基于神经网络的世界模拟(World Emulation via Neural Network)
Ollin Boer Bohan ## 基于神经网络的世界模拟(World Emulation via Neural Network) 2025年4月25日
我将我家附近的一条森林小径变成了一个可玩的神经世界。 你可以在你的网页浏览器中探索这个世界 点击这里:
我所说的 "神经世界",是指整个东西是一个神经网络,根据之前的图像 + 控制来生成新的图像。 没有关卡几何体,没有光照或阴影的代码,没有脚本动画。 只有一个循环中的神经网络。
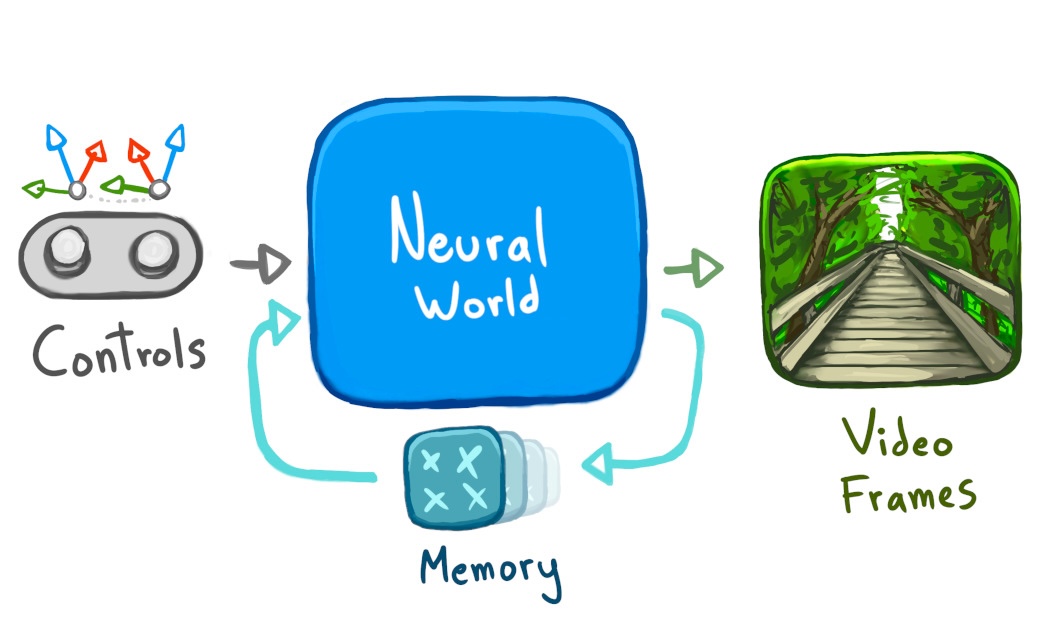 我所说的 "在你的网页浏览器中",是指这个世界在本地,在_你的_网页浏览器中运行。 一旦世界加载完毕,即使在飞行模式下,你也可以继续探索。
那么,为什么要费力用这种方式创建一个世界呢? 有一些有趣的理论原因(我稍后会讲到),但我的主要目标只是超越之前的帖子。
你看,三年前,我通过训练一个神经网络来模仿来自 YouTube 的游戏视频,让一个简单的二维视频游戏世界在浏览器中运行。
模仿一个2D视频游戏世界很可爱,但最终有点毫无意义;现有的视频游戏已经存在,而且我们可以很好地模拟它们。
神经世界的美妙、独特、令人兴奋的特性是,它们可以从任何视频文件构建,而不仅仅是旧视频游戏的屏幕录像。 我之前的帖子并没有真正表达出这一点。
因此,为了这篇文章,为了展示神经网络真正特别的地方,我想训练一个神经网络来模拟真实世界的游戏视频。
