复现 Hacker News 写作风格指纹识别
复现 Hacker News writing style fingerprinting
antirez 2 小时前. 5850 次浏览.
大约三年前,我在 Hacker News 上看到一篇非常有趣的文章。一位名叫 Christopher Tarry 的学生,通过使用余弦相似度来比较评论中高频词的频率向量,从而检测出相似的 HN 账户——有时甚至能检测出实际上由同一用户控制的账户,也就是用来掩盖作者身份的虚假账户。
这是原文链接:https://news.ycombinator.com/item?id=33755016
当时,我对 Burrows-Delta 方法进行风格检测并不了解:仅仅通过归一化高频词的频率向量就能达到如此显著的效果,这似乎有点神奇。我阅读了一些 Wikipedia 页面,并在脑海中记下了它。后来,当我在使用 Vectors for Redis 时,我想起了这篇文章,在网上搜索后发现原始页面已经消失,而且作者在原始文章和网站中并没有很好地解释数据的处理方式、高频词的提取方式(尤其是使用了多少个高频词)等等。我想,一旦完成主要工作,我就可以用 Vector Sets 重现这项工作。现在,新的数据类型已经进入候选版本,我找到了一些时间来解决这个问题。这是一份关于我所做工作的报告,但在继续之前,必须先展示一下演示站点:您可以通过以下链接进行体验:
https://antirez.com/hnstyle?username=pg&threshold=20&action=search
注意:由于数据集需要 700MB 的 RAM,在我的小型服务器上,我可能会在未来几个月内将其关闭。但是,在本文后面,您会找到代码链接和 Github 仓库,可以从头开始重现一切。
注意2:我希望这个网站能存活下去,它只是一个非常粗糙的 Python 脚本。我在这台小型服务器上对 VSIM 命令进行了基准测试,发现它每秒可以交付 8 万次 VSIM!这就是 int8 量化以及一些其他优化的奇迹。但 Python 脚本非常糟糕,每次都创建一个新的 Redis 连接等等。祈祷它能挺住。
原始数据下载和处理
好吧,我遇到的第一个问题是,为了做类似的事情,我需要找到一个包含 Hacker News 评论的存档。幸运的是,有一个存档包含了从 HN 成立到 2023 年的所有帖子,总数据量高达 10GB。您可以在这里找到它:https://huggingface.co/datasets/OpenPipe/hacker-news ,老实说,我不太确定这些数据是如何获得的,是使用 scraping 还是 HN 以某种方式公开了这些数据。
由于我不太喜欢二进制文件,至少在公共数据集的特定情况下,我使用了两个 Python 脚本来将 Parquet 文件转换为更小、更易于处理的文件。第一个脚本 gen-top-words.py 获取二进制文件并生成一个 txt 文件,其中包含数据集中使用的前 N 个词的列表。默认情况下,它会生成 1 万个词,但对于统计分析,需要的词要少得多(或者实际上:如果你使用太多的词,你将不再捕捉到风格,而是用户正在谈论的内容类型!)。然后,另一个 Python 脚本会累积每个用户的全部评论,并生成一个非常大的 JSONL 文件,其中只有两个键:用户名和给定用户从 HN 成立到 2023 年的历史记录中使用的所有词的频率表。每个条目都像这样:
{"by": "rtghrhtr", "freqtab": {"everyone": 1, "hates": 1, "nvidia": 1, "but": 1, "treats": 1, "ati": 1, "as": 1, "an": 1, "afterthought": 1, "another": 1, "completely": 1, "useless": 1, "tool": 1, "to": 1, "throw": 1, "on": 1, "the": 1, "pile": 1}}
此时,最后一个脚本 insert.py 可以完成所有实际工作:为每个用户应用 Borrows 方法,创建用户风格向量,并将其插入到 Redis 中。预处理文件(一个缓慢的操作)的优势在于,可以更轻松地使用不同的参数(尤其是要使用的前 N 个词的数量)来调用插入脚本,以便更快地看到不同的结果,而无需每次都重新处理 Parquet 文件。
Burrow 方法如何工作?
