RL 是否真的能提升 LLM 中超越 Base Model 的推理能力?
强化学习真的能提升 LLM 中超出 Base Model 的推理能力吗?
Yang Yue1*† Zhiqi Chen1* Rui Lu1 Andrew Zhao1 Zhaokai Wang2 Yang Yue1 Shiji Song1 and Gao Huang1‡ 1 Tsinghua University, LeapLab 2 Shanghai Jiao Tong University
- Equal Contribution † Project Lead ‡ Corresponding Author Correspond to: {le-y22,zq-chen23}@mails.tsinghua.edu.cn , gaohuang@tsinghua.edu.cn Paper arXiv GitHub Yang Yue 目前专注于开发激励 LLM/MLLM 推理、广义世界模型以及探索 VLA 泛化的新范式。 他正在积极寻找与能够自由探索这些前沿和基本问题的公司合作的机会, 同时需要有丰富的资源和强大的技术氛围。 此外,他也在寻求博士访问的机会。 如果有合作的潜力,请随时联系。
您的浏览器不支持视频标签。
视频:基础模型及其零 RL 训练的对应模型在多个数学基准测试中的 _pass@k 曲线。 当 k 较小时,RL 训练的模型优于其基础版本。 然而,当 k 增加到几十或几百时,基础模型在所有基准测试和 LLM 系列中始终能赶上 RL 训练的模型。 最终,基础模型超越了 RL 训练的模型。
介绍我们的工作
最近在以推理为中心的大型语言模型 (LLMs)(如 OpenAI-o1、DeepSeek-R1 和 Kimi-1.5)方面的突破主要依赖于 Reinforcement Learning with Verifiable Rewards (RLVR),它用自动奖励(例如,经过验证的数学解决方案或通过的代码测试)代替人工注释,以扩展自我改进。 虽然 RLVR 增强了诸如自我反思和迭代改进之类的推理行为,但我们对一个核心假设提出了质疑:
RLVR 实际上扩展了 LLM 的推理能力,还是仅仅优化了现有的推理能力?
通过 pass@k 评估模型,其中成功仅需要在 k 次尝试中获得一个正确的解决方案,我们发现 RL 训练的模型在低 k 时表现出色(例如,pass@1),但在高 k 时始终_不如基础模型_(例如,pass@256)。 这表明 RLVR 缩小了模型的探索范围,倾向于已知的高奖励路径,而不是发现新的推理策略。 至关重要的是,来自 RL 训练模型的所有正确解决方案都已存在于基础模型的分布中,这证明 RLVR 增强了 采样效率,而不是推理能力,同时无意中缩小了解空间。
