Local LLM inference – impressive but too hard to work with
本地 LLM 推理:效果惊艳但难以应用
我偶然在一次支线任务中接触到了本地推理。主线任务是构建一个 text-to-SQL 产品。好奇心劫持了路线图:我能否将整个 GenBI 堆栈塞进浏览器?
原型产品最终未能发布。但我确实掉进了本地推理的兔子洞。虽然我的笔记本电脑的规格表上没有列出“AI 推理”这一项功能,但通过开源软件的神奇力量,现在它可以在浏览器标签中免费运行强大的 LLM。这令人印象深刻。但作为开发者平台,它还不够成熟,无法直接用于生产环境。
为什么费心进行本地计算?
从大型机到 PC 再到云,计算一直在中心化和边缘之间摇摆。现在,如果你透过炒作仔细观察,它正在向边缘回归。但大多数用户实际上并不关心计算发生在_哪里_。他们希望它快速且廉价。
例如:Figma 受欢迎不是因为它运行在 WebAssembly 上,而是因为用户觉得它响应迅速。DuckDB 在数据领域获得关注不是因为它能装在笔记本电脑上,而是因为它能削减 Snowflake 的账单。
大多数应用程序仍然在云端运行。然而,将计算转移到本地设备有四个好处:
- 成本
- 隐私
- 速度
- 支持离线使用
本地推理并不新鲜:iPhone 面部解锁自 2018 年以来已在移动设备上大规模实现了本地推理。没有本地推理,面部解锁就无法工作:它必须快速、离线工作、保证隐私,并且不能让 Apple 每次有人尝试解锁手机时都要为此付费。
随着软件应用程序越来越多地集成 LLM,将 AI 推理推向边缘可以带来相同的好处。
框架
我测试了以下本地推理框架,并使用了量化版本的 DeepSeek-R1-Distill-Qwen-7B 模型:
- llama.cpp: C/C++ 核心,高度优化。由 Georgi Gerganov 领导的出色项目。
- Ollama: 基于 llama.cpp 构建的产品和业务。更好的 DevEx 和模型库管理。
- WebLLM: 基于浏览器的推理,使用 WebGPU 加速,由 Carnegie Mellon 开发。构建在 MLC 之上。
我运行了推理基准测试,并以 OpenAI 的 gpt-4.0-mini 作为基线进行比较。基准测试代码可以在这里找到。
性能
测试是在我的 Macbook Pro 上运行的,配置如下:
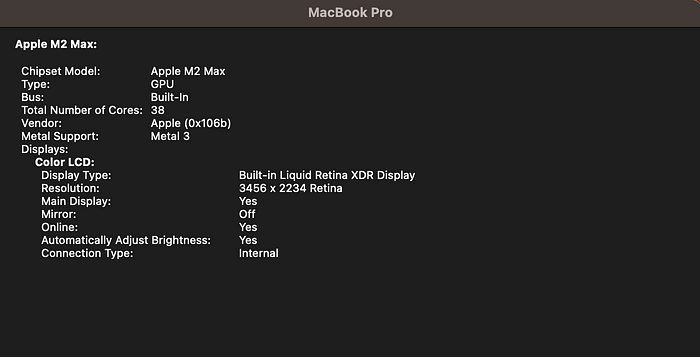