在原始文章中,Christopher 写道,你只需要对词语使用频率进行归一化并应用余弦相似度即可。实际上,这个过程要复杂一些。首先,让我们问问自己,这种方法本质上是如何工作的?好吧,它想要捕捉到每个特定用户相对于预期的“平均”语言过度使用或未充分使用的词语。为此,我们实际上使用以下步骤(来自 Python 代码)。
这是我们对每个高频词所做的:
# Convert to relative frequency
rel_freq = frequency / total_words
# Standardize using z-score: z = (freq - mean) / stddev
mean = word_means.get(word, 0.0)
stddev = word_stddevs.get(word, 1.0) # Default to 1.0 to avoid division
# zero
z_score = (rel_freq - mean) / stddev
# Set the z-score directly in the vector at the word's index
vector[word_to_index[word]] = z_score
因此,我们首先通过减去该词的 全局 使用频率来“居中”用户使用给定词的频率。这样,我们就得到了一个数字,描述了用户对该词的使用程度(负数)或过度使用程度(正数)。但是,如果你仔细想想,在不同作者的使用中具有更高方差的词语,当它们发生变化时,就不那么重要了。我们希望放大用户过度或未充分使用某个词语的信号,使其远大于该词语的正常方差。这就是为什么我们将居中的频率除以该词的全局标准差。现在我们得到了所谓的“z 分数”,这是一个调整后的度量,衡量了给定的词语在一种或另一种方向上离群的程度。
现在,我们可以将该词插入到 Redis 向量集中,只需:
VADD key FP32 [blob with 350 floats] username
(我不会在这里介绍向量集的细节,因为您可以在这里找到文档 -> https://github.com/redis/redis/blob/unstable/modules/vector-sets/README.md)
请注意,Redis 会对插入的向量执行 L2 归一化,但会记住 L2 值,以便在使用 VEMB 检索关联向量时返回这些值,因此 z_score 的设置保持不变。
最后,使用 VSIM,我们可以获得相似的用户:
127.0.0.1:6379> vsim hn_fingerprint ele pg
1) "pg"
2) "karaterobot"
3) "Natsu"
4) "mattmaroon"
5) "chc"
6) "montrose"
7) "jfengel"
8) "emodendroket"
9) "vintermann"
10) "c3534l"
所有代码(除了 webapp 本身)都可以在这里找到:https://github.com/antirez/hnstyle
README 文件解释了如何重现每个部分。
为什么是 350 个词?
原始文章中缺失的一个点,也激发了这篇博客文章,就是应该使用多少个高频词。如果你使用太多的词,你将会看到很多关于 Redis 的评论,因为 Redis 是使用频率最高的前 1 万个词之一。你猜怎么着?我最初就是犯了这个错误,VSIM 继续报告与我自己谈论相似话题的用户,而不是具有相似风格的用户。但幸运的是,互联网档案库缓存了 Christopher 关于 “pg” 账户的结果,在这里:
https://web.archive.org/web/20221126235433/https://stylometry.net/user?username=pg
因此,现在我可以调整我的 top-k 个词来获得相似的结果。此外,通过阅读原始论文,我惊讶地发现,为了使分析能够良好地工作,你甚至只需要少至 150 个词。一般来说,150 到 500 的范围被认为是最佳的。
警告:不要相信当你搜索一个用户时,你会找到的大部分是虚假账户。对于许多虚假账户来说,数据太少,因为人们经常创建一次性账户,写一些评论,仅此而已。因此,与给定用户风格相关联的大多数账户将只是具有相似写作风格的其他人。我相信这种方法在区分谁是母语者和谁不是母语者方面非常有效。从下面的向量可视化中可以特别清楚地看到这一点。
验证和可视化…
我重现的另一件事(也是 OP 的一个想法)是尝试以两种变体插入相同的用户,比如 antirez_A 和 antirez_B,使用两组不同的评论。然后检查请求与 antirez_A 相似的用户是否会报告 B。事实上,对于我测试过的大多数用户来说,效果非常好,而且通常是排名第一的结果。所以我们知道实际上我们的方法是有效的。
但是,由于从向量中很容易“看到”一种风格,那么我们的肉眼呢?最近我切换到 Ghostty 作为我的终端,它支持 Kitty 图形协议,因此你可以直接在终端窗口中显示位图。我想玩玩它已经有一段时间了。最后我找到了一个很好的理由来测试这个功能。
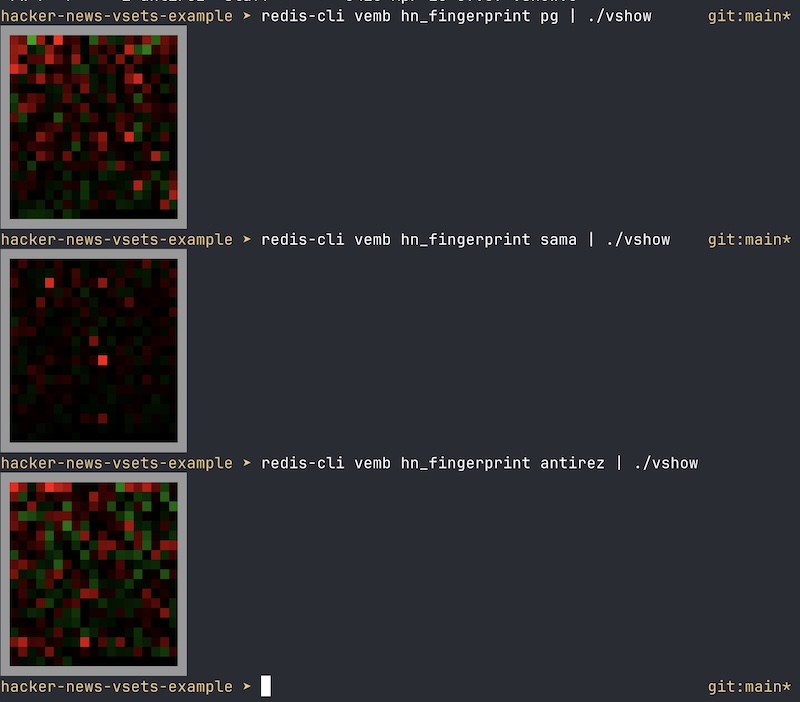
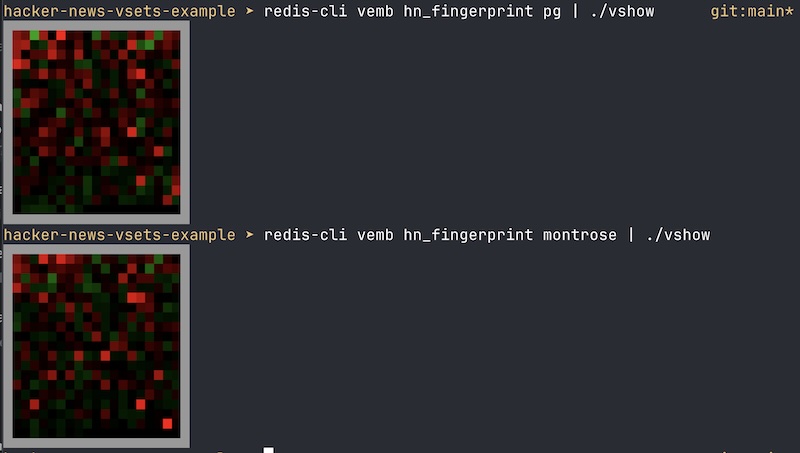
上面发生的事情是,我们调用 VEMB 命令,该命令只返回一个浮点数列表(向量)。
然后,vshow 实用程序(也是存储库的一部分)将负责找到可以包含该向量的最小正方形,并以红色显示正值,以绿色显示负值。
正如你所看到的,作为一个非母语者,我过度使用非常简单的词语,而未充分使用更复杂的词语。其他作者强调某些特定词语,而另一些作者则更加“平淡”,显示出较少的伪影。在某些时候,我很好奇那里到底发生了什么:我过度使用和未充分使用哪些词语?因此,在演示网站中,你也可以按下按钮来分析给定的用户,并查看过度使用和未充分使用的前 10 个词语。嗯,我的一些问题肯定是因为我的英语语法问题:D
好了,这次调查就到此为止!Vector sets 现在位于 Redis 8 RC1 中,我还有更多工作要做,但这很有趣,我相信它表明,即使在 AI 出现之前,向量也绝对很酷。感谢您阅读如此长的文章。
编辑:我忘记说了,insert.py 脚本还会插入包含用户编写的总字数的 JSON 元数据。因此,你可以使用 FILTER 来只显示与给定字数匹配的结果。这对于检测重复账户很有用,因为它们通常只在必须掩盖身份时才会被使用:
127.0.0.1:6379> vsim hn_fingerprint ele pg FILTER ".wordcount < 10000"
1) "montrose"
2) "kar5pt"
3) "ryusage"
4) "corwinstephen"
5) "ElfinTrousers"
6) "beaned"
7) "MichaelDickens"
8) "bananaface"
9) "area51org"
10) "william42"
EDIT2:如果你觉得匹配结果可疑(毫无意义),就像 tptacek 在这篇博客文章的 HN 提交中的评论中指出的那样,这里有一个“可视化”匹配,显示了例如 montrose 和 pg 在词语使用模式方面是多么相似: