多项式特征是万恶之源吗?(2024)
一个误解
当使用线性回归拟合非线性模型时,我们通常使用非线性函数生成新的特征。 我们也知道,理论上任何函数都可以用足够高阶的多项式来近似。 这个结果被称为 Weierstrass approximation theorem。 但是许多博客、论文甚至书籍都告诉我们应该避免高阶多项式。 它们容易振荡和过拟合,并且正则化没有帮助! 他们甚至用图像吓唬我们,例如下面的图像,当使用数据点(红色)进行多项式拟合时,远离真实函数(蓝色): 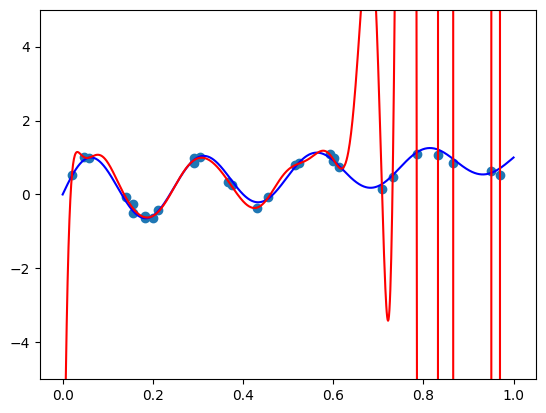
事实证明,这只是一个误解。 高阶多项式本身并没有什么问题,与通常的教导相反,高阶多项式很容易使用标准的 ML 工具(如正则化)来控制。 这种误解的主要来源是对多项式的两个误解,我们将在本文中探讨。 事实上,它们不仅是非常好的非线性特征,某些表示形式还为我们提供了对我们希望学习的函数形状的强大控制。
一个包含用于重现上述结果的代码的 colab notebook 可在此处获得 here。
近似 vs 估计
Vladimir Vapnik 在他著名的著作《统计学习理论的本质》中创造了近似与估计之间的平衡,该书至今已被引用超过 100,000 次。 模型的近似能力是其表示我们想要学习的“现实”的能力。 通常,近似能力随着模型的复杂性而增加 - 更多的参数意味着更多的能力以任意精度表示任何函数。 多项式也不例外 - 较高阶的多项式可以更高精度地表示函数。 但是,更多的参数使得_从数据中估计这些参数_变得困难。
确实,较高阶的多项式具有更高的近似任意函数的能力。 并且由于它们具有更多的系数,因此从数据中估计这些系数更加困难。 但它与其他非线性特征(例如众所周知的 radial basis functions)有何不同? 为什么多项式有如此糟糕的声誉? 它们真的很难从数据中估计吗?
事实证明,主要来源是用于 n 阶多项式的标准多项式基 En=1,x,x2,...,xn。 实际上,任何 n 阶多项式都可以写成这些函数的线性组合:
α0⋅1+α1⋅x+α2⋅x2+⋯+αnxn
但是标准基 Bn 对于从数据中估计多项式来说是_糟糕的_。 在这篇文章中,我们将探讨其他适合机器学习的多项式表示方法,这些方法在标准 Python 包中很容易获得。 我们注意到,多项式相对于其他非线性特征基的一个优势是,唯一的超参数是它们的_阶数_。 没有像径向基函数中那样的“核宽度”1。
它们声誉不佳的第二个原因是误解了 Weierstrass 近似定理。 它通常被引用为“多项式可以近似任意连续函数”。 但这并不完全正确。 它们可以近似 区间内的 任意连续函数。 这意味着在使用多项式特征时,必须将数据归一化为位于某个区间内。 可以使用最小-最大缩放、计算经验分位数或将特征传递给 sigmoid 来完成。 但我们应该避免在原始的未归一化的特征上使用多项式。
构建基础
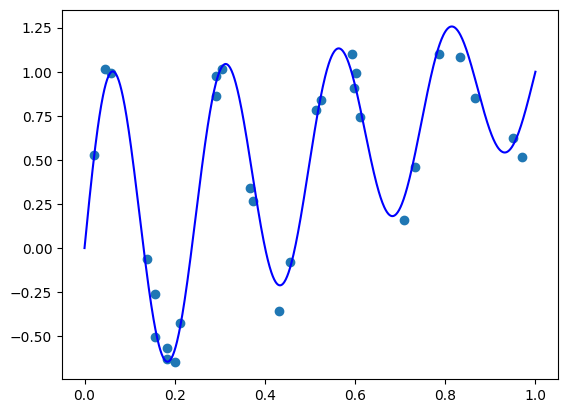
在这篇文章中,我们将演示拟合函数 f(x)=sin(8πx)/exp(x)+x 通过拟合到被高斯噪声破坏的 m=30 个样本,在区间 [0,1] 上。 以下代码实现该函数并生成样本:
import numpy as np
def true_func(x):
return np.sin(8 * np.pi * x) / np.exp(x) + x
m = 30
sigma = 0.1
# 生成特征
np.random.seed(42)
X = np.random.rand(m)
y = true_func(X) + sigma * np.random.randn(m)
对于函数绘图,我们将使用 [0,1] 中均匀分布的点。 以下代码绘制真实函数和样本点:
import matplotlib.pyplot as plt
plt_xs = np.linspace(0, 1, 1000)