我所说的 "在你的网页浏览器中",是指这个世界在本地,在_你的_网页浏览器中运行。 一旦世界加载完毕,即使在飞行模式下,你也可以继续探索。
那么,为什么要费力用这种方式创建一个世界呢? 有一些有趣的理论原因(我稍后会讲到),但我的主要目标只是超越之前的帖子。
你看,三年前,我通过训练一个神经网络来模仿来自 YouTube 的游戏视频,让一个简单的二维视频游戏世界在浏览器中运行。
模仿一个2D视频游戏世界很可爱,但最终有点毫无意义;现有的视频游戏已经存在,而且我们可以很好地模拟它们。
神经世界的美妙、独特、令人兴奋的特性是,它们可以从任何视频文件构建,而不仅仅是旧视频游戏的屏幕录像。 我之前的帖子并没有真正表达出这一点。
因此,为了这篇文章,为了展示神经网络真正特别的地方,我想训练一个神经网络来模拟真实世界的游戏视频。
记录数据
为了开始这个项目,我走过一条森林小径,用我的手机录制视频,使用一个定制的相机应用程序,它也记录了我手机的运动。
我收集了约 15 分钟的视频和运动记录。 我将运动可视化为一个 "行走" 控制杆(在左边)和一个 "观看" 控制杆(在右边)。
回到家后,我将录音传输到我的笔记本电脑上,并将它们洗牌成一个 (前一帧, 控制 → 下一帧) 对的列表,就像我之前的游戏模拟数据集一样。
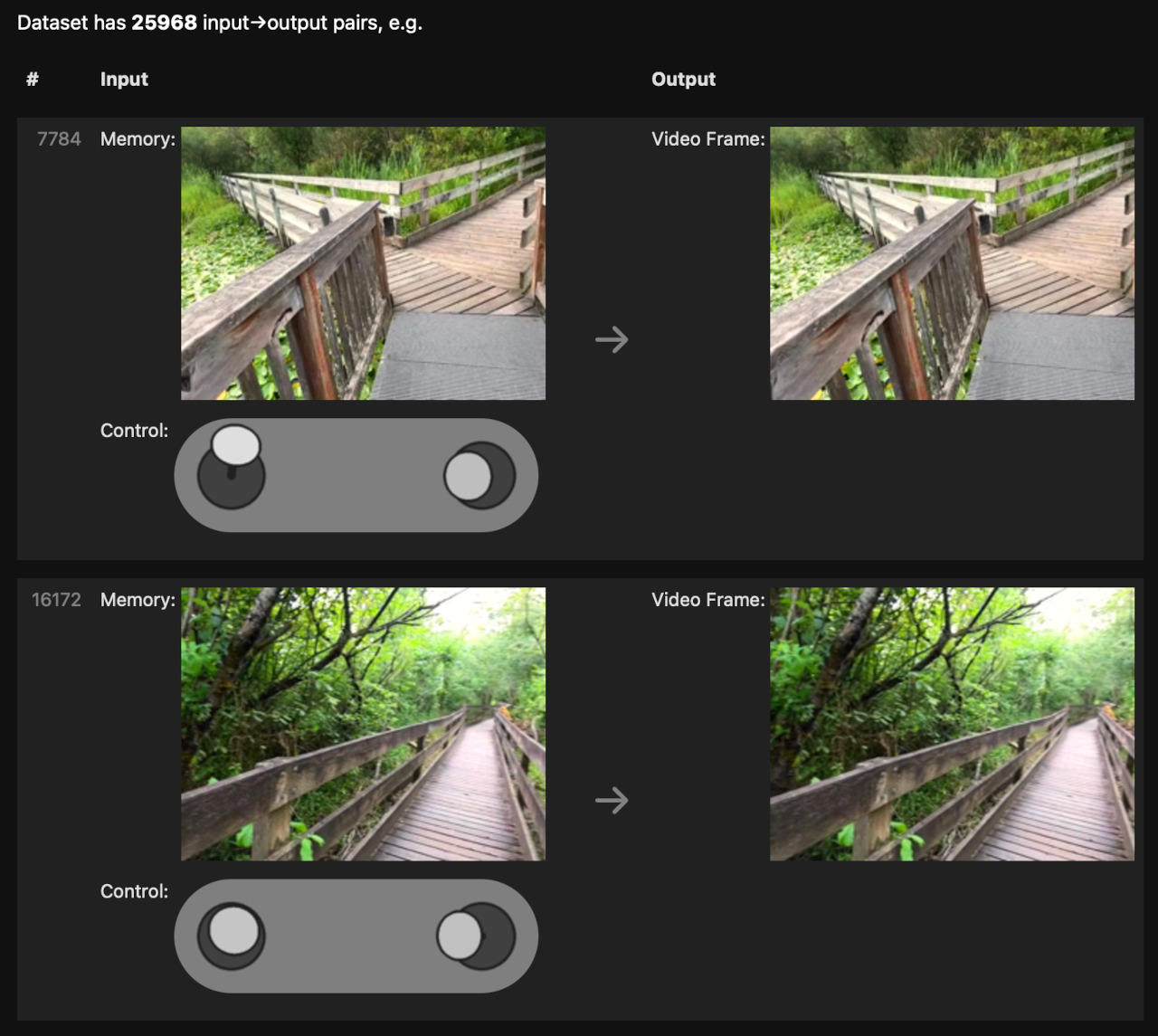 现在,我所需要做的就是训练一个神经网络来模仿这些输入→输出对的行为。 我已经有了来自我之前的游戏模拟项目的可用代码,所以我尝试重新运行该代码以建立基线。
现在,我所需要做的就是训练一个神经网络来模仿这些输入→输出对的行为。 我已经有了来自我之前的游戏模拟项目的可用代码,所以我尝试重新运行该代码以建立基线。