我跟踪的指标是:首个 Token 的中位时间 (TTFT) 和 每秒 Token 数 (TPS)。
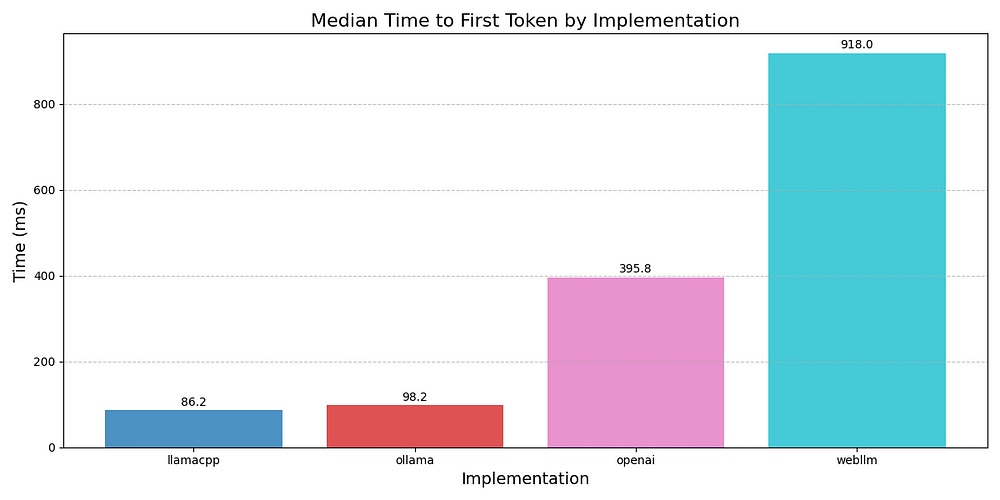
如上图所示,llama.cpp 和 Ollama 在 TTFT 方面都非常快。OpenAI 稍慢,可能是由于网络开销和身份验证。WebLLM 最慢。
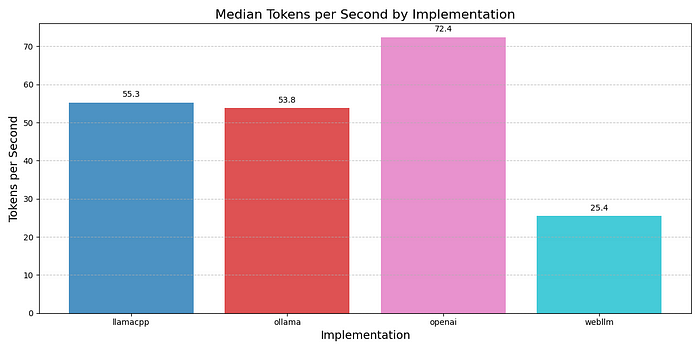
在 TPS 方面,llama.cpp 和 Ollama 相当,这是合理的,因为它们底层相同。WebLLM 的 TPS 仅为其他框架的一半。我只能推测这是因为 WebGPU 加速在利用本地 GPU 方面不如直接访问 GPU 的 llama.cpp 实现有效。
所有本地推理解决方案都比运行 gpt-4.0-mini 的 OpenAI 慢,而 gpt-4.0-mini 是一个相当大的模型。
虽然我没有跟踪内存使用情况或 CPU/GPU 利用率,但在基准测试运行时,我没有注意到在笔记本电脑上使用其他应用程序时出现任何明显的副作用。
更多模型,更多问题
虽然本地推理的性能落后于云解决方案,但它已经足够满足许多任务的需求。这就引出了我遇到的主要问题:为给定的任务找到和部署正确的模型。
考虑到资源限制,本地运行的模型必须比在云端运行的模型小得多。对于开发者来说,目前还没有办法找到(或轻松调整)一个可以执行“text-to-SQL”并在配备 M2 芯片的 Macbook 上工作的模型。即使我搁置了原型想法,只是想用 deepseek-qwen-7B 来对这些工具进行基准测试,我也不得不决定应该从 HuggingFace 上与此名称匹配的 663 个不同模型中下载哪个用于 llama.cpp。
此外,即使是精简的 7B 模型的量化版本也超过 5GB。即使在光纤互联网上,下载和加载这些模型也非常慢。对于应用程序开发者来说,这会导致应用程序的初始用户体验下降。例如,如果你的 webapp 使用 WebLLM,用户将需要坐等几分钟,等待模型下载到他们的机器上。
最终想法
本地 LLM 推理是可行的。它现在就可以工作,但在实际应用程序利用本地推理超出小众用例之前,开发工具还需要进一步成熟。
任何真正的解决方案都需要使训练和部署小型、特定于任务的模型变得非常简单,并与云 LLM 紧密集成。它必须在后台处理下载、缓存和本地执行,因此用户永远不会注意到模型在哪里运行或如何到达那里。