plt.scatter(X.ravel(), y.ravel())
plt.plot(plt_xs, true_func(plt_xs), 'blue')
plt.show()
 现在让我们使用标准基将多项式拟合到采样点。 也就是说,给定一组噪声点 {(xi,yi)}mi=1,我们需要找到最小化的系数 α0,…,αn:
m∑i=1(α0+α1xi+⋯+αnxni−yi)2
不出所料,这很容易通过将每个样本 xi 转换为特征向量 1,xi,…,xni,并将线性回归模型拟合到生成的特征来实现。 幸运的是,NumPy 具有
现在让我们使用标准基将多项式拟合到采样点。 也就是说,给定一组噪声点 {(xi,yi)}mi=1,我们需要找到最小化的系数 α0,…,αn:
m∑i=1(α0+α1xi+⋯+αnxni−yi)2
不出所料,这很容易通过将每个样本 xi 转换为特征向量 1,xi,…,xni,并将线性回归模型拟合到生成的特征来实现。 幸运的是,NumPy 具有 numpy.polynomial.polynomial.polyvander 函数。 它接受一个包含 x1,…,xm 的向量并生成矩阵
(1x1x21…xn11x2x22…xn2⋮⋮⋮⋱⋮1xmx2m…xnm)
该函数的名称来自矩阵的名称 - Vandermonde 矩阵。 让我们用它来拟合一个 n=50 阶的多项式。
from sklearn.linear_model import LinearRegression
import numpy.polynomial.polynomial as poly
n = 50
model = LinearRegression(fit_intercept=False)
model.fit(poly.polyvander(X, deg=n), y)
我们使用 fit_intercept=False 的原因是 ‘intercept’ 由 Vandermonde 矩阵的第一列提供。 现在我们可以绘制我们刚刚拟合的函数:
plt.scatter(X.ravel(), y.ravel()) # 绘制样本
plt.plot(plt_xs, true_func(plt_xs), 'blue') # 绘制真实函数
plt.plot(plt_xs, model.predict(poly.polyvander(plt_xs, deg=n)), 'r') # 绘制拟合模型
plt.ylim([-5, 5])
plt.show()
不出所料,我们得到了这篇文章开头“可怕”的图像。 确实,标准基对于模型拟合来说太糟糕了! 我们希望正则化能提供补救措施,但事实并非如此。 也许添加一些 L2 正则化会有所帮助? 让我们使用 sklearn.linear_model 包中的 Ridge 类来拟合 L2 正则化模型:
from sklearn.linear_model import Ridge
reg_coef = 1e-7
model = Ridge(fit_intercept=False, alpha=reg_coef)
model.fit(poly.polyvander(X, deg=n), y)
plt.scatter(X.ravel(), y.ravel()) # 绘制样本
plt.plot(plt_xs, true_func(plt_xs), 'blue') # 绘制真实函数
plt.plot(plt_xs, model.predict(poly.polyvander(plt_xs, deg=n)), 'r') # 绘制拟合模型
plt.ylim([-5, 5])
plt.show()
我们得到以下结果:
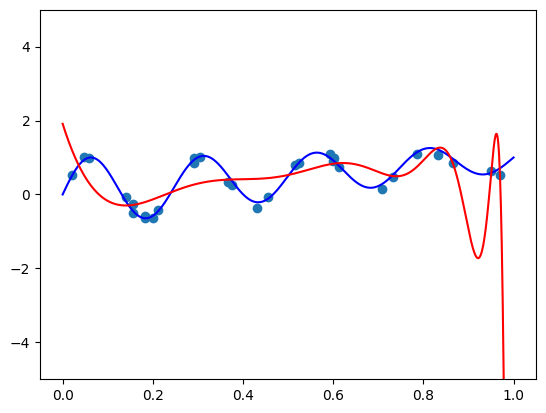 α=10−7 的正则化系数足够大,可以破坏 [0,0.8] 中的模型,但不足以避免 [0.8,1] 中的过度拟合。 增加系数显然没有帮助 - 模型将在 [0,0.8] 中被进一步破坏。
