Observability 2.0 和支持它的数据库
[正文内容]
加入我们的线上 Zoom 会议,时间为7月31日晚上8点(PDT),主题是使用一个时序数据库同时处理 Metrics 和 Logs 👉🏻 立即注册
Observability 2.0 和支持它的数据库
Observability 2.0 以“wide events”(宽事件)为中心,打破了 Metrics、Logs 和 Traces 之间的壁垒。本文概述了这种新范式的核心思想和技术挑战,并介绍了 GreptimeDB (一个原生的开源数据库,专为 wide events 设计) 如何为下一代 Observability 平台提供统一而高效的基础。
![]() Ning Sun, CTO, Greptime
Ning Sun, CTO, Greptime

Observability 2.0 是由 Honeycomb 的 Charity Majors 提出的概念,尽管她后来 对其命名表示保留 (后续)。
尽管其命名存在争议,但 Observability 2.0 代表着从 Observability 的基础“三大支柱”——Metrics、Logs 和 Traces 的演进,这三大支柱在近十年里一直占据着主导地位。相反,它强调单一数据源的范式,作为 Observability 的数据基础。这种方法优先考虑高基数、wide-event 数据集,而不是传统的孤立遥测数据,旨在更有效地应对现代系统的复杂性。
什么是 Observability 2.0 和 Wide Events
多年来,Observability 一直依赖于 Metrics、Logs 和 Traces 这三大支柱。这些支柱催生了无数的库、工具和标准——包括 OpenTelemetry,这是最成功的云原生项目之一,它完全建立在这个范式之上。然而,随着系统复杂性的增加,这种方法的局限性变得越来越明显。
传统 Observability 的缺点
- 数据孤岛:Metrics、Logs 和 Traces 通常是分开存储的,如果没有细致的管理,会导致数据不相关,甚至不一致。
- 预聚合的权衡:预聚合的 Metrics (counters, summaries, histograms) 最初的设计是为了通过牺牲粒度来降低存储成本和提高性能。然而,时序数据的刚性结构限制了上下文信息的深度,迫使团队生成数百万个不同的时序数据来捕获必要的细节。具有讽刺意味的是,这种做法现在导致了指数级更高的存储和计算成本——直接违背了该方法最初的目的。
- 非结构化 Logs:虽然 Logs 本身包含结构化数据,但提取含义需要密集的解析、索引和计算工作。
- 静态 instrumentation:工具依赖于预定义的查询和阈值,将检测限制在“已知已知”范围内。要调整 Observability 需要更改代码,使其与缓慢的软件开发周期保持一致。
- 冗余数据:相同的信息在 Metrics、Logs 和 Traces 中重复,浪费存储空间并增加开销。
Wide Events:Observability 2.0 的方法
Observability 2.0 通过采用 wide events 作为其基础数据结构来解决这些问题。它不预先计算 Metrics 或结构化 Logs,而是将原始的、高保真的事件数据保存为单一的数据源。这使得团队能够追溯地执行探索性分析,从原始数据集中动态地派生出 Metrics、Logs 和 Traces。
Boris Tane 在 他的文章 Observability Wide Event 101 中,将 wide event 定义为上下文丰富、高维度和高基数的记录。例如,一个 wide event 可能包括:
{
"method": "POST",
"path": "/articles",
"service": "articles",
"outcome": "ok",
"status_code": 201,
"duration": 268,
"requestId": "8bfdf7ecdd485694",
"timestamp":"2024-09-08 06:14:05.680",
"message": "Article created",
"commit_hash": "690de31f245eb4f2160643e0dbb5304179a1cdd3",
"user": {
"id": "fdc4ddd4-8b30-4ee9-83aa-abd2e59e9603",
"activated": true,
"subscription": {
"id": "1aeb233c-1572-4f54-bd10-837c7d34b2d3",
"trial": true,
"plan": "free",
"expiration": "2024-09-16 14:16:37.980",
"created": "2024-08-16 14:16:37.980",
"updated": "2024-08-16 14:16:37.980"
},
"created": "2024-08-16 14:16:37.980",
"updated": "2024-08-16 14:16:37.980"
},
"article": {
"id": "f8d4d21c-f1fd-48b9-a4ce-285c263170cc",
"title": "Test Blog Post",
"ownerId": "fdc4ddd4-8b30-4ee9-83aa-abd2e59e9603",
"published": false,
"created": "2024-09-08 06:14:05.460",
"updated": "2024-09-08 06:14:05.460"
},
"db": {
"query": "INSERT INTO articles (id, title, content, owner_id, published, created, updated) VALUES ($1, $2, $3, $4, $5, $6, $7);",
"parameters": {
"$1": "f8d4d21c-f1fd-48b9-a4ce-285c263170cc",
"$2": "Test Blog Post",
"$3": "******",
"$4": "fdc4ddd4-8b30-4ee9-83aa-abd2e59e9603",
"$5": false,
"$6": "2024-09-08 06:14:05.460",
"$7": "2024-09-08 06:14:05.460"
}
},
"cache": {
"operation": "write",
"key": "f8d4d21c-f1fd-48b9-a4ce-285c263170cc",
"value": "{\"article\":{\"id\":\"f8d4d21c-f1fd-48b9-a4ce-285c263170cc\",\"title\":\"Test Blog Post\"..."
},
"headers": {
"accept-encoding": "gzip, br",
"cf-connecting-ip": "*****",
"connection": "Keep-Alive",
"content-length": "1963",
"content-type": "application/json",
"host": "website.com",
"url": "https://website.com/articles",
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36",
"Authorization": "********",
"x-forwarded-proto": "https",
"x-real-ip": "******"
}
}
Wide events 包含比传统结构化 Logs 显著更多的上下文数据,捕获了全面的应用程序状态细节。当存储在 Observability 数据存储中时,这些事件充当原始数据集,团队可以从中事后计算 任何常规 Metrics。例如:
- 特定 API 路径的 QPS(每秒查询数)。
- 按 HTTP 状态代码划分的响应率分布。
- 按用户区域或设备类型过滤的错误率。
此过程不需要更改代码——Metrics 是直接通过查询从原始事件数据派生的,无需预聚合或先前的 instrumentation。
有关实际实现,请参阅:
Observability 2.0 采用的挑战
传统的 Metrics 和 Logs 旨在优先考虑资源效率:最大限度地降低计算和存储成本。例如,Prometheus 采用半键值数据模型来优化时序存储,类似于早期的 NoSQL 时代:正如开发人员将关系数据库工作负载转移到 Redis(counters、sorted sets、lists)以提高速度和简化性一样,Observability 工具也采用了预聚合的 Metrics 和 Logs 来减少开销。
然而,与软件工程中向大数据转变类似,从“三大支柱”到 wide events 的转变反映了对原始、细粒度数据的日益增长的需求,而不是预先计算的摘要。这种转变带来了关键挑战:
- 事件生成:缺乏成熟的框架来 instrument 应用程序并发出标准化的、上下文丰富的 wide events。
- 数据传输:高效地流式传输高容量事件数据,而不会出现瓶颈或延迟。
- 经济高效的存储:经济地存储 TB 级的原始、高基数数据,同时保持查询性能。
- 查询灵活性:无需预定义模式,即可跨任意维度(例如,用户属性、请求路径)进行 ad-hoc 分析。
- 工具集成:通过从存储的事件追溯地派生 Metrics 和 Logs (而不是在应用程序层),来利用现有工具(例如,仪表板、警报)。
什么塑造了 Observability 2.0 的数据库
正如 Charity Majors 在她最近的 博客文章 中指出的那样,Observability 正在向数据湖模型演进。虽然 wide events 通过充当单一数据源来简化数据建模,但它们需要旨在解决先前概述的挑战的基础设施。
采用 Observability 2.0 旨在最大限度地提高原始数据的效用,而不会带来过高的复杂性。虽然在技术上可以使用以下方式拼凑出一个解决方案:
- 用于原始事件存储的 OLAP 数据库。
- 用于派生 Metrics/Traces 的预处理 pipelines。
- 用于仪表板的单独 Metrics 存储。
- 用于分布式跟踪 API 的 Trace 存储。
- 用于冷数据的备份系统。
……这种碎片化的方法破坏了 Observability 2.0 的核心承诺。相反,这种范式需要一个专门的数据库,针对其独特的工作负载进行了优化。
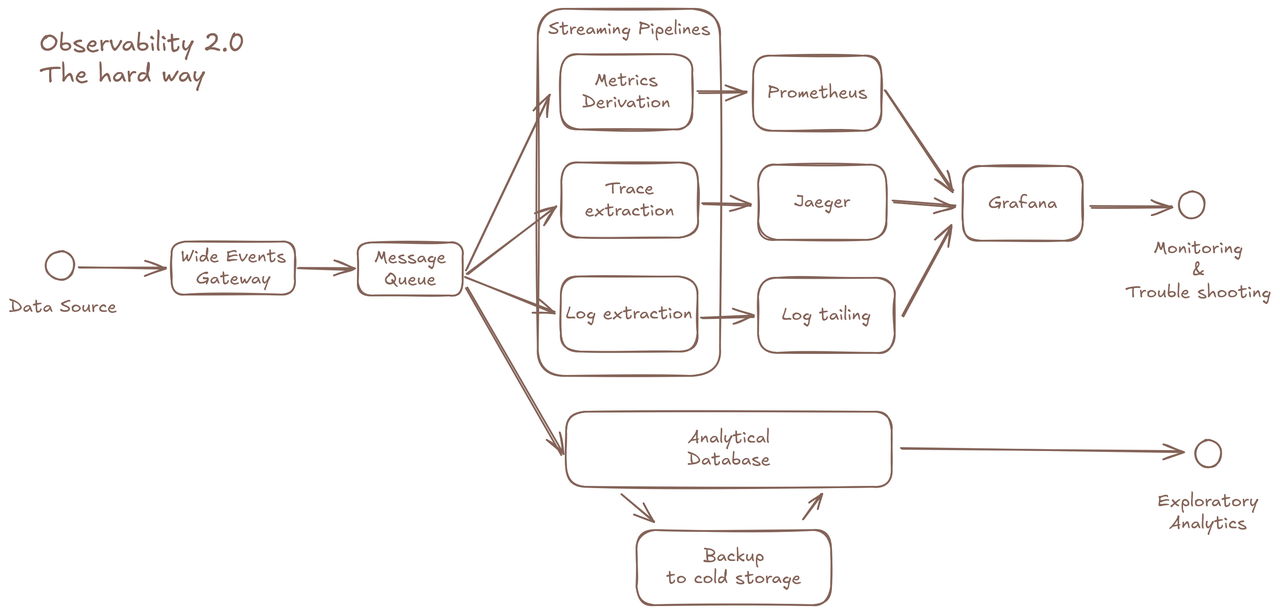 (图 1:Observability 2.0 的架构)
(图 1:Observability 2.0 的架构)
让我们来看看定义 Observability 2.0 的数据库要求的关键因素:
充分利用通用存储和数据格式
- 解耦架构,云对象存储
- 用于压缩和性能的列式数据格式
正如 Boris Tane 的示例所示,单个未压缩的 wide event 可以超过 2KB。对于基于高吞吐量微服务的应用程序,这会在存储需求上引入倍增效应——尤其是在长期保留数据以进行持续分析(例如,训练 AI 模型或审计历史趋势)时。
该数据库必须利用基于云的对象存储(例如,AWS S3、Google Cloud Storage)来实现成本效益和可扩展性。理想情况下,它应该自动执行本地存储和云存储之间的数据分层,并最大限度地减少管理开销——体现了 解耦的计算和存储架构,其中存储的扩展独立于计算资源。
列式数据格式(例如,Apache Parquet、Arrow)对于降低存储成本至关重要。通过按顺序存储来自同一字段的值,它们可以实现自定义编码(例如,字典编码、游程编码)以压缩静态数据。此外,列式格式本质上针对分析查询进行了优化,因为它们允许高效的列修剪和矢量化处理。
实时、可扩展和弹性
- 查询和数据可见性的低延迟
- 摄取速率可以随站点流量而扩展
由于其预聚合的性质,传统的 Metrics 不会随着流量的增加而扩展,除非您启动大量新实例。这使得 Metrics 存储的容量规划更加简单。但是,由于 wide events 充当单一数据源,因此 Observability 数据是按请求生成的,这意味着 Observability 2.0 基础设施必须与应用程序一样可扩展和弹性。为了在现代云环境中正确扩展,必须仔细设计数据库,将状态包含在最小范围内,并为每种类型的节点建立明确的职责分离。
您的数据必须以实时方式摄取和查询,才能满足诸如仪表板和警报之类的实时用例的需求。
灵活的查询功能
- 数据库必须处理 Observability 1.0 查询以及分析查询。
- Metrics 需要在数据库中从 wide events 派生。
Observability 2.0 数据库必须支持两种类型的查询:例行查询(用于仪表板和警报)和探索性查询(用于 ad-hoc 分析)。
删除作为一等公民的 Metrics 并不会消除对预聚合的需求:它只是将此责任从应用程序层转移到数据库。用户仍然需要通过仪表板或警报快速访问“已知已知”(例如,错误率、延迟阈值),这需要高效处理例行查询。然而,这在高维数据中变得具有挑战性。为了解决这个问题,数据库必须支持:
- 灵活的索引策略
- 预处理能力
- 增量计算(例如,更新聚合而无需重新处理整个数据集)
此外,数据库必须处理探索性分析,这可以通过离线、长期分析来揭示“未知未知”。这些查询通常是不可预测的,跨越大型数据集和较长时间范围。理想情况下,数据库应该执行它们,而不会降低例行查询或摄取的性能。虽然用户可以将此工作负载卸载到专用的 OLAP 数据库,但数据复制带来的额外延迟和成本会产生摩擦,从而破坏 Observability 2.0 的统一、实时洞察的目标。
向后兼容 Observability 1.0
- 我们仍然需要 Grafana 仪表板
我们已经拥有来自 Observability 1.0 的强大仪表板、可视化和警报规则。过渡到 wide events 不需要放弃这些工具或从头开始重建。
与 SQL 相比,像 PromQL 这样的 DSL 仍然非常适合时序仪表板。现在的优势在于,由于例行查询(针对仪表板/警报进行了优化)和探索性分析之间的明确分离,复杂的 PromQL 查询变得不必要。至关重要的是,高基数不应再是 Observability 数据库的系统性限制。
必须通过新的后端访问 Trace 视图和日志尾部功能。来自 Observability 1.0 的所有已建立的最佳实践 (例如,警报阈值、仪表板约定和 Trace 分析工作流程) 应保留和增强,而不是丢弃。
这就是我们构建 GreptimeDB 的方式
GreptimeDB 是为 wide events 和 o11y 2.0 实践而构建的开源分析 Observability 数据库。我们将其设计为与现代云基础设施无缝协作,并为用户提供高效、一站式和便捷的 Observability 数据管理体验。
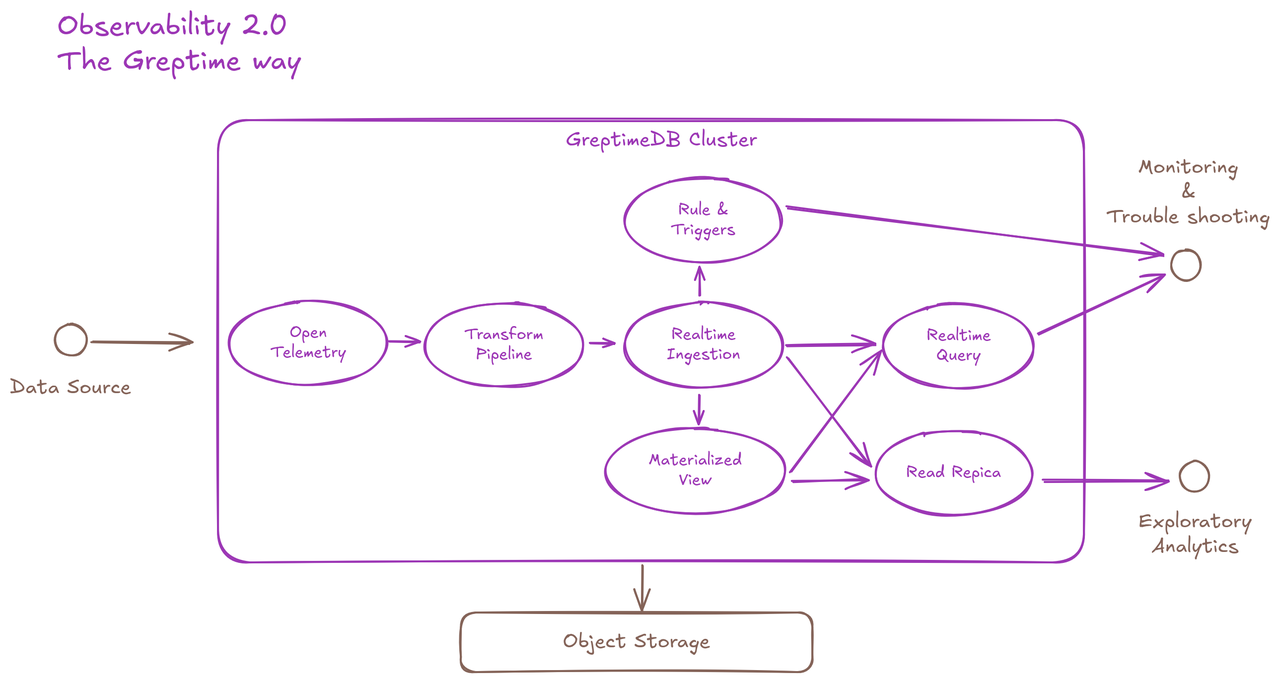 (图 2:Observability 2.0-The Greptime Way)
(图 2:Observability 2.0-The Greptime Way)
此逻辑流程图描述了 GreptimeDB 适合 Observability 2.0 数据生命周期的关键特性:
- 接受 OpenTelemetry 格式的传入数据
- 用于预处理数据的内置转换引擎
- 高吞吐量实时数据摄取
- 实时查询 API
- 用于数据派生的物化视图
- 用于隔离分析查询的只读副本
- 用于基于推送的通知的内置规则引擎和触发机制
- 用于数据持久性的对象存储
结论
我们相信基于原始数据的方法将改变我们使用 Observability 数据并从中提取价值的方式。GreptimeDB 致力于成为开源基础设施,帮助您逐步实现它。
立即开始您的 GreptimeDB 之旅,一次一个事件,解锁 Observability 的未来。
关于 Greptime
GreptimeDB 是一个开源的、云原生的数据库,专为实时 Observability 而构建。它用 Rust 构建并针对云原生环境进行了优化,它为 Metrics、Logs 和 Traces 提供统一的存储和处理——从边缘到云,以任何规模提供亚秒级洞察。
- GreptimeDB OSS – 适用于中小规模 Observability 和 IoT 用例的开源数据库,非常适合个人项目或开发/测试环境。
- GreptimeDB Enterprise – 具有增强的安全性、高可用性和企业级支持的强大 Observability 数据库。
- GreptimeCloud – 一种完全托管的、无服务器的 DBaaS,具有弹性伸缩和零运营开销。专为需要开箱即用的速度、灵活性和易用性的团队而构建。
🚀 我们欢迎贡献者——从带有标记的 issue 开始 good first issue 并与我们的社区联系。