使用 Cloudflare Workers 和缓存实现 Have I Been Pwned 的超大规模扩展
[中文正文内容]
Sponsored by:
更进一步:使用 Cloudflare Workers 和缓存实现 Have I Been Pwned 的超大规模扩展
2024年11月21日
我已经花了十多年时间撰写关于如何加速 Have I Been Pwned (HIBP) 的文章。 真的 很快。速度之快,有时甚至 太 快了:
每次搜索的响应都返回得如此之快,以至于用户不确定它是否真的在检查他们输入的后续地址,或者是否存在故障。
多年来,该服务不断发展,采用新兴的新技术,不仅使其速度更快,而且使其在负载下更易于扩展,提高可用性,有时甚至降低成本。 例如,8 年前,我开始将最重要的服务迁移到 Azure Functions,“无服务器”代码,不再受逻辑机器的限制,而是可以扩展到任何请求量。就在去年,我开启了 Cloudflare cache reserve 以确保所有可缓存的对象保持缓存,即使在以前会被逐出的情况下也是如此。
现在,最精彩的部分来了,这是我们迄今为止所做的最酷的性能优化(现在是“我们”,感谢 Stefán):只需将全部内容缓存在 Cloudflare 上。所有内容。您所做的每一次搜索……几乎如此。 首先,让我通过一些背景知识来解释:
当您访问 HIBP 上的任何服务时,流量从您的浏览器首先到达 Cloudflare 的 330 个“边缘节点”之一:
我现在坐在澳大利亚黄金海岸的最东边海岸写作,我向 HIBP 发出的任何请求都会到达澳大利亚大陆最右边的边缘节点,它就在布里斯班的路上。昆士兰州首府距离酒店仅一小段水上摩托艇路程,直线距离约 80 公里。 在此之前,每次我从家里搜索 HIBP 时,我的请求字节都会沿着线路到达布里斯班,然后进行 12,000 公里的巨大行程到达西雅图,那里的 West US Azure 数据中心的 Azure Function 会查询数据库,然后将响应发送 12,000 公里回到西方的 Cloudflare 的边缘节点,然后最后 80 公里到达我在冲浪者天堂的家。 但如果不必这样呢? 如果这些数据已经位于布里斯班的 Cloudflare 边缘节点上呢? 以及巴黎的那个,以及嗯,我什至不确定所有这些蓝点在哪里,但如果它 无处不在 呢? 将会发生几件很棒的事情:
- 您会更快地收到响应,因为我们已经减少了 99% 以上的字节需要传输的距离。
- 可用性将大大提高,因为流量需要遍历的节点少得多,而且当响应被缓存时,我们不再依赖 Azure Function 或底层存储机制。
- 我们可以节省 Azure Function 的执行成本、存储帐户命中次数,尤其是出口带宽(这非常昂贵)。
简而言之,将数据和处理“推向边缘”有利于我们的客户和我们自己。 但是,如何针对 5 十亿 个唯一的电子邮件地址执行此操作? (注意:截至今天,HIBP 报告了超过 140 亿个泄露帐户,唯一电子邮件地址的数量较低,因为平均而言,每个泄露地址都出现在多个泄露事件中。)为了回答这个问题,让我们回顾一下如何查询数据:
- 通过网站的首页。 这会访问“统一搜索”API,该 API 接受电子邮件地址,并使用 Cloudflare 的 Turnstile 来禁止并非来自浏览器的自动请求。
- 通过公共 API。 此端点还将电子邮件地址作为输入,然后返回它出现的所有泄露事件。
- 通过 k-anonyity 企业 API。 此端点由少数大型订阅者(例如 Mozilla 和 1Password)使用。 它不是按电子邮件地址搜索,而是实现 k-匿名性并按哈希前缀搜索。
让我们进一步深入研究最后一点,因为这是整个缓存模型的工作原理的秘诀。 为了向此服务的订阅者提供对所搜索电子邮件地址的完全匿名性,传递给 API 的唯一数据是完整电子邮件地址的 SHA-1 哈希的前六个字符。 如果这听起来很奇怪,请阅读该最后一个项目符号点中链接的博客文章以获取完整详细信息。 但是,现在最重要的是,这意味着总共有 16^6 个不同的可能请求可以发送到 API,这略高于 1600 万个。 此外,我们可以在服务器端将上述前两个用例转换为 k-匿名性搜索,因为它仅涉及哈希电子邮件地址并获取前六个字符。
总而言之,这意味着我们可以将整个可搜索的电子邮件地址数据库归结为以下内容:
- AAAAAA
- AAAAAB
- AAAAAC
- ...大约 1600 万个其他值...