训练基线
将我之前的通过神经网络进行游戏模拟的配方应用于这个新数据集,遗憾的是,产生了一种交互式的森林风味汤。 我的神经网络无法准确地预测实际的下一帧,而且它无法足够快地弥补新的细节,因此即使我通过从真实的视频帧初始化来给它一个良好的开端,由此产生的世界也会崩溃: 毫不气馁,我开始开发新版本的神经世界训练代码。
升级训练配方
为了帮助我的网络理解真实世界的视频,我做了以下升级:
- 添加更多的控制信息。 我将 "控制" 网络输入从简单的 2D 控制升级为更具信息的 3D (6DoF) 控制。
- 添加更多的内存。 我将 "内存" 网络输入从单个帧升级到 32 帧(对较旧的帧使用较低的分辨率)。
- 添加多个尺度。 我重构了网络以处理跨多个分辨率的所有输入,而不是固定的 1/8 分辨率。
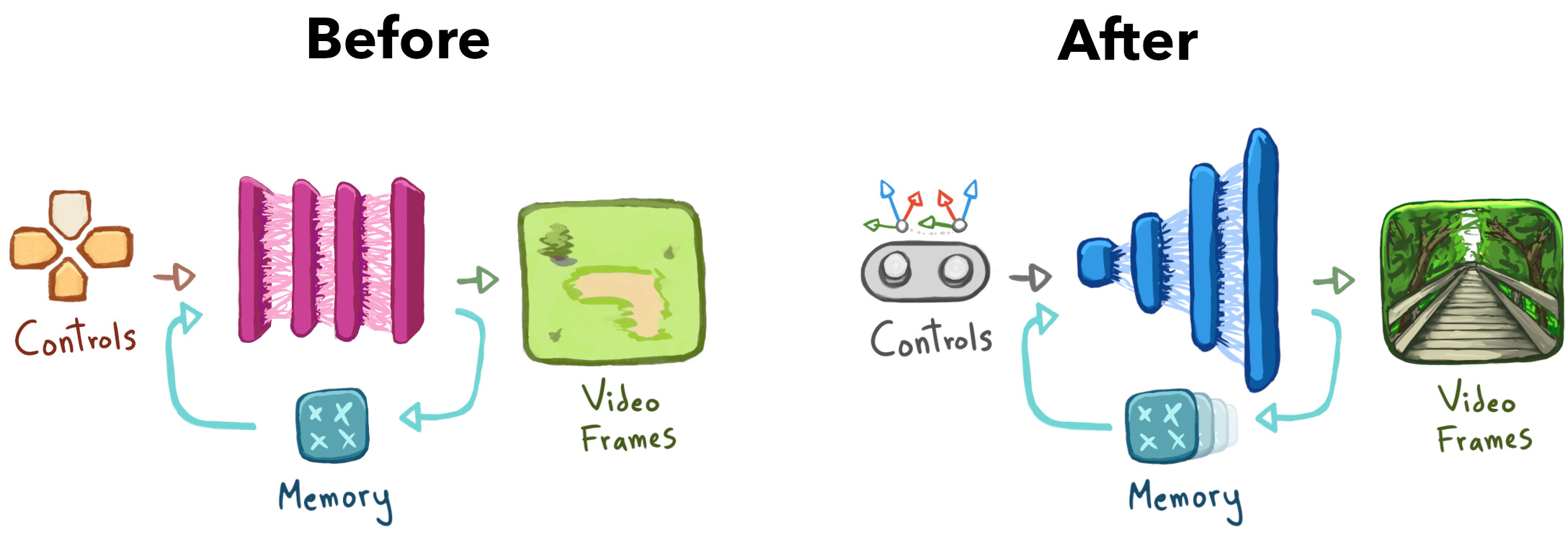 这些升级让我避免了足够多的 soupification,从而获得了一个半成品演示:
这是一个重要的进展。 不幸的是,这个世界仍然很融化,所以我开始进行第二批改进(这次更令人沮丧)。
这些升级让我避免了足够多的 soupification,从而获得了一个半成品演示:
这是一个重要的进展。 不幸的是,这个世界仍然很融化,所以我开始进行第二批改进(这次更令人沮丧)。
更多地升级训练配方
这一次,我将输入/输出保持不变,并专注于寻找对训练过程的增量改进。 这是一个经过优化的蒙太奇: 质量的最大飞跃来自:
- 使网络更大:我添加了更多的神经网络处理层,同时努力维持一个可以在一定程度上进行游戏的 FPS。
- 选择更好的训练目标:我调整了训练,以减少对细节预测的重视,而更多地强调细节生成。
- 训练更长时间:我在选定的视频帧子集上训练了网络更长时间,以尝试获得最高质量的结果。
以下是最终森林世界配方的摘要:
- 数据集:22,814 帧(30FPS SDR 视频,带时间戳的 ARKit 姿势)在 Marymoor Park Audobon Bird Loop 使用 iPhone 13 Pro 捕获。
- 输入:3x4 元素的相对相机姿势、2 元素的相对于重力的横滚/俯仰、相对时间增量、有效/增强位、4 个过去的帧 TCHW 内存缓冲区 (32×3×3×4, 16×3×12×16, 8×3×48×64, 4×3×192×256),4 个每个空间尺度上的 U(0, 1) 单通道噪声张量(如 StyleGAN)。
- 模型:非对称(解码器繁重)4 尺度 UNet,具有缩小尺寸的全分辨率解码器块。 ~5M 可训练参数,每个生成的 192×256 帧 ~1 GFLOP。

- 训练:AdamW 恒定 LR + SWA, L1 + 对抗损失, 来自游戏模拟配方的稳定性修复, 约 ~100 GPU-hours (~$100 USD)。
- 推理:控制条件顺序自回归,具有 60FPS 限制,在 JS 中进行预处理,在 ONNX Runtime Web 的 WebGL 后端中进行网络处理。
呼。 那么,让我们回到最初的问题:为什么要费力呢? 为什么要付出这么多努力来获得一条森林小径的低分辨率神经世界? 为什么不使用传统的视频游戏技术制作更稳定、更高分辨率的演示呢?
创建世界的两种方式
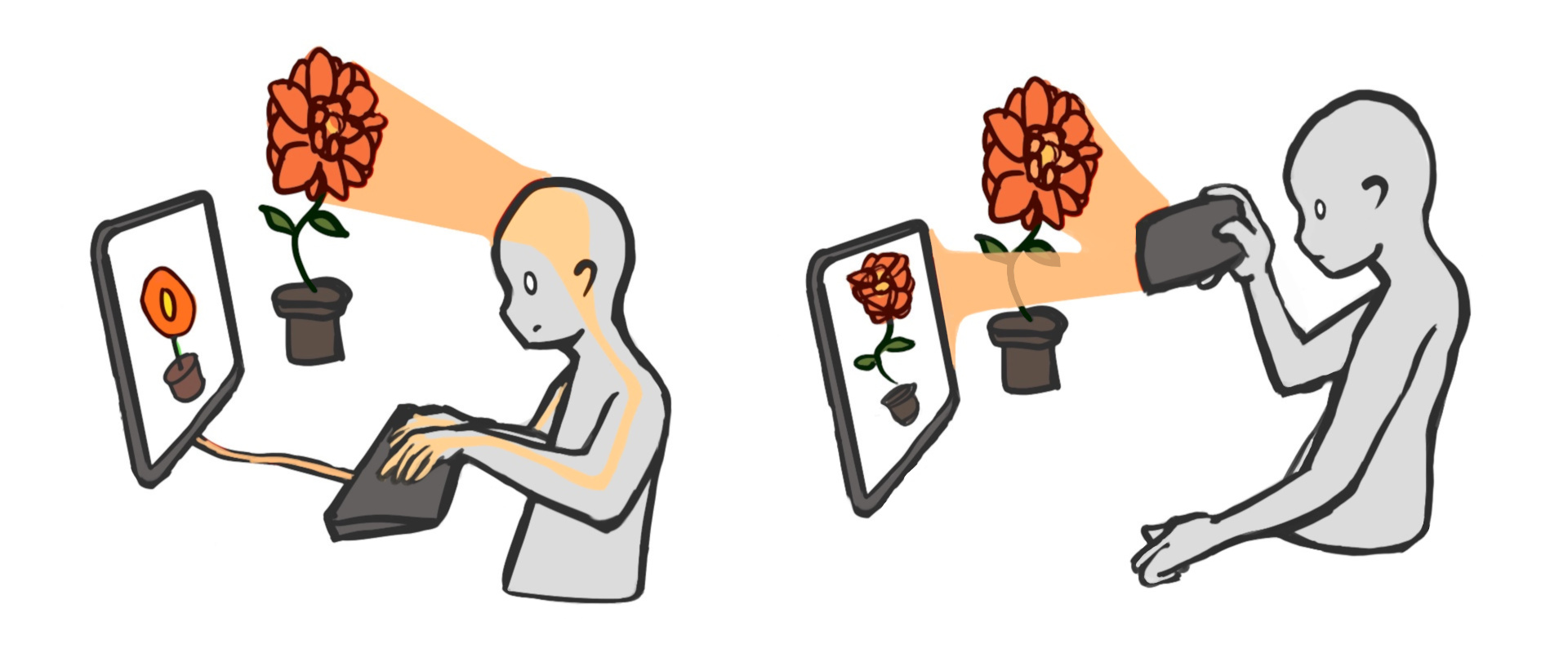
传统的游戏世界就像绘画一样制作。 你坐在一个空白的画布前,一层一层地 敲击键盘,直到得到一些美丽的东西。 传统游戏中每一个栩栩如生的细节都只是因为 一些艺术家把它画进去。
神经世界的制作方式截然不同。 为了创建一个森林的神经世界,我走进一个真实的森林,然后按下我手中设备的 "记录" 按钮。 最终世界中每一个栩栩如生的细节都只是因为我的手机记录了它。
因此,如果传统的游戏世界是绘画,那么神经世界就是照片。 信息从传感器流向屏幕,而无需经过人手。
 诚然,截至这篇文章发布时,神经世界类似于_非常早期的_照片。 早期的相机 几乎无法工作,而且它们拍摄的照片根本就不逼真。
诚然,截至这篇文章发布时,神经世界类似于_非常早期的_照片。 早期的相机 几乎无法工作,而且它们拍摄的照片根本就不逼真。
 令人兴奋的是,相机将创建真实图像从一个艺术问题简化为一个技术问题。 随着技术的进步,相机也随之改进,照片变得越来越忠实于现实,而绘画却没有。
令人兴奋的是,相机将创建真实图像从一个艺术问题简化为一个技术问题。 随着技术的进步,相机也随之改进,照片变得越来越忠实于现实,而绘画却没有。
 我认为神经世界的保真度会像照片一样得到提高。 随着时间的推移,神经世界将拥有在风中摇曳的树木、在雨中漂浮的睡莲、互相唱歌的鸟儿。 自动地,因为现实世界有这些东西,而且一个工具可以记录它们。 而不是因为艺术家把它们画进去。
我认为创建神经世界的工具最终也可以像今天的相机一样方便。 正如现代数码相机只需按下一个按钮即可创建图像或视频一样,我们可以拥有一个创建世界的工具。
如果神经世界变得像今天的照片一样逼真、廉价和可组合,那么神经世界的叙事安排可能会成为一种独特的创意媒介,就像照片与绘画的区别一样。
我认为那将是非常令人兴奋的!
对世界进行建模的神经网络通常被称为 "世界模型",许多聪明的人都在研究它们;一个经典的例子是 Comma 的 "Learning a Driving Simulator",最近的一些例子是 OpenDriveLabs 的 Vista 或 Wayve 的 GAIA-2。 如果你是一名对训练自己的世界模型感兴趣的程序员,我建议你看看 DIAMOND 或 Diffusion Forcing。
与拥有数十亿个参数的严肃的 "Foundation World Models" 相比,本文中介绍的基于 GAN 的 WM 只是一个玩具(而且是一个相当脆弱的玩具)。 尽管如此,进一步改进配方并制作更多世界会很有趣。 如果你知道西雅图附近有什么有趣的地方可以拍摄,LMK。
GitHub / Mastodon / Twitter / Email
我认为神经世界的保真度会像照片一样得到提高。 随着时间的推移,神经世界将拥有在风中摇曳的树木、在雨中漂浮的睡莲、互相唱歌的鸟儿。 自动地,因为现实世界有这些东西,而且一个工具可以记录它们。 而不是因为艺术家把它们画进去。
我认为创建神经世界的工具最终也可以像今天的相机一样方便。 正如现代数码相机只需按下一个按钮即可创建图像或视频一样,我们可以拥有一个创建世界的工具。
如果神经世界变得像今天的照片一样逼真、廉价和可组合,那么神经世界的叙事安排可能会成为一种独特的创意媒介,就像照片与绘画的区别一样。
我认为那将是非常令人兴奋的!
对世界进行建模的神经网络通常被称为 "世界模型",许多聪明的人都在研究它们;一个经典的例子是 Comma 的 "Learning a Driving Simulator",最近的一些例子是 OpenDriveLabs 的 Vista 或 Wayve 的 GAIA-2。 如果你是一名对训练自己的世界模型感兴趣的程序员,我建议你看看 DIAMOND 或 Diffusion Forcing。
与拥有数十亿个参数的严肃的 "Foundation World Models" 相比,本文中介绍的基于 GAN 的 WM 只是一个玩具(而且是一个相当脆弱的玩具)。 尽管如此,进一步改进配方并制作更多世界会很有趣。 如果你知道西雅图附近有什么有趣的地方可以拍摄,LMK。
GitHub / Mastodon / Twitter / Email