α=10−7 的正则化系数足够大,可以破坏 [0,0.8] 中的模型,但不足以避免 [0.8,1] 中的过度拟合。 增加系数显然没有帮助 - 模型将在 [0,0.8] 中被进一步破坏。
由于我们将尝试几个多项式基,因此为我们的实验编写一个更通用的函数是有意义的,该函数将接受我们选择的基的各种“Vandermonde”矩阵函数,使用 Ridge 类拟合多项式,并使用原始函数和样本点绘制它。
def fit_and_plot(vander, n, alpha):
model = Ridge(fit_intercept=False, alpha=alpha)
model.fit(vander(X, deg=n), y)
plt.scatter(X.ravel(), y.ravel()) # 绘制样本
plt.plot(plt_xs, true_func(plt_xs), 'blue') # 绘制真实函数
plt.plot(plt_xs, model.predict(vander(plt_xs, deg=n)), 'r') # 绘制拟合模型
plt.ylim([-5, 5])
plt.show()
现在我们可以通过调用来重现我们最新的实验:
fit_and_plot(poly.polyvander, n=50, alpha=1e-7)
多项式基
事实证明,在我们的姐妹学科近似理论中,研究人员也遇到了标准基 En 的类似困难,并开发了一种理论,用于通过来自不同基的多项式来近似函数。 n 阶多项式基的两个突出例子包括:
- Chebyshev polynomials Tn={T0,T1,…,Tn},在
numpy.polynomial.chebyshev模块中实现。 - Legendre polynomials Pn={P0,P1,…,Pn},在
numpy.polynomial.legendre模块中实现。
它们是大量数值算法的计算主力,这些算法通过使用多项式近似函数来实现,并且以其在 [−1,1] 区间中近似函数的优势而闻名2。 特别是,相应的“Vandermonde”矩阵由上述相应模块中的 chebvander 和 legvander 函数提供。 这些矩阵中的每一行都包含每个点的基函数的值,就像标准基的标准 Vandermonde 矩阵一样。 例如,Chebyshev Vandermonde 矩阵是:
(T0(x1)T1(x1)…Tn(x1)T0(x2)T1(x2)…Tn(x2)⋮⋮⋱⋮T0(xm)T1(xm)…Tn(xm))
我不会在这里详细阐述它们的公式和属性,原因会立即揭晓。 但是,我强烈推荐 Nick Trefethen 教授的“近似理论和近似实践”在线视频课程,以熟悉它们的优势。 他同名的书是对该主题的极好介绍。
可能很想尝试使用我们上面的 fit_and_plot 方法直接拟合 Chebyshev 多项式:
import numpy.polynomial.chebyshev as cheb
fit_and_plot(cheb.chebvander, n=50, alpha=1e-7)
然而,这不是最好的做法。 我们的目标是拟合从 [0,1] 采样的函数,但 Chebyshev 基“存在”于 [−1,1] 中。 因此,我们将在调用 chebvander 函数之前添加变换 x→2x−1:
def scaled_chebvander(x, deg):
return cheb.chebvander(2 * x - 1, deg=deg)
fit_and_plot(scaled_chebvander, n=50, alpha=1)
请注意,不同的基需要不同的正则化系数。 我们得到以下结果:
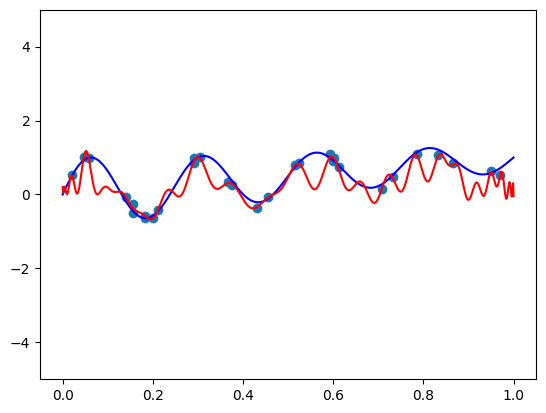 哇! 似乎比标准基还要糟糕! 也许更多的正则化会有所帮助?