- FFFFFD
- FFFFFE
- FFFFFF
这是一个很大但有限的列表,这就是我们现在正在缓存的内容。 因此,以下是通过电子邮件地址搜索的样子:
- 要搜索的地址:test@example.com
- 完整 SHA-1 哈希:567159D622FFBB50B11B0EFD307BE358624A26EE
- 六个字符的前缀:567159
- API 端点:https://[host]/[path]/567159
- 如果哈希前缀已缓存,则从那里检索结果
- 如果哈希前缀 未 缓存,则查询源并保存到缓存
- 将结果返回给客户端
K-匿名性搜索显然会直接转到步骤四,跳过前几个步骤,因为我们已经知道哈希前缀。 所有这些都发生在 Cloudflare worker 中,因此它是“边缘上的代码”,用于创建哈希、检查缓存,然后在必要时从源检索。 该代码还负责处理转换查询的参数,例如,按域过滤或截断响应。 这是一个美丽而简单的模型,全部包含在一个 worker 和一个非常简单的源 API 中。 但有一个问题——当数据发生变化时会发生什么?
有两个事件可以更改缓存的数据,一个是简单的,一个是主要的:
- 有人选择退出公共搜索,并且需要删除其电子邮件地址。 这很简单,我们只需在 Cloudflare 调用一个 API 并刷新单个哈希前缀。