您的浏览器不支持视频标签。 视频:RLVR 对 LLM 推理能力的影响。 搜索树是通过从基础模型和 RLVR 训练的模型重复采样来生成的,以解决给定的问题。 灰色表示模型不太可能采样的路径,而黑色表示模型可能采样的路径。 绿色表示正确的路径,它具有正向奖励。 我们的主要发现是,RLVR 模型中的所有推理路径都已存在于基础模型中。 对于某些问题(如问题 A),RLVR 训练使分布偏向于奖励路径,从而提高了采样效率。 然而,这是以降低推理能力范围为代价的:对于其他问题(如问题 B),基础模型包含正确的路径,而 RLVR 模型则没有。
结论
- 在较大的 k 值下,RL 训练的模型在 pass@k 中表现不如基础模型。 虽然 RL 训练的模型在低采样规模(小 k)下优于基础模型,但在所有基准测试中,基础模型在较大的 k 下始终超越它们,甚至获得更高的 pass@k 分数。 手动检查表明,基础模型可以通过生成不同的推理路径来解决被认为需要 RL 训练的问题,每个问题至少有一个正确的解决方案。 这表明,与基础模型中的激进采样相比,RL 训练不会增强(甚至可能限制)LLM 的完整推理潜力。
- RL 提高了采样效率,但降低了推理能力的边界。 该分析表明,RLVR 训练的模型生成了已经存在于基础模型输出分布中的推理路径,这意味着 RLVR 使模型偏向于更高奖励的解决方案,而不是创建全新的推理能力。 然而,这种对奖励路径的关注降低了模型的探索能力,限制了它在更大采样规模下对可解决问题的覆盖范围。 这些发现表明,RLVR 并未从根本上超越基础模型的推理能力,而是以牺牲更广泛的问题解决多样性为代价来优化现有路径。
- RLVR 算法表现相似,并且与最优算法相差甚远。 该研究比较了各种 RL 算法(PPO、GRPO、Reinforce++),发现它们的性能差异很小,正如采样效率差距 (∆SE) 所衡量的,它评估了它们与最优采样效率的接近程度。 尽管算法之间的 ∆SE 略有不同,但所有方法的差距仍然很大。 这表明,目前专注于提高采样效率的 RL 方法仍然远未达到最佳性能。
- RLVR 和蒸馏从根本上是不同的。 虽然 RL 提高了采样效率,但蒸馏确实可以将新知识引入模型。 因此,通过从蒸馏模型中学习,蒸馏模型通常表现出超出基础模型的扩展推理能力范围,这与 RLVR 训练的模型(其能力受基础模型的限制)形成对比。
实验
我们进行了跨三个代表性领域的实验,以评估 RLVR 对基础模型和 RLVR 模型的推理能力边界的影响。
数学
在数学实验中,我们评估了多个 LLM 系列(Qwen-2.5 和 LLaMA-3.1)及其 RL 训练的变体在 GSM8K、MATH500 和 AIME24 等基准测试中的表现。 我们分析 pass@k 曲线以比较基础模型和 RL 训练的模型,观察到 RL 提高了低 k 性能,但降低了高 k 时的题目覆盖率。 我们手动检查 CoT 有效性,以确保正确的答案源于有效的推理,而不是侥幸猜测。 此外,我们检查了 Oat-Zero 训练的模型并过滤了可猜测的问题,以专注于具有挑战性的情况。 结果表明,尽管 RL 最初的准确率有所提高,但基础模型保持了更广泛的推理覆盖范围。
编程
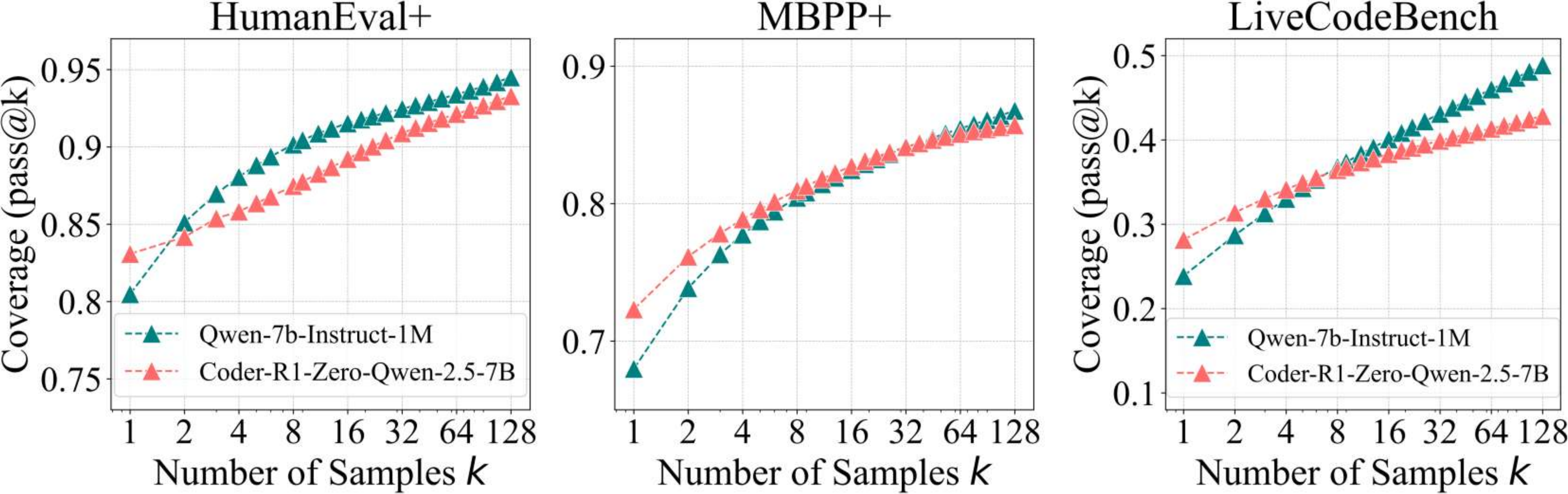
在编码实验中,我们评估了 RLVR 训练的模型 CodeR1-Zero-Qwen2.5-7B,该模型源自 Qwen2.5-7B-Instruct-1M,并在 LiveCodeBench、HumanEval+ 和 MBPP+ 等基准测试中进行评估。 我们使用 pass@k 指标评估性能,根据预定义的测试用例衡量正确性。 结果表明,RLVR 提高了单样本 pass@1 分数,但降低了更高采样计数 (k = 128) 下的覆盖率。 原始模型表现出通过更大的 k 持续改进的潜力,而 RLVR 的性能趋于平稳。 这表明 RLVR 增强了确定性准确性,但限制了探索多样性。
视觉推理
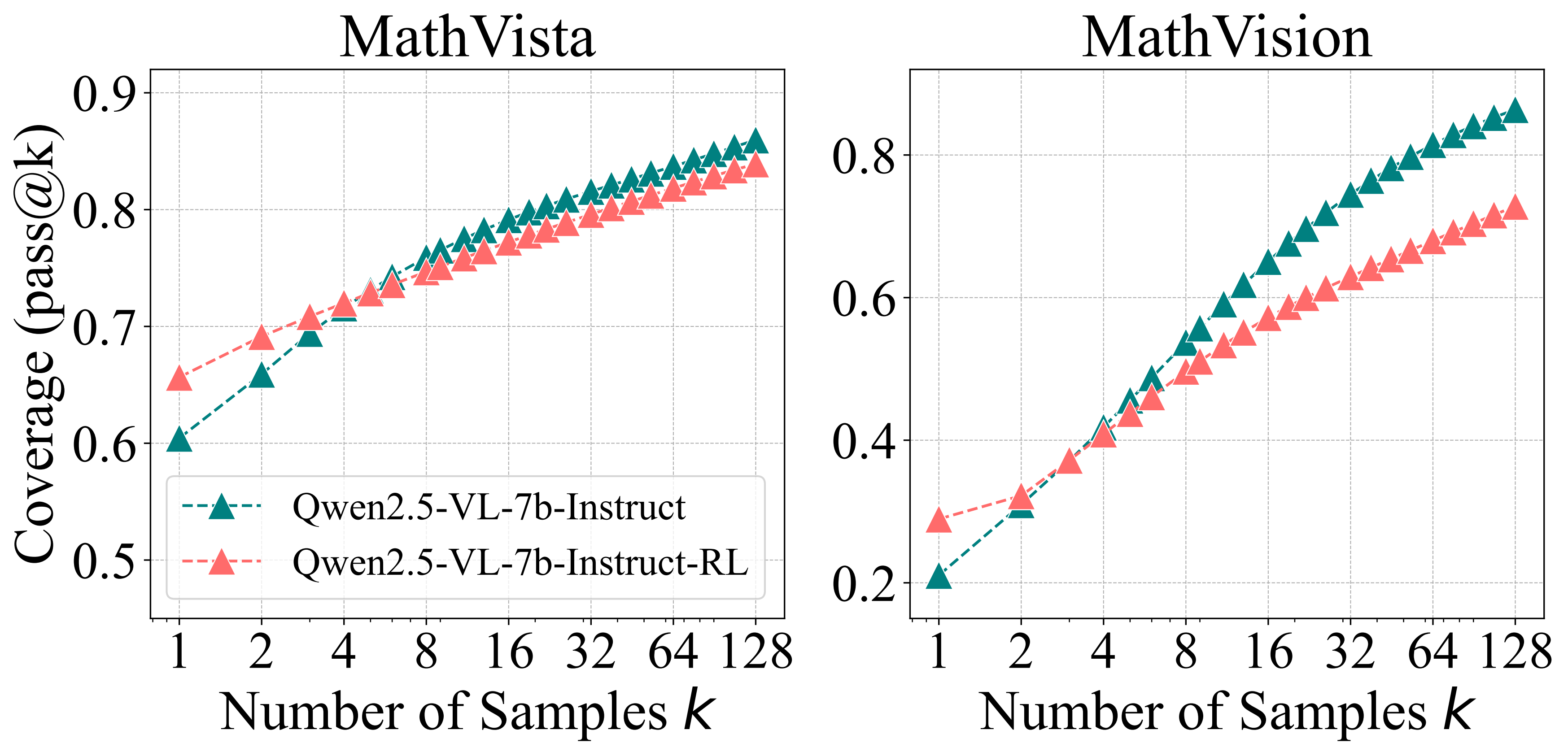
在关于视觉推理的实验中,我们评估了 Qwen-2.5-VL-7B 在经过筛选的视觉推理基准(MathVista 和 MathVision)上的表现,移除了多项选择题,以专注于强大的问题解决能力。 RLVR 在视觉推理方面的改进与在数学和编码基准中看到的改进相一致,表明原始模型已经涵盖了广泛的可解决问题,即使在多模态任务中也是如此。 各个领域的一致性表明,RLVR 增强了推理能力,而没有从根本上改变模型的问题解决方式。
案例研究
我们展示了从 base 模型中采样的 ONE 个正确的 CoT,该模型是从 AIME24 中最难问题的 2048 个采样中手动选择的。 来自基础模型的响应往往是长的 CoT,并且表现出反思行为,突出了基础模型中固有的强大推理能力。
示例

BibTeX
@article{yue2025limit-of-rlvr,
title={Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?},
author={Yue, Yang and Chen, Zhiqi and Lu, Rui and Zhao, Andrew and Wang, Zhaokai and Yue, Yang and Song, Shiji and Huang, Gao},
journal={arXiv preprint arXiv:2504.13837},
year={2025}
}