哇! 似乎比标准基还要糟糕! 也许更多的正则化会有所帮助?
fit_and_plot(scaled_chebvander, n=50, alpha=10)
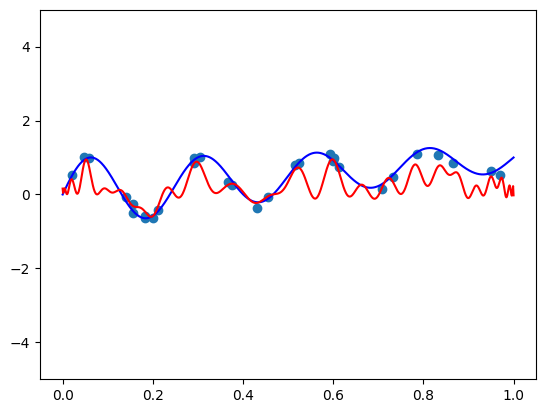 看来我们的多项式既不适合该函数,而且振荡也非常剧烈。 甚至比标准基更糟糕! 感兴趣的读者可以使用 Legendre 多项式重复实验,并看到稍微好一点但类似的结果。 那么有什么问题呢? 近似理论试图教给我们关于多项式的一切都是错误的吗?
看来我们的多项式既不适合该函数,而且振荡也非常剧烈。 甚至比标准基更糟糕! 感兴趣的读者可以使用 Legendre 多项式重复实验,并看到稍微好一点但类似的结果。 那么有什么问题呢? 近似理论试图教给我们关于多项式的一切都是错误的吗?
答案源于两项任务之间的根本区别:
- 插值 - 找到一个多项式,该多项式在 精心选择的 点集上与近似函数 f(x) 完全 一致
- 拟合 - 找到一个多项式,该多项式与给定的 有噪声的 点集 近似 一致,这些点 超出我们的控制。
Chebyshev 基和 Legendre 基在插值任务中表现非常好,但在拟合任务中表现不佳。 事实证明,Chebyshev 基中的多项式 Tk 和 Legendre 基中的多项式 Pk 都是 k 阶多项式。 例如,T1 是一个线性函数,而 T50 是一个 50 阶多项式。 这两个函数截然不同。 因此,T1 和 T50 的系数具有“不同的单位”。 标准基也具有此属性。 因此,我们有两个问题:
- 高阶基函数系数的微小变化(例如系数 α50)对多项式的形状有巨大影响。 因此,输入数据中的微小扰动(无论是来自噪声还是来自稍微不同的数据点 xi)对拟合模型有 巨大 影响。
- L2 正则化没有意义! 对于合理的函数,系数 α50 应该远小于系数 α1。 这与基的选择无关!
这两个属性都表明,对于拟合任务而不是插值任务,我们需要其他东西。
Bernstein 基
Bernstein basis Bn={b0,n,…,bn,n} 提供了一种补救措施。 这些是 n 阶多项式,由以下公式在 [0,1] 上定义:
bi,n(x)=(ni)xi(1−x)n−i
这些多项式广泛用于计算机图形学中以近似曲线和曲面,但似乎它们在机器学习社区中鲜为人知。 事实上,您在阅读这篇文章时在屏幕上看到的所有文本都是使用 Bernstein 多项式渲染的3。 我们将在接下来的文章中更深入地研究它们,但在现阶段我想指出两个简单的属性,它们可以直观地解释为什么它们在机器学习中有用。
首先,请注意每个 bi,n 都是一个 n 阶多项式。 因此,当使用以下公式表示多项式时
pn(x)=α0b0,n(x)+α1b1,n(x)+⋯+αnbn,n(x), 所有系数都具有相同的“单位”。
如果 bi,n(x) 的公式看起来很熟悉 - 您是正确的。 它正是二项分布的概率质量函数,用于在成功概率为 x 的一系列试验中获得 i 次成功。 因此,bi,n(x)≥0,并且对于任何 x∈[0,1],∑ni=0bi,n(x)=1。 因此,多项式 pn(x) 只是系数 α0,…,αn 的加权平均值。 因此,系数不仅具有相同的“单位”,而且它们的“单位”也与模型的标签相同。 因此,它们更容易正则化 - 它们都在同一个“尺度”上。
最后,由于与二项分布 p.m.f 的等价性,我们可以使用 scipy.stats.binom.pmf 函数在 Python 中实现“Vandermonde”矩阵。
from scipy.stats import binom