- 加载新的数据泄露事件,并且大量哈希前缀发生更改。 在这种情况下,我们刷新整个缓存并从头开始重新填充它。
第二点有点令人沮丧,因为我们已经构建了这个漂亮的数据集合,这些数据都靠近消费者,可以非常快速地查询,然后我们将其全部删除并从头开始。 问题在于,要么这样做,要么我们有选择地清除可能数百万个单独的哈希前缀,这是你做不到的:
对于企业计划中的区域,您可以在一个 API 调用中清除最多 500 个 URL。
而且:
Cache-Tag、主机和前缀清除在每个 24 小时周期内都有 30,000 个清除 API 调用的速率限制。
我们正在进一步思考所有这些,但这是一个重要的问题,并且完全刷新缓存既简单又(几乎)瞬间完成。
说够了,让我们来看一些图片! 这是企业 k-匿名性 API 的典型一周查询:
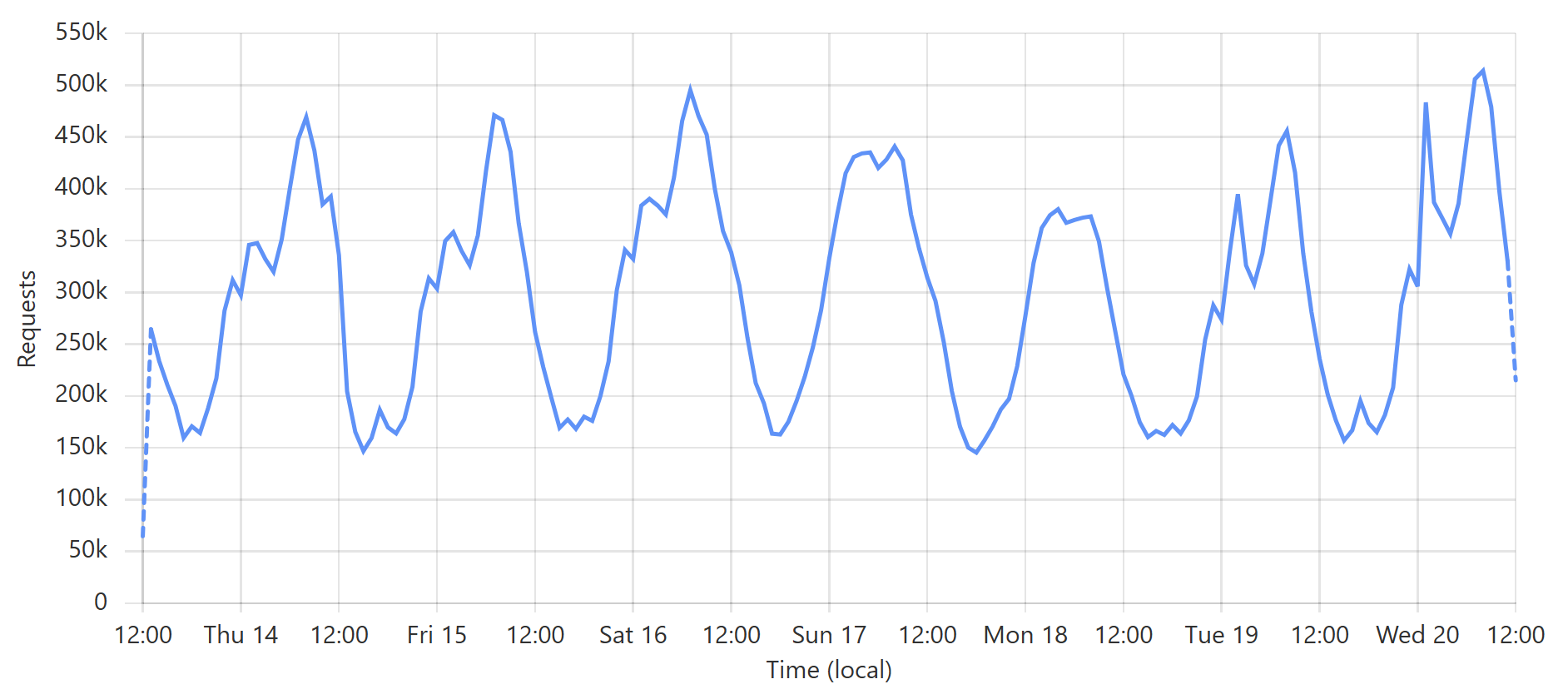
这是一个 非常 可预测的模式,主要是由于一个特定的订阅者每天定期查询其整个客户群。(附注:我们的大多数企业级订阅者都使用回调,以便在新泄露事件影响其客户时,我们通过 Webhook 将更新推送给他们。) 这是入站请求的总量,但真正有趣的是命中源站的请求(蓝色)与直接由 Cloudflare 提供服务的请求(橙色):
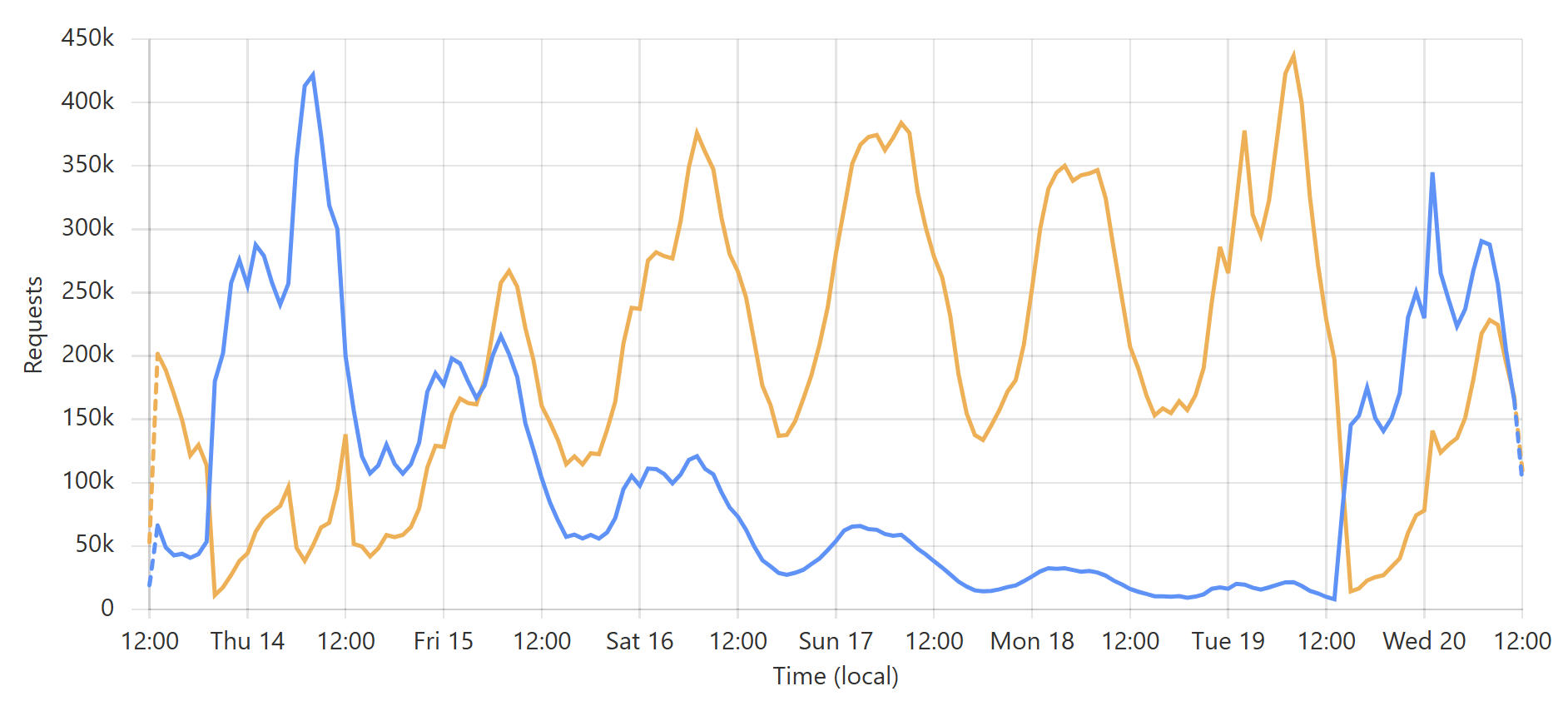
让我们以图表末尾最低的蓝色数据点为例:
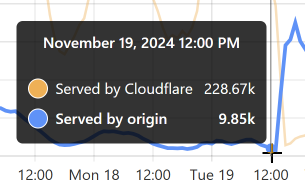
当时,96% 的请求来自 Cloudflare 的边缘。 太棒了! 但稍后看一下:
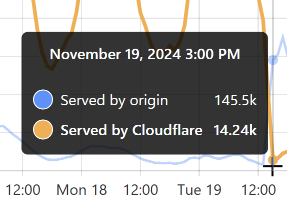
那是我为 Finsure 泄露事件 刷新缓存的时候,并且 100% 的流量开始被定向到源站。(我们仍然通过 Cloudflare 看到 14.24k 次点击,因为不可避免的是,该 1 小时块中的一些请求与相同的哈希范围相关,并从缓存中提供。) 然后,缓存花了整整 20 个小时才重新填充到命中:未命中率恢复到大约 50:50 的程度:
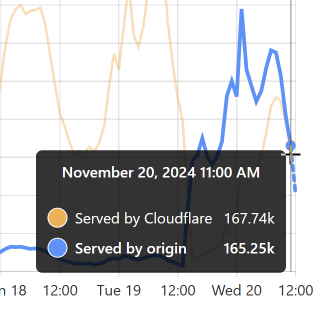
回头看看图表的开头,你可以看到我加载 DemandScience 泄露事件 时的相同模式。 所有这些都对我们的源 API 产生了非常奇怪的影响:
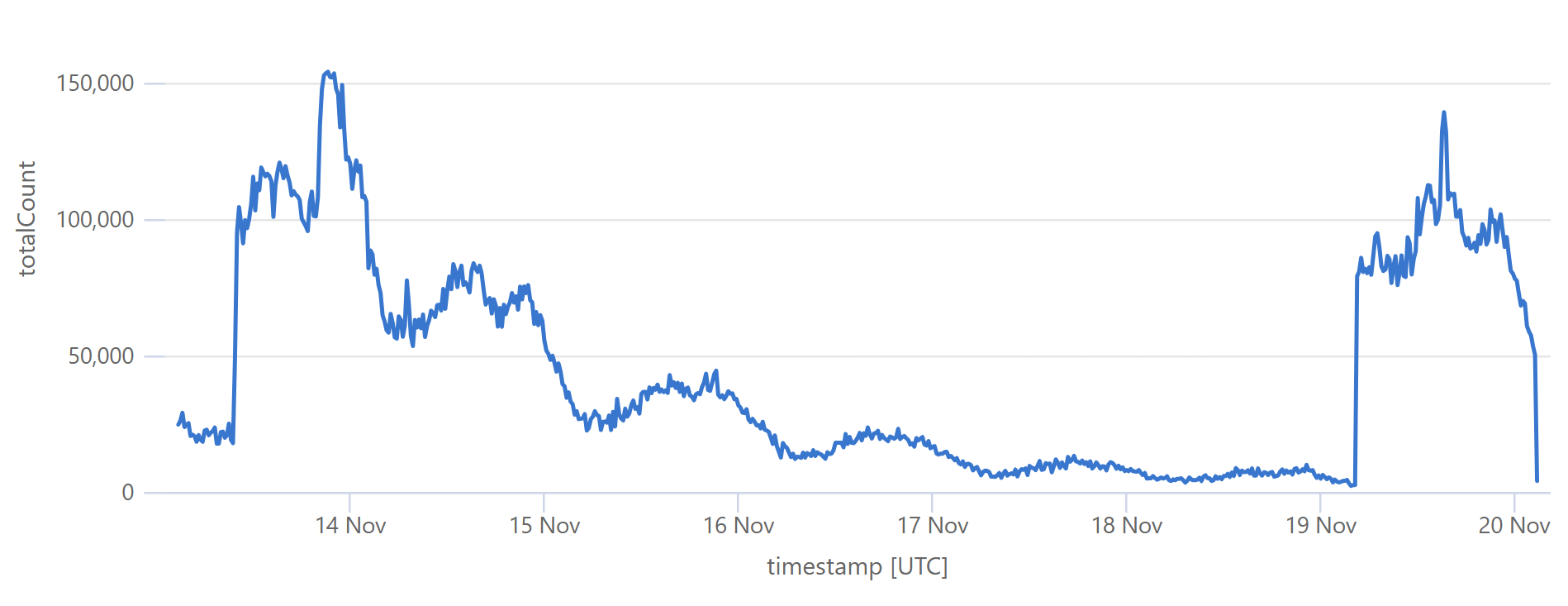
最后一次突然增加是流量在瞬间增加了 30 倍以上! 如果我们没有小心管理源基础设施,我们就会构建一台真正的 DDoS 机器。 Stefán 稍后将介绍我们如何管理底层数据库以确保不会发生这种情况,但即便如此,当我们处理上面第一个图表中看到的周期性支持模式时,我知道加载泄露事件的最佳时间是澳大利亚下午晚些时候,那时流量是早上第一件事时的三分之一。 这有助于平滑到源站的请求速率,这样当流量增加时,更多的内容可以直接从 Cloudflare 返回。 你可以在上面的图表中看到这一点; 最后一个图表中那个大的峰值块非常稳定,即使第一个图表在同一时期内的入站流量显着增加。 这就像我们试图通过在缓存中构建一个错误来与不断增加的入站流量竞争。
这是整个事情的另一个角度:现在比以往任何时候都更加,加载数据泄露事件会花费我们的钱。 例如,到上面图表的结尾时,我们的缓存命中率达到了 50%,这意味着我们只需支付 Azure Function 执行、出口带宽和底层 SQL 数据库的一半费用,否则我们需要支付所有费用。 刷新缓存并突然将所有流量发送到源站会使我们的成本翻倍。 等待我们回到 90% 的缓存命中率时,刷新缓存会使这些成本增加 10 倍。 如果我从财务角度完全无情地考虑这个问题,我需要加载更少的泄露事件或将它们批量组合在一起,这样刷新缓存只会清除少量数据,但显然,我没有这样做 😄
还剩下最后一个缺点...
在查询电子邮件地址的三种方法中,第一种方法是不费吹灰之力的:来自网站首页的搜索会命中 Cloudflare Worker,在其中验证 Turnstile 令牌并返回结果。 容易。 但是,第二种模型(公共 API 和企业 API)增加了针对 Azure API Management (APIM) 验证 API 密钥的负担,而它唯一存在的地方是 West US 源服务。 对于这些端点,这意味着在我们从可能距离我们只有一小段水上摩托艇路程的位置返回搜索结果之前,我们需要前往世界另一端来验证密钥并确保请求在速率限制范围内。 我们以尽可能轻量级的方式执行此操作,几乎没有数据通过请求来检查密钥,而且我们以异步方式执行此操作,如果数据尚未缓存在缓存中,则从源服务中拉回数据。 换句话说,我们尽可能高效,但我们仍然承担着巨大的延迟负担。
在源站进行 API 管理非常令人沮丧,但实际上只有两种替代方案。 第一种是将我们的 APIM 实例分发到其他 Azure 数据中心,而问题在于我们需要该产品的 Premium 实例。 我们目前在 Basic 实例上运行,这意味着仅解锁该功能,价格就上涨了 19 倍。 但那只是升级到 Premium; 然后我们需要至少在其他地方再创建一个实例,这样才有意义,这意味着价格上涨了 28 倍。 而且我们添加的每个区域都会进一步放大这一点。 这在财务上是不可行的。
第二种选择是让 Cloudflare 构建一个 API 管理产品。 这 是这个难题的关键部分,因为它会将所有检查和平衡都放在一个边缘节点中。 这是我现在已经多次提出的建议,谁知道呢,也许它已经在开发中了,但我提出这个建议是出于对该公司所做工作的热爱以及希望完全依靠他们来控制我们的流量流的愿望。 我本周确实收到了一条关于在 worker 中推出实际上是“穷人的 API 管理”的建议,这是一个非常酷的建议,但当人们更改计划或当我们想将配额应用于 API 而不是速率限制时,它就会变得困难。 所以加油,Cloudflare,让我们实现它吧!
最后,再提供一个关于直接从边缘提供内容是多么强大的统计数据:我上个月分享了 Pwned Passwords 的这个统计数据,它从 Cloudflare 的缓存储备中提供了超过 99% 的请求:
就是这样——我们现在在 30 天内对 Pwned Password 发出了 10,000,000,000 次请求 😮 在 @Cloudflare 的支持下,大规模边缘缓存数据,使其超级快速且高度可用,这成为可能。 pic.twitter.com/kw3C9gsHmB — Troy Hunt (@troyhunt) 2024 年 10 月 5 日
平均而言,这大约是每秒 3,900 个请求,连续 30 天不停歇。 显然,在高峰期,它的速度要快得多; 快速浏览一下过去一个月,似乎在几周前的一分钟内大约有 17k 个请求:
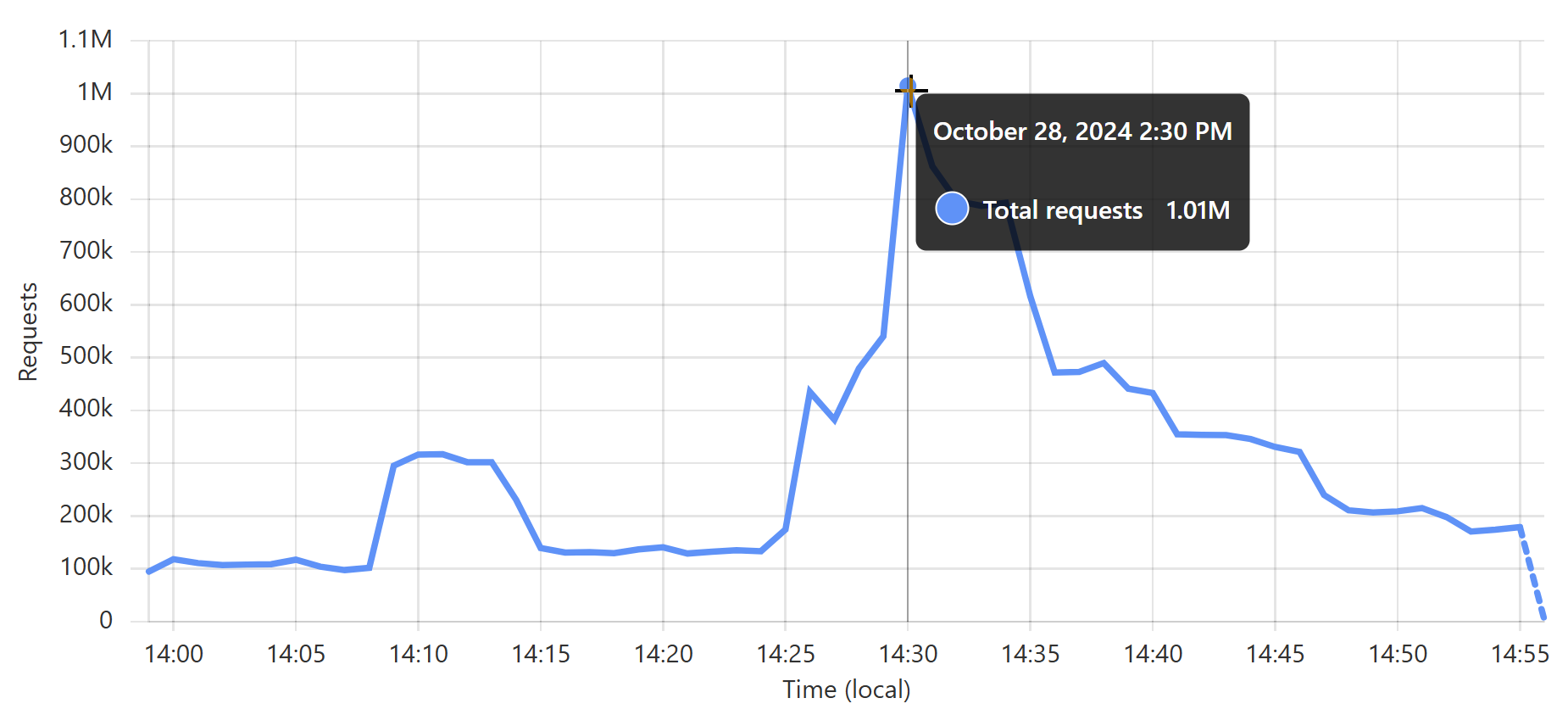
但这并不重要,因为它有多高并不重要,因为我甚至从未考虑过它。 我设置了 worker,我打开了缓存储备,就是这样😎
希望你喜欢这篇文章,Stefán 和我将在 AEST 星期五早上 06:00 直播这个话题,这是本周的定期视频更新,并且将在之后立即提供重播。 为了方便起见,它也嵌入在此处: