FontDiffuser:基于去噪扩散的文本到字体生成
FontDiffuser:通过去噪扩散和多尺度内容聚合以及风格对比学习实现的 One-Shot 字体生成
Zhenhua Yang1, Dezhi Peng1, Yuxin Kong1, Yuyi Zhang1, Cong Yao3, Lianwen Jin12*
1South China University of Technology, 2SCUT-Zhuhai Institute of Modern Industrial Innovation, 3Alibaba Group
Paper Code Demo
![]()


摘要
自动字体生成是一项模仿任务,旨在创建模仿参考图像风格的字体库,同时保留源图像的内容。虽然现有的字体生成方法已经取得了令人满意的性能,但它们仍然难以处理复杂的字符和较大的风格变化。为了解决这些问题,我们提出了 FontDiffuser,一种基于扩散的图像到图像的 one-shot 字体生成方法,它创新地将字体模仿任务建模为噪声到去噪的范例。在我们的方法中,我们引入了一个多尺度内容聚合 (Multi-scale Content Aggregation, MCA) 块,它有效地结合了跨不同尺度的全局和局部内容线索,从而增强了复杂字符的复杂笔画的保留。此外,为了更好地管理风格转移中的大型变化,我们提出了一个风格对比细化 (Style Contrastive Refinement, SCR) 模块,这是一种用于风格表示学习的新颖结构。它利用风格提取器从图像中解耦风格,随后通过精心设计的风格对比损失来监督扩散模型。大量实验表明 FontDiffuser 在生成不同的字符和风格方面具有最先进的性能。与以前的方法相比,它在复杂字符和大型风格变化方面始终表现出色。
动机

- 任务定义:字体生成是一项模仿任务,旨在创建模仿参考图像风格的字体库,同时保留源图像的内容。
- 现有问题:现有的字体生成方法已经取得了令人满意的性能,但它们仍然难以处理复杂字符和较大的风格变化,导致严重的笔画缺失、伪影、模糊、布局错误和风格不一致,如上图所示。
- 原因分析:(1) 大多数方法采用基于 GAN 的框架,由于其对抗性训练性质,可能会受到不稳定训练的影响。(2) 这些方法中的大多数仅通过单尺度的高级特征来感知内容信息,忽略了对于保留源内容至关重要的细粒度细节,特别是对于复杂字符。(3) 许多方法采用先验知识来促进字体生成,例如字符的笔画或组件组成;但是,对于复杂字符,此信息的注释成本很高。(4) 在以前的文献中,目标风格通常由一个简单的分类器或鉴别器来表示,这很难学习合适的风格,并且阻碍了具有较大变化的风格转移。
- 策略:FontDiffuser 是一种基于扩散的图像到图像的 one-shot 字体生成方法,它将字体生成学习建模为噪声到去噪的范例,并且能够生成未见过的字符和风格。(1) 我们引入了一个多尺度内容聚合 (MCA) 块,它利用跨各种尺度的全局和局部内容特征。(2) 我们引入了一种新颖的风格表示学习策略,通过应用风格对比细化 (SCR) 模块来增强生成器在模仿风格方面的能力。
框架
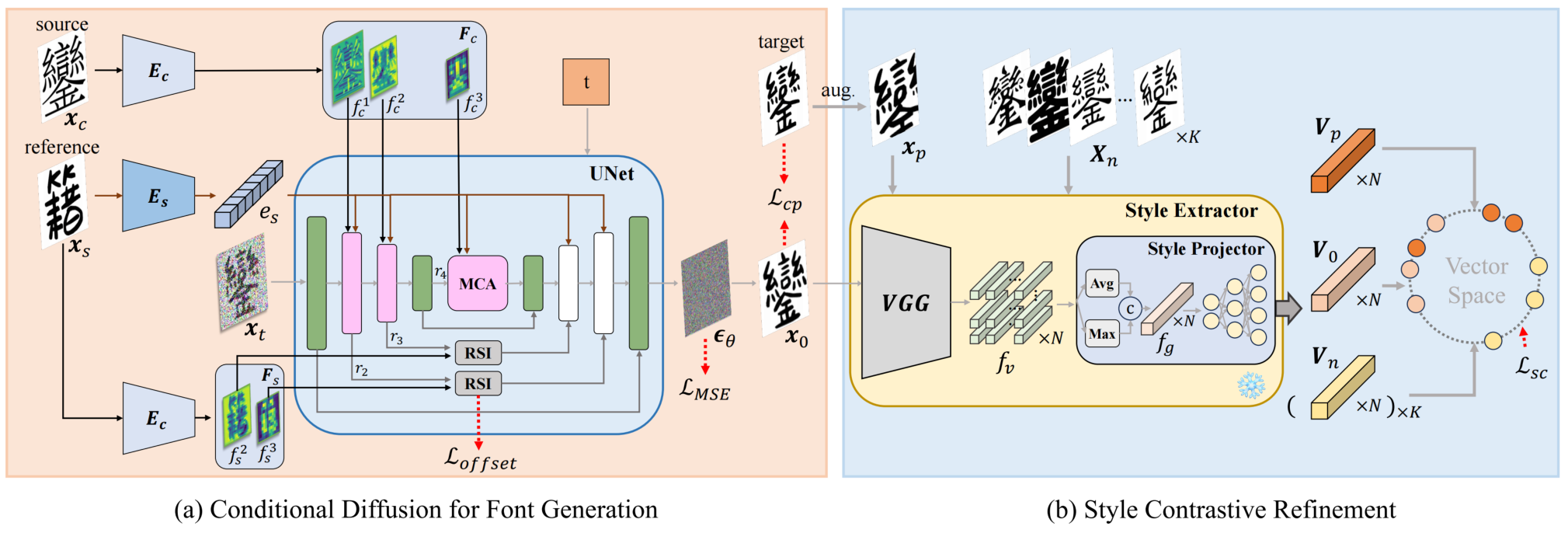
我们提出的方法的概述。(a) 条件扩散模型是一个基于 UNet 的网络,由内容编码器 Ec 和风格编码器 Es 组成。参考图像 Xs 分别通过风格编码器 Es 和内容编码器 Ec,获得风格嵌入 e 和结构图 Fs。源图像由内容编码器 Ec 编码。为了获得多尺度特征 Fc,我们从 Ec 的不同层导出输出,并通过我们提出的 MCA 块注入它们。RSI 块用于对参考结构特征 Fs 进行空间变形。(b) 风格对比细化模块用于从图像中解耦不同的风格,并为扩散模型提供指导。
实验
定量结果
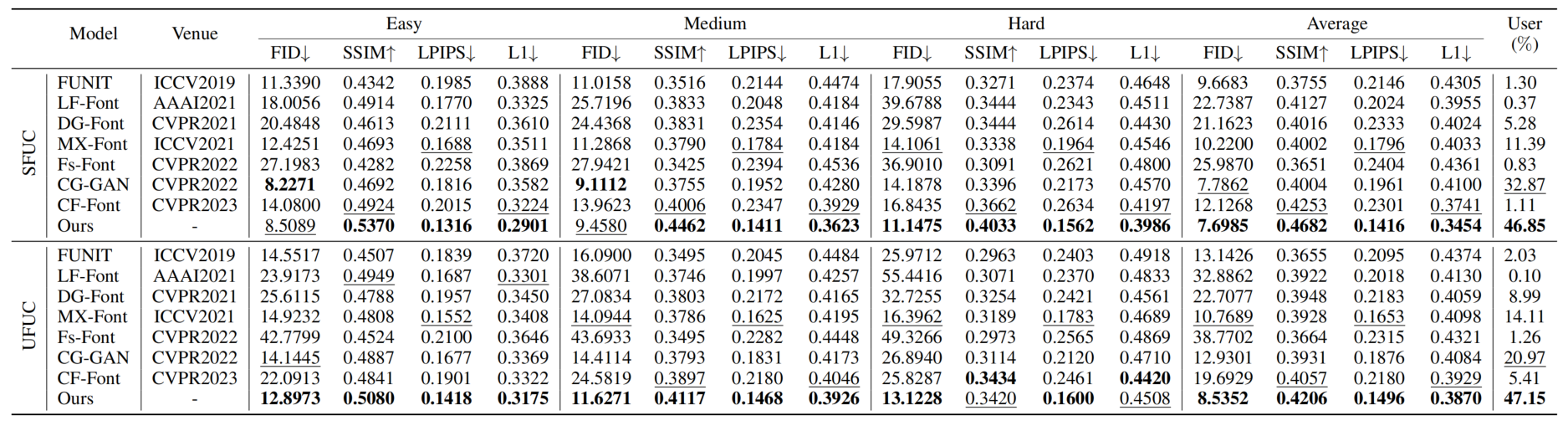
定性比较
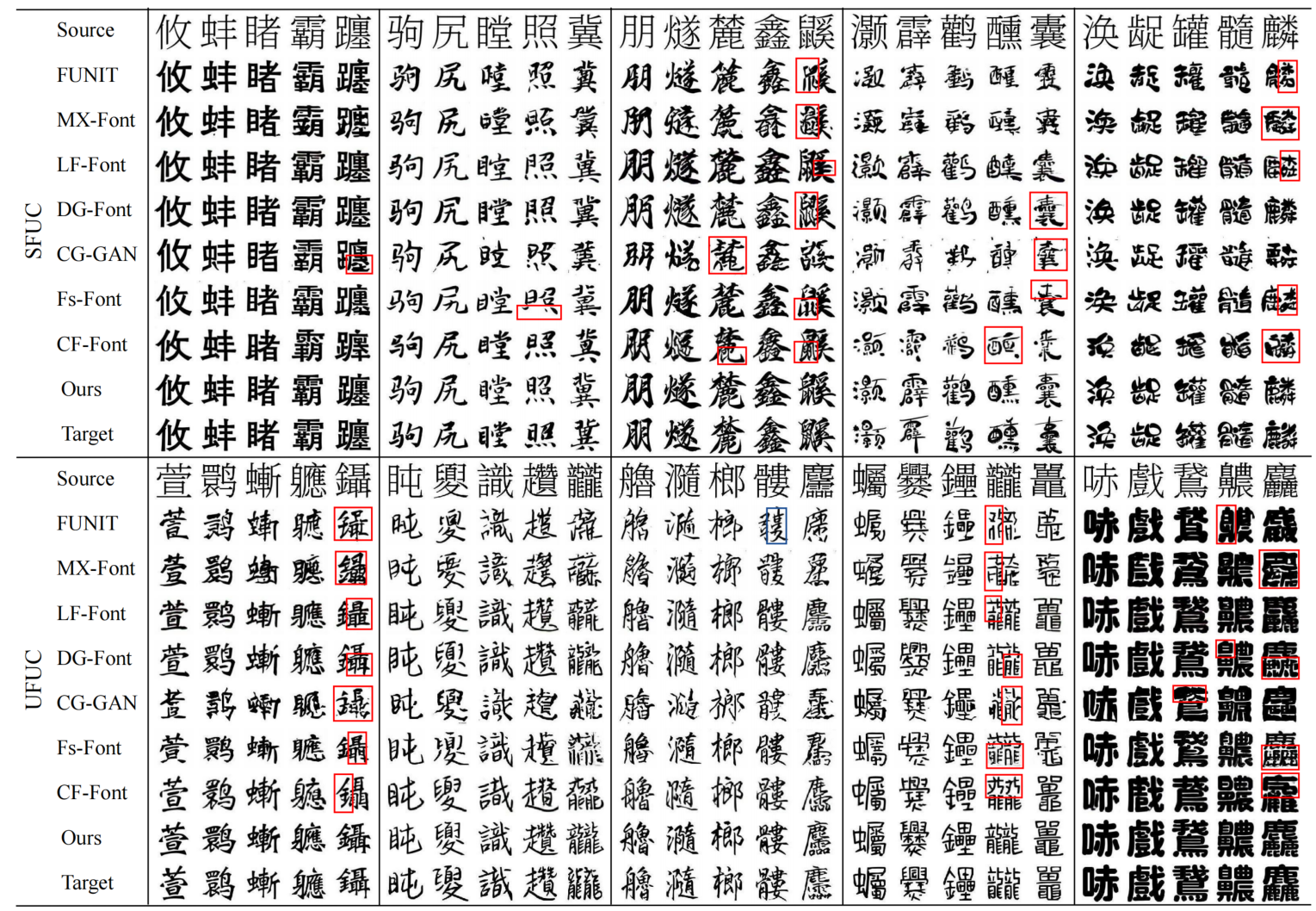
更多可视化
难度级别高的字符

难度级别中等的字符

难度级别简单的字符

跨语言生成可视化(中文到韩语)

联系方式
对于使用 FontDiffuser 时遇到的问题,请发送电子邮件至 Zhenhua Yang (eezhyang@gmail.com)。对于商业用途,请联系 Lianwen Jin 教授 (eelwjin@scut.edu.cn)。
版权
- 此存储库只能用于非商业研究目的。
- 对于商业用途,请联系 Lianwen Jin 教授 (eelwjin@scut.edu.cn)。
- 版权所有 2023,华南理工大学 Learning and Vision Computing Lab (DLVC-Lab)。
BibTeX
@inproceedings{yang2024fontdiffuser,
title={FontDiffuser: One-Shot Font Generation via Denoising Diffusion with Multi-Scale Content Aggregation and Style Contrastive Learning},
author={Yang, Zhenhua and Peng, Dezhi and Kong, Yuxin and Zhang, Yuyi and Yao, Cong and Jin, Lianwen},
booktitle={Proceedings of the AAAI conference on artificial intelligence},
year={2024}
}
本网站已获得 Creative Commons Attribution-ShareAlike 4.0 International License 许可。