SIMD ISA 的三个根本缺陷 (2023)
Bits'n'Bites
一点一滴地学习...
Marcus Geelnard,2021年8月9日,2023年5月31日更新
SIMD ISA 的三个根本缺陷
根据 Flynn 的分类法,SIMD 指的是一种计算机架构,它可以使用单个指令处理多个数据流(即“单指令流,多数据流”)。 存在不同的分类法,并且在这些分类法中,有几个不同的子类别和架构可以归类为“SIMD”。
但是,在本文中,我指的是 packed SIMD ISA,即在当今消费级 CPU 中最常见的 SIMD 指令集架构类型。 更具体地说,我指的是非谓词 packed SIMD ISA,其中 packed SIMD 处理的细节暴露给软件环境。
Packed SIMD
packed SIMD 架构的共同特征是,多个数据元素被打包到固定宽度的单个寄存器中。 这是一个 128 位宽 SIMD 寄存器的可能配置示例:
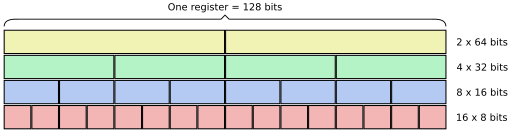
例如,一个 128 位寄存器可以容纳 16 个整数字节或 4 个单精度浮点值。
自 1990 年代中期以来,这种类型的 SIMD 架构一直非常流行,一些 packed SIMD ISA 包括:
- x86: MMX, 3DNow!, SSE, SSE2, …, 和 AVX, AVX2, AVX-512
- ARM: ARMv6 SIMD, NEON
- POWER: AltiVec (又名 VMX 和 VelocityEngine)
- MIPS: MDMX, MIPS-3D, MSA, DSP
- SPARC: VIS
- Alpha: MVI
1 AVX 和更新的 x86 SIMD ISA(尤其是 AVX-512)结合了来自向量处理的功能,使它们成为 packed SIMD / 向量处理混合体(因此本文中讨论的某些方面并不完全适用)。
所有这些 ISA 都承诺提高数据处理性能,因为每条指令都并行执行多个操作。 但是,此模型存在问题。
缺陷 1:固定的寄存器宽度
由于寄存器大小是固定的,因此如果没有添加新的指令和寄存器,就无法将 ISA 扩展到新的硬件并行级别。 例如:MMX(64 位)与 SSE(128 位)与 AVX(256 位)与 AVX-512(512 位)。
添加新的寄存器和指令会产生许多影响。 例如,必须更新 ABI,并且必须将支持添加到操作系统内核、编译器和调试器。
另一个问题是,每个新的 SIMD 世代都需要新的指令操作码和编码。 在固定宽度指令集(例如 ARM)中,这可能会阻止任何新的扩展,因为可能没有足够的指令代码槽来添加新指令。 在可变宽度指令集(例如 x86)中,效果通常是指令变得越来越长(有效地损害了代码密度)。 矛盾的是,每个新的 SIMD 世代实际上都使前几代变得多余(除了支持二进制向后兼容性之外),因此浪费了大量指令而没有增加太多价值。
最后,任何想要使用新指令集的软件都需要重写(或至少重新编译)。 更糟糕的是,软件开发人员通常必须针对多个 SIMD 世代,并在其程序中添加机制,以根据支持的 SIMD 世代动态选择最佳代码路径。
缺陷 2:流水线
packed SIMD 的范例是寄存器宽度和执行单元宽度之间存在 1:1 的映射(这通常是对于混合来自多个通道的输入的指令实现合理性能所必需的)。 同时,许多 SIMD 操作都是流水线的,需要多个时钟周期才能完成(例如,浮点运算和内存加载指令)。 这样做的副作用是,一个 SIMD 指令的结果直到指令流中的几个指令之后才能使用。
因此,必须展开循环,以避免停顿并保持流水线繁忙。 这可以在具有寄存器重命名和推测性乱序执行的高级(耗电)硬件实现中完成,但是对于更简单(通常更节能)的硬件实现,必须在软件中展开循环。 许多旨在同时支持按顺序和乱序处理器的软件开发人员和编译器只是在软件中展开所有 SIMD 循环。
但是,循环展开会损害代码密度(即使程序二进制文件更大),这反过来又损害了指令缓存性能(更少的程序段适合指令缓存,从而降低了缓存命中率)。
循环展开还会增加寄存器压力(即,必须使用更多寄存器才能将多个循环迭代的状态保存在寄存器中),因此该架构必须提供足够的 SIMD 寄存器以避免寄存器溢出。
缺陷 3:尾部处理
当要在循环中处理的数组元素的数量不是 SIMD 寄存器中元素数量的倍数时,需要在软件中实现特殊的循环尾部处理。 例如,如果一个数组包含 99 个 32 位元素,并且 SIMD 架构是 128 位宽(即,一个 SIMD 寄存器包含四个 32 位元素),则可以在主 SIMD 循环中处理 4*24=96 个元素,并且需要在主循环之后处理 99-96=3 个元素。
这需要在循环之后添加额外的代码来处理尾部。 某些架构支持掩码加载/存储,这使得可以使用 SIMD 指令来处理尾部,而更常见的方案是,您必须使用标量(非 SIMD)指令来实现尾部(在后一种情况下,如果标量和 SIMD 指令具有不同的功能和/或语义,则可能会出现问题,但这本身并不是 packed SIMD 的问题,而只是某些 ISA 的设计方式的问题)。
通常,您还需要在循环之前添加额外的控制逻辑。 例如,如果数组长度小于 SIMD 寄存器宽度,则应跳过主 SIMD 循环。
添加的控制逻辑和尾部处理代码会损害代码密度(再次降低指令缓存效率),并增加额外的开销(并且通常难以编码)。
替代方案
解决上述所有缺陷的 packed SIMD 的一种替代方案是向量处理器。 也许最著名的向量处理器是 Cray-1(于 1975 年发布),它已成为新一代指令集架构的灵感来源,包括 RISC-V RVV。
其他几个(可能不太为人所知)的项目也在追求类似的向量模型,包括 Agner Fog 的 ForwardCom、Robert Finch 的 Thor2021 和我自己的 MRISC32。 一个有趣的变体是 Libre-SOC(基于 OpenPOWER)及其 Simple-V 扩展,该扩展将向量映射到标量寄存器文件(这些文件被扩展为包括每个 128 个寄存器)。
ARM SVE 是一种以谓词为中心的、与向量长度无关的 ISA,它可以解决许多传统的 SIMD 问题。
Mitch Alsup 的 My 66000 及其虚拟向量方法 (VVM) 采用了完全不同的方法,它借助特殊的循环修饰指令在硬件中将标量循环转换为向量化循环。 这样,它甚至不必具有向量寄存器文件。
另一个有趣的架构是 Mill,它也支持向量,而没有 packed SIMD。
示例
编辑:此部分于 2021-08-19 添加,以提供一些代码示例,这些示例显示了 packed SIMD 与其他替代方案之间的区别,并于 2023-05-31 扩展,增加了 RISC-V RVV 和 ARM SVE 示例以及更多注释。
BLAS 中的一个简单例程是 saxpy,它计算 z = a*x + y,其中 a 是一个常数,x 和 y 是数组,“saxpy”中的“s”代表单精度浮点数。
// saxpy 的 C 实现示例:
void saxpy(size_t n, float a, float* x, float* y, float* z)
{
for (size_t i = 0; i < n ; i++)
z[i] = a * x[i] + y[i];
}
以下是汇编代码片段,用于为不同的 ISA 实现 saxpy。
Packed SIMD (x86_64 / SSE)
saxpy:
test rdi, rdi
je .done
cmp rdi, 8
jae .at_least_8
xor r8d, r8d
jmp .tail_2_loop
.at_least_8:
mov r8, rdi
and r8, -8
movaps xmm1, xmm0
shufps xmm1, xmm0, 0
lea rax, [r8 - 8]
mov r9, rax
shr r9, 3
add r9, 1
test rax, rax
je .dont_unroll
mov r10, r9
and r10, -2
neg r10
xor eax, eax
.main_loop:
movups xmm2, xmmword ptr [rsi + 4*rax]
movups xmm3, xmmword ptr [rsi + 4*rax + 16]
mulps xmm2, xmm1
mulps xmm3, xmm1
movups xmm4, xmmword ptr [rdx + 4*rax]
addps xmm4, xmm2
movups xmm2, xmmword ptr [rdx + 4*rax + 16]
addps xmm2, xmm3
movups xmmword ptr [rcx + 4*rax], xmm4
movups xmmword ptr [rcx + 4*rax + 16], xmm2
movups xmm2, xmmword ptr [rsi + 4*rax + 32]
movups xmm3, xmmword ptr [rsi + 4*rax + 48]
mulps xmm2, xmm1
mulps xmm3, xmm1
movups xmm4, xmmword ptr [rdx + 4*rax + 32]
addps xmm4, xmm2
movups xmm2, xmmword ptr [rdx + 4*rax + 48]
addps xmm2, xmm3
movups xmmword ptr [rcx + 4*rax + 32], xmm4
movups xmmword ptr [rcx + 4*rax + 48], xmm2
add rax, 16
add r10, 2
jne .main_loop
test r9b, 1
je .tail_2
.tail_1:
movups xmm2, xmmword ptr [rsi + 4*rax]
movups xmm3, xmmword ptr [rsi + 4*rax + 16]
mulps xmm2, xmm1
mulps xmm3, xmm1
movups xmm1, xmmword ptr [rdx + 4*rax]
addps xmm1, xmm2
movups xmm2, xmmword ptr [rdx + 4*rax + 16]
addps xmm2, xmm3
movups xmmword ptr [rcx + 4*rax], xmm1
movups xmmword ptr [rcx + 4*rax + 16], xmm2
.tail_2:
cmp r8, rdi
je .done
.tail_2_loop:
movss xmm1, dword ptr [rsi + 4*r8]
mulss xmm1, xmm0
addss xmm1, dword ptr [rdx + 4*r8]
movss dword ptr [rcx + 4*r8], xmm1
add r8, 1
cmp rdi, r8
jne .tail_2_loop
.done:
ret
.dont_unroll:
xor eax, eax
test r9b, 1
jne .tail_1
jmp .tail_2
请注意,packed SIMD 代码包含一个 4x 展开版本的主 SIMD 循环和一个标量尾部循环。 它还包含一个设置阶段(前 20 条指令),对于长数组来说,这不会对性能产生巨大的影响,但对于短数组来说,设置代码会增加不必要的开销。
不幸的是,这种手动设置 + 展开 + 尾部处理代码占用了 CPU 内核中不必要的大量指令缓存。
这演示了上面描述的缺陷 2 和 3。 缺陷 1 实际上也存在,因为您需要多个实现才能在所有 CPU 上获得最佳性能。 例如,除了上面的 SSE 实现之外,您还需要 AVX2 和 AVX-512 实现,并根据 CPU 功能在运行时在它们之间切换。
向量 (MRISC32)
saxpy:
bz r1, 2f ; 没有什么可做的?
getsr vl, #0x10 ; 查询最大向量长度
1:
minu vl, vl, r1 ; 定义操作向量长度
sub r1, r1, vl ; 递减循环计数器
ldw v1, [r3, #4] ; 加载 x[](元素步幅 = 4 字节)
ldw v2, [r4, #4] ; 加载 y[]
fmul v1, v1, r2 ; x[] * a
fadd v1, v1, v2 ; + y[]
stw v1, [r5, #4] ; 存储 z[]
ldea r3, [r3, vl*4] ; 递增 x 指针
ldea r4, [r4, vl*4] ; 递增 y 指针
ldea r5, [r5, vl*4] ; 递增 z 指针
bnz r1, 1b
2:
ret
与 packed SIMD 版本不同,向量版本更加紧凑,因为它在硬件中处理展开和尾部。 此外,设置代码是最小的(仅 1-2 条指令)。
GETSR 指令用于查询实现定义的最大向量长度(即向量寄存器可以容纳的 32 位元素的数量)。 VL 寄存器定义向量操作的向量长度(要处理的元素数量)。 在最后一次迭代期间,VL 可能小于最大向量长度,这将处理尾部。
加载和存储指令采用“字节步幅”参数,该参数定义每个向量元素之间的地址增量,因此在这种情况下(步幅 = 4 字节),我们加载/存储连续的单精度浮点值。 FMUL 和 FADD 指令分别对每个向量元素进行操作(并行或串行,取决于硬件实现)。
向量 (RISC-V V 扩展)
代码和注释由 Bruce Hoult 慷慨提供:
saxpy:
vsetvli a4, a0, e32,m8, ta,ma // 获取向量长度(以项为单位),最大为 n
vle32.v v0, (a1) // 从 x[] 加载
vle32.v v8, (a2) // 从 y[] 加载
vfmacc.vf v8, fa0, v0 // y[] += a * x[]
vse32.v v8, (a3) // 存储到 z[]
sub a0, a0, a4 // 递减项计数
sh2add a1, a4, a1 // 递增 x 指针
sh2add a2, a4, a2 // 递增 y 指针
sh2add a3, a4, a3 // 递增 z 指针
bnez a0, saxpy
ret
与向量长度无关的 RISC-V 向量 ISA 能够实现比 packed SIMD 更高效的代码和更小的代码占用空间,就像 MRISC32 一样。 RISC-V 还有一个融合乘加指令 (VFMACC),可以进一步缩短代码(计划将来将 FMA 添加到 MRISC32 ISA 中)。
关于示例中 VSETVLI(设置向量长度)的使用的几点说明:
- e32,m8 表示 32 位数据项,一次使用 8 个向量寄存器,例如 v0-v7、v8-v15,有效地通过 8 倍硬件展开,并使用 128 位向量寄存器一次处理 32 个项。 最后一次迭代可以处理 1 到 32 个项中的任何一个(如果 n 为 0,则为 0)。
- ta,ma 表示我们不关心如何处理掩码掉的元素(我们没有使用掩码),也不关心如何在最后一次迭代中处理未使用的尾部元素。
该代码实际上可以正确处理 n=0(空数组),因此除非我们希望这种情况非常常见,否则专门处理它并用一条指令减慢其他所有操作的速度是很愚蠢的。
谓词 SIMD (ARM SVE)
saxpy:
mov x4, xzr // 设置起始索引 = 0
dup z0.s, z0.s[0] // 将标量 a 转换为向量
1:
whilelo p0.s, x4, x0 // 设置谓词 [index, n)
ld1w z1.s, p0/z, [x1, x4, lsl 2] // 加载 x[] (谓词)
ld1w z2.s, p0/z, [x2, x4, lsl 2] // 加载 y[] (谓词)
fmla z2.s, p0/m, z0.s, z1.s // y[] += a * x[] (谓词)
st1w z2.s, p0, [x3, x4, lsl 2] // 存储 z[] (谓词)
incw x4 // 递增起始索引
b.first 1b // 如果 p0 的第一位已设置,则循环
ret
可以看出,具有适当谓词/掩码支持的 SIMD ISA 可以轻松地在硬件中进行尾部处理,因此该代码与向量处理器的代码非常相似。 关键是谓词寄存器 (p0) 的使用,该寄存器使用 WHILELO 指令初始化为二进制真/假掩码,然后用于所有向量操作以掩盖不应成为当前迭代一部分的向量元素(实际上仅在最后一次迭代中发生,这将处理尾部)。
另请注意代码如何与寄存器宽度无关(WHILELO 和 INCW 可以为您处理)。
虚拟向量方法 (My 66000)
saxpy:
beq0 r1,1f ; 没有什么可做的?
mov r8,#0 ; 循环计数器 = 0
vec r9,{} ; 启动向量循环
lduw r6,[r3+r8<<2] ; 加载 x[]
lduw r7,[r4+r8<<2] ; 加载 y[]
fmacf r6,r6,r2,r7 ; x[] * a + y[]
stw r6,[r5+r8<<2] ; 存储 z[]
loop ne,r8,r1,#1 ; 递增计数器和循环
1:
ret
虚拟向量方法 (VVM) 是 Mitch Alsup 发明的一种新技术,它允许在没有向量寄存器文件的情况下进行向量化。 正如您在此示例中看到的那样,仅使用了标量指令和对标量寄存器名称(“r * “)的引用。 这里的关键参与者是 VEC 和 LOOP 指令,它们将标量循环转换为向量循环。
本质上,VEC 指令标记了向量化循环的顶部(r9 存储循环开始的地址,该地址由 LOOP 指令隐式使用)。 VEC 和 LOOP 之间的所有指令都经过一次解码和分析,然后在硬件的功能下执行。 在这种情况下,大多数寄存器标识符(r1、r3、r4、r5、r6、r7、r8)用作虚拟向量寄存器,而 r2 用作标量寄存器。 LOOP 指令将计数器递增 1,将其与 r1 进行比较,并只要满足条件(不等于 (“ne”))就重复循环。
延伸阅读
另请参阅:SIMD considered harmful (D. Patterson, A. Waterman, 2017)