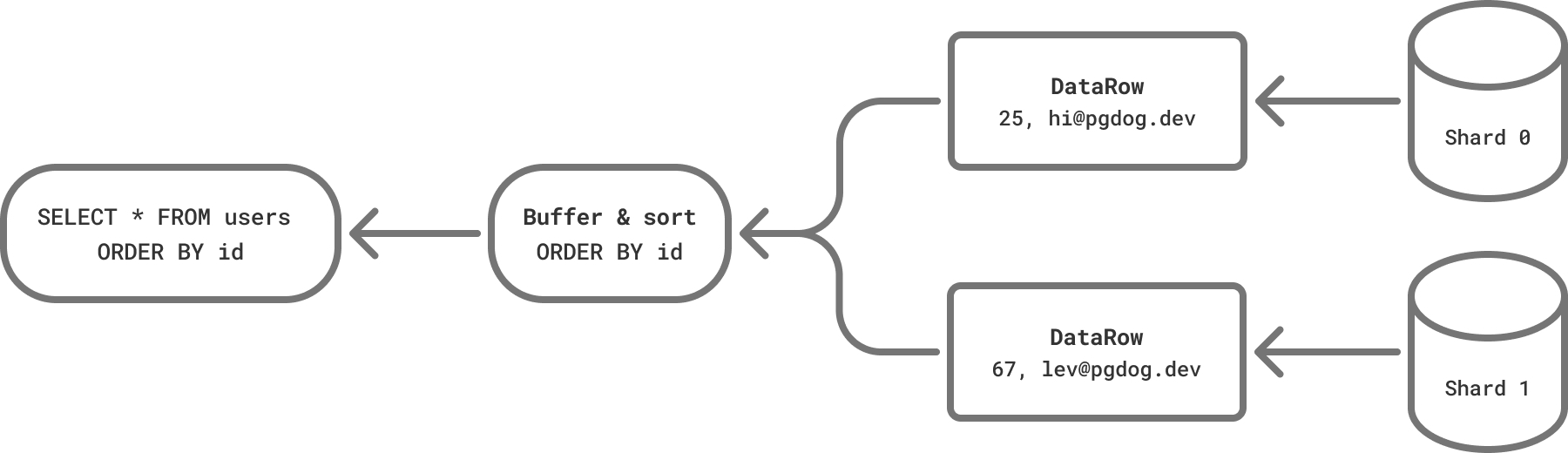
这就是对 SQL 的理解开始成形的地方。提取列值很好,但我们需要做更多的工作来确保查询被正确执行。PgDog 还不是一个完整的协调器,但每周都会添加更多功能。
CommandComplete 消息被重写以反映正确的行计数。我们通过解析它的内容,并将我们从所有分片收到的所有消息中的行数相加来实现这一点。ReadyForQuery 按原样转发(只有最后一条消息),跨分片查询就完成了。
协议操作适用于对话的两侧。PgDog 不仅仅是操作服务器消息。它更进一步,可以修改客户端消息,以创建一个强大的跨分片数据摄取管道。
分布式 COPY
将数据写入 Postgres 的最快方法是使用 COPY。它是一个特殊的命令,可以读取 CSV、文本或二进制数据,并直接将其写入一个表。它可以用来批量导入记录,并在数据库之间移动数据。
COPY users (id, email) FROM STDIN CSV HEADER;
id,email
65,hi@pgdog.dev
25,lev@pgdog.dev
Postgres 客户端使用两条消息发送这个命令:
Query发送 COPY 命令本身- 一系列
CopyData消息,其中包含实际的行
在分片数据库中,这个命令需要特殊处理。对于每一行,PgDog 提取分片键,对其进行哈希,并将其路由到正确的服务器:
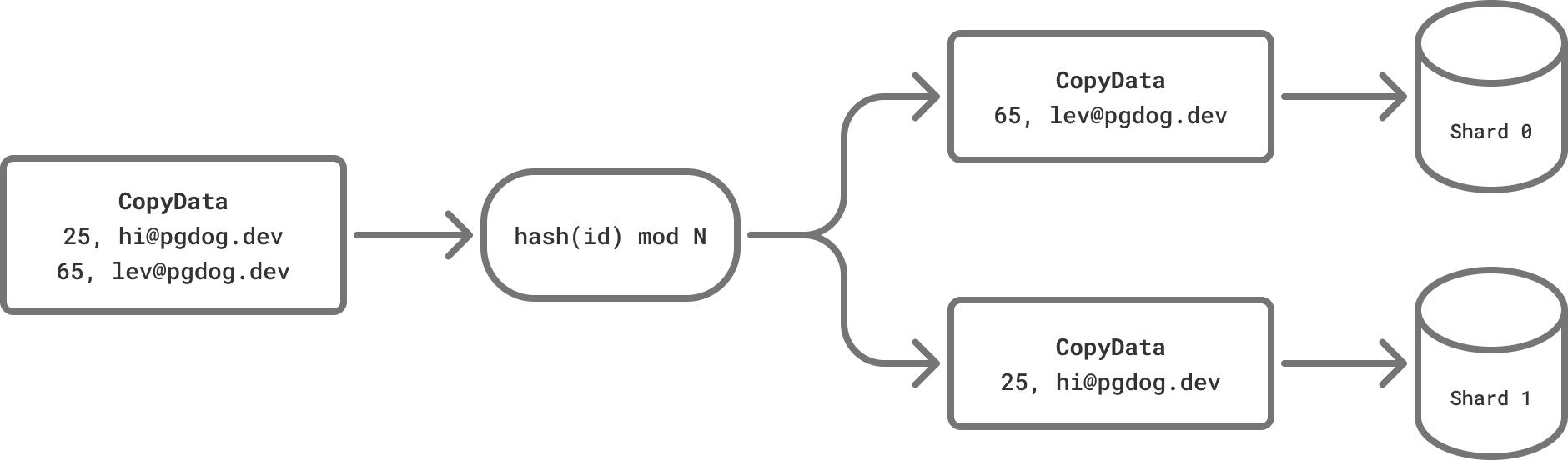
客户端通常以块的形式发送数据,而不管编码边界如何。例如,psql 创建的每个 CopyData 消息的长度为 4096 字节,可能会破坏 CSV 记录。为了实现这一点,PgDog 通过一次缓冲一行完整的数据来处理部分 CSV 记录和流式二进制数据。从 PgDog 发出的 CopyData 消息总是包含一个完整且唯一的行。
性能
理论上,分布式 COPY 可以线性扩展分片 Postgres 的导入速度。对于每个新的分片,导入速度应该增加 1/N,其中 N 是分片的数量。由于 PgDog 使用 Tokio 和多个线程,因此可以在具有多个 CPU 的机器上运行它,并并行处理数据行的哈希和操作。单个导入管道可以将每秒千兆字节的数据推送到 Postgres 中,同时保持 schema 和数据的完整性。
下一步
PgDog 只是刚刚开始。虽然它可以操作客户端和 Postgres 服务器使用的前端/后端 wire protocol,但我们将更进一步,并应用相同的技术来操作逻辑复制流。
由于 PgDog 在网络层完成所有这些操作,因此它可以运行在任何地方,包括像 AWS RDS 这样的托管云,并且可以与像 Aurora、AlloyDB 和 Cockroach 这样的 Postgres 克隆版本一起工作。
如果这很有趣,请联系我们!我们正在寻找早期采用者和设计合作伙伴。我们总是感谢 GitHub 上的 一个 star。
© 2025 PgDog, Inc. 保留所有权利。