def bernvander(x, deg):
return binom.pmf(np.arange(1 + deg), deg, x.reshape(-1, 1))
让我们尝试在根本没有正则化的情况下进行拟合
fit_and_plot(bernvander, n=50, alpha=0)
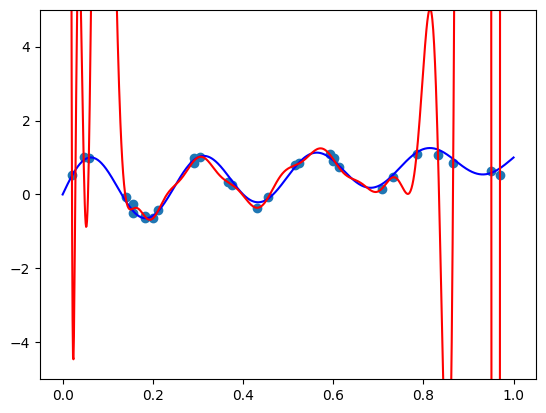 我们看到了我们常规的过度拟合。 现在让我们看看它们是否真的很容易正则化。 在尝试了几个正则化系数后,我想出了这个:
我们看到了我们常规的过度拟合。 现在让我们看看它们是否真的很容易正则化。 在尝试了几个正则化系数后,我想出了这个:
fit_and_plot(bernvander, n=50, alpha=5e-7)
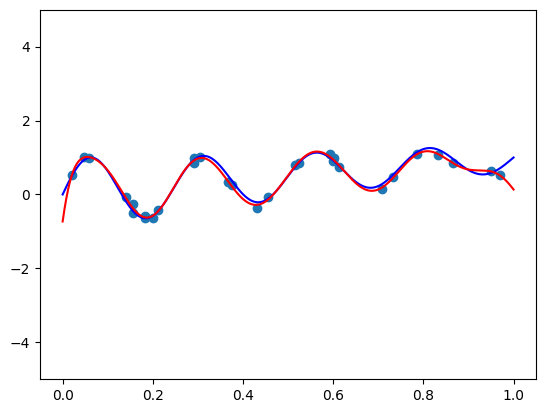 太棒了! 这是一个 50 阶的多项式! 拟合效果很好,没有振荡,并且右端点附近的失配源于噪声 - 我不相信数据中有足够的信息来传达它应该“向上弯曲”而不是“向下弯曲”的事实。
太棒了! 这是一个 50 阶的多项式! 拟合效果很好,没有振荡,并且右端点附近的失配源于噪声 - 我不相信数据中有足够的信息来传达它应该“向上弯曲”而不是“向下弯曲”的事实。
让我们看看当我们调高阶数时会发生什么。 我们可以产生一个漂亮的非振荡多项式吗?
fit_and_plot(bernvander, n=100, alpha=5e-4)
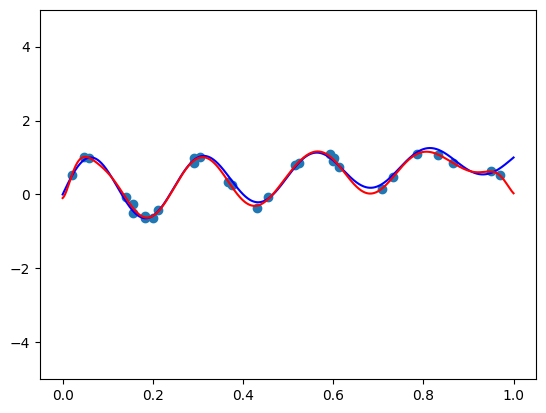 这是一个 100 阶的多项式,不会过度拟合!
这是一个 100 阶的多项式,不会过度拟合!
总结
高阶多项式在机器学习社区中的臭名昭著主要是无稽之谈。 尽管如此,论文、书籍和博客文章都基于这个前提,就好像它是一个公理。 Bernstein 多项式在机器学习社区中鲜为人知,但有一些论文45使用它们来表示多项式特征。 它们的主要优点是易于使用 - 我们可以使用高阶多项式来利用它们的近似能力,并且只需一个超参数 - 正则化系数 - 即可轻松控制模型的复杂性。
在接下来的文章中,我们将更详细地探讨 Bernstein 基。 我们将使用它来为真实世界的数据集创建多项式特征,并针对标准基对其进行测试。 此外,我们将看到如何正则化系数以控制我们希望表示的函数的形状。 例如,如果我们知道我们旨在拟合的函数正在增加会怎样? 敬请期待!
- 还有核方法和多项式核。 但是多项式核存在与标准基类似的问题。 ↩
- 标准基并没有那么糟糕。 它是表示复单位圆上多项式的绝佳基础。 事实上,傅里叶变换正是基于这种观察。 ↩
- 请参阅 Bézier curves 和 TrueType font outlines。 ↩
- Marco, Ana, and José-Javier Martı. “Polynomial least squares fitting in the Bernstein basis.” Linear Algebra and its Applications 433.7 (2010): 1254-1264. ↩
- Wang, Jiangdian, and Sujit K. Ghosh. “Shape restricted nonparametric regression with Bernstein polynomials.” Computational Statistics & Data Analysis 56.9 (2012): 2729-2741